
KHcoder 24. 自己組織化マップ(第1回)
自己組織化マップについて
チャレンジしてみた
分析対象テキストはこれまで通り「好きなすしネタ」です。
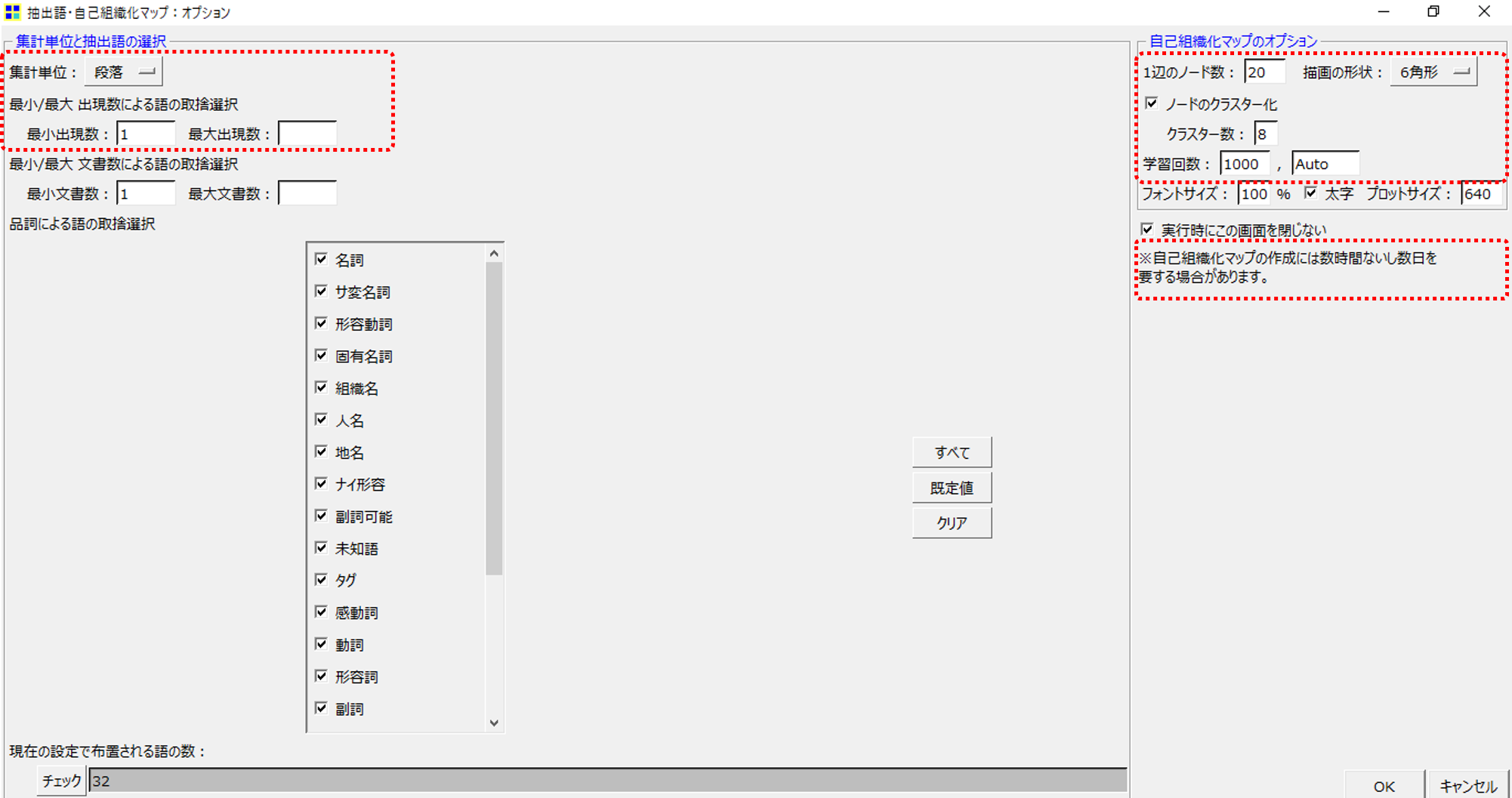
・集計単位=「段落」(12段あります)
・最小出現数=1(32「語」あります)に設定します。
・1辺のノード数=20
・描画の形状=六角形
・学習回数=1,000、auto、これらはデフォルト設定のとおりです。
自己組織化マップの作成には数時間ないし数日を要する場合があります。
恐ろしい注意書が目に飛び込んできます。自己組織化マップにチャレンジすることを躊躇してしまいますが、思い切って「OK」を押します。待つこと約5分、12段、32語ですから数時間を要することはありませんでした。
マップの概要
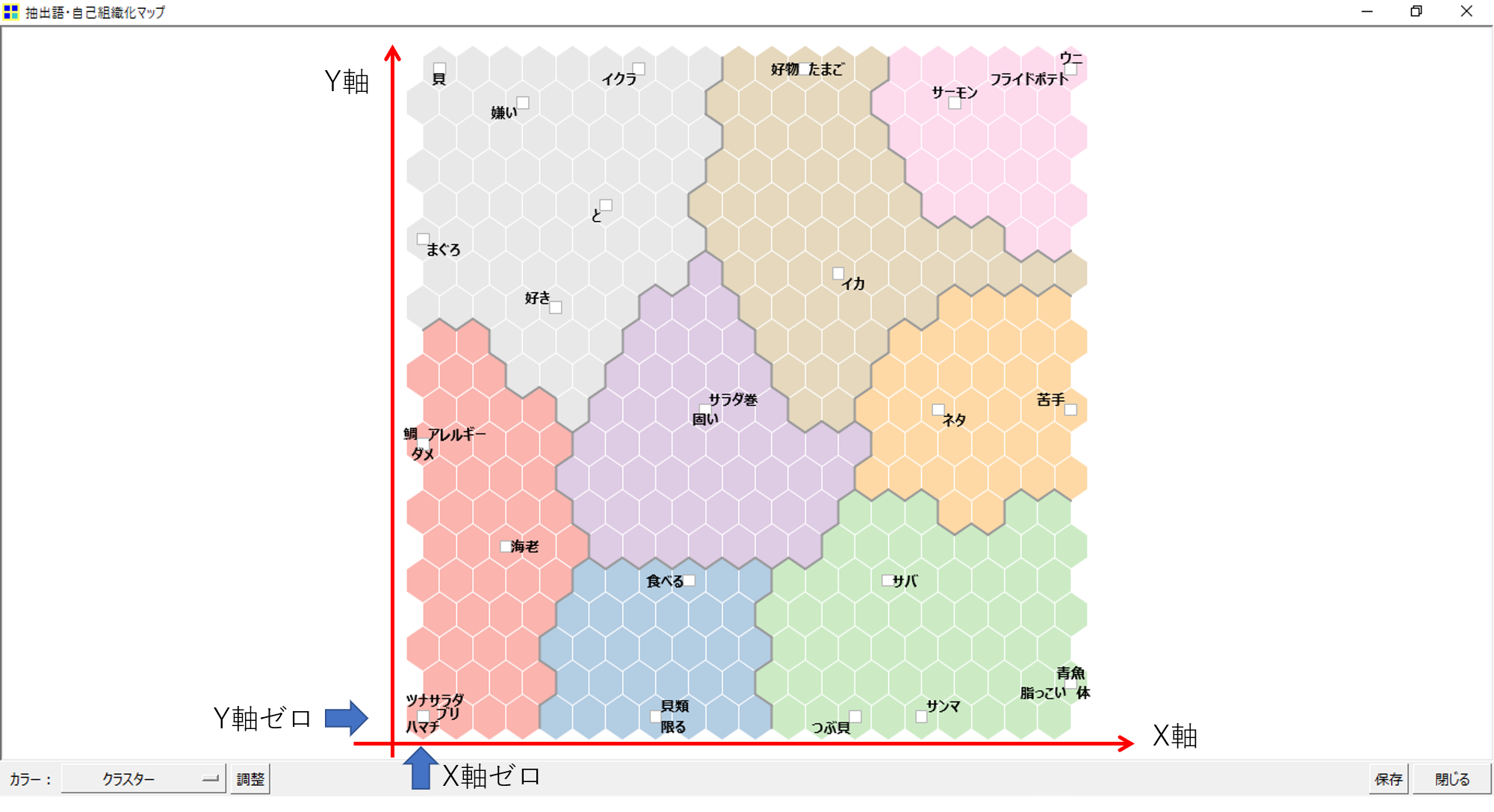
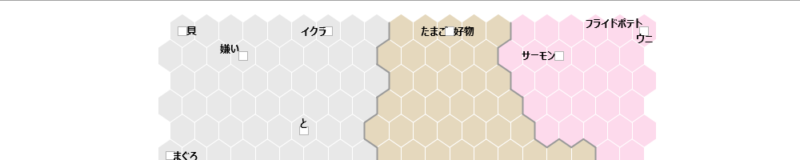
基本構造は散布図です。横軸がX、縦軸がYです。一番左端に縦に並んだ六角形の座標がX=ゼロ、最下段横に並んだ六角形の座標がY=ゼロです。六角形は横20個、縦20個、合計400個あります。はじめに設定した「1辺のノード数」が六角形の1辺の個数になります。
六角形は散布図のキャンバスを区切るマス目です。(六角形なのにマス目というのは変ですけれど)いわゆるキャンバスを400分割するメッシュです。
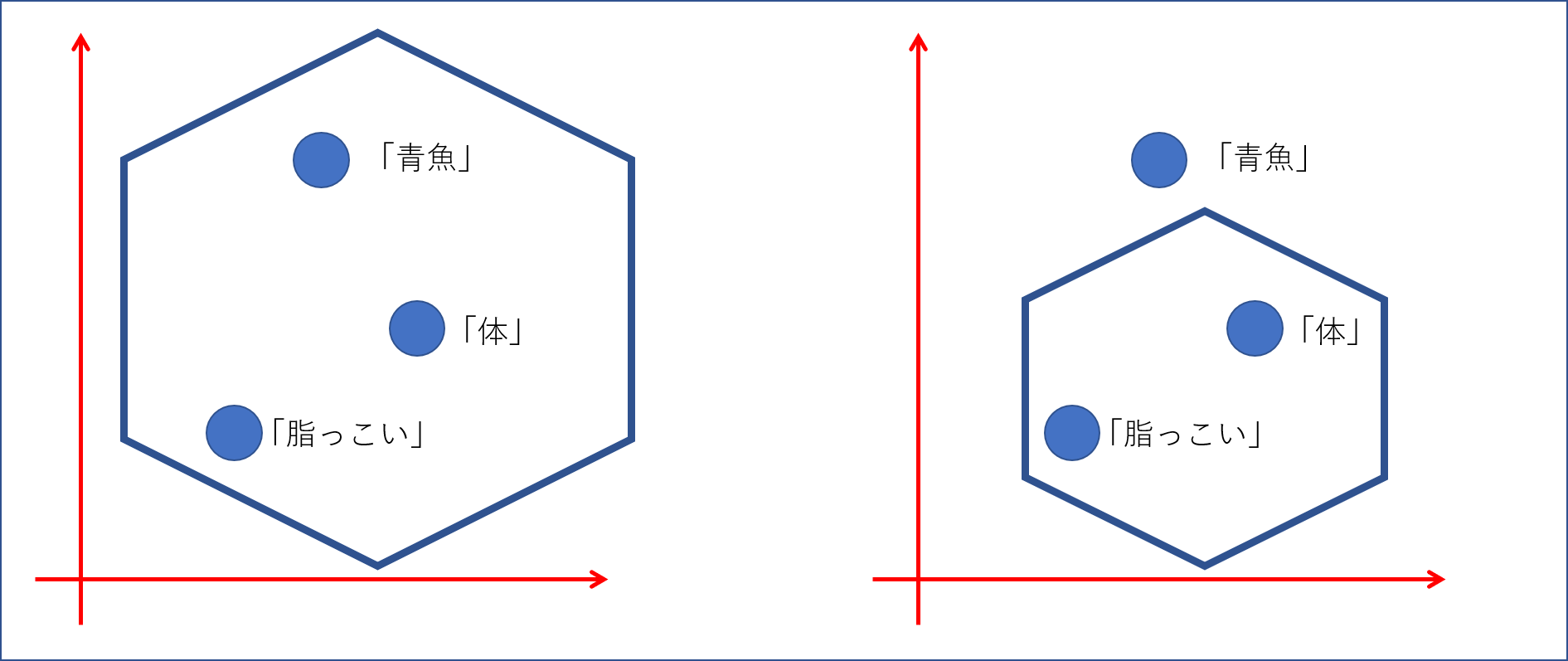
・右下「青魚」「脂っこい」「体」の3語が1つの六角形のなかにおさまっています。
