

Coding(KHcoder) 5 Pearson rsd
バブルの色付けにつかわれている Pearson rsd その計算式を解明しました。
Pearson rsd計算方法
内部で計算されている
KHcoderの解析結果の多くはRソースで出力することができます。
その出力ファイルを見るとデータをどのように整形しているのか、どのような関数で計算しているのかを概ね理解することができます。
実際にRへファイルを投入すれば計算の途中経過を確認することができます。
魚卵 エビ・イカ マグロ 青魚 貝類 惣菜 10代 4 4 3 0 0 3 40代 1 3 3 4 0 0 60代 1 1 2 3 4 0
KHcoderで描画される分析結果の多くは、このようにディメンション×ディメンションと出現回数のマトリクス型データをインプットしRで計算して、各種解析結果をアウトプットするような仕組みになっています。
rsd <- matrix( c(1.41421356237309,-0.707106781186547,-0.707106781186547,0.816496580927726,0.204124145231932,-1.02062072615966,0.204124145231932,0.204124145231932,-0.408248290463863,-1.52752523165195,1.09108945117996,0.436435780471985,-1.15470053837925,-1.15470053837925,2.3094010767585,2,-1,-1), byrow=T, nrow=6, ncol=3 ) rsd <- t(rsd)
「Pearson rsd」の算出方法が知りたくてヒートをRソースに出力しました。出力ファイルを開いてみると、すでに計算された結果が・・・Rへ送り込まれています。
