

データ表の形式 (列指向形式発展型)
データ分析しやすい列指向形式ですが、弱点もあります。データ編集方法と分析のときのポイントを解説しています。
列指向形式の弱点
2種類以上の値があるとき

データをグラフ化するときに列指向形式の方がクロス集計形式よりも圧倒的に勝っていることがわかりました。しかし、列指向形式にも弱点があるのです。
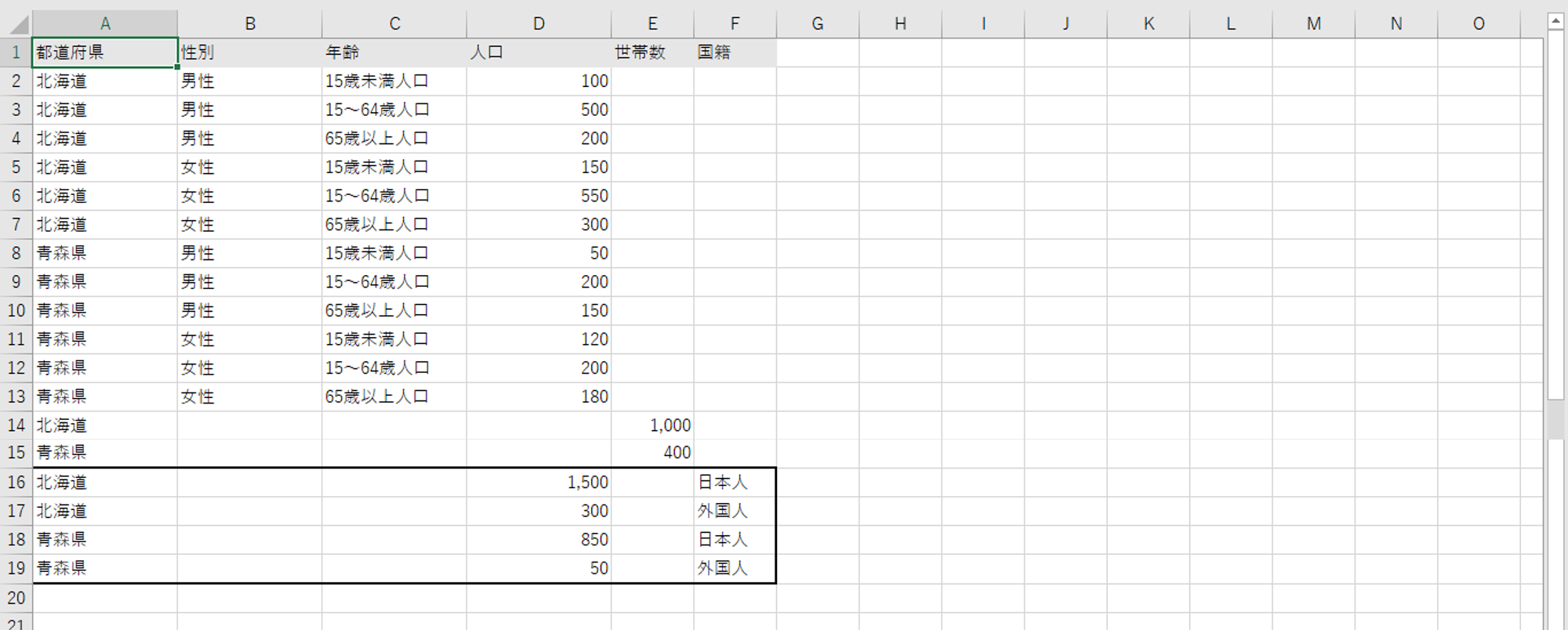
前回のクロス集計形式へ画像のように「世帯数」と「国政の別-日本人・外国人」を追加しました。クロス集計形式では各値がきっちりとおさまっています。
さて、このクロス集計形式のデータ表を列指向形式へと変換してみます。
どこのセルへ値を入れるのか
人口の単位は「人」です。世帯数の単位は「世帯」ですからから人口の列へ世帯数を入れこむことはできません。
従って「世帯数」の列を新規で追加することになります。

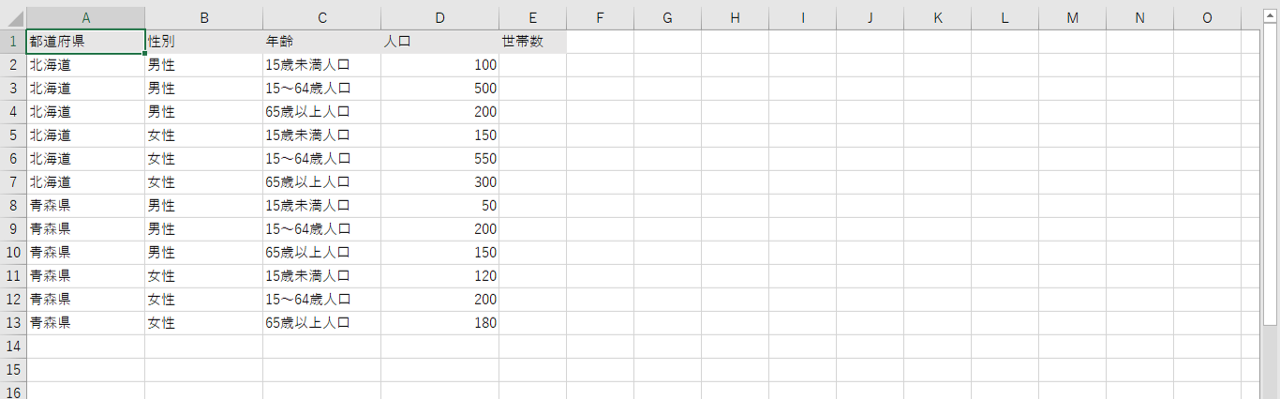
