
年次経済財政報告(経済財政白書)第2回
ピアソン相関係数を使い、タブローでKHcoder的なビジュアルを作成。それらしい感じのものができる。
全体的に俯瞰する
前回のVIZ
前回の投稿で、画像のように抽出語をフィルターすることで抽出語の出現回数が時間の経過とともにどのように変化するのかを確認することができました。
しかし、このような棒グラフで同時に抽出語の出現回数推移を確認することができるのはせいぜい2~3語です。
そこで今回は、抽出語の出現回数の時間軸変化を全体的にビジュアル化してみます。
タブローの動きが遅い
分析を開始する前にタブローの動きが遅くなってきているので改善します。
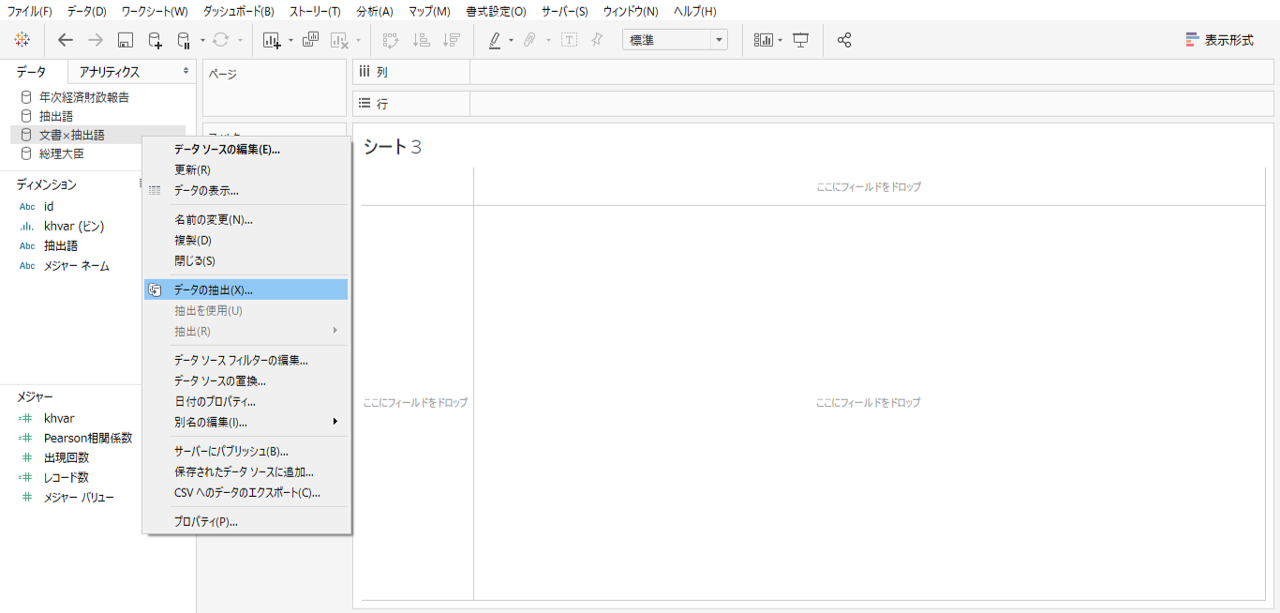
クエリに時間を要するのは「文書×抽出語」データソースへの接続状態に原因があるようです。
