

クラスター分析(第1回) 好きと苦手の境界線
クラスター分析とは
好きな食べ物
日本人が好む食事といえば寿司だそうです。すしネタのなかでは、まぐろ、サーモン、いくら、はまち、えび、このあたりが人気上位を占めるみたいです。
とは言っても、すし店に来店される顧客の全員がまぐろ好きとは限りません。まぐろは苦手という顧客もいるし、まぐろしか食べないというよな顧客もいるはずです。
好きなすしネタ、苦手なすしネタのような顧客別の嗜好ですし店の顧客を特徴づける方法がクラスター分析です。
クラスター分析が有効な場面
回転すし店を予約しようと思います。近隣には回転すし店が3店舗あってどこにしようかと迷います。
回転すし店のスマホアプリを開いてみると、
・1店舗目は「まぐろ1皿無料クーポン」
・2店舗目は「サーモン1皿無料クーポン」
・3店舗目は「フライドポテト100円値引クーポン」です。
まぐろ好きは1店舗目、サーモン好きは2店舗目、お子様連れは3店舗目を予約すると思います。
すし店がアプリを開いた顧客の嗜好をあらかじめ知っているとしたら?
・1店舗目をまぐろ好きが開くと「まぐろ1皿無料クーポン」
・1店舗目をサーモン好きが開くと「サーモン1皿無料クーポン」
・1店舗目をお子様連れが開くと「フライドポテト100円値引クーポン」
顧客の好みにあわせたクーポンが表示されます。
2軸クラスター分析
サンプルデータ
| 顧客グループ | さば | まぐろ | サーモン | 合計 |
| A | 60 | 120 | 80 | 260 |
| B | 40 | 130 | 60 | 230 |
| C | 50 | 80 | 100 | 230 |
| D | 60 | 100 | 130 | 290 |
| E | 90 | 60 | 70 | 220 |
| F | 100 | 40 | 50 | 190 |
| 合計 | 400 | 530 | 490 |
顧客グループ:A,B,C,D,E,F
商品データ:3種類 さば、まぐろ、サーモン
値:食べた皿数
クラスター分析

分析ツール:タブロー
食べた皿数で2軸を設定して、顧客グループをプロットした散布図をつくります。クラスター分析のスタートは2軸からです。
3種類の商品から2軸をつくると、
・さばorまぐろ
・さばorサーモン
・まぐろorサーモン
選択した2商品のどちらかが「横軸」「縦軸」になり、3通りの散布図を描くことができます。
プロットの形状、〇□△+がクラスターの別を示します。
顧客たいして二者択一の質問を、例えば「さばとまぐろとを比べると、どちらが好きですか?」といったイメージです。
まぐろの皿数が多ければ「まぐろが好き」だといえます。
散布図から読み取れる結果をアナログで表現するとこのような感じです。
| 顧客グループ | さばorまぐろ (どちらが好きか?) | さばorサーモン (どちらが好きか?) | まぐろorサーモン (どちらが好きか?) |
| A | まぐろ | はっきりしない | まぐろ |
| B | まぐろ | はっきりしない | まぐろ |
| C | まぐろ | サーモン | どちらも好き |
| D | まぐろ | サーモン | サーモン |
| E | さば | さば | はっきりしない |
| F | さば | さば | はっきりしない |
3通りの散布図がら
・「A・B」=どの散布図でも常に同じクラスターになる
・「E・F」=どの散布図でも常に同じクラスターになる
・CとDは散布図によって「A・B」のクラスターになったり、別のクラスターにもなる
・CとDが分かれて別のクラスターになる散布図もあります。
質問にたいする回答
質問①:さば、まぐろ、どちらが好きですか?
質問②:さば、サーモン、どちらが好きですか?
質問③:まぐろ、サーモンどちらが好きですか?
・A・Bは常に同じクラスターになる
・E・Fも常に同じクラスターになる
ということは・・・二者択一の3つの質問にたいして「A・B」と「E・F」はいつも同じ答えをしているから常に同じクラスターになるようにみえます。
さばorまぐろorサーモン
全部盛り
二者択一の質問ではなく、
質問:さば、まぐろ、サーモン、どれがが好きですか?