六角形がメッシュであるというのは、画像のように「青魚」「脂っこい」「体」それぞれのXY座標が完全に一致していないときでも1つのメッシュの中に各「語」を入れこみます。
仮に1辺のノード数を増やしてメッシュを細かく(六角形の面積を小さく)するとしたら、例えば「青魚」は別の六角形にプロットされる可能性があります。逆に六角形の面積を大きくすると1つの六角形内にプロットされる「語」が増加する可能性があります。(対応分析を六角形ビンで描画する)
自己組織化マップの計算
データ
d
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12]
サーモン 1 1 0 1 0 0 0 0 0 0 0 1
サバ 0 0 0 0 1 0 1 0 0 0 1 1
イカ 0 1 0 0 0 0 1 0 0 1 0 0
サンマ 0 0 0 0 0 0 0 0 0 0 1 1
アレルギー 0 0 0 0 0 1 0 0 0 0 0 0
ウニ 0 0 0 1 0 0 0 0 0 0 0 0
ネタ 0 0 0 0 0 0 1 0 0 0 0 0
ハマチ 0 0 0 0 0 0 0 1 0 0 0 0
ブリ 0 0 0 0 0 0 0 1 0 0 0 0
貝類 0 0 0 0 0 0 0 0 1 0 0 0
好物 0 1 0 0 0 0 0 0 0 0 0 0
好き 1 0 0 0 1 1 1 0 0 1 0 0
苦手 0 1 0 0 0 0 1 0 0 0 0 1
嫌い 0 0 1 0 1 0 0 0 0 0 0 0
ダメ 0 0 0 0 0 1 0 0 0 0 0 0
まぐろ 1 1 1 0 1 1 0 1 1 1 0 0
イクラ 1 1 1 1 1 0 0 0 0 0 0 0
海老 0 0 1 0 0 1 1 0 0 0 0 0