このデータソースは215,264行あります。もともとのエクセルデータソースの行数がこのくらいならノーストレスでサクサク動きます。現在の接続状態がピボットした結果215,264行になっているのでクエリに時間を要しているみたいです。
・データペインの「文書×抽出語」を右クリックします。
・データの抽出を選択してhyper形式で保存します。
これで抽出したデータに接続した状態になります。
データ抽出は、データを抽出するのと同時に接続を抽出データへ切り替える機能です。ですから抽出データへ接続しているときに元データソースを変更・修正してもタブローへ変更が反映さることはありません。元データソースを変更したときは抽出を更新します。
「年次経済財政報告書」データへは分析対象テキスト全文が文字列で入っているのでこちらも抽出すると動きが早くなる可能性があります。やってみるとサクサク動くようになりました。
Pearson(ピアソン)相関係数
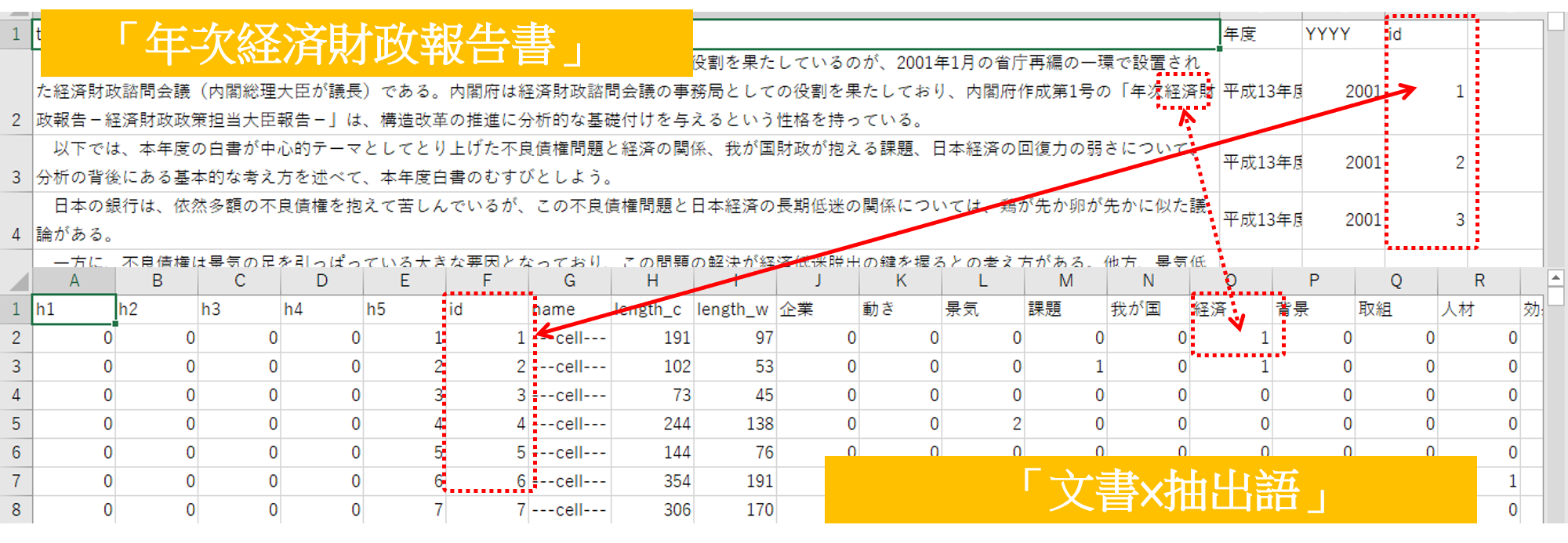

ここまで使用してきたデータソースの構造を確認します。
データソース「年次経済財政報告書」(分析対象テキスト)と「文書×抽出語」の各idが完全に一致するようにできています。このidで2種類のデータソースをデータブレンドできる仕組みになっているわけです。さらにidには別の役割があります。
抽出語の出現回数を変数1、id(数値)を変数2に設定してPearson相関係数を計算します。
このようにidは変数として利用することができます。Pearson相関係数がマイナスが大きければ2001年度寄りに出現回数が多い抽出語、プラスが大きいと2019年度寄りに出現回数が多い抽出語になるはずです。
