
食中毒統計調査 Tableau Prepでデータを整える
タブロープレップのデータインタープリター機能で複雑な構造になっているデータ表を分析しやすいように整えます。
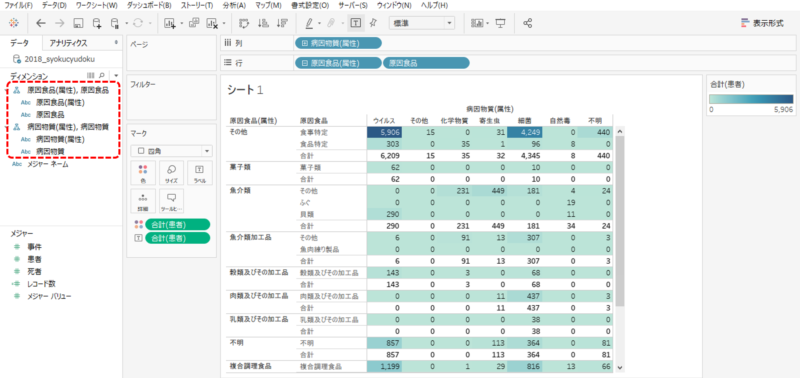
食中毒統計調査 表4
データ出典
政府統計の総合窓口 e-Stat
https://www.e-stat.go.jp/
食中毒統計調査 / 令和元年食中毒統計調査
表4
(こちらから詳細確認・ダウンロードできます)
もとデータの列名の構造に課題があります
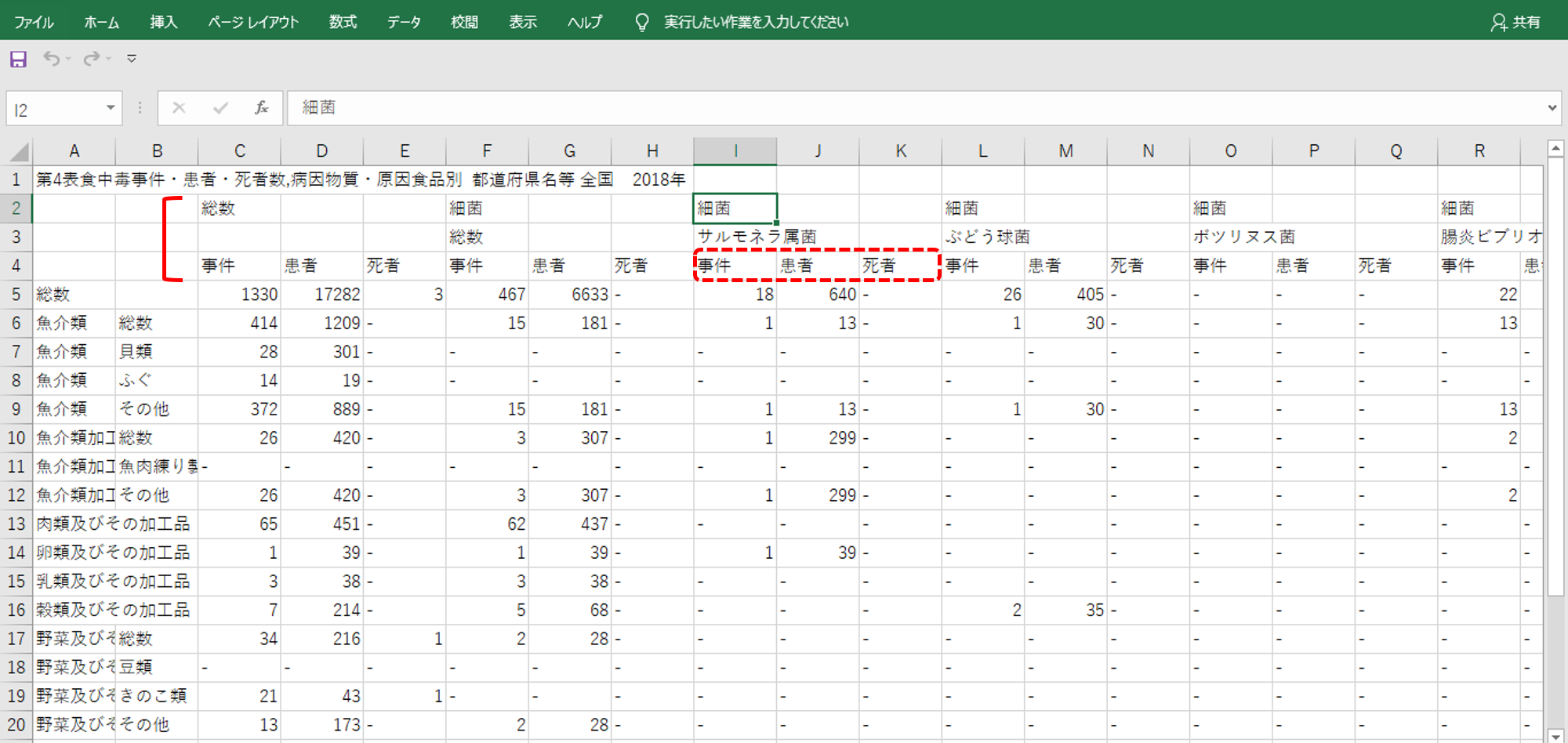
データはエクセルで画像のようになっています。
A列とB列が分析の項目(ディメンション)です。「魚介類」の「貝類」、「魚介類」の「ふぐ」、粒度にしたがった階層になっています。
列名が3行にわたって付与されています。
「サルモネラ属菌」のところで説明すると、
・2行目
「サルモネラ属菌」が「細菌」であることを示します。「細菌」のほかに「ウイルス」「寄生虫」「科学物質」などの列名があります。
・3行目
「サルモネラ属菌」「ぶどう球菌」にように具体的な病因物質名です。2行目よりも細かい「粒度」になっているわけです。
・4行目
「事件」「患者」「死者」にわかれています。これはメジャー(Σ)です。
表から「魚介類」の「貝類」の「細菌」の「サルモネラ属菌」の食中毒事件はゼロです。このようにデータ読むことができます。表の数値を目で追いながら「読む」ことは可能です。小計・総計も記載があるのでよく読めます。
ところが、この表からグラフのようなビジュアルを作成しようとするとどうでしょうか?