たまご 0 1 0 0 0 0 0 0 0 0 0 0
つぶ貝 0 0 0 0 0 0 0 0 0 0 1 0
サラダ巻 0 0 0 0 0 0 0 0 0 1 0 0
ツナサラダ 0 0 0 0 0 0 0 1 0 0 0 0
フライドポテト 0 0 0 1 0 0 0 0 0 0 0 0
青魚 0 0 0 0 0 0 0 0 0 0 0 1
と 0 0 0 0 1 0 0 0 0 0 0 0
食べる 0 0 0 0 0 0 0 0 1 1 0 0
限る 0 0 0 0 0 0 0 0 1 0 0 0
固い 0 0 0 0 0 0 0 0 0 1 0 0
脂っこい 0 0 0 0 0 0 0 0 0 0 0 1
貝 0 0 1 0 0 0 0 0 0 0 0 0
体 0 0 0 0 0 0 0 0 0 0 0 1
鯛 0 0 0 0 0 1 0 0 0 0 0 0KHcoder側からRへ送っているのは、行=「語」、列=「段」、数値=出現回数、おなじみのデータです。
#dを加工します。lengは各「段」に出現する文字数(句読点を含む)です。
d < d / leng
d <- d * 1000
#行の合計値を取り出します。
d <- subset(d, rowSums(d) , 0)
#標準化します。
d <- scale(d)
#データの最終形はこのようになります。実際のデータは下へ全32行あります。
d
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12]
サーモン 1.7590091 0.7468760 -0.6026348 2.0963868 -0.6026348 -0.6026348 -0.6026348 -0.6026348 -0.6026348 -0.6026348 -0.6026348 0.2188065