手法はKHcoder共起ネットワーク(共起パターンの変化を探る)と同じです。
タブローで計算
・id(現在は文字列になっている)を複製します。
・データ形式を数値(整数)へ変更してメジャーへ移動します。
1~434(段落数と同じ)までの整数メジャーができました。これでidを変数として扱うことができるようになります。
・名称をKHcoderと同様に「khvar」にします。
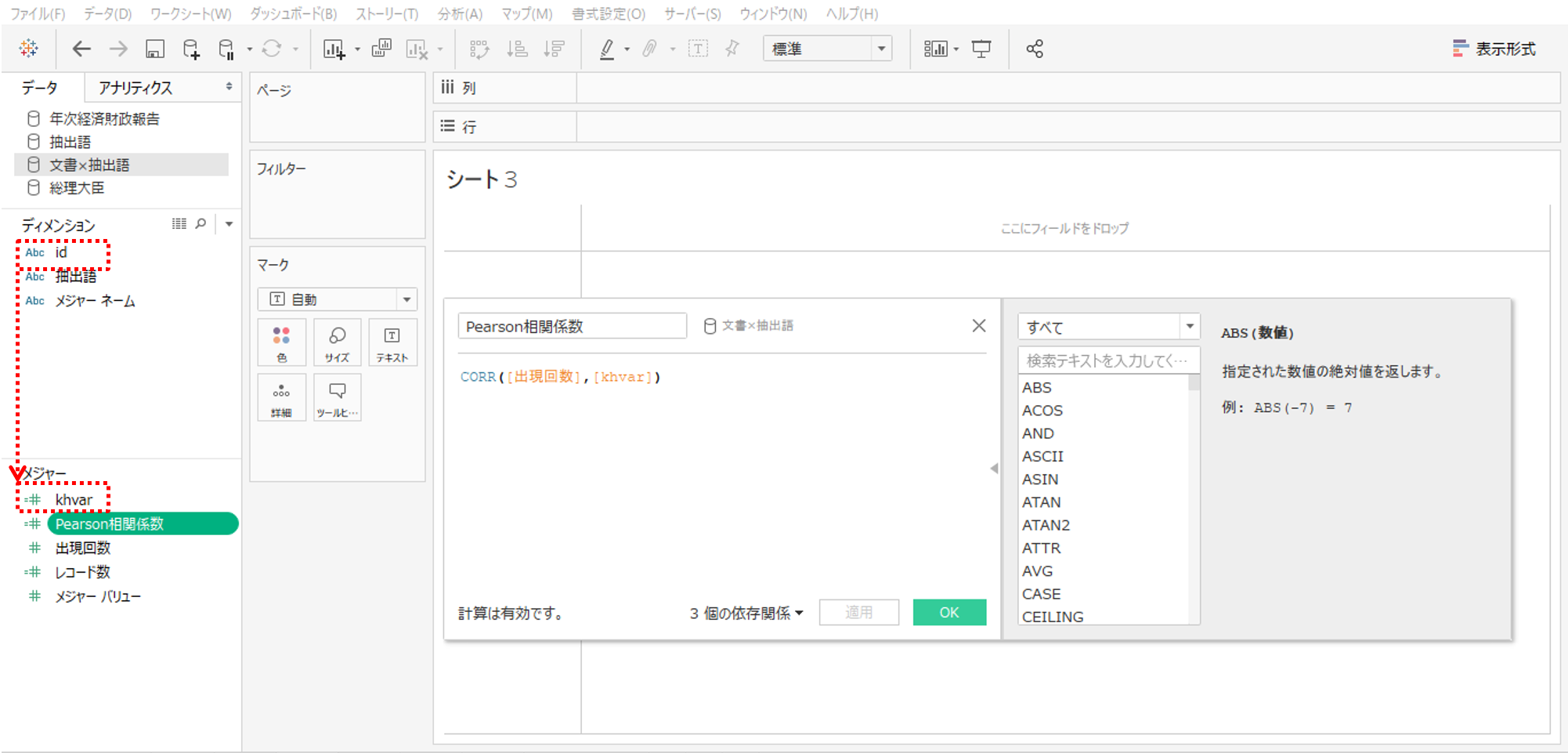
・Pearson相関係数を計算します。
#Pearson相関係数を算出するタブロー計算式 CORR([出現回数],[khvar])
・操作するデータソースは「文書×抽出語」です。
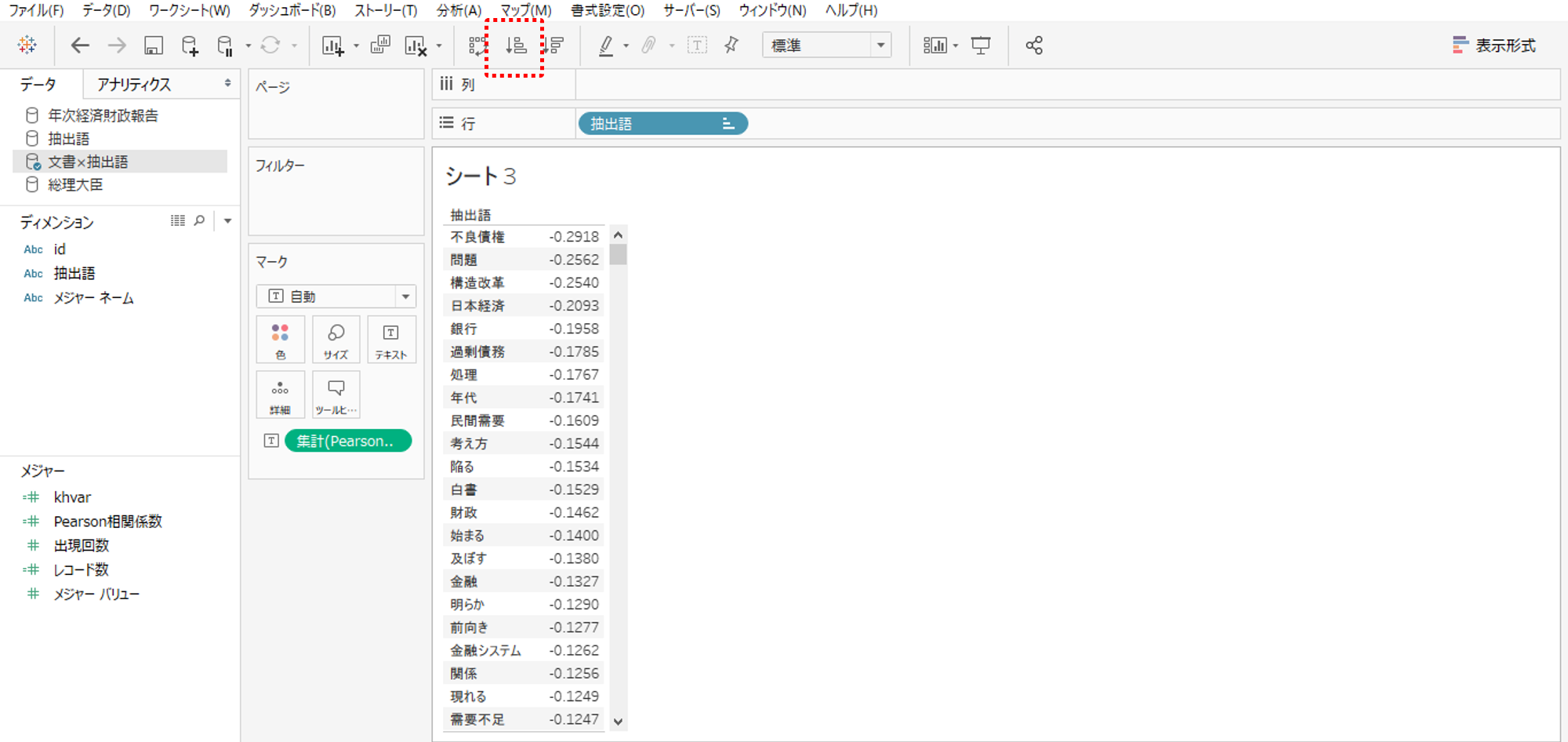
・抽出語を行シェルフへドロップして
・Pearson相関係数をラベルへ入れます。