魚卵 エビ・イカ マグロ 青魚 貝類 惣菜 10代 1.4142136 0.8164966 0.2041241 -1.5275252 -1.154701 2 40代 -0.7071068 0.2041241 0.2041241 1.0910895 -1.154701 -1 60代 -0.7071068 -1.0206207 -0.4082483 0.4364358 2.309401 -1
「Pearson rsd」は、はじめから計算済みのデータとしてRへ送り込まれているので、Rをみても計算式がわかりません。
「Pearson rsd」は統計解析で一般的に広く使用されていないのでしょうか?ネットで調べても計算式を発見できず苦戦しました。
「rsd」の「相対的標準偏差」、標準偏差という語にずいぶん悩まされながらも、エクセルで計算して何とか計算式を発見しました。
計算式を解明
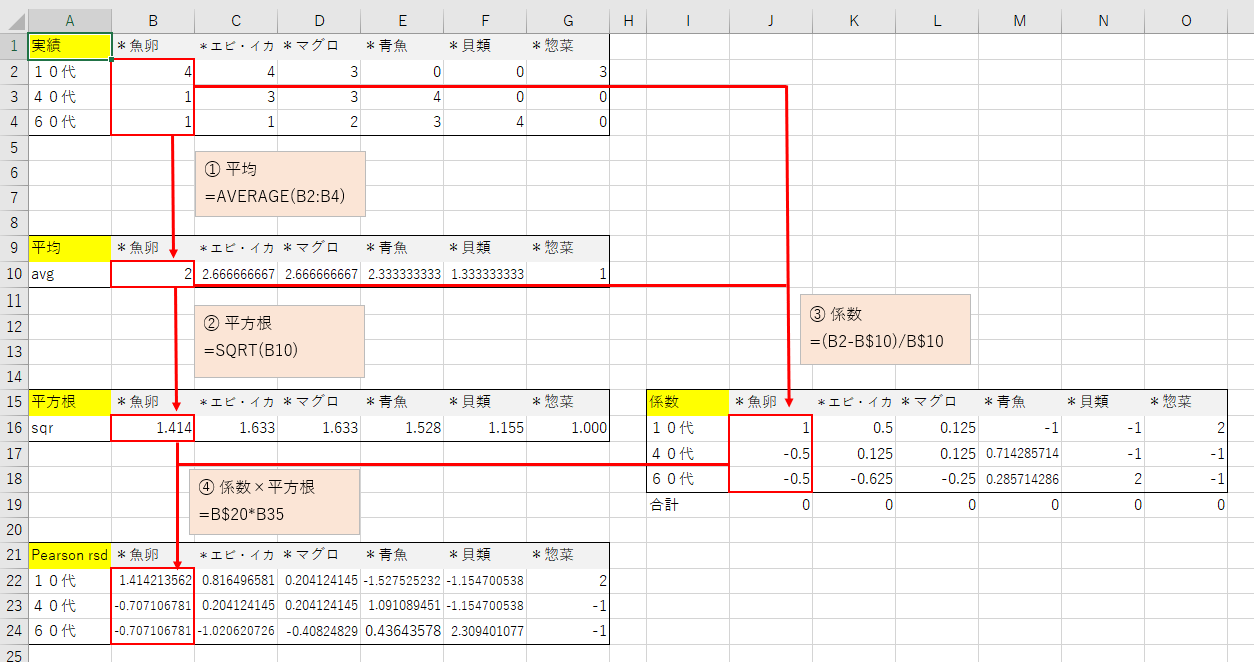
元データはコーディング・クロス集計、値は「度数」です。
① 平均
列ごとに合計出現回数の平均値を算出します。度数の合計を行数(3)で割ります。
*魚卵でいうと出現合計(タテ計)=6を行数=3で割るから、平均=2です。
② 平均の平方根
平均値の平方根を計算します。√平均値です。
③ 係数
セルごとに係数を算出します。(度数-平均値)÷平均値です。係数のタテ計はゼロになります。
④ 係数×平均値の平方根
②と③をかけ合わせます。これで完成です。「Pearson rsd」の縦計はゼロになります。
方程式:√平均値×(度数-平均値)÷平均値
・平均値の平方根は「コード」の度数合計に比例します。
・(個別の度数-平均値)÷平均値は、個別度数と合計度数平均値との差分に比例します。
「Pearson rsd」は、
A:「コード」の出現回数が多ければ「コード」と「コード」の関係において相対的に高くなる。
→データテーブル表のヨコの関係(分散)をみることができる。
B:特定の「外部変数」に集中して出現すると、特定の「コード」が出現する「外部変数」と「外部変数」の関係において相対的に高くなる。
→データテーブル表のタテの関係(分散)をみることができる。