ディメンションとメジャーを明確化する
もとデータからグラフを作成しようとするときの最大の課題はC列以降の列にディメンションになる「原因物質」が2行にわかれて記載されていること。それに、メジャーになる数値項目がくっついてクロス集計されていることです。
一言でいうと、列名が3行にわたって付与されているところを直す必要があります。
最終的にはこのようなデータ表へ編集します

画像のように、
・原因食品(2列)に対して原因物質を2列、列指向形式でくっつける。
・「事件」「患者」「死者」がそれぞれメジャーになるように列をつくりクロス集計する。
これでOKです。
タブロープレップの手順
エクセルを少し加工する
タブロープレップのデータインタープリター機能を使用してデータへ接続するのですが、さすがに、はじめの画像のような状態ではうまく接続できません。すこしだけエクセルを加工します。
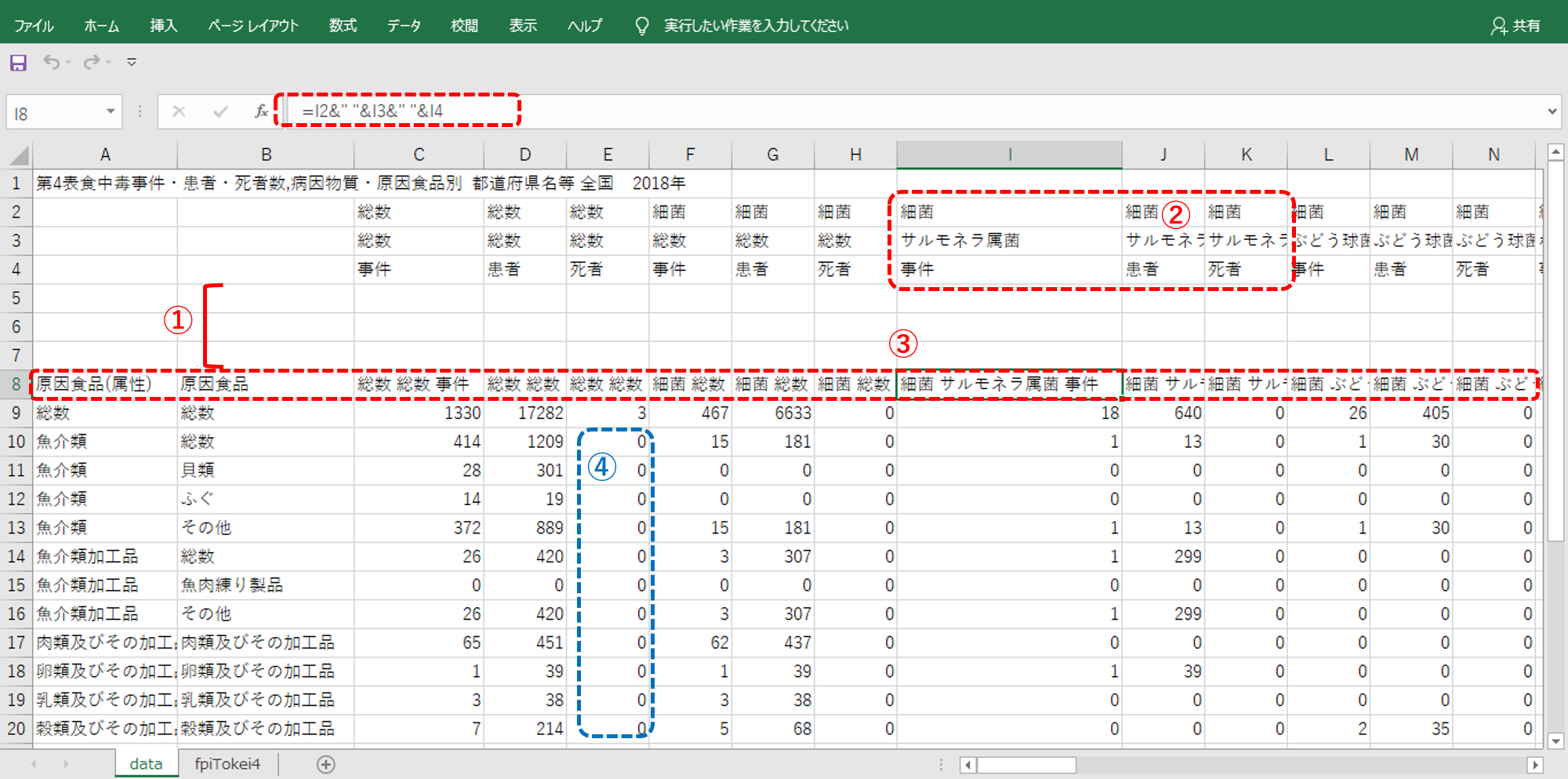
<① 空白行を挿入する>
データインタープリターはエクセル・CSVファイルの1枚のシートのなかに複数存在する表へそれぞれ個別に接続する機能です。
データインタープリターは、それぞれの表の間にある程度の空白セルを認識して「個別の表」だとみなします。経験的に空白セルの数は行・列ともに3個くらいあったほうが良いような感じです。
・もとデータの3行に分かれた項目名の下に空白行を挿入して、8行以下の表がひとつのデータ表でることをタブロープレップへ認識させます。