・昇順で並べ替えると2001年度寄りの抽出語から順番に並びます。
VIZを作成
ハイライト表
ハイライト表をつくります。ハイライト表はデータポイントを比較するときに便利な機能です。主に色の色相の変化とコントラストで表現します。
・データソースは「文書×抽出語」のままです。
・抽出語を行シェルフへドロップします。
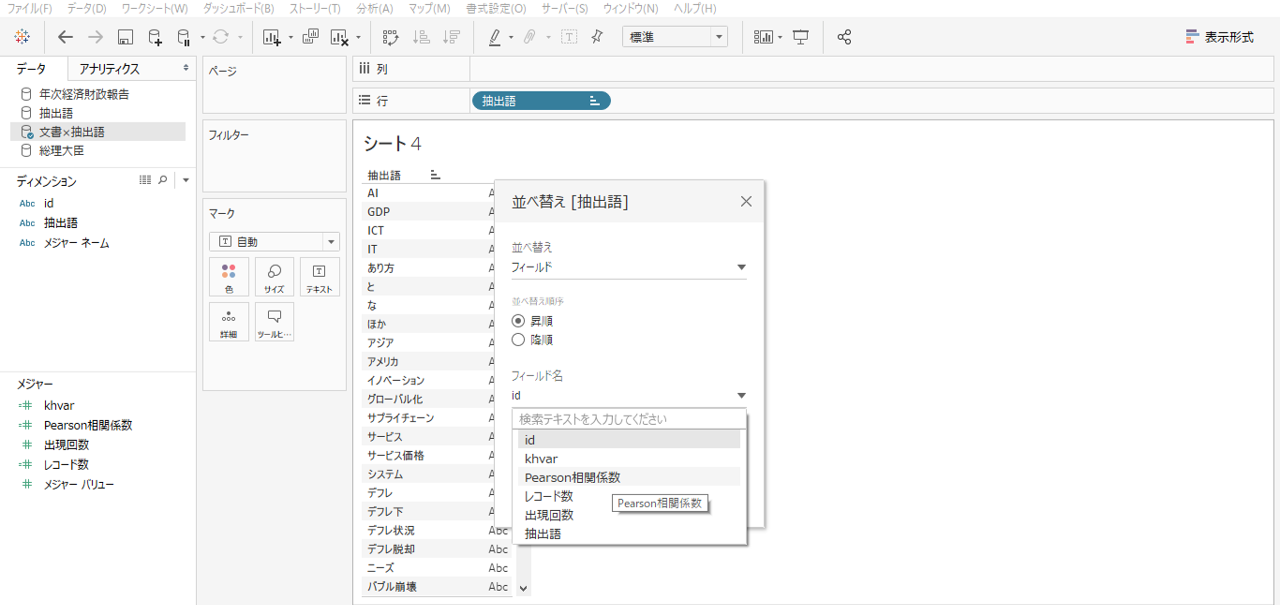
・右クリックして並び替えを選択します。
・並び替え順序を昇順、フィールド名からPearson相関係数を選択します。
これでシート3と同じ状態が出来上がります。
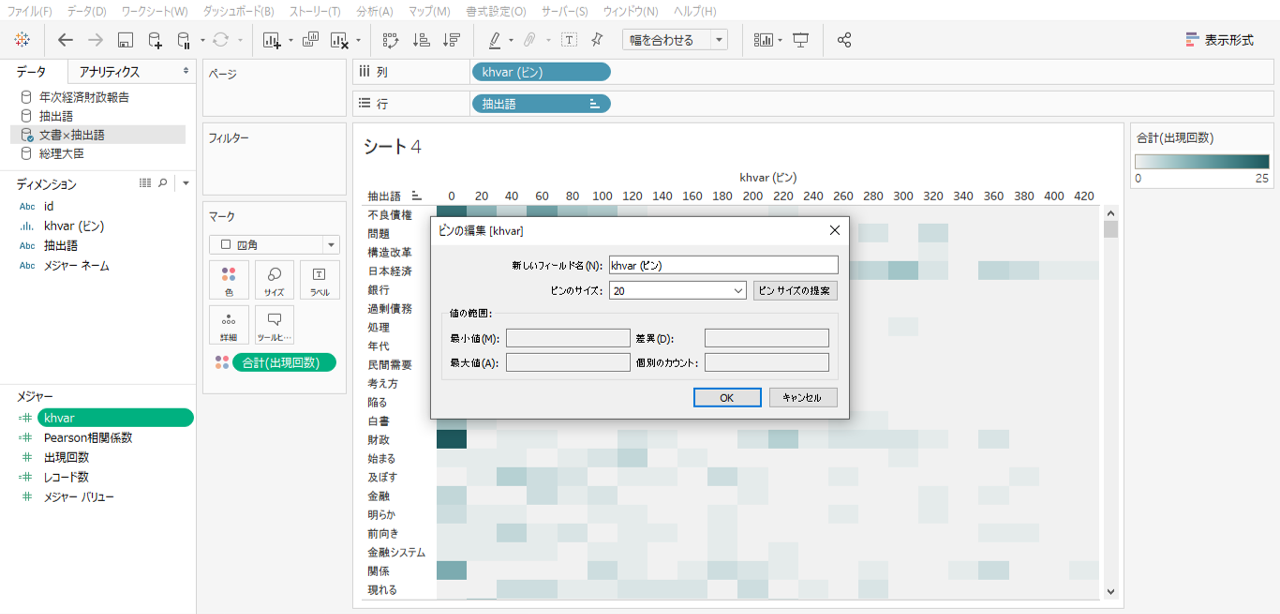
・メジャーのkhvarを右クリックしてビンを作成します。
・ビンのサイズは20にしました。