では?どこの行へ値を入れるのでしょうか。性別ごと、あるいは、年齢ごとの世帯数データ値はありません。わかっているのは都道府県の別だけです。
E列の入れ方もF列の入れ方も不正解です。
E列のように追加すると都道府県で世帯数を集計したときに実際の6倍の世帯数になります。
F列のように追加すると北海道の男性の15歳未満の世帯数が1,000世帯あるような集計が可能になってしまいます。
列指向Mix形式
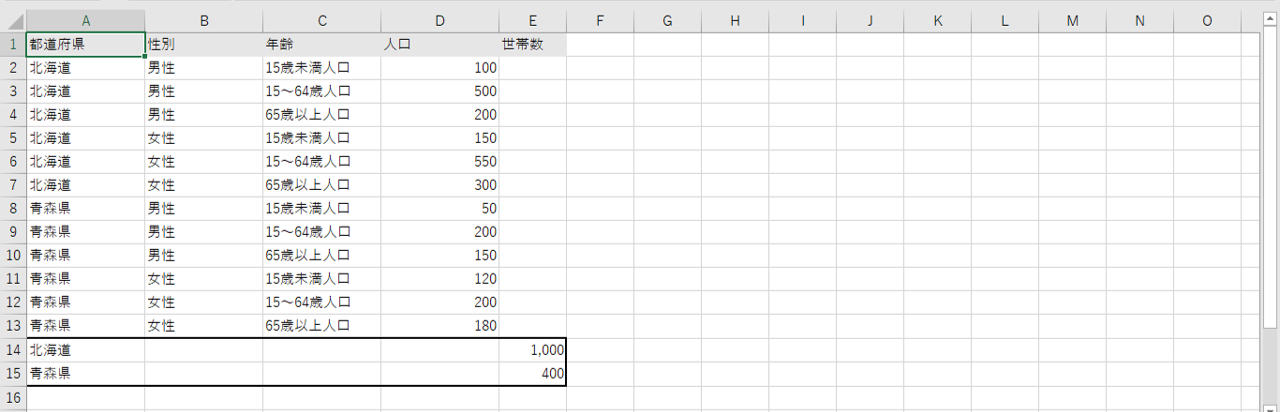
画像のように都道府県の行を追加します。世帯数に性別・年齢の別はいずれにもないので、性別列・年齢列のセルは空白(null)です。
人口列は違う値ですから空白(null)です。追加した「世帯数」の列と都道府県の行がクロスするセルへ値を入れます。「世帯数」列と性別&年齢行がクロスするセルは空白(null)です。
列指向形式にクロス集計形式をくっつけたような形式になるので、個人的に列指向Mix形式と名付けています。見た目がさえない・・・確かにこの表の弱点です。
グラフ化すると
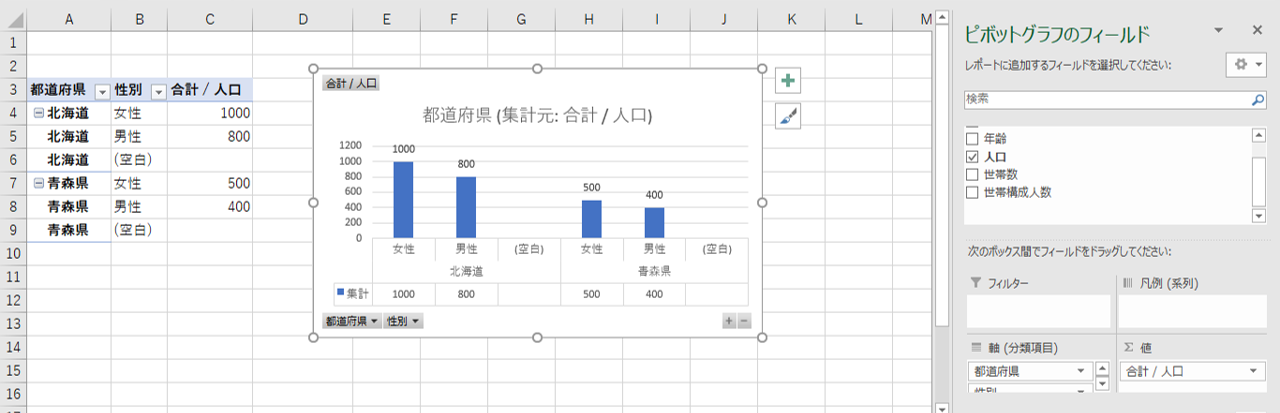