<② 空白セルをうめる>
・もとデータのJ2、J3は空欄でした。ここの空欄を埋めます。
この作業はあたらしい列名をつくるための準備です。
<③ あたらしい列名をつくる>
・2列目、3列目、4列目の列名をすべてくっつけます。
・エクセルの演算子は「&」です。
・半角スペース「” “」を入れます。「”-“」のような記号でもかまいません。
<④ NULLを0(ゼロ)に置き換える>
もとデータには「-」が入っています。このままタブロープレップで接続すると「-」はNULLに置換されます。これは便利な機能なのですが、ちょっと困ることも発生します。
タブロープレップは列に対する行データがすべてNULLのとき、その列自体を自動的に削除してしまうことがあります。
・エクセルの「検索と置換」機能を使い「-」を0(ゼロ)に置換します。
タブロープレップから接続
<データインタープリター>
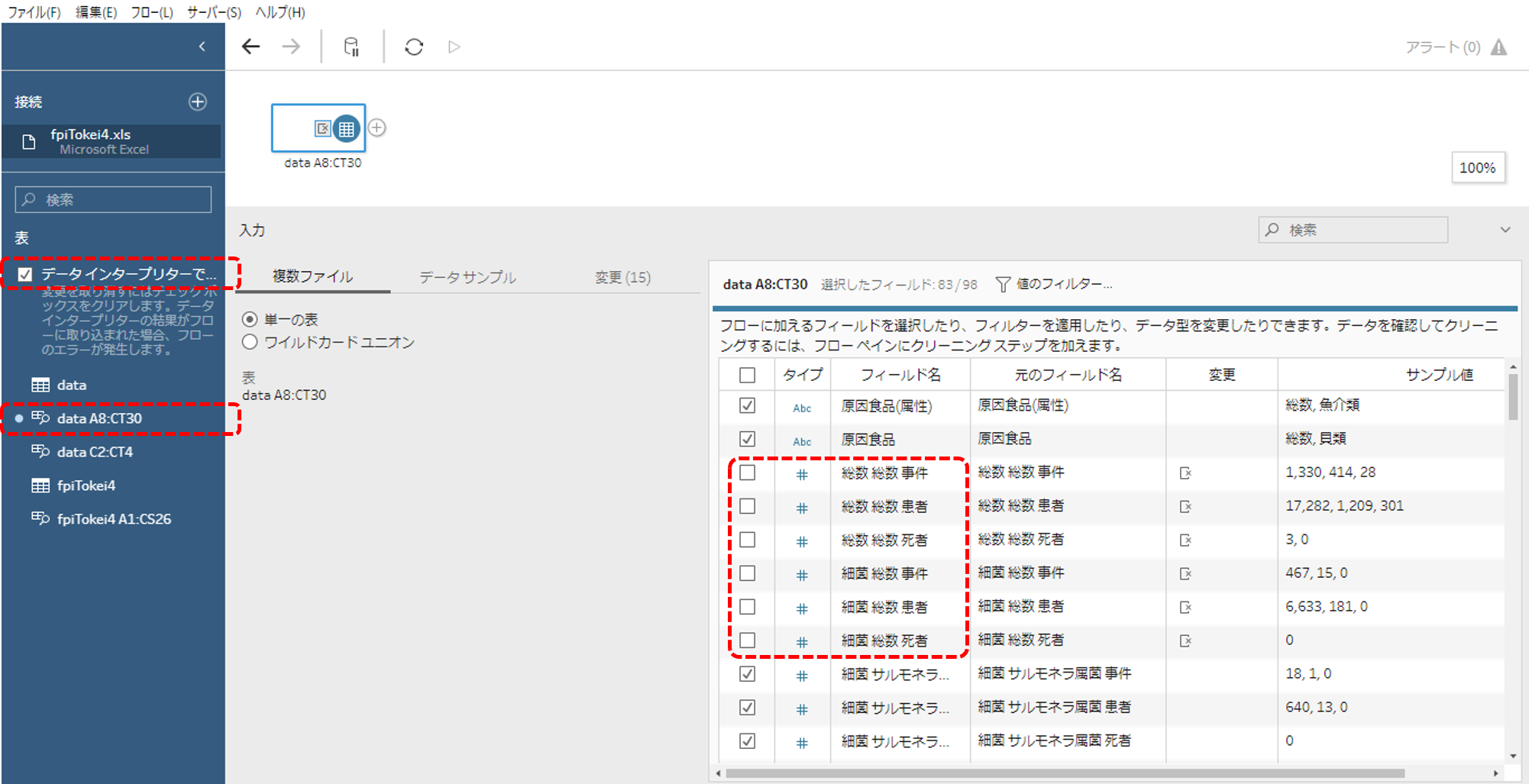
・データインタープリターをチェックします。
A8以下の表をデータ表として認識してくれています。
・A8~の表をドロップします。
・「総数」のチェックを外します。
「総数」の文字が含まれている列は、小計・合計の列です。分析には不要なのでチェックを外します。
<データをクリーニングする>
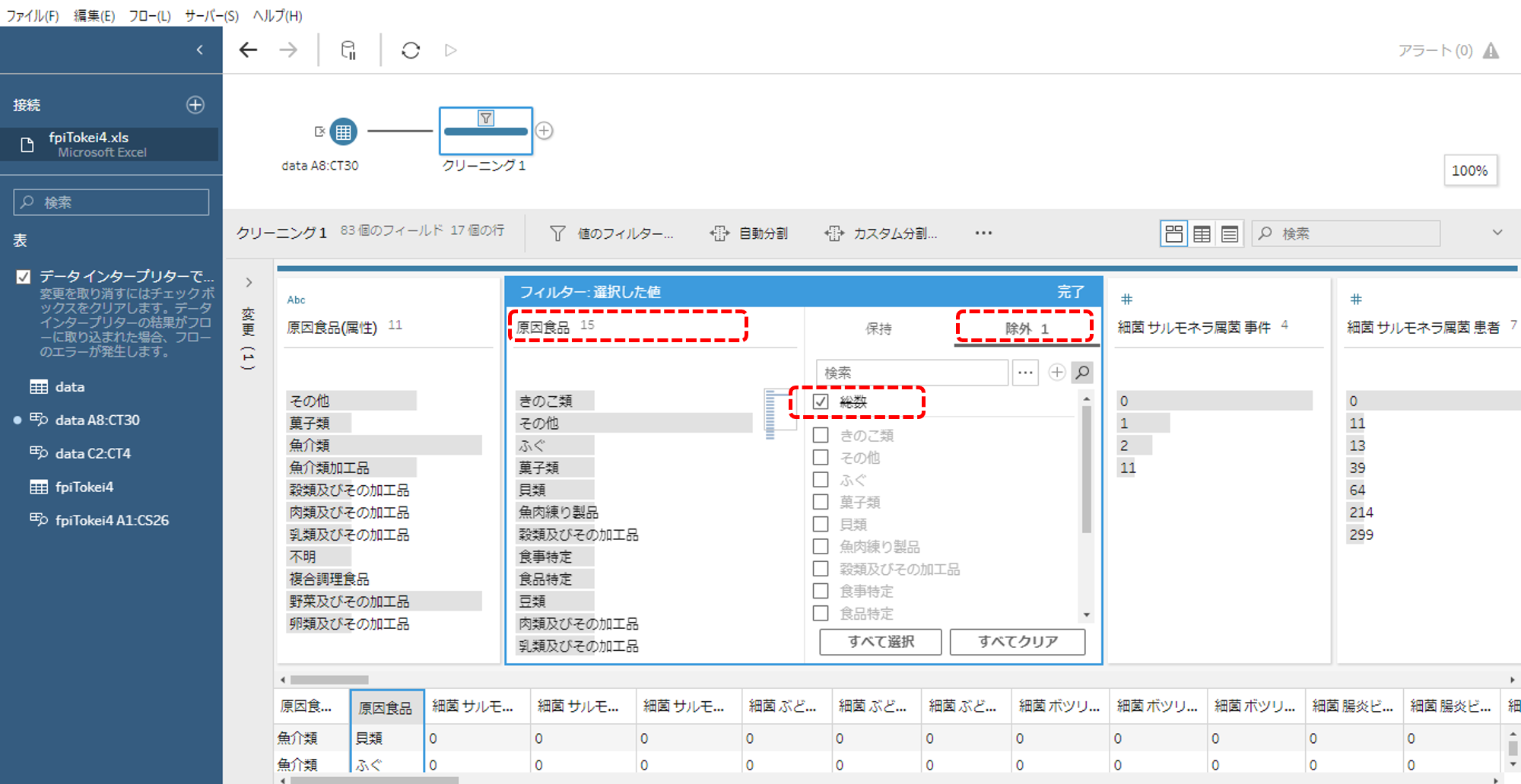
・クリーニングステップを挿入します。