タブローのビン作成機能はほんとうに便利です。例えば顧客属性の年齢を5歳ごとにまとめるとか、10歳ごとにまとめ方を変更するとかの作業があっという間にできます。ビンは、レコード数の分布を確認できるヒストグラムの軸に利用します。
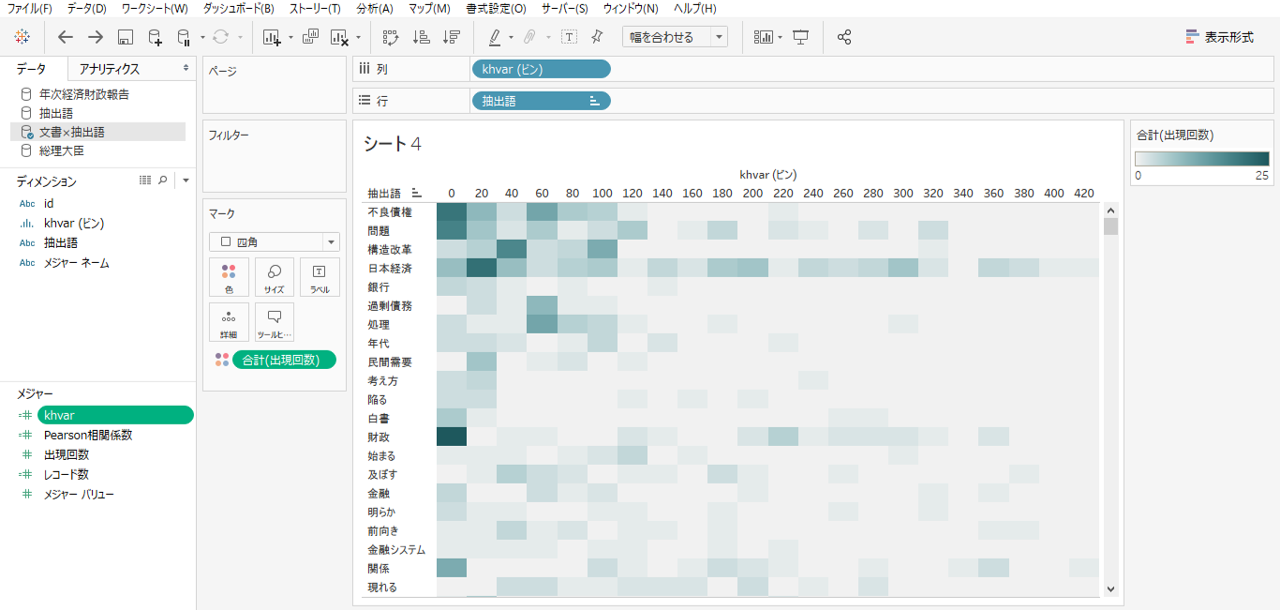
・khvar(ビン)を列シェルフへ
・出現回数を色へドロップします。
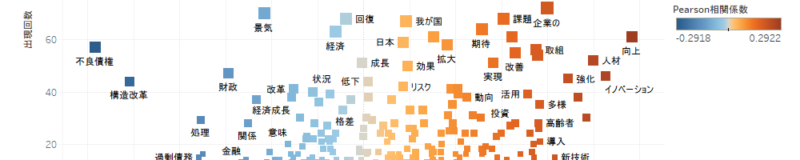
Pearson相関係数のマイナスが大きい抽出語ほど左側が濃くなります。
データの分布を色で表現した一種のヒストグラムです。お好みで出現回数をサイズへ設定してください。ただし今回のデータのように各ビンの中身にゼロが多いときはサイズよりも色を工夫したほうが見やすくなります。デフォルトの色設定ではゼロ値が薄いブルーになるため、色の分化でゼロ値が薄いグレーになるように設定しました。