C:相対評価だから「Pearson rsd」のタテ計はゼロになる。
D:個別度数と合計度数平均値との差分がゼロのとき「Pearson rsd」はゼロになる。つまりバラつきがない。
「語」のバブル
「語」のバブルを描く方法
バブルはコーディング分析にしかありません。
「コード」でバブルは描けても「語」では描けません。そこでプログラミングなしで「語」をバブルにプロットする方法を考えました。
① 「語」をすべて1対1の「コード」へ変換する。
② 「バブル」で出力したRソースのデータ部分を「語」のデータ(度数とPearson rsd)に書き換える。
③ 別のツールをつかう。
②の方法は全くやる気が起こらないので、まず①の方法をやってみます。
「語」を「コード」へ変換する方法
*イクラ イクラ *明太子 明太子 *エビ エビ (実際のファイルは下へずっと続きます)
すべての「語」をコーディングします。「語」=「コード」、1対1です。
いい感じの結果になりました。19「語」のコーディングですからそれほどの時間を要することなく完成しました。
しかし、数百語になるとコーディングファイルを作成する気にならないところに最大の問題があります。そこで③別のツールでやってみます。
タブロー
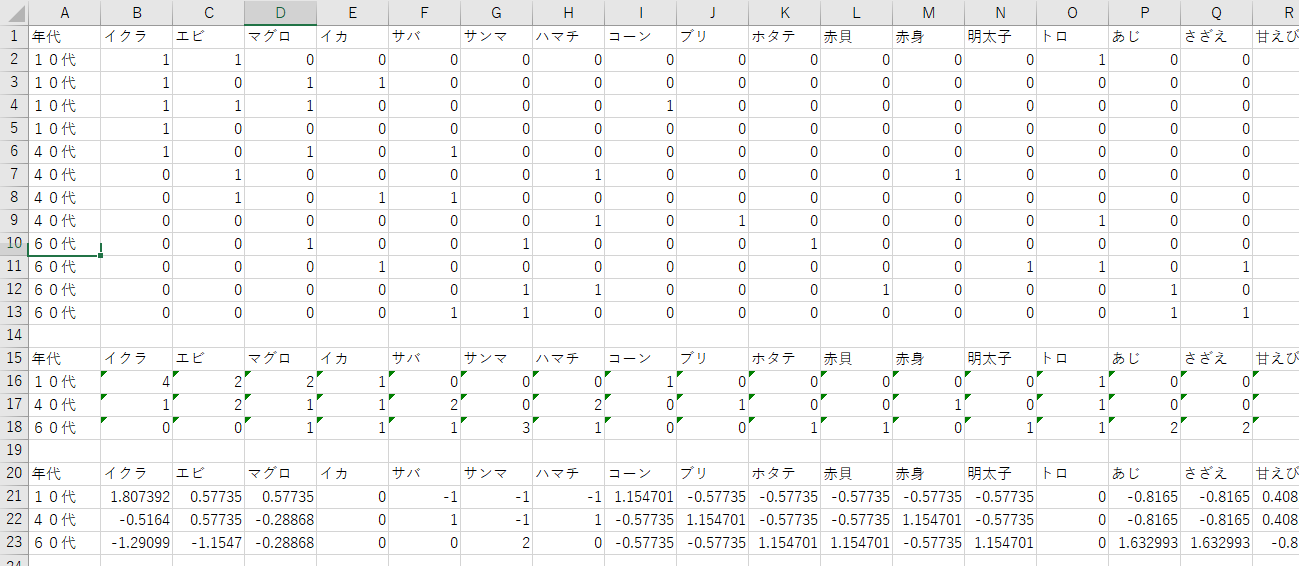
KHcoderには「外部変数」・「語」のクロス集計表をアウトプットする機能がありません。別の方法でクロス集計表を抽出します。
・まず、「ツール」→「文書」→「文書×抽出語」表の出力→CSVファイルを出力します。
・「分析対象テキスト」の外部変数のなかの年代を結合します。
これで画像上部分のクロス集計表が完成です。(不要な列は除いてください)
このままタブローにつないでもよいのですが、セルごとの計算はエクセルのほうがが得意とするので、エクセルでクロス集計表を加工します。
・年代ごとに度数を集計(合計)します。
・「Pearson rsd」の計算式をつかい、「Pearson rsd」をセルごとに算出します。
・エクセルで保存します。
