
Pearson 相関 タブロー編
1つの列指向形式データ表からPearson相関係数を算出する手法について解説しています。
本稿は
>ピアソンの相関関係を見つける
こちらのウエブサイトを参考にしました。
最小集計粒度でPearson相関係数を算出する手順
データについて
顧客コード,バスケット,sales,unit,グループコード,グループ名称 19014 ,20181103_00030296,20,1,1,青物 6349 ,20181107_00042474,38,1,1,青物 5744 ,20181101_00013161,39,1,1,青物 19326 ,20181101_00024108,39,1,1,青物 4169 ,20181101_00040497,39,1,1,青物 455 ,20181102_00013233,39,1,1,青物
総行数:93,760(ヘッダー行を含む)
バスケット数:20,653
顧客コード数:4,301
グループ名称数:20
sales合計:37,354,518
unit合計:201,912
最小集計粒度は「バスケット」
「顧客コード」でも集計できます。
データへ接続
Pearson相関を算出するためには2個のメジャーが必要です。
例えば、
・商品Aの売上高と商品Bの売上高
・商品Aの売上高と商品Aの利益高

トレーニングデータは画像のように列指向形式です。
グループAの売上高、グループBの売上高のような列がありません。売上高を示す列フィールドは「sales」だけです。
従って、売上高の値(メジャー)からPearson相関係数を算出しようにも、売上高の値が1つしかないわけですから算出することは不可能です。。
列指向形式のデータ表から2つの売上高メジャーをつくる方法は・・・

・まず、データへ接続します。
・そして、全く同一のデータへリレーションシップで接続します。
・最小集計粒度の「バスケット」でリレーションします。
これで、各ディメンションにたいして2つのメジャー(売上高を示す「sales」)をつくることができます。