散布図
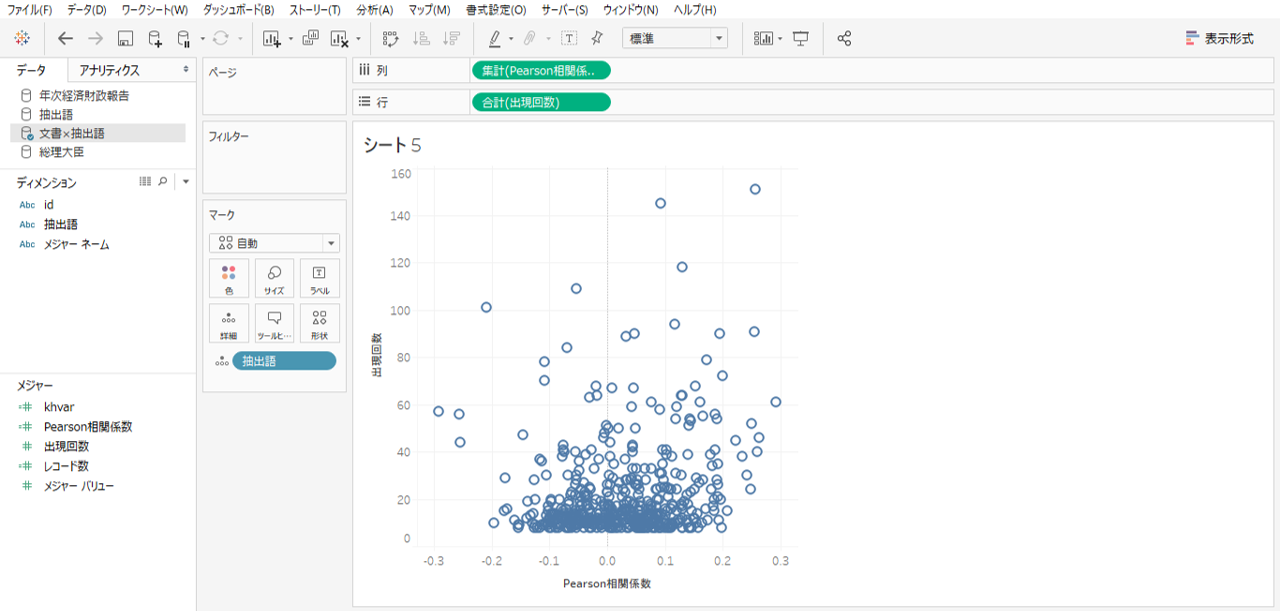
・データソースは「文書×抽出語」です。
・Pearson相関係数を列シェルフへ
・出現回数を行シェルフへドロップします。
Pearson相関係数により左側に昔の抽出語、右側に最近の抽出語がプロットされます。
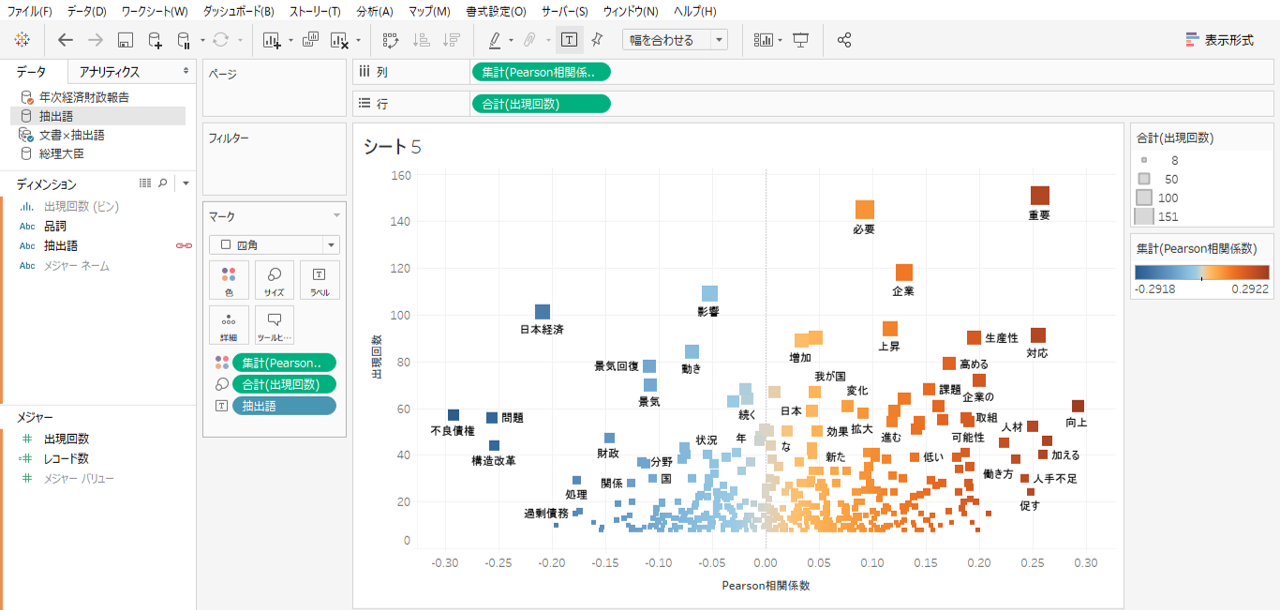
・Pearson相関係数を色へドロップします。
・KHcoderに倣いプラスをオレンジ、マイナスをブルーにします。
・サイズを出現回数
・形状は四角です。
抽出語の品詞をフィルタリングします。ある程度の客観性が求められるようなレポートの場合は名詞系の抽出語に注目すると見やすくなります。
・「名詞」「サ変名詞」「固有名詞」「地名」「未知語」「タグ」を選択しました。