都道府県ごとに男性・女性別の人口棒グラフをピボットグラフで作成します。新規追加した世帯数は使用しません。
横軸に空欄(null)が表示されます。データ表の性別列へ空欄(null)があるためです。年齢を横軸にしたときも同様です。
列指向Mix形式では、分類項目(ディメンション)の列に空白(null)が発生するから、常にフィルターかスライサーで空欄(null)を非表示にする手間がかかります。これが弱点です。
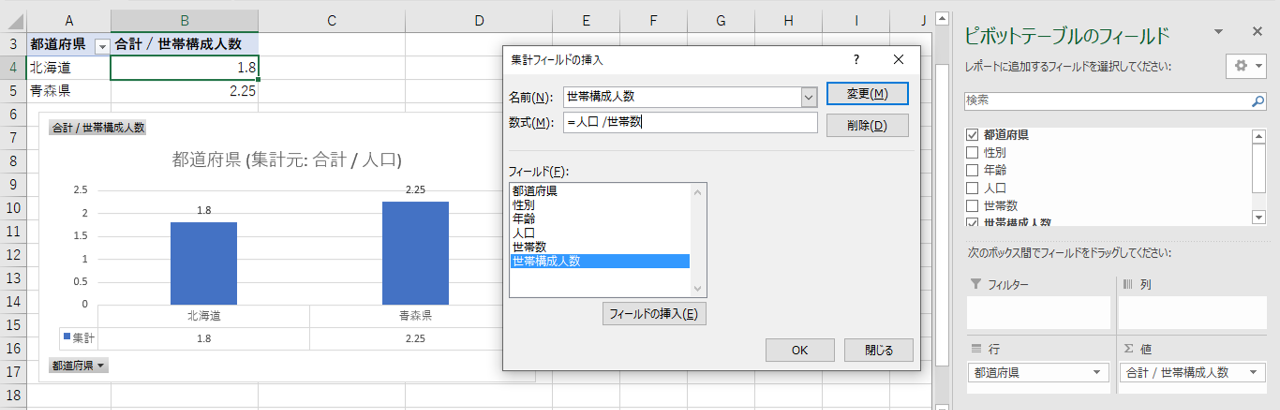
このようにピボットで計算フィールドを作成することができるので、列指向Mix形式には弱点があるものの、分析においては利便性が高い形式であることがわかると思います。
さらに追加
国籍の別を追加
この表へ国籍の別を追加します。
クロス集計形式なら、このようになります。
国籍の別の列を追加、値は人口だから人口の列へ値を追加するのは残念。これでは、都道府県ごとに人口を集計すると実際の2倍の値になります。
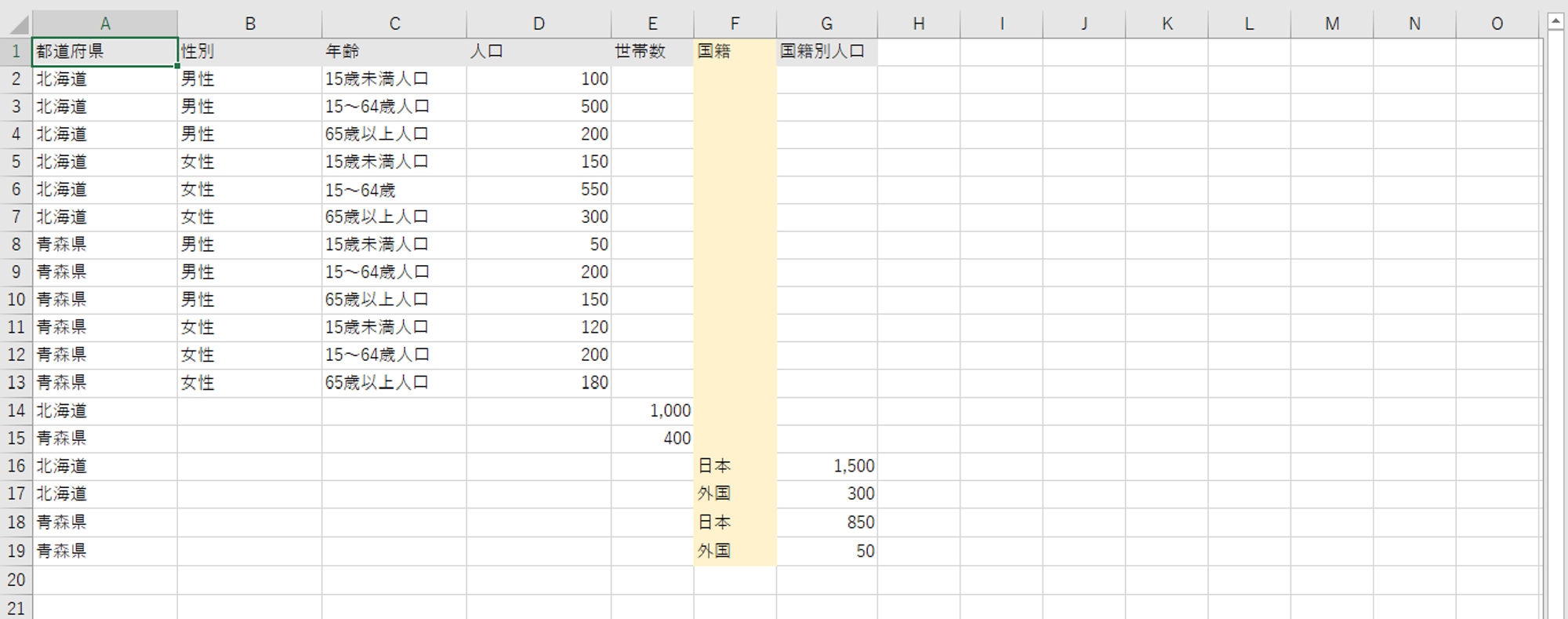