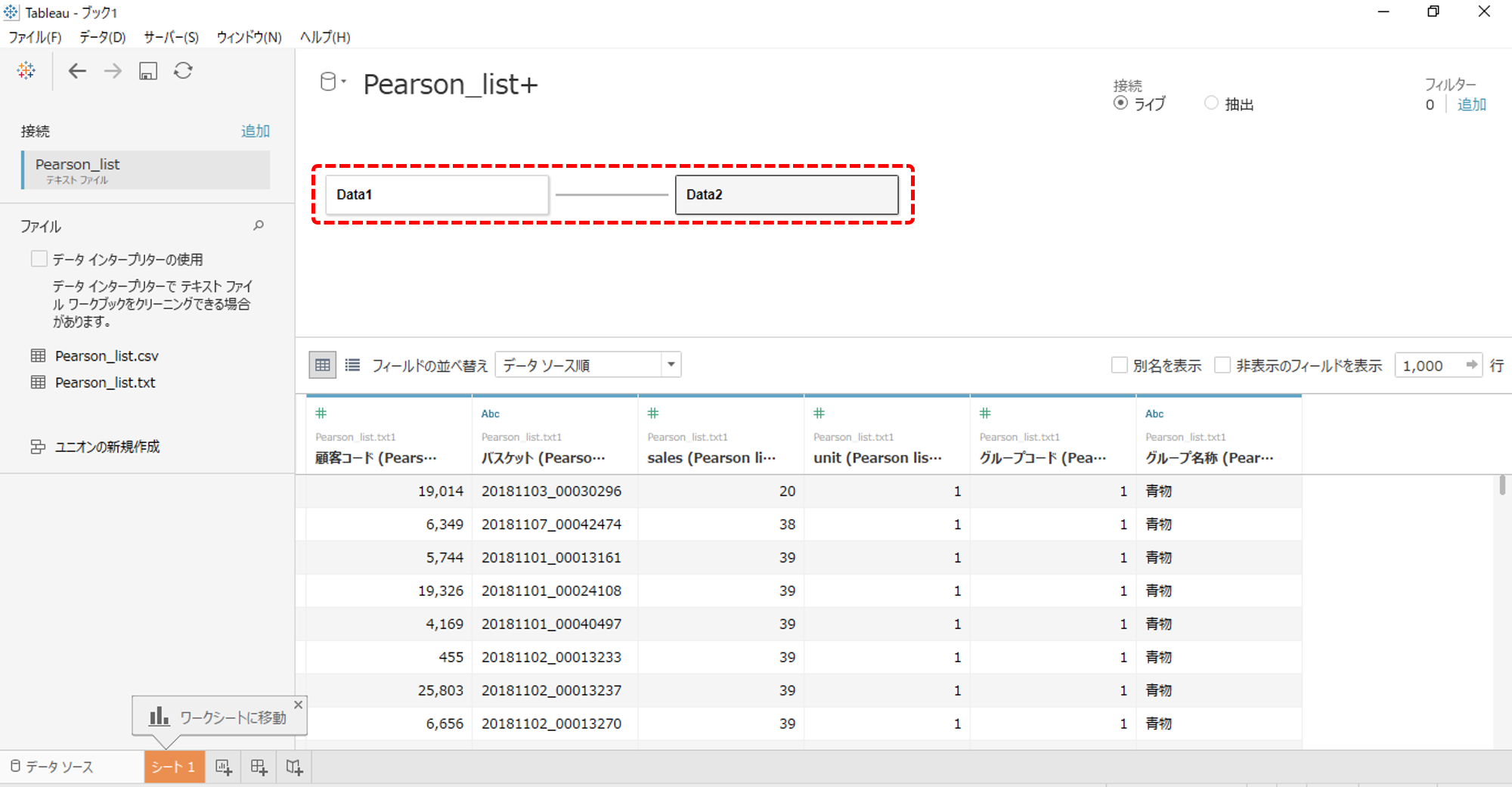
説明しやすいようにデータ名を「Data1」「Data2」へ変更しておきます。
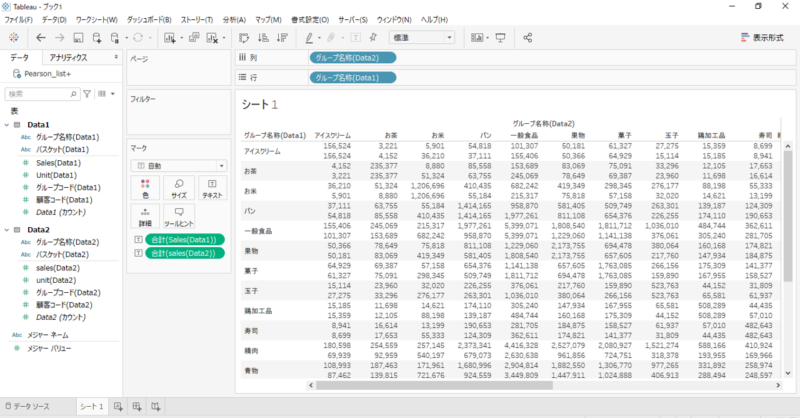
クロス集計表
・行シェルフへ「グループ名称(Data1)」
・列シェルフへ「グループ名称(Data2)」
・テキストへ「Sales(Data1)」「Sales(Data2)」を上下にドロップします。
クロス集計表ができました。
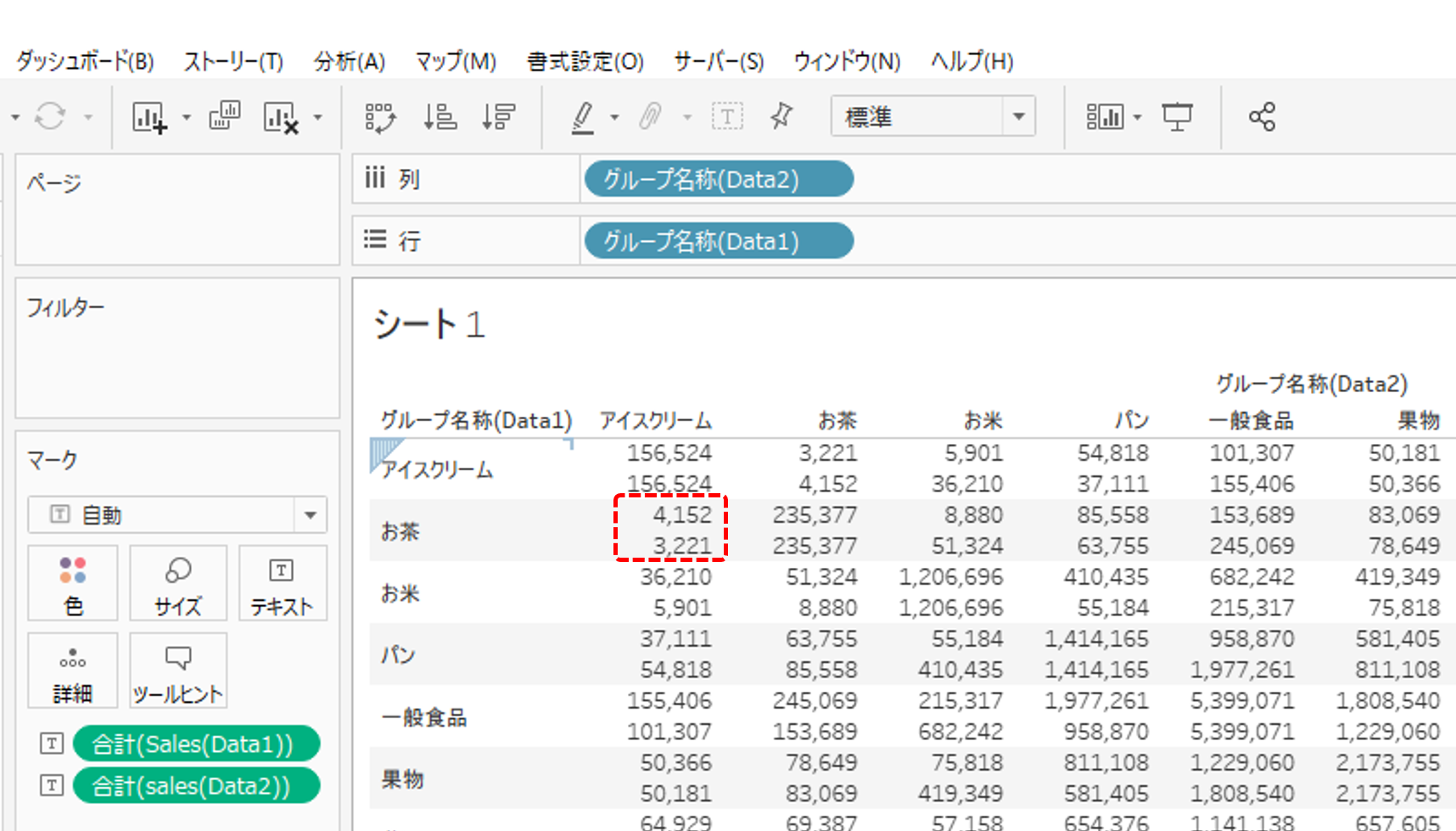
・4,152円は、
「アイスクリーム」が入っているバスケットの「お茶」の売上高合計
・3,221円は、
「お茶」が入っているバスケットの「アイスクリーム」の売上高合計
Pearson 相関を計算
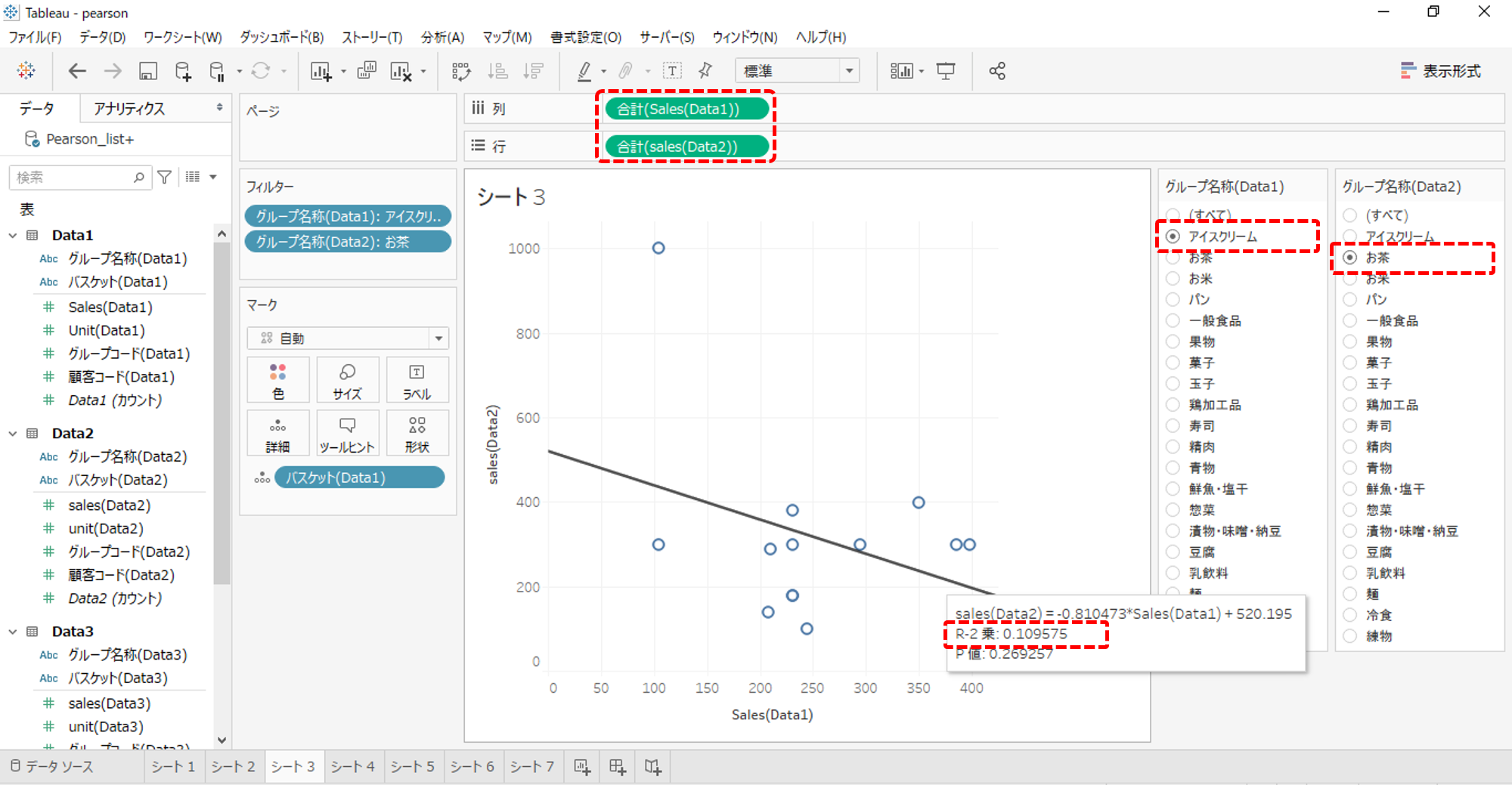
Pearson相関係数の2乗=R-2乗です。

例えば、画像のPearson相関係数は、