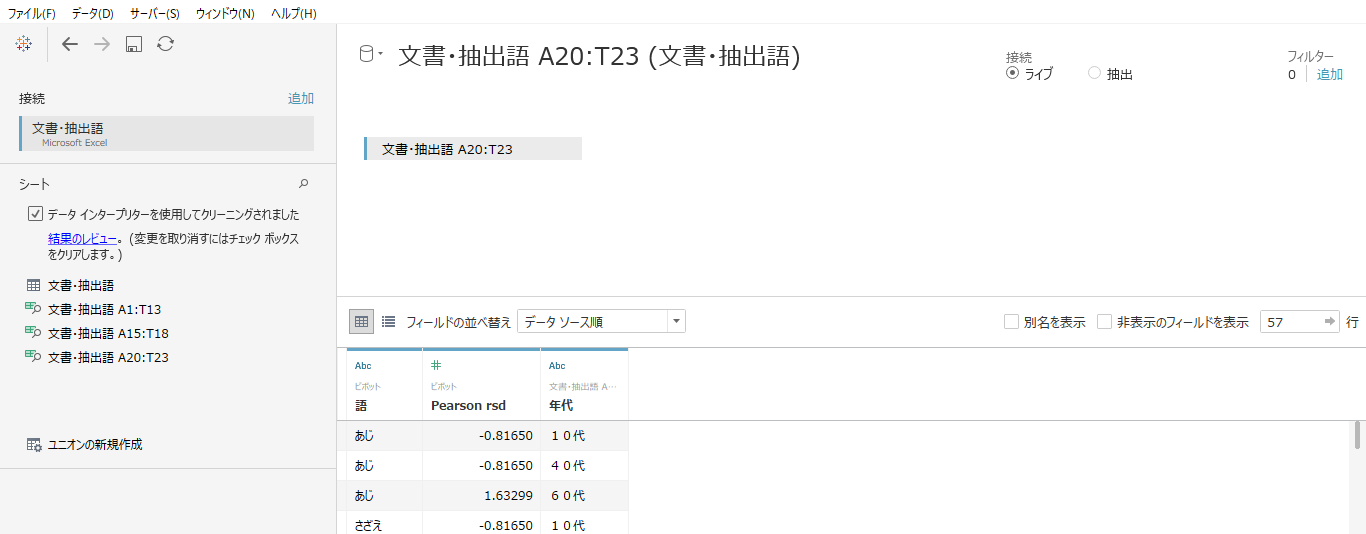
タブローでデータに接続します。
エクセルの1シートには複数のテーブルがあるので
・データインタープリターで年代ごとの度数集計テーブル
・「Pearson rsd」のテーブルへ接続します。
タブローのデータインタープリター機能はすばらしい。
・どちらのテーブルも「語」のすべての列をピポットでリスト型テーブルへ変換します。(ピポット対象列をすべて選択して右クリック、ピポットをクリックするだけでテーブル型へ変換できます)
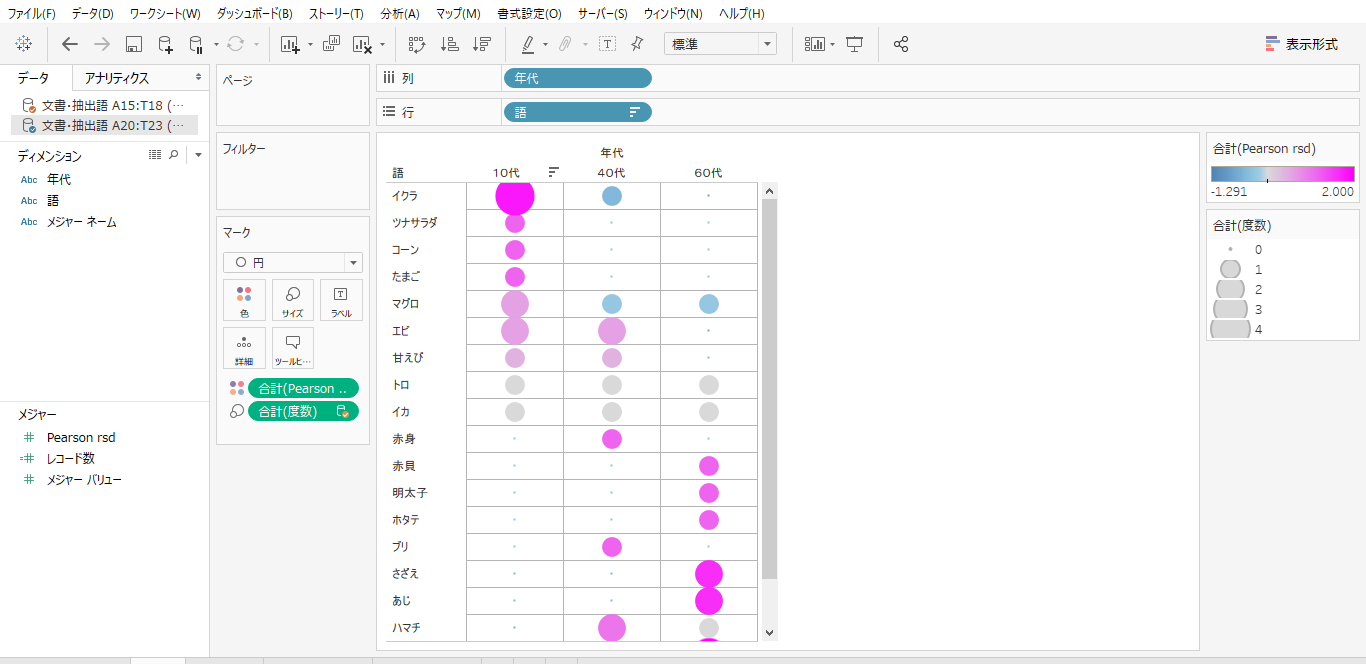
・「Pearson rsd」データの「年代」を列シェルフへ
・「語」を行シェルフへドロップします。
・色へ「Pearson rsd」
・サイズへ年代ごとの度数集計データの「度数」をドロップして
・マークの形状・色の分化・サイズを調整して完成です。

・サイズへドロップした「度数」を外します。
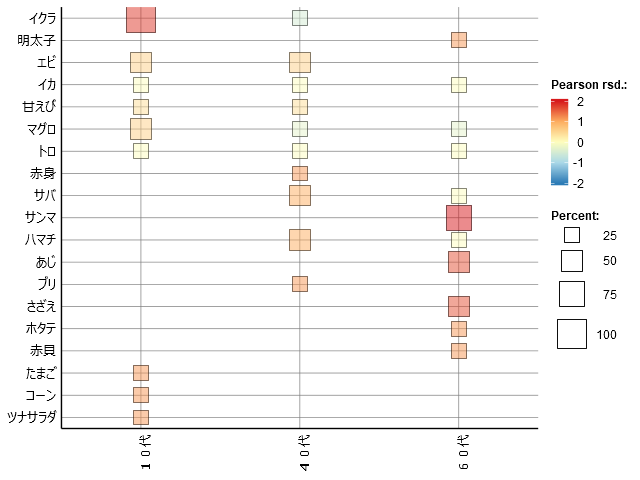
これを描画したかったのです。「語」レベルでです。これは「抽出語」のヒートを「Pearson rsd」で色分けしたものだといえます
・「Pearson rsd」のクロス集計表をみると「度数」がゼロのセルにも「Pearson rsd」値があります。
・KHcoserのバブルは「度数」ゼロのセルはプロットしません。
しかし、「度数」がセロのときの「Pearson rsd」に何か意味があるのではないかと考えました。
・左画像は10代・「Pearson rsd」降順でならべています。
・右画像はコード別・10代・「Pearson rsd」降順にならべています。
・「コード」でみるとマグロは全年代に人気があるが、赤身を好むのは40代、トロはすべての年代が好む。
・10代は惣菜のどのネタも好む。
「ツナサラダ・コーンたまご乗せ」のようなメニューを開発すると大ヒット間違いなし。
一方、「イクラ」&「明太子」の盛り合わせはどの年代にもウケません。