サバ -0.6341852 -0.6341852 -0.6341852 -0.6341852 1.5860781 -0.6341852 0.9330595 -0.6341852 -0.6341852 -0.6341852 2.0301307 0.5242130
イカ -0.5504751 1.8456185 -0.5504751 -0.5504751 -0.5504751 -0.5504751 1.4227785 -0.5504751 -0.5504751 1.6858790 -0.5504751 -0.5504751Rの計算
rlen1 <- 1000 #autoにすると200000になります。 rlen2 <- 200000 #計算します somm <- som( d, n_nodes, n_nodes, topol="hexa", #六角形にします rlen=c(rlen1,rlen2) )
計算はこれだけです。
Rの計算結果
$code
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12]
[1,] -0.289586470 -2.895874e-01 -0.2793403534 -0.289587417 -0.289586778 -0.27964789 -0.283559338 3.157413606 -0.287864372 -0.289478815 -0.2895873726 -0.2895874132
[2,] -0.291126512 -2.911296e-01 -0.2638236154 -0.291129710 -0.291127516 -0.26731485 -0.275065865 3.122481583 -0.279046068 -0.290459030 -0.2911291142 -0.2911296564
[3,] -0.296958040 -2.969781e-01 -0.2077787561 -0.296978325 -0.296963366 -0.22209415 -0.244497891 2.919236986 -0.172884894 -0.290164311 -0.2969623967 -0.2969767468計算結果の列は12ですから「段」数です。ここでは3行だけを表示していますが、実際の行数は400行あります。
つまり、1辺のノード数の2乗(六角形の数量)が行数になります。1辺のノード数を10に設定すると100行になります。
12段×400行ですからエクセルのセル数でいうと4,800セルです。KHcoderインストール時に付属している「こころ」は1,215段あります。400行で486,000セルになります。1,000回学習すると、”数時間ないし数日を要する”のだろうと思います。
プロットする計算結果
$visual
x y qerror
1 16 18 0.61945369
2 14 4 0.61534922
3 12 13 0.29499911
4 15 0 0.38794530
5 0 8 0.07466252
6 19 19 0.13075905
7 15 9 0.48695729
8 0 0 0.02292505
9 0 0 0.02292505
10 7 0 0.10364673
11 11 19 0.10082840
12 4 12 0.79703309
13 19 9 0.33753584