・「アイスクリーム」が入っているバスケットの「お茶」売上高
・「お茶」が入っているバスケットの「アイスクリーム」の売上高
それぞれを軸にした散布図へプロットしたバスケットの相関(プロットされるポイントの相関)を計算するものです。
・散布図へ近似直線を追加します。
・R-2乗値が表示されます。
Pearson相関係数^2=R-2乗値 ということは
Pearson相関係数=±√R-2乗値 です。
画像の近似直線は右肩下がりになっているのでPearson相関係数はマイナスになります。
Pearson相関係数=-√R-2乗値
縦軸・横軸を入れ替えてもR-2乗値は変化しません。従って、Pearson相関係数も変化しません。
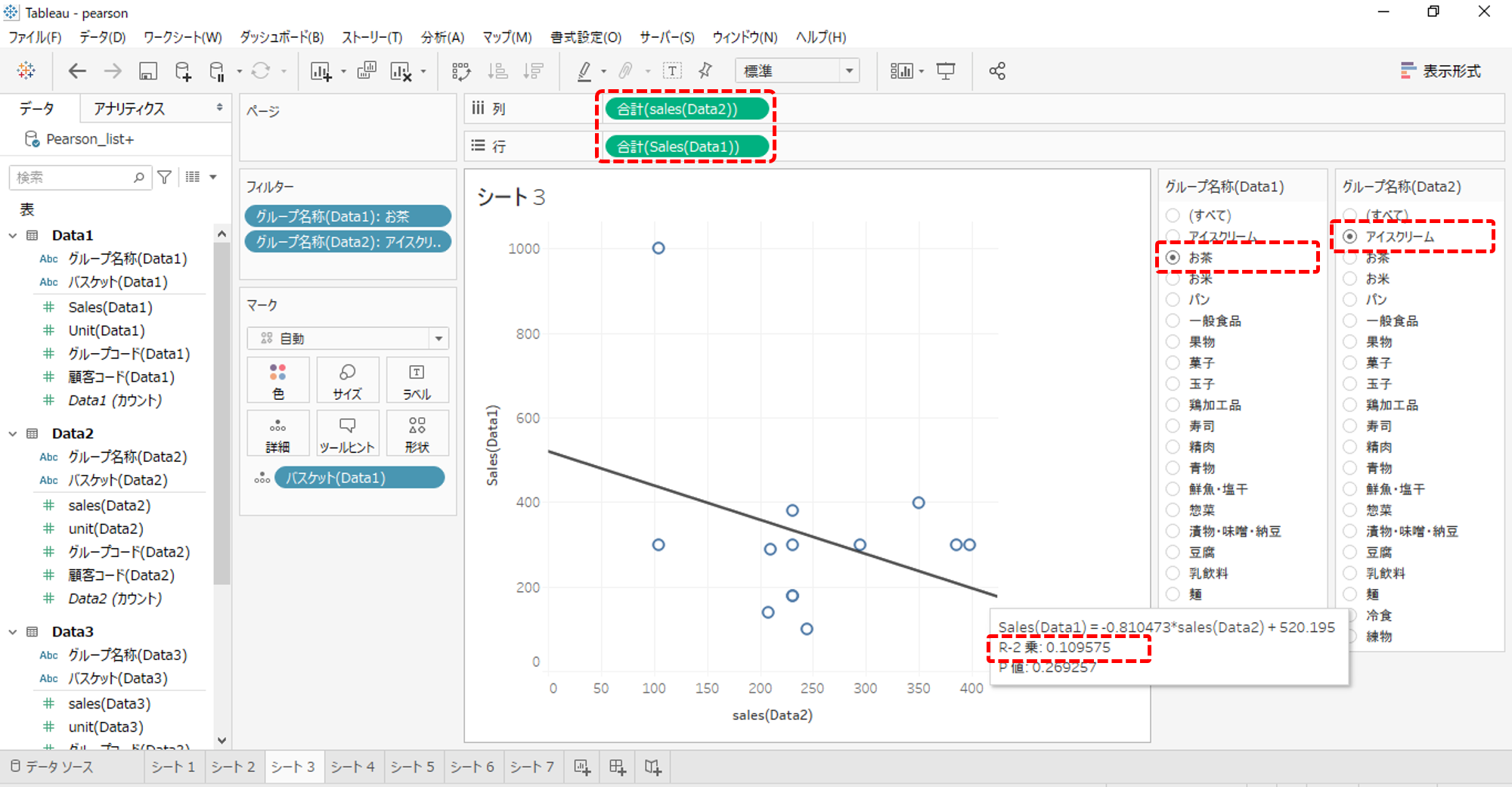
グループ名称の選択のData1とData2を入れ替えてもR-2乗値は変化しません。
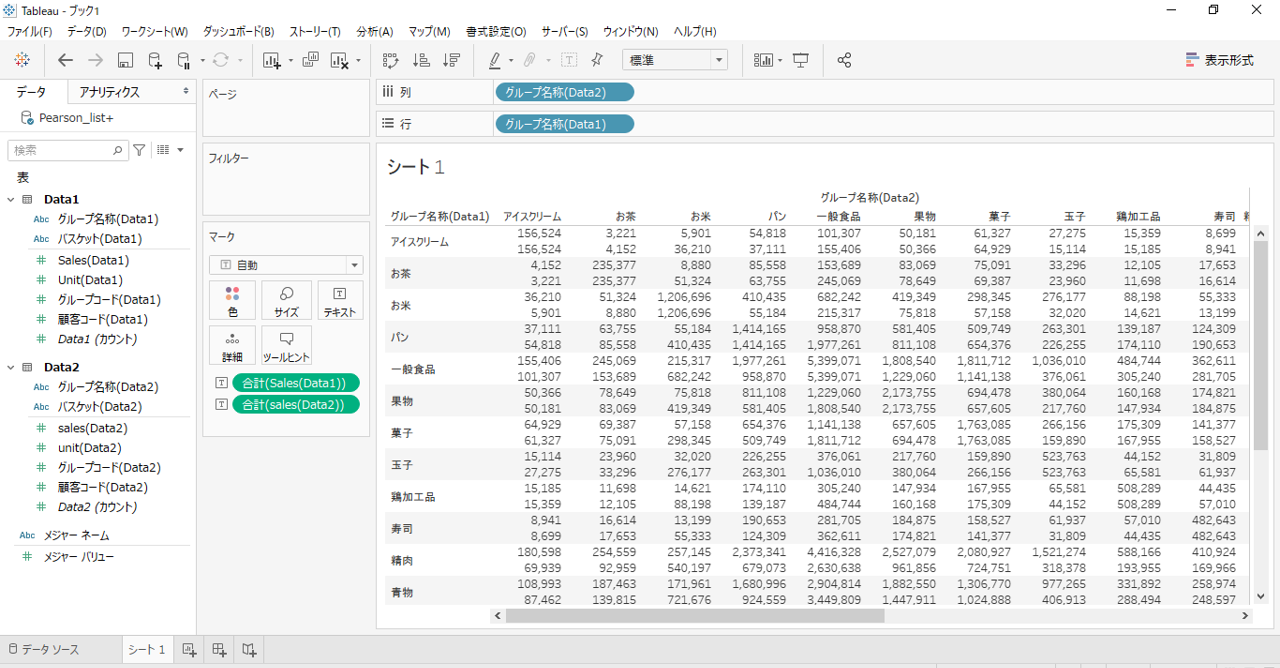
関数「CORR」