・「原因食品」の「総数」をフィルターで除外します。
BIツールで分析する際に、「総数」や「合計」・「小計」のような行・列は不要です。
<ピボットして列指向形式へ変換する>
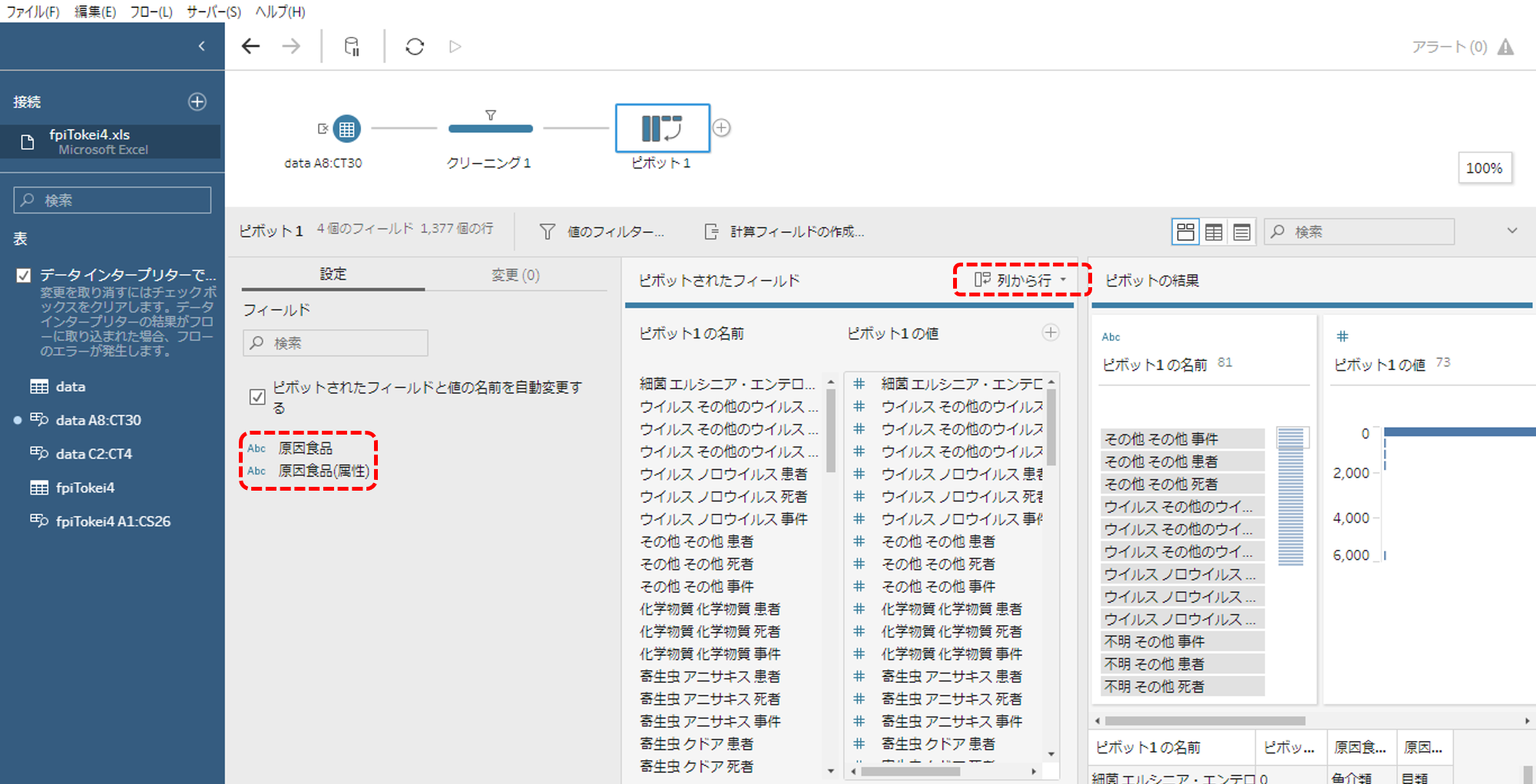
・ピボットは「列から行」です。
・「原因食品」「原因食品(属性)」(ディメンションになる列)を除くすべての列を行へピボットします。
<値を分割する>
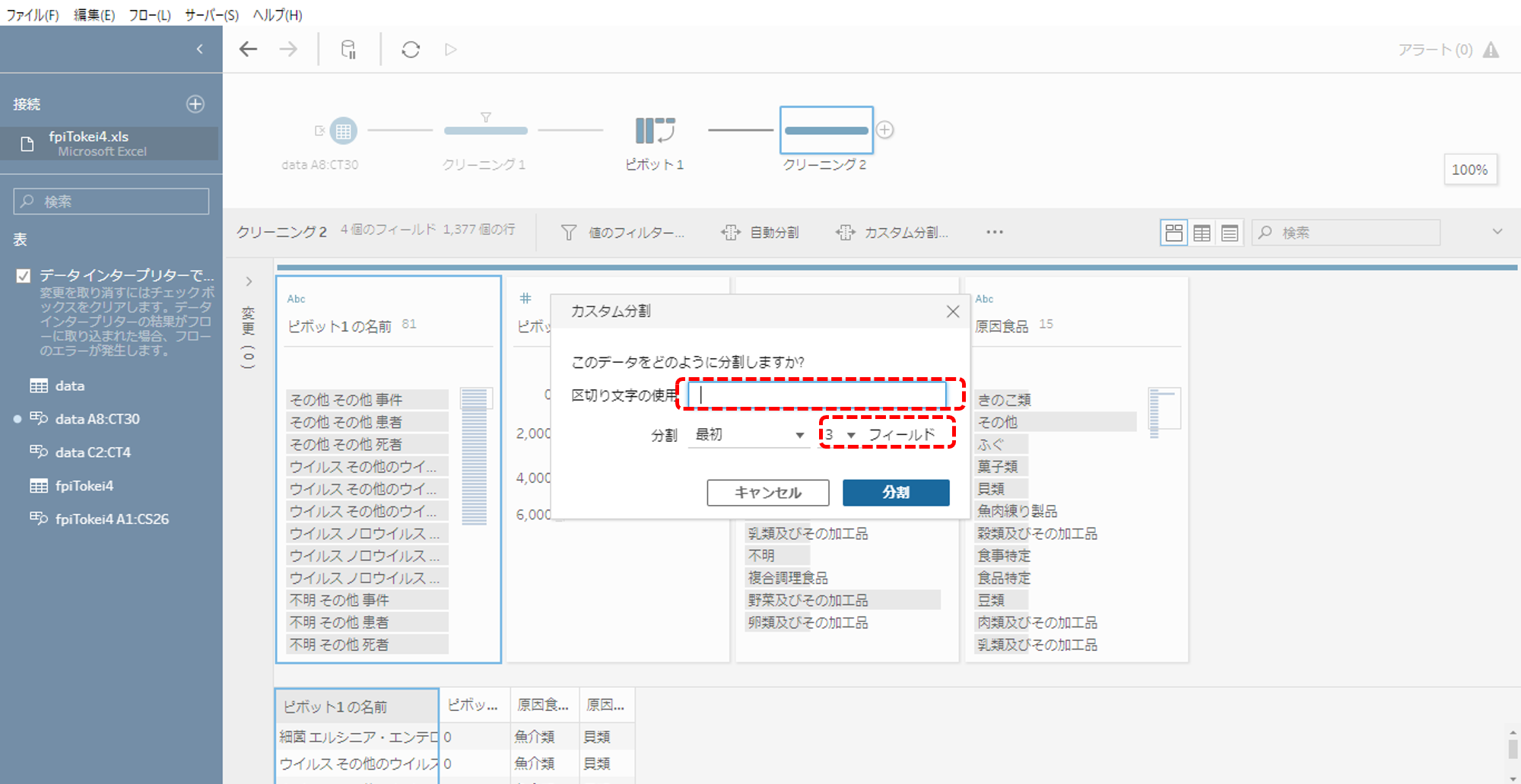
クリーニングステップで「ピボット1の名前を」3個に分割します。
・カスタム分割から
・区切り文字は半角スペース
・フィールドは3です。