このような質問に変更します。
分析ツールR
#データを読み込みます
d2<-read.csv("ファイルパス/ファイル名.csv",header=T)
#店舗を列名にします
row.names(d2) = d2[,1]
#データの2列目から4列目を分析します
#アイテム数が多い場合は分析する列数を増やすだけでOKです
d2 = d2[,2:4]
#距離を計算します
d.dist<- dist(d2)
#クラスターを形成します
d.hc1<-hclust(d.dist,method="ward.D2")
#デンドログラムを描画します
plot(d.hc1)
結果
デンドログラム (樹形図といわれています) で描画しました。 (左右は同じものです)
・右図①の赤い線で分割するとクラスターは2になります。
「さばorまぐろ」の散布図でクラスターをつくったときと同じ結果になります。
・右図②の赤い線で分割するとクラスターは3になります。
「さばorサーモン」の散布図でクラスターをつくったときと同じ結果になります。
・右図③の赤い線で分割するとクラスターは4になります。
前回の「まぐろorサーモン」の散布図と同じ結果になります。
結果が同じということは、アイテム数 (すしネタの種類) 「or」をどんどん増やしてもアルゴリズムはまったく同じだろうということです。
何を計算してクラスターを形成しているのか
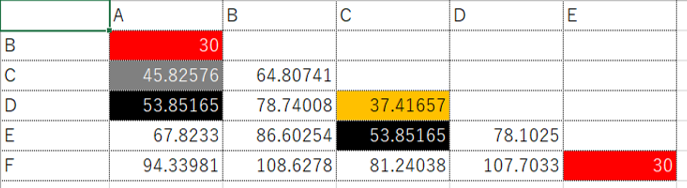
A、B、C、D、E、F、それぞれの2点間の距離をあらわします。 (6×5) ÷ (2×1) =15通りの距離を算出します。
<第1段階 ③の線>
・はじめに、2点間の距離が最も近いA・BとE・F (赤いセル) のクラスターが同時に形成されます。同時というのはどちらも距離が同じ (30) だからです。
図では同じ高さのところでA・BとE・Fのクラスターが形成されました。CとDはくっついていませんからこの時点でのクラスター数は4です。
<第2段階 ②の線>
・次に距離が近いC・D (オレンジのセル) でクラスターが形成されます。
この時点でのクラスター数は3です。
<第3段階 ①の線>
・その次に距離が近いA・C (グレーのセル) がクラスターを形成します。
Aは第1段階でBとクラスターを形成、Cは第2段階でDとクラスターをすでに形成しているので、A・B・C・Dでクラスターが形成されます。
この時点でのクラスター数は2。言い換えるとAとCの仲が良いからA・B・C・Dがまとまっている。
<最終段階 母集団>
さいごはA・DとC・E(黒のセル)がくっついて母集団になります。
決定木分析との違い
決定木分析でもクラスター分析結果のような樹形図をアウトプットしました。どちらも似ていますが決定的な違いがあります。
決定木分析は母集団を順次切り離す、樹形図の上から純度が高いノードを分離してゆく手順です。クラスター分析は似ているデータを集める、樹形図の下から積み上げてゆく手順です。ですからクラスターは「分ける」ものではなく「形成する」ものですね。
タブローとRの連携
R側でRserveパッケージをつかいかます
install.packages(Rserve) library(Rserve) Rserve()
タブローを起動する前にRを起動しておく必要があります。
タブロー側
「ヘルプ」→「設定とパフォーマンス」→「外部サービス接続の管理」
計算式でメジャーをつくります
SCRIPT_INT( 'set.seed(42);result<- kmeans( data.frame(.arg1,.arg2,.arg3),.arg4[1]);result$cluster;',SUM([さば]), SUM([まぐろ]),SUM([サーモン]),[clust] )
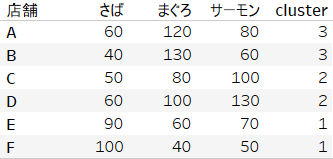
さいごの[clust]はパラメーターです。クラスター数を設定する (非階層クラスター分析) と便利です。