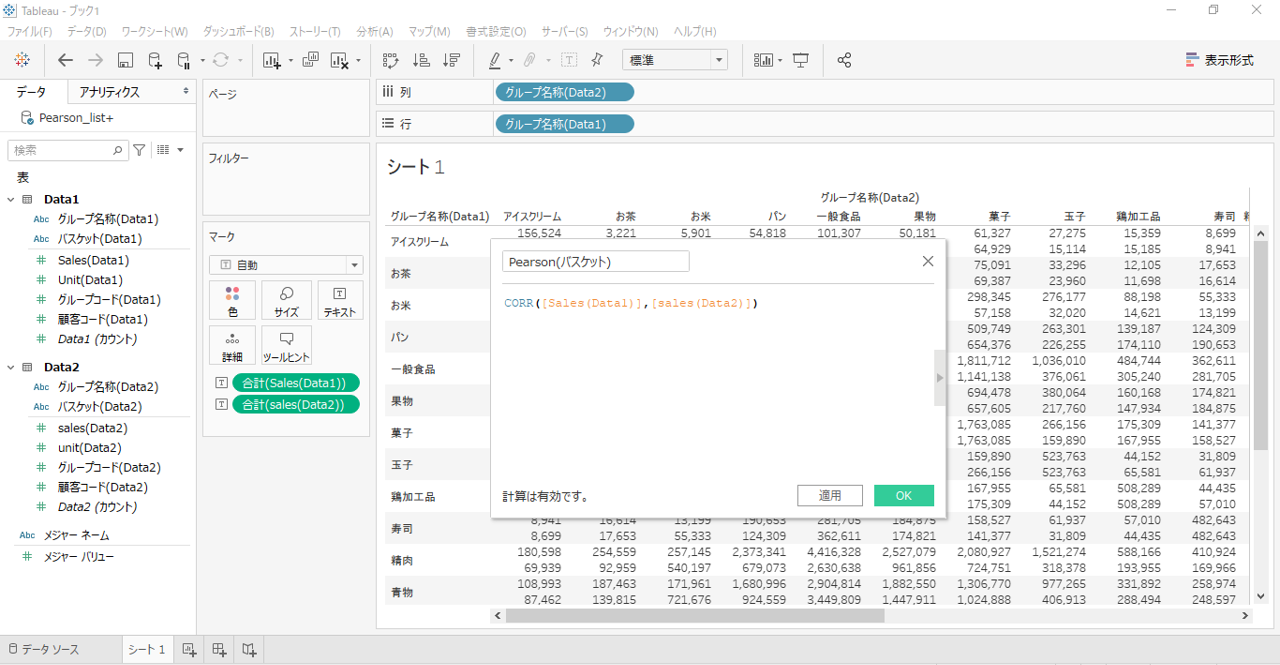
CORR([Sales(Data1)],[sales(Data2)])
Pearson相関係数を算出する関数は「CORR」です。
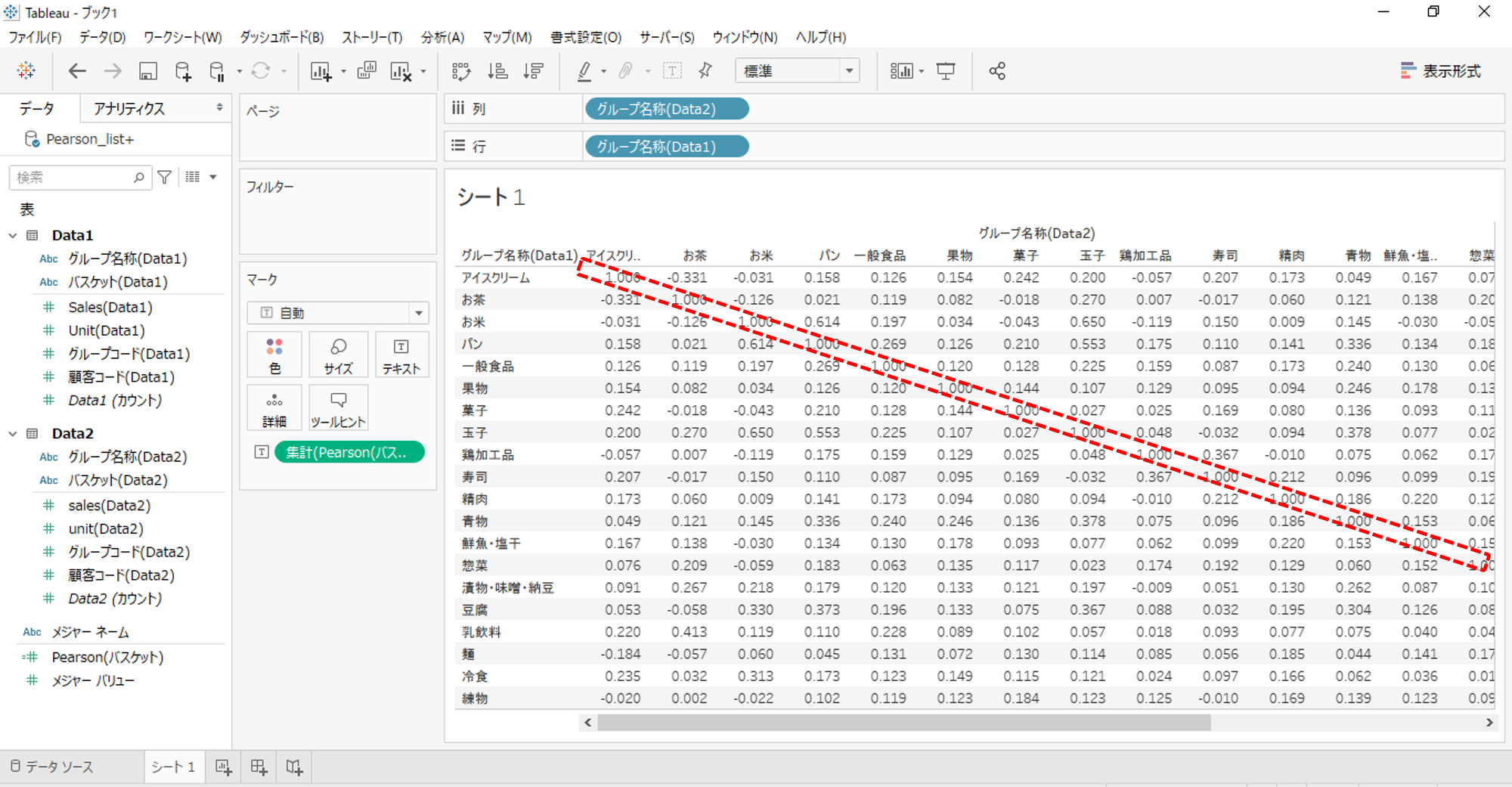
「テキスト」へPearsonをドロップします。
「値1.000」をはさんで対角にPearson相関係数は同一値になります。
対角にPearson相関係数は同一値になるといことは、散布図の縦軸・横軸を入れ替えても、グループ名称の選択のData1とData2を入れ替えてもPearson相関係数は同一値になるということです。
対角線上にある値を非表示にする
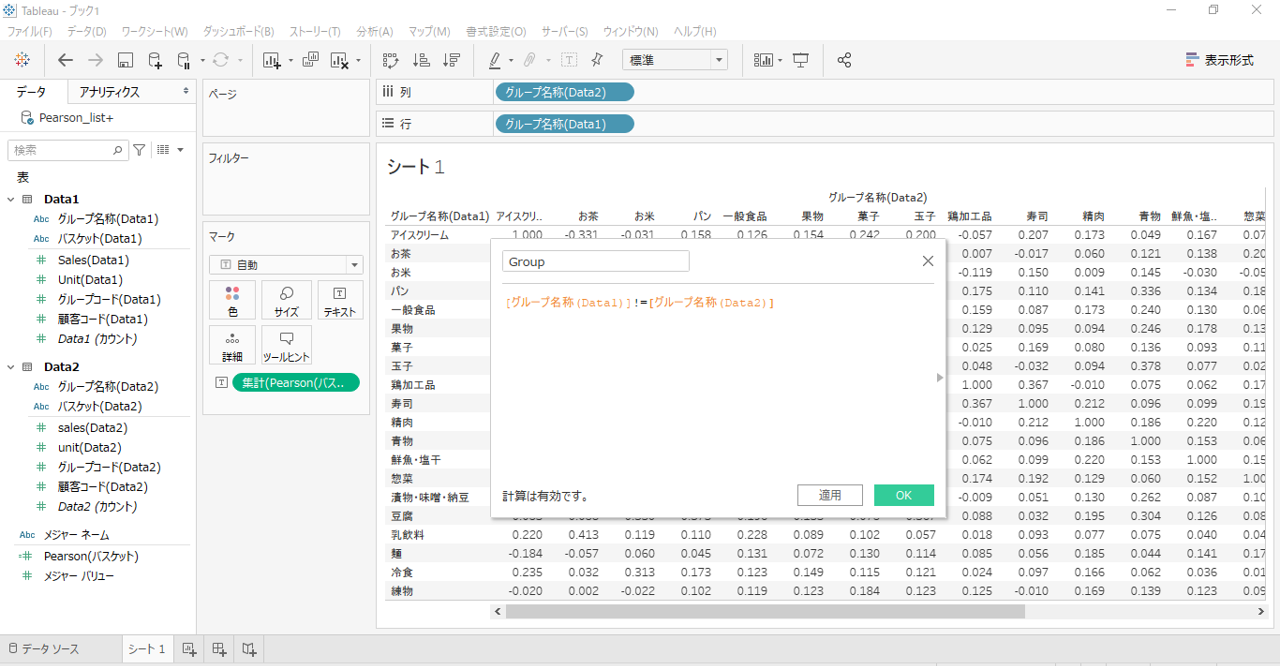
対角線上の値「1.0000」を非表示にする手順です。
[グループ名称(Data1)]!=[グループ名称(Data2)]
新規計算フィールドを作成します。

作成した計算フィールドは形式が「T|F」ですのでブールになります。