もともとは3行に分かれていた列名を1行へまとめました。値を分割することで、もとの3行の状態に戻りました。
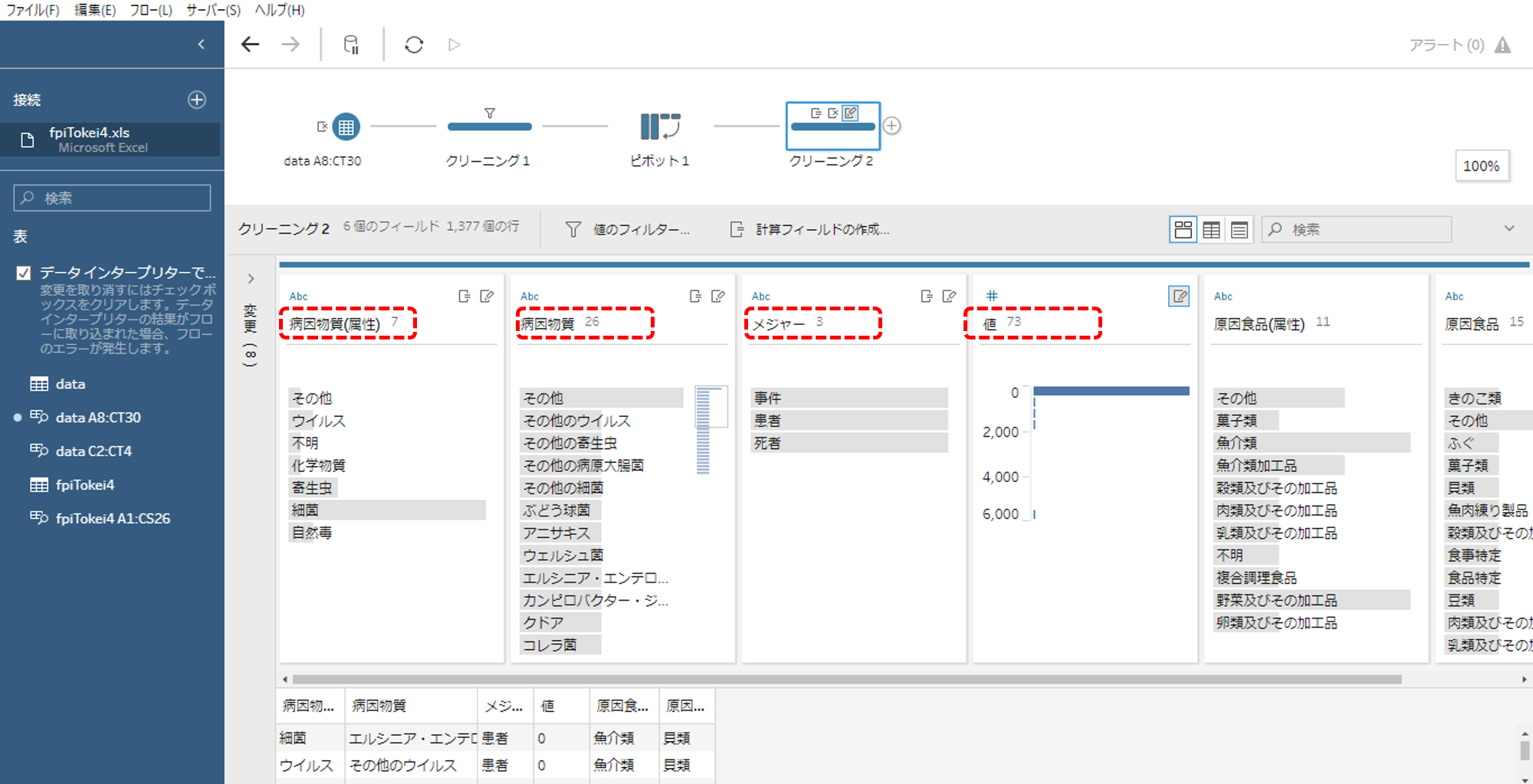
分割したフィールド名をととのえます。現在の値(メジャー)は1列です。1列のなかに「事件(数)」「患者(数)」「死者(数)」が行ごとに入っている状態です。
逆ピボットします
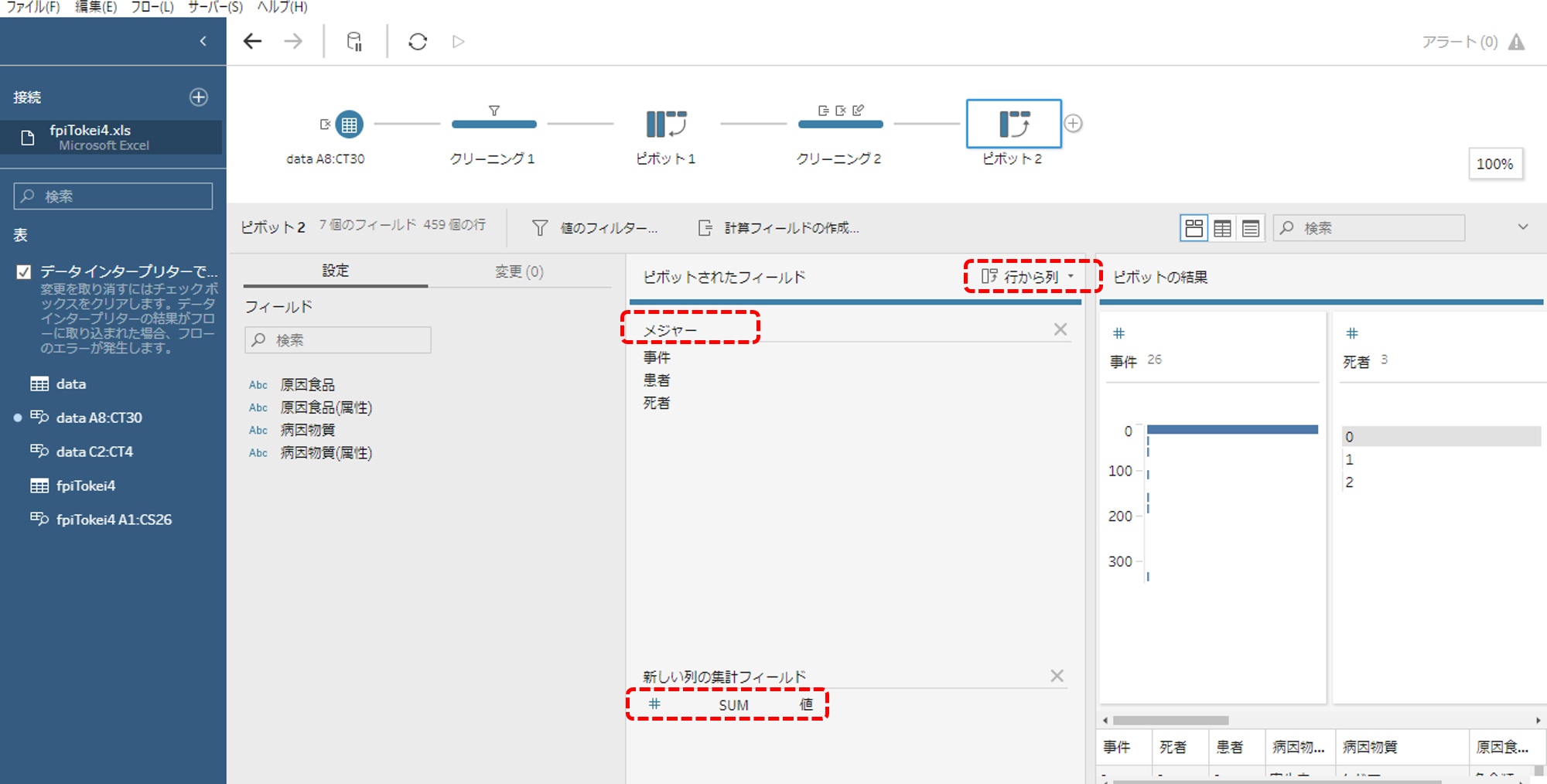
もういちどピボットします。
・今度は、「行から列」です。メジャーを行から列へ
・新しい列の集計フィールドは値です。
これで「事件(数)」「患者(数)」「死者(数)」がそれぞれメジャーになりました。
タブローから接続