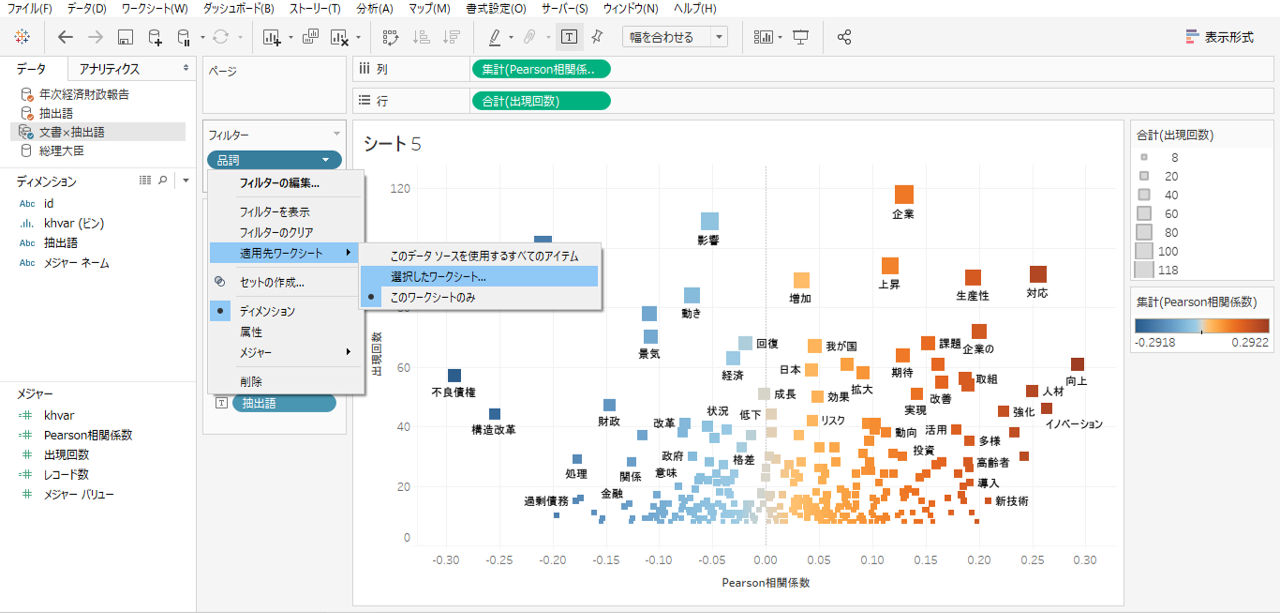
・先に作成したシート4にも同様のフィルターを適用します。
ダッシュボード
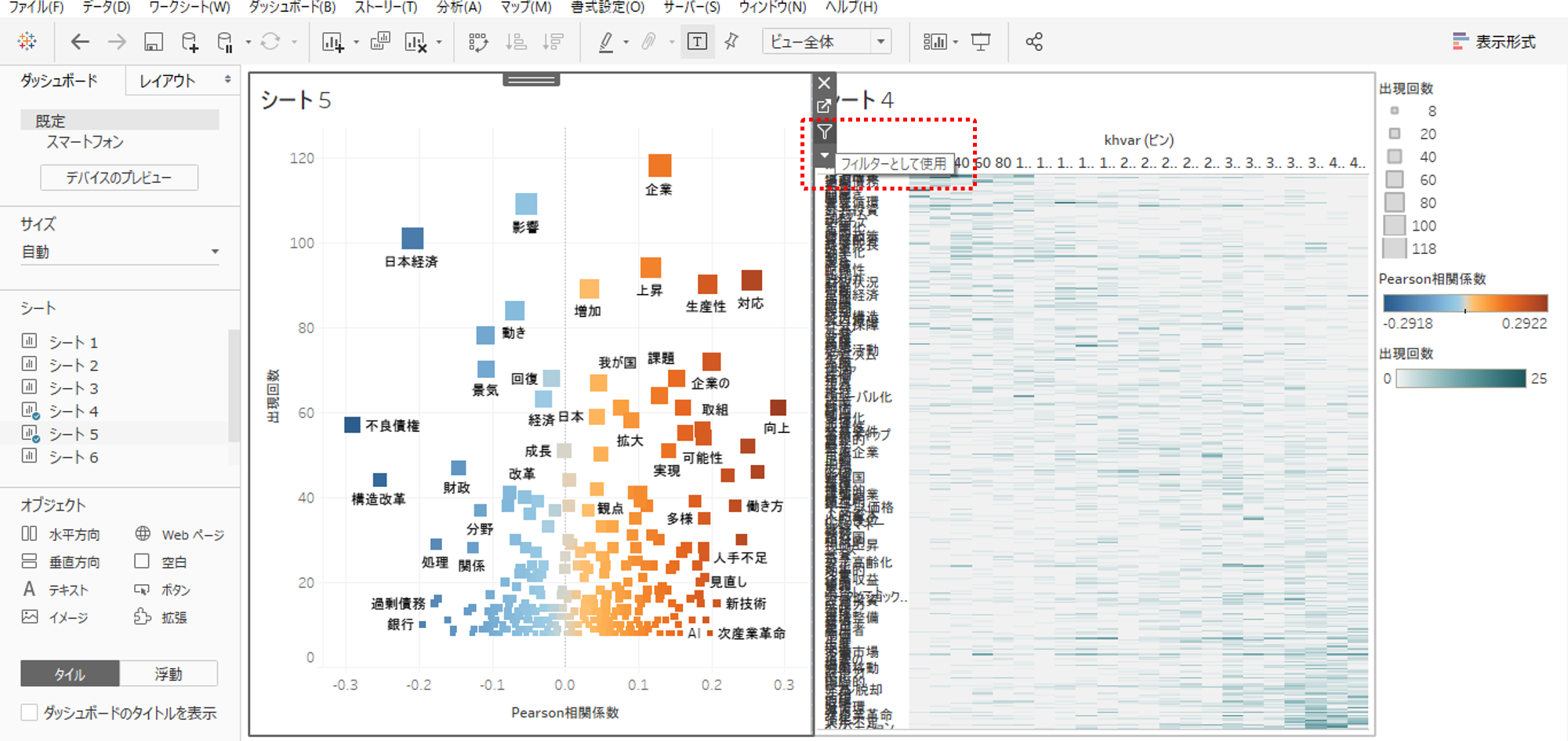
・シート5とシート4をダッシュボードへ入れます。
・シート5からフィルターアクションを追加します。
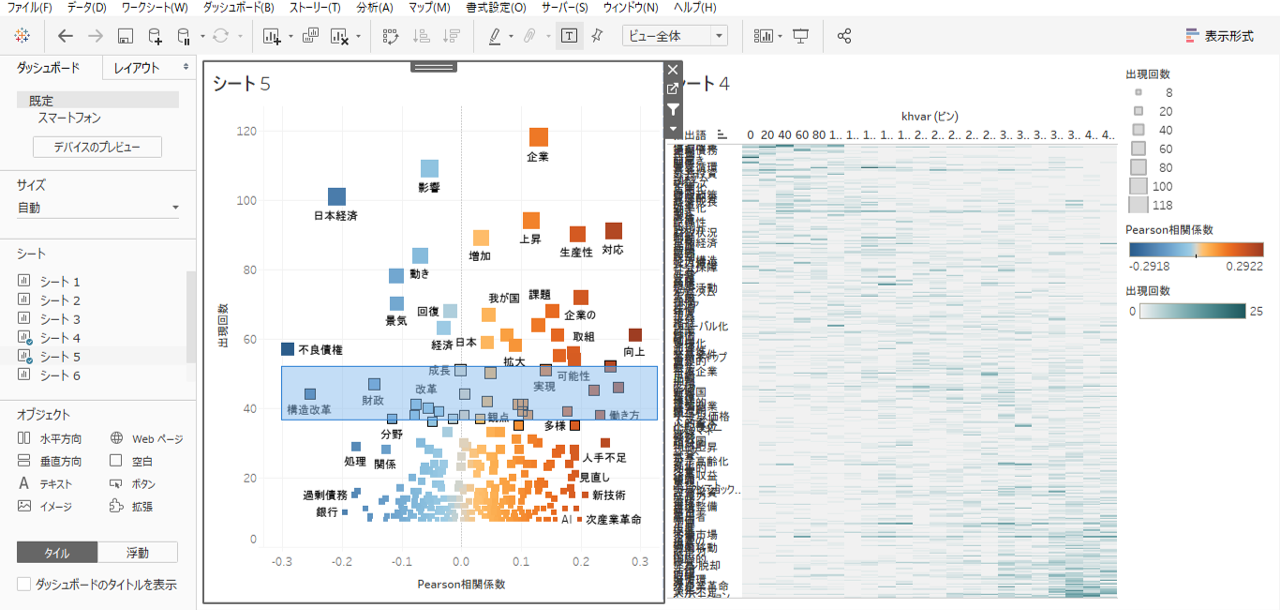
・出現回数40回くらいのところを横に長く範囲を選択してみましょう。
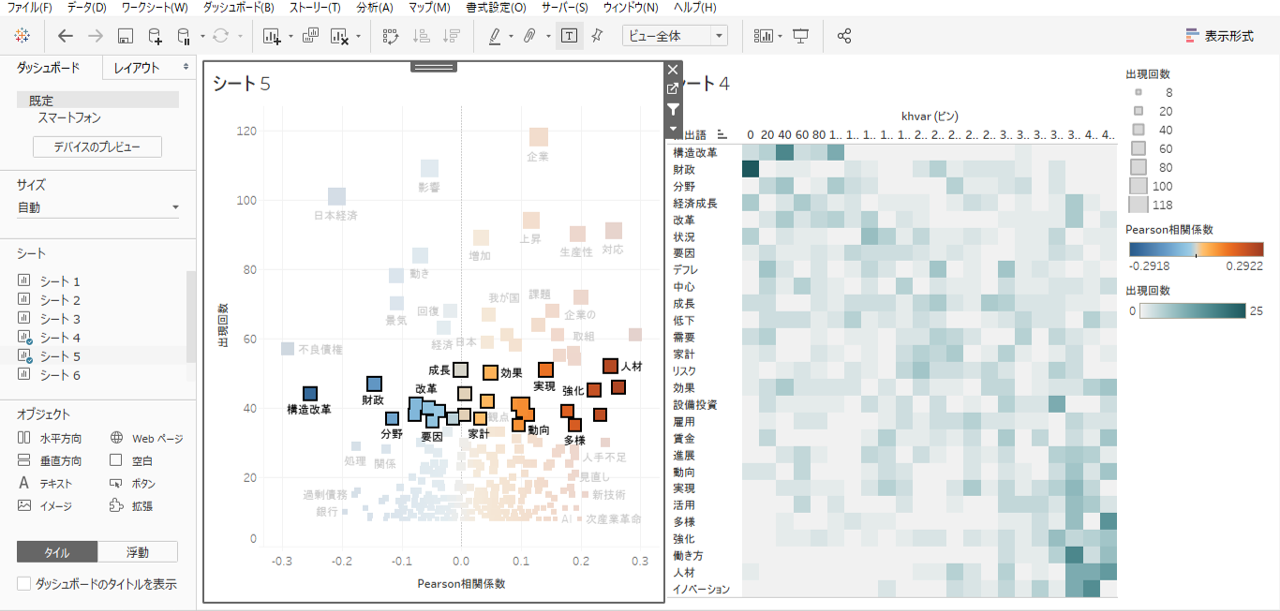
時間軸に沿って出現する抽出語の概要が見えてきたような感じです。
>年次経済財政報告(経済財政白書)第1回
>年次経済財政報告(経済財政白書)第3回
>年次経済財政報告(経済財政白書)第4回