・フィルターへドロップします。
・「真」をチェックします。
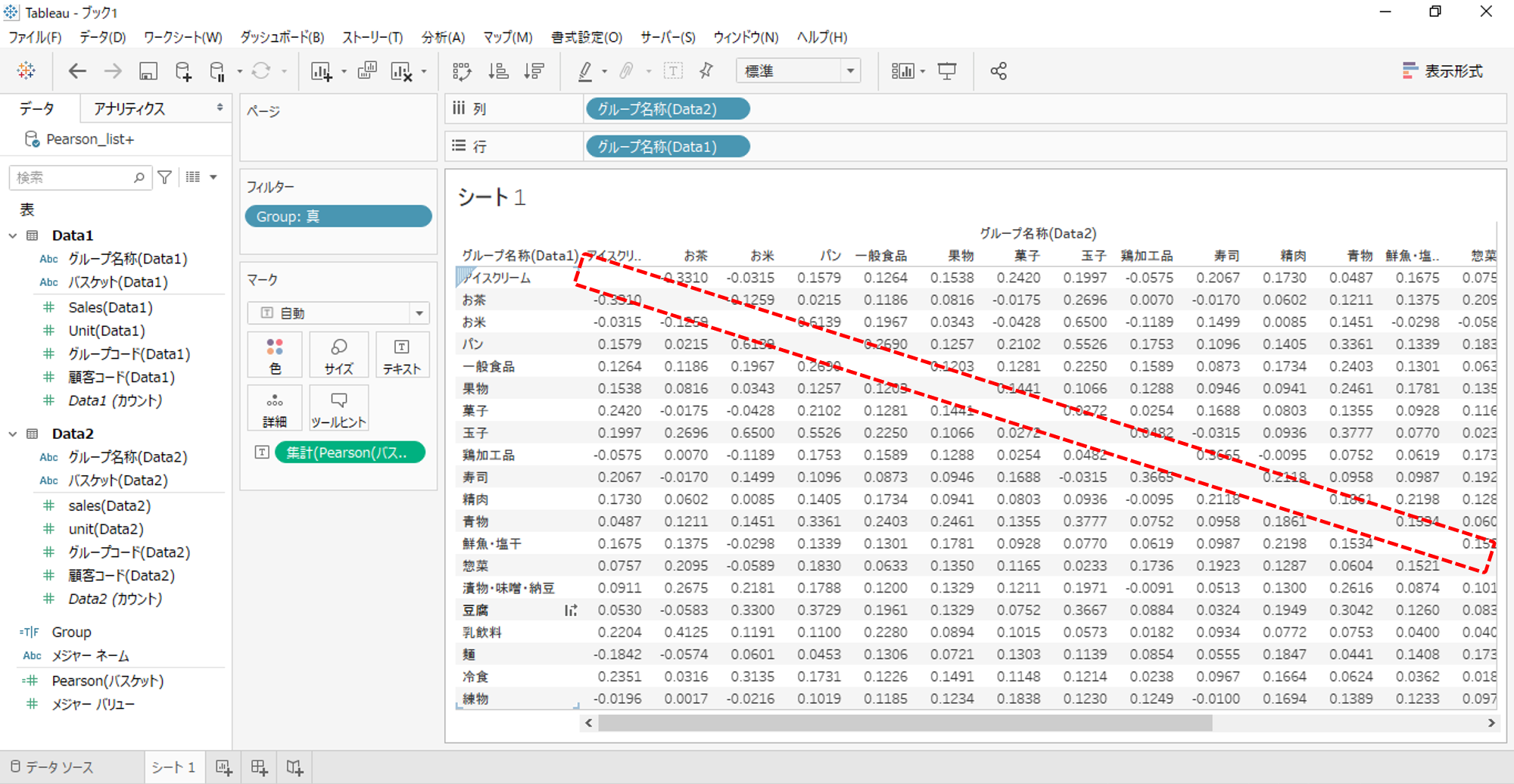
対角線上の値を非表示にできました。
チャート作成
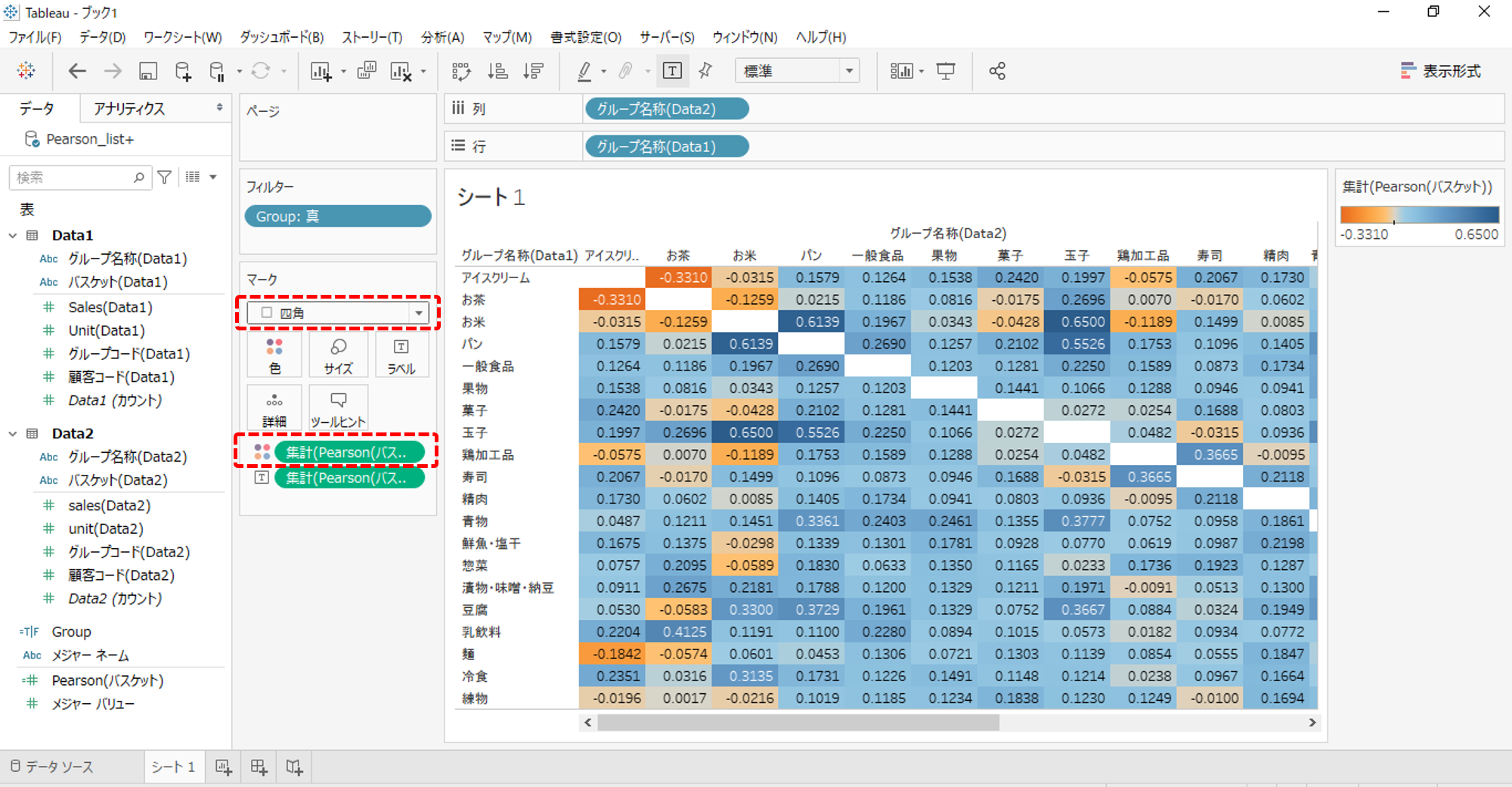
ハイライト表
・色へPearson
・形状を四角
濃いブルーは相関が高く、濃いオレンジは相関が低いといえます。
「お米」と「玉子」は同時購買の相性がよさそうです。
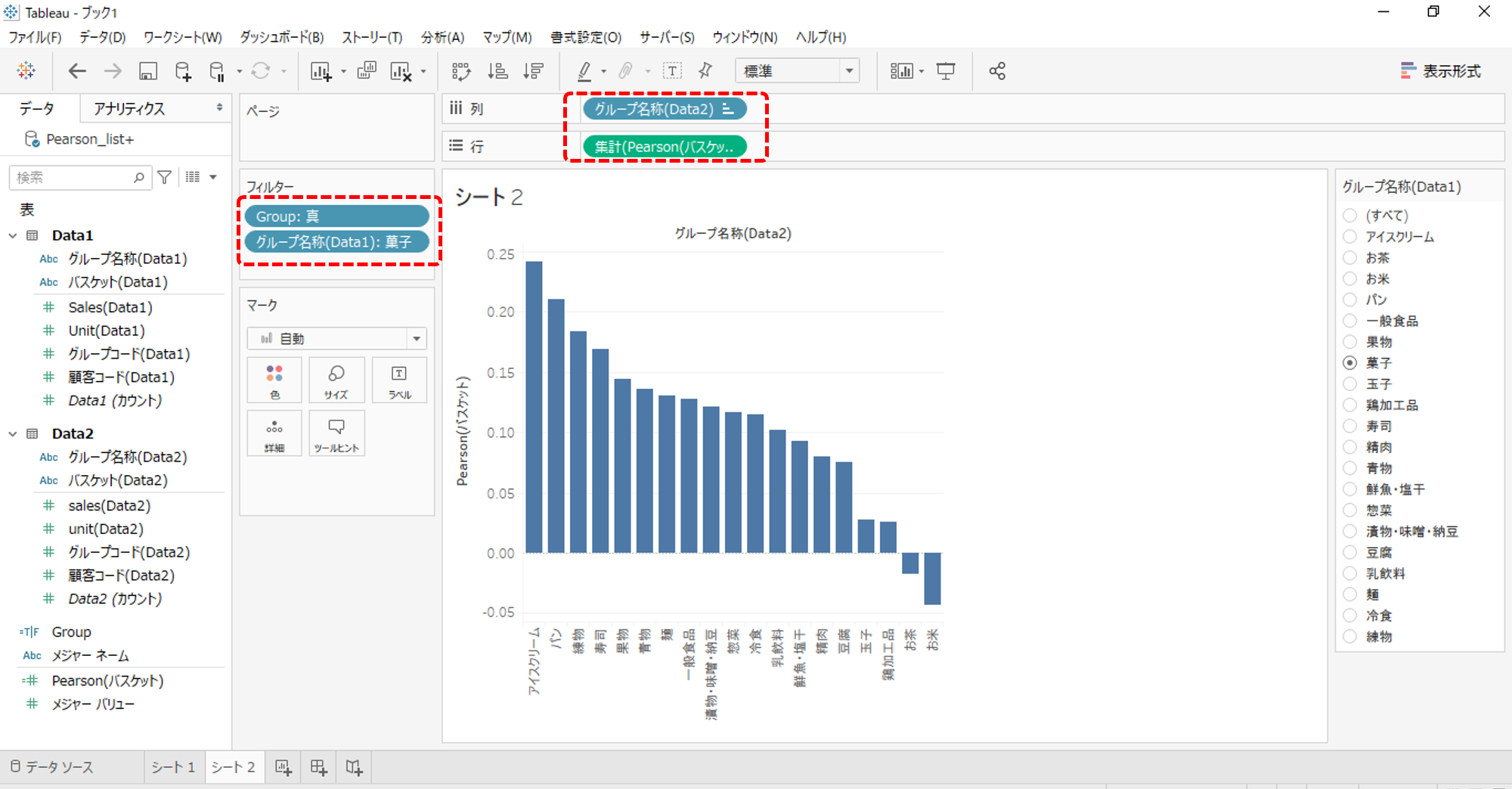
棒グラフを作成し、グループ名称(Data1)でフィルターします。
「お菓子」と「アイスクリーム」の相性がよさそうです。
中間粒度でPearson相関係数を算出する手順
粒度を変更するということ
ここまでは、最小集計粒度の「バスケット」でPearson相関係数を計算しました。
ここからは、「バスケット」よりも粒度が粗い「顧客コード」でPearson相関係数を計算します。