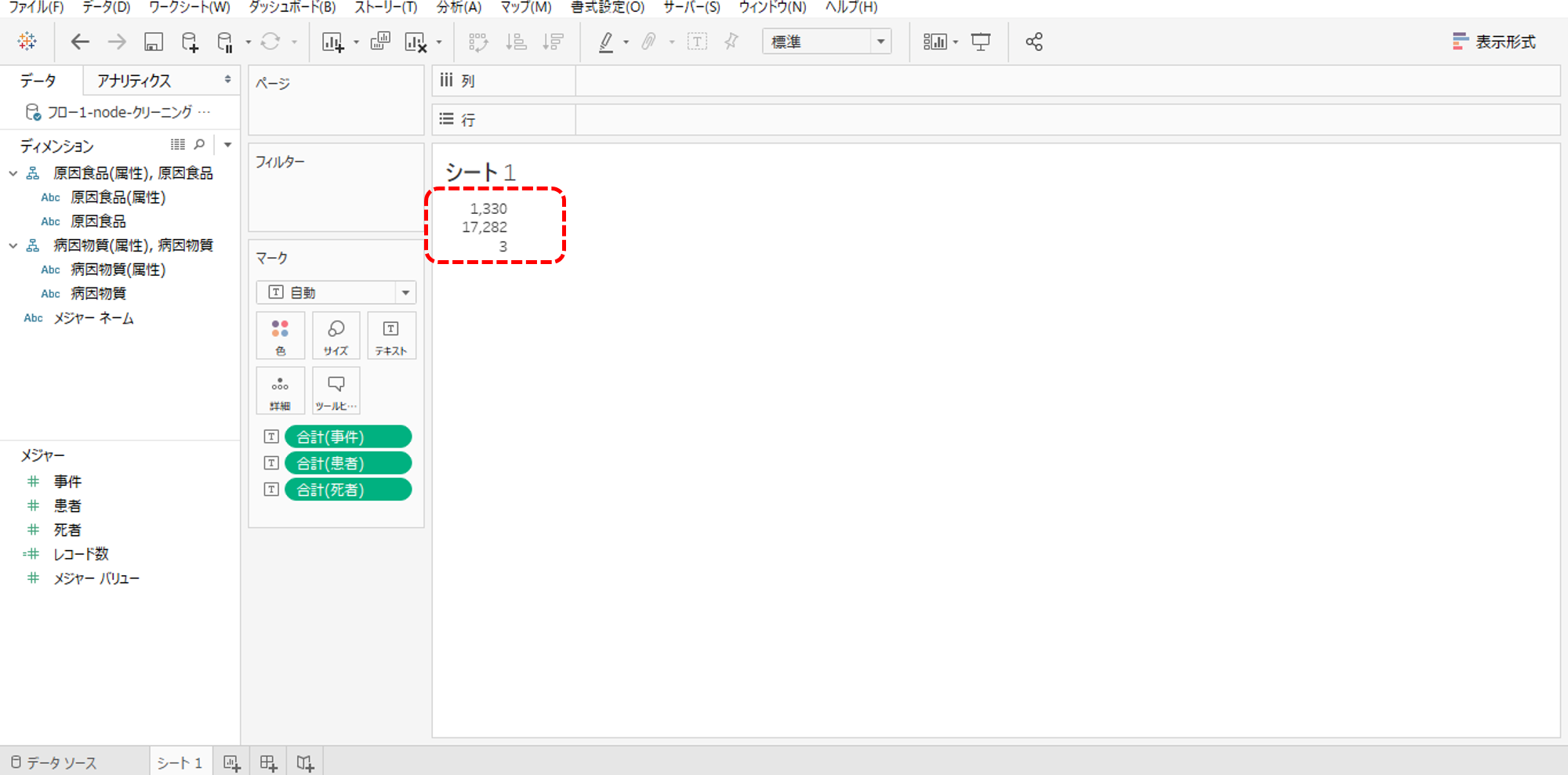
タブローで確認してみましょう。
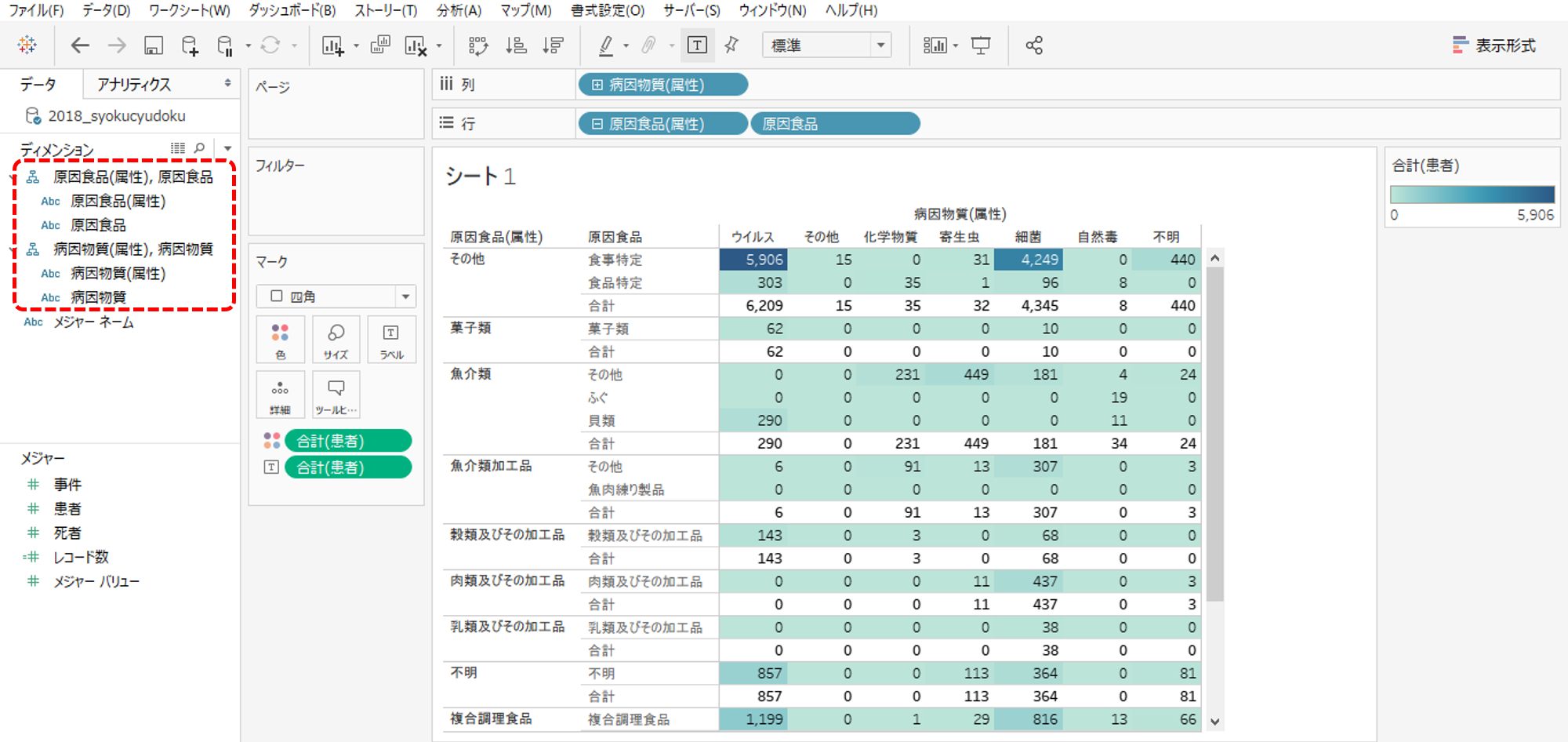
「原因食品」と「原因物質」は階層にするとドリルダウンできます。
もとデータはこちらからダウンロードできます。練習してみてください。
https://www.e-stat.go.jp/stat-search/files?page=1&layout=datalist&toukei=00450191&tstat=000001040259&cycle=7&tclass1=000001138592&stat_infid=000031925494