14 3 18 0.60473047
15 0 8 0.07466252
16 0 14 0.65291469
17 6 19 0.74515956
18 2 5 1.01934851
19 11 19 0.10082840
20 13 0 0.55898220
21 8 9 0.09351105
22 0 0 0.02292505
23 19 19 0.13075905
24 19 1 0.01801312
25 5 15 0.89007374
26 8 4 0.36660991
27 7 0 0.10364673
28 8 9 0.09351105
29 19 1 0.01801312
30 0 19 0.72682512
31 19 1 0.01801312
32 0 8 0.07466252 1行目の「語」は「サーモン」です。
・「サーモン」をX=16(左端がゼロだから左から数えて17番目)
・Y=18(最下段がゼロだから下から数えて19番目)の六角形へ「サーモン」をプロットします。
$code.sum
x y nobs
1 0 0 3
2 1 0 0
3 2 0 0
4 3 0 0
5 4 0 0
6 5 0 0
7 6 0 0
#実際の計算結果は400行(六角形の数)あります。「nobs」が「語」の数です。X=0、Y=0の六角形内へは3「語」が入っているということになります。
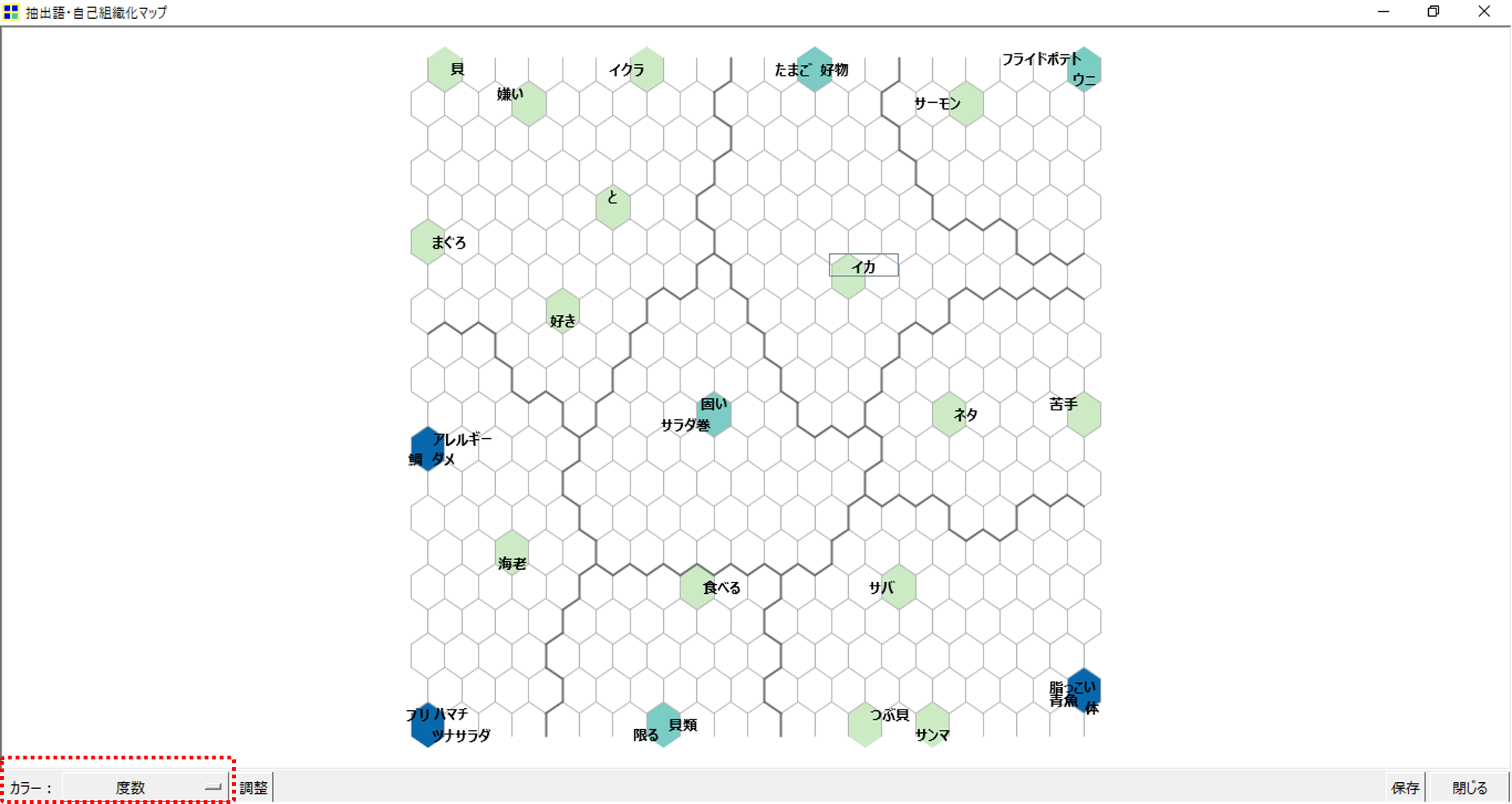
カラーを度数に変更しました。六角形の中に入っている「語」が多いほど青色が濃くなります。X=0、Y=0の六角形へは「ブリ」「ハマチ」「ツナサラダ」の3語が入っています。
>KHcoder 25. 自己組織化マップ(第2回)