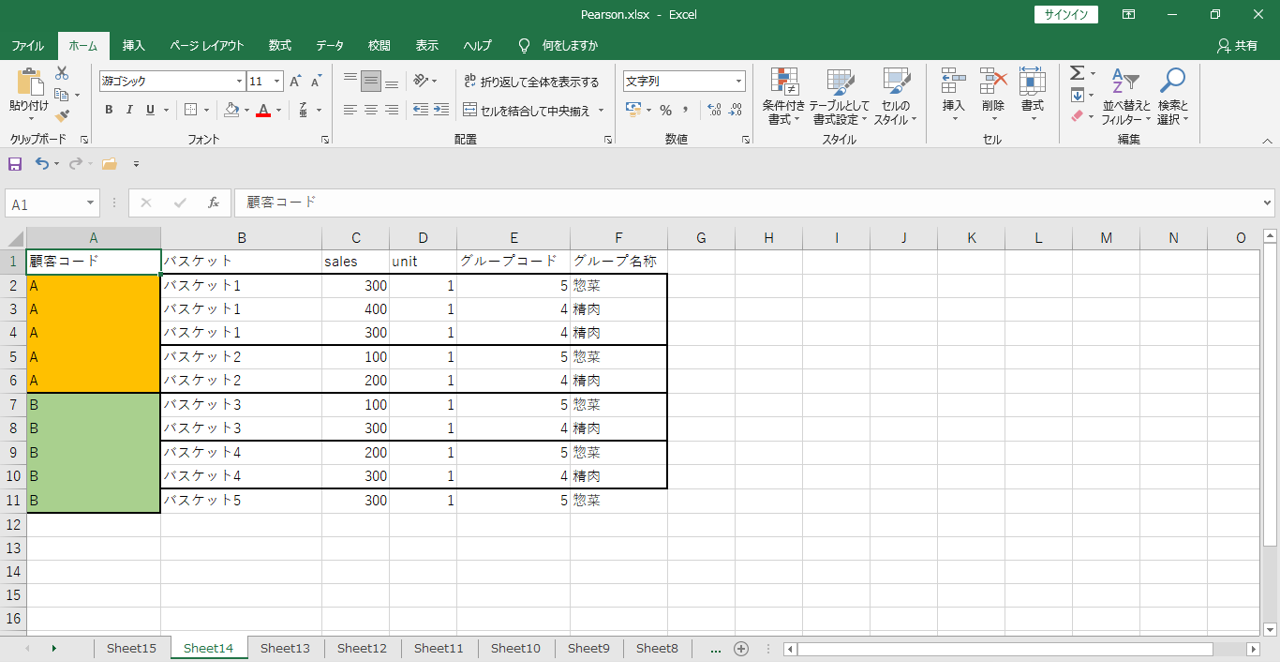
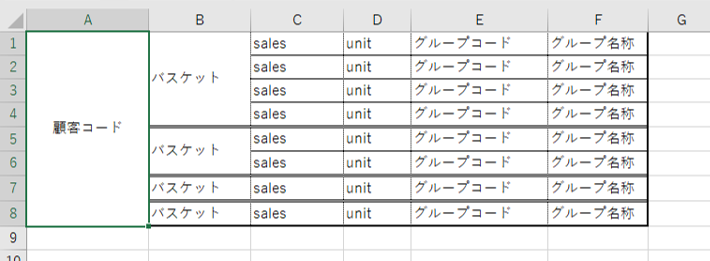
画像のようなデータがあるとします。
・バスケットのユニークカウント数=5
・顧客コードのユニークカウント数=2
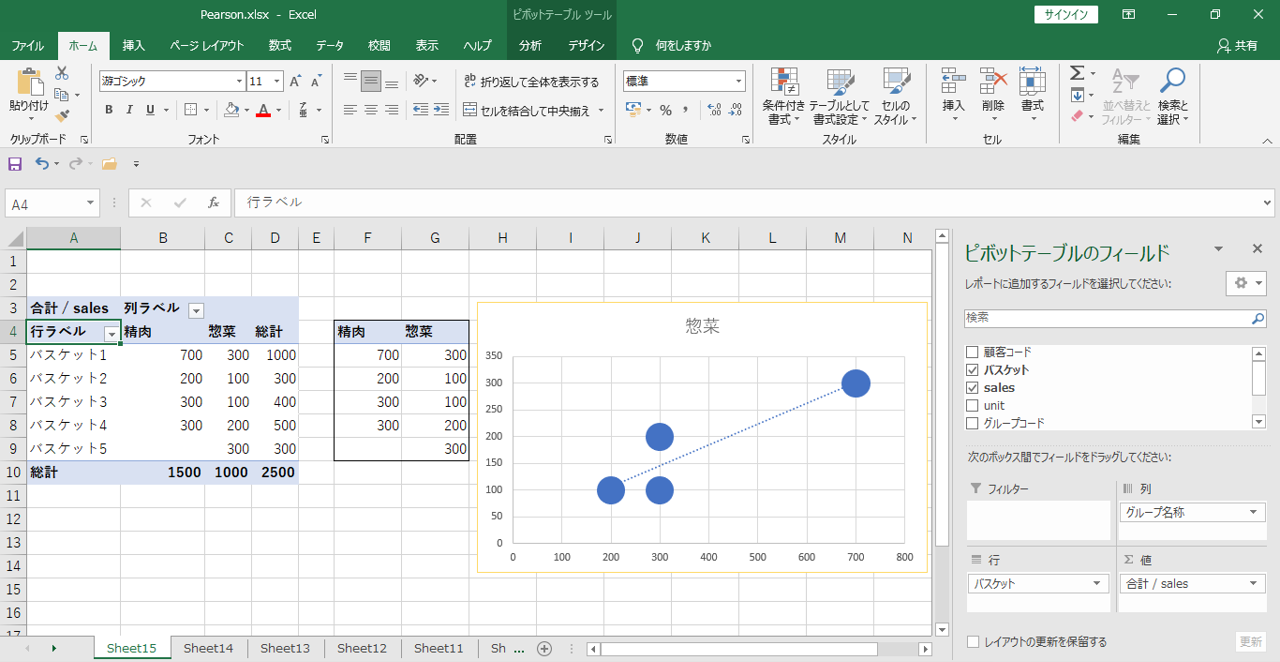
バスケットを集計レベルとして散布図を作成すると、
「精肉」と「惣菜」の両方が入っているバスケット数は4です。
したがって、散布図へプロットされるデータポイントの数は4です。

顧客コードを集計レベルとして散布図を作成すると、
「精肉」と「惣菜」の両方が入っている顧客コード数は2です。
したがって散布図へプロットされるデータポイントの数は2です。
計算のもとになる散布図(相関図)が違うから相関係数も違うという結論になります。
データへ接続
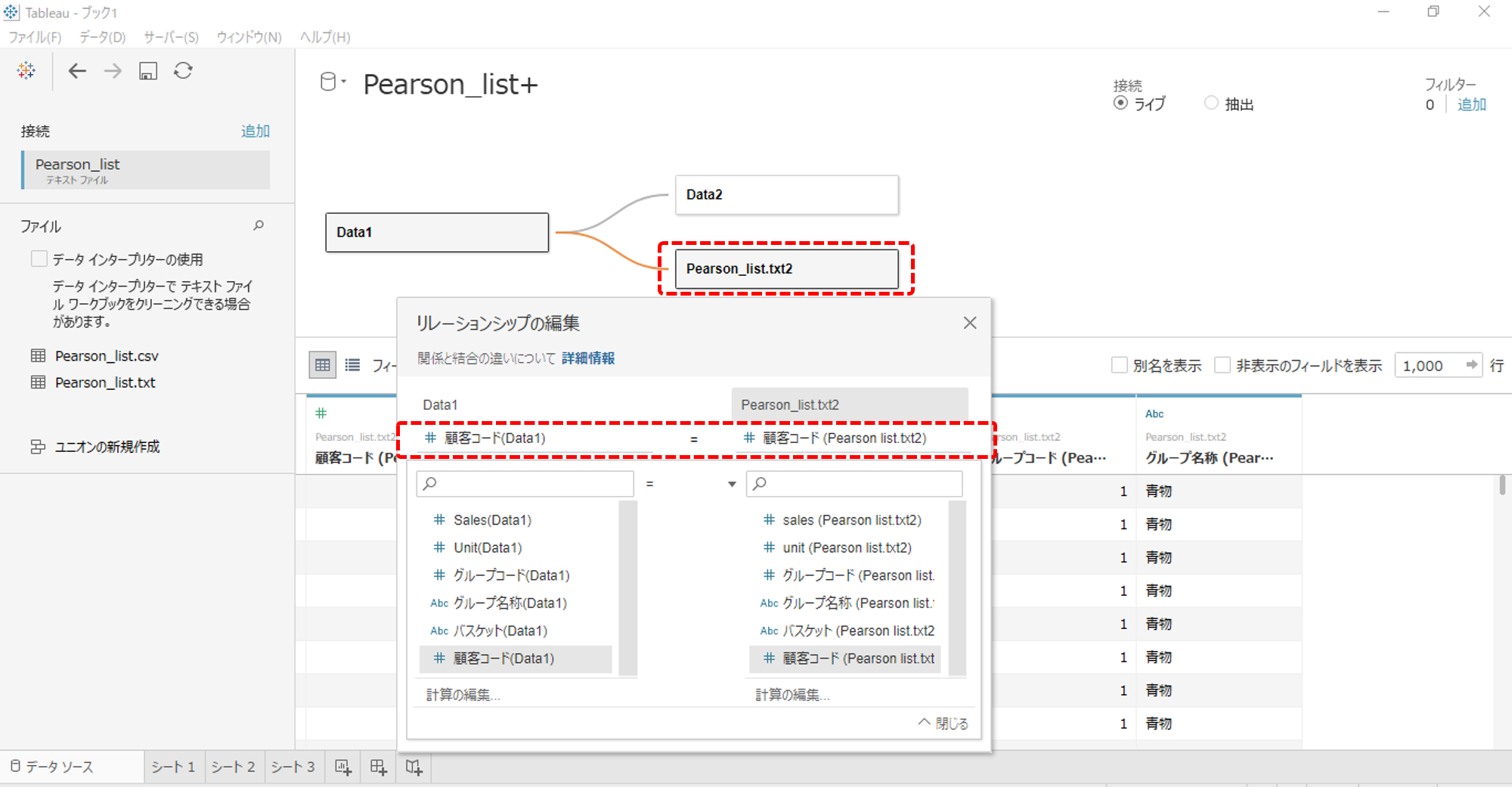
・同一データをリレーションします。