値の列を新規追加します。「国籍別人口」としました。
グラフ化すると

今度は値の空欄(null)があらわれます。国籍をフィルターして空欄(null)を除外する必要がありますね。
Mixしすぎるとややこしくなる
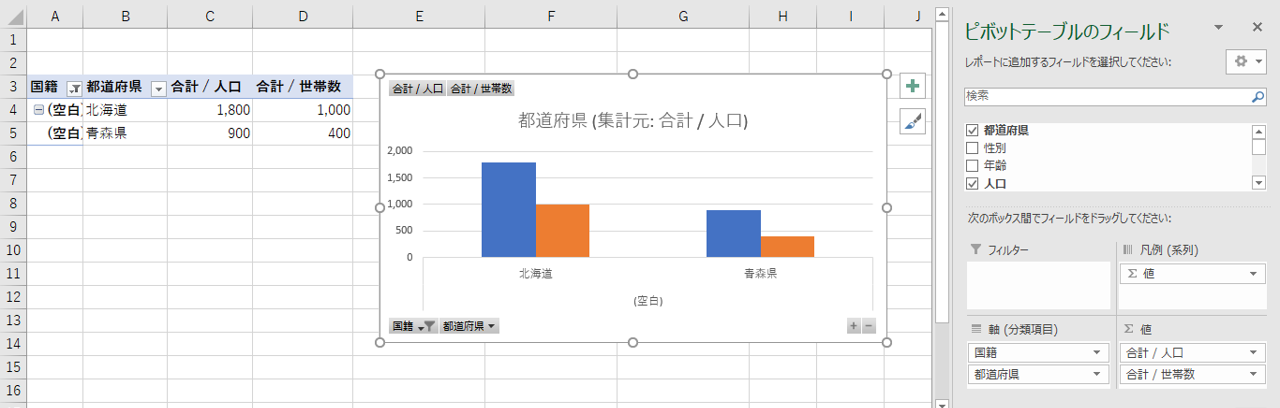
画像のように「都道府県」と「国籍」を軸に設定して「人口」と「世帯数」を集計します。
「国籍」軸は空欄(null)だけを示します。なぜ「国籍」は空欄(null)だけになるのでしょうか?国籍の別の「人口」・「世帯数」のセルが空欄だからです。当たり前ですね。値にたいするディメンションの粒度が異なるからです。
つまり、「国籍」を軸に設定したときは「国籍別人口」の値だけが有効、「性別」を軸に設定したときは「人口」の値だけが有効だということを理解して記憶しておかなければならないといえます。
従って多くの表を次々にくっつけて項目と値が増えすぎるとわけが分からなくなります。なるべく関係性が高い項目と値に限ってまとめることをオススメします。