・「顧客コード」でリレーションするのがポイントです。
LODをつかう
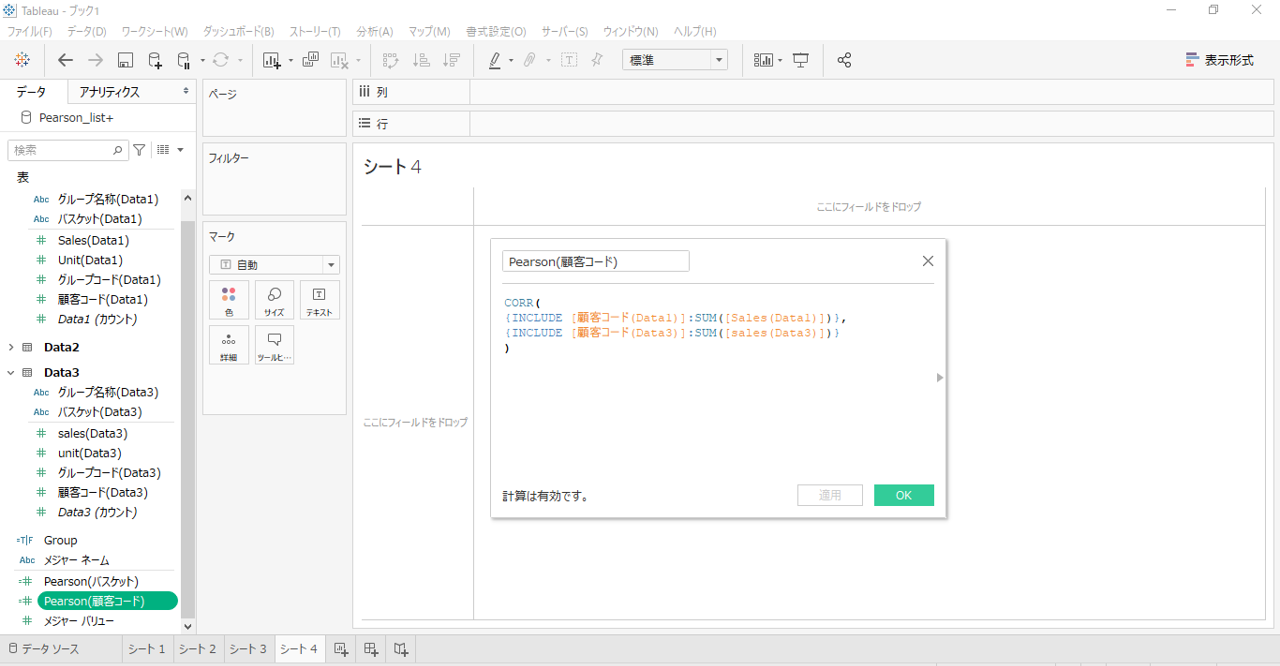
CORR(
{INCLUDE [顧客コード(Data1)]:SUM([Sales(Data1)])},
{INCLUDE [顧客コード(Data3)]:SUM([sales(Data3)])}
) データの最小集計粒度は「バスケット」です。
粒度を「顧客コード」に指定して計算する必要があります。
・「INCLUDE」を使用します。
最小集計粒度が「顧客コード」のとき「INCLUDE」は必要ありません。
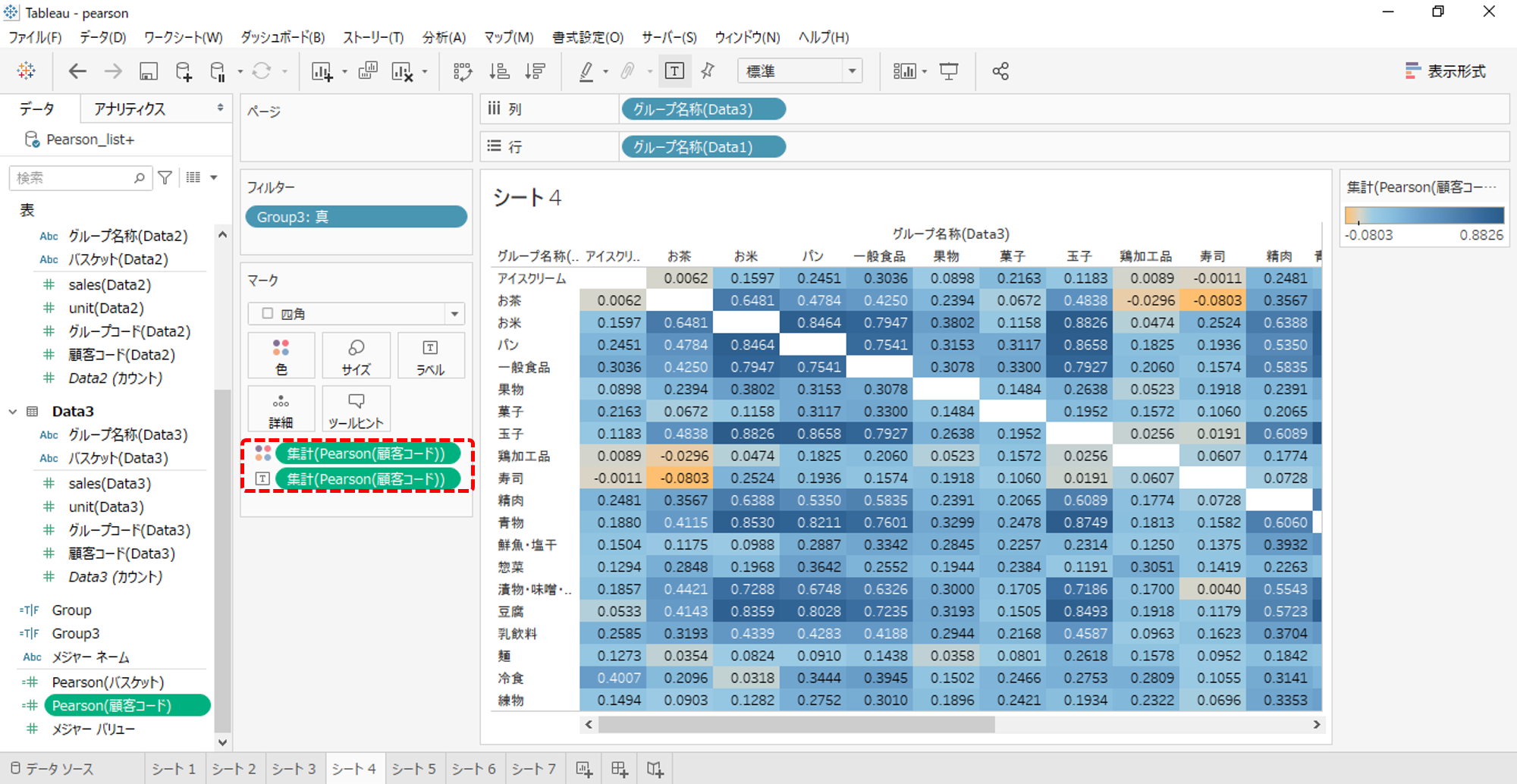
ハイライト表のテキストと色を入れ替えます。
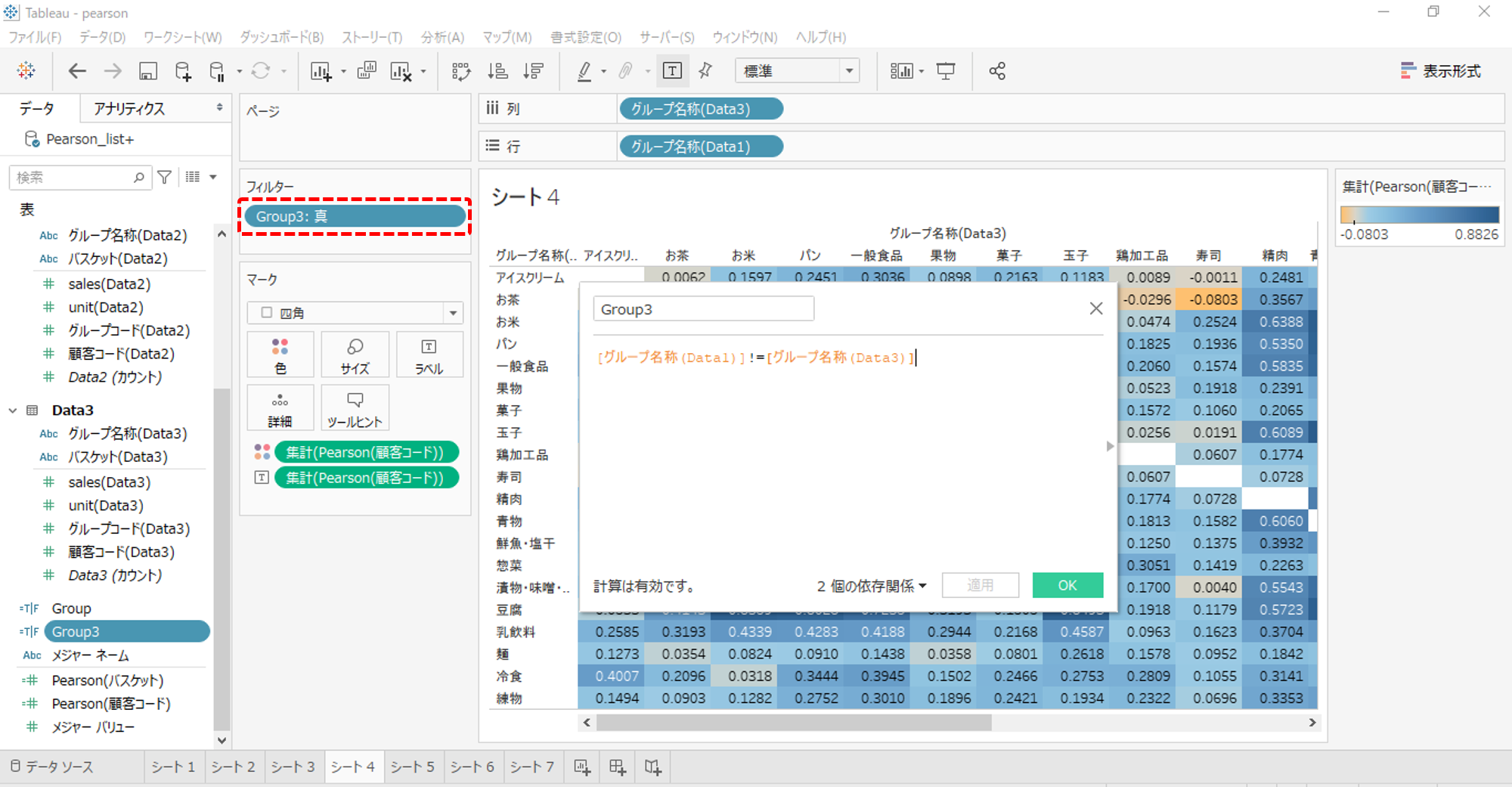
対角線上の値を除外します。

Pearson相関係数を確認します。
>Pearson 相関 エクセル編
こちらと同一値になっていると思います。