
対応分析(第1回) テキストマイニングツールの仕事
テキストマイニングイメージ
対応分析とは
分析ツール:KHcoder
対応分析とは、数量化理論Ⅲ類の分析手法でコレスポンデス分析でありまして、主成分分析との違いは・・・とにかく説明が難しいです。「言うは易く行うは難し」とは正反対で、実行する方が簡単なのです。
というのも、テキストマイニングツールの進化がすばらしく、マイニング(まさに発掘)、数量化理論に基づいた分析を一気にツールがこなしてくれるようになったからです。
今回は、テキストマイニングツールがどのようなことを内部で実行しているのか、結果として何が出てくるのかをみてゆきます。
自分のブログを自分でテキストマイニング
テキストをマイニングするためには「分析対象テキスト」が必要です。実はこのようなブログでテキストマイニングを説明するにあたり、何を「分析対象テキスト」に使うのかが問題になります。
ネットで検索すれば自治体が実施したアンケート結果、日銀短観のような文書、WEBニュース記事、グルメサイトやショッピングサイトのレビューなどテキストマイニングに使えそうな素材は山ほどあります。
ところが文章というものには「著作権」がありますから基本的には勝手に利用できません。最も困るのは、文書は利用可でも「改変・編集不可」というものが全てだからです。
そもそもテキストマイニングは「文章」を「段落」→「文」→「語」と切り分けて分析します。このような切り分け行為が「改変・編集」に該当するのか?ということで、自分のブログ記事を「分析対象テキスト」にしました。
語句の説明
テキストマイニング編で使用している語句について書いておきます。これらはKHcoderに設定されている語句に準じています。わかりやすいように文中では「」で表現しています。
「分析対象テキスト」:分析するテキスト全文のこと。
「段」:.xlsx形式と.csv形式は1セル内に記載されているテキスト。.txt形式の場合はエンターで区切られる。
「文」:句点「。」で区切られる。
「語」:分析の最小単位。
「外部変数」:「段」や「文」ごとに付与されている属性のこと。アンケートなら性別の男女・年代・賛否、小説では巻・章・見出しなどを「外部変数」にして分析します。
データイメージ
| 1 サンプルテキスト | ||
| txt | 見出し | 段id |
| 雨が降るとスーパーマーケットの売上高は晴れた日よりも減少します。スーパーマーケットの・・・ | 線形回帰分析(単回帰)とは | 1 |
| このような様々な変化に富んだデータ群から数学的な「妥当な線」を算出する手法が回帰分析です。 | 線形回帰分析(単回帰)とは | 2 |
| 回帰分析は結果になるデータと原因になるデータの関係を「回帰直線」で表現します。結果になる・・・ | 線形回帰分析(単回帰)とは | 3 |
データ:当サイト「回帰分析(単回帰)1回」「資本独立型地方食料品ストアが厳しい」を除く
txtの列がテキストマイニング「分析対象テキスト」です。見出しの列が「外部変数」に相当します。「線形回帰分析(単回帰)とは」「回帰分析結果を解説」「分析の視点」これら3種類の見出しを外部変数に設定しています。
「段」に分解して「語」を抽出する
「段」に分解する
テキストマイニングツールは、まず、分析対象テキスト全文を「段」に分解します。xlsx形式と.csv形式であれば1セル内に記載されているテキストごとに、.txt形式の場合はエンターごとに分解します。そして各「段」に通し番号を自動的に付与してすべての「段」数をカウントします。サンプルテキストのように右端へ「段id」の列を挿入するようなことを自動的におこないます。短文ならがんばって手作業でも可能です。
分析対象テキスト全体を「丁目=段」に分割するイメージです。この時点で地図はありません。まだ「丁目」には緯度経度がありません。いまあるのは「丁目」名のリストだけです。
本文は基本的に「段」で解説をすすめます。ちなみに「文」への分割は次のとおりです。
”「文」の場合はファイル形式にかかわらず読点「。」で区切られます。「文」もすべてに通し番号を付与してすべての「文」数がカウントされます。”
「語」を抽出する
分析対象テキスト全文から「語」を抽出します。
例えば、「雨が降るとスーパーマーケットの売上高」→「雨が / 降ると / スーパーマーケットの / 売上高」このように分解します。
「雨 (名詞) 」「降る (動詞) 」「スーパーマーケット (名詞) 」「売上高 (合成語) 」を抽出して品詞別に分類します。
ここで助詞・助動詞等は分析対象にしないので除外されます。そして各「語」の出現回数をカウントします。
出現する回数のカウントというのは、「語」が各「段」の中で何回出現しているか?です。
「語」がどこかの「段」に出現する回数を集計すれば、「語」がどこの「外部変数」に何回出現するのかを算出できます。
1丁目の住民は「雨」「降る」「スーパーマーケット」「売上高」である。このように「丁目」と「語」のリストが完成します。住民基本台帳のイメージです。ここでもまだまだ丁目には緯度経度がないので地図を描くことができません。
「語」の抽出方法
日本語の場合、特に難しいのが「語」の抽出です。
「スーパーマーケット」は「スーパー」「マーケット」の2語を抽出するのか1語にするのか、「売上高」は「売上」「高い」の2語か1語か?あるいは、「降る」「降った」は同じ「降る」で抽出するのかどうか?このようなあいまいな部分をテキストマイニングツールはその進化とともに解決しようとしています。
現在のマイニングルーツは搭載している辞書機能を使って「語」を抽出します。辞書機能が進化するほど文意に沿って「語」を抽出してくれるようになります。
辞書がAIの役割を担っているわけです。「語」の抽出は人間技では不可能です。
テキストマイニングツール3つの仕事
仕事1 「語」と「段」のデータ化
| 売上高 |
| 回帰直線 |
| 回帰分析 |
| 回帰係数 |
| ダウントレンド |
| 損益分岐点売上高 |
| 閉店Xデー |
このように「分析対象テキスト」から「語」を抽出します。
「損益分岐点売上高」「閉店Xデー」のような「語」をサクッと抽出してしまうあたりにテキストマイニングツールの進化を感じます。
| id | データ | 顧客 | バーゲン | トレンド | 原因 | 店舗 | スーパーマーケット | 直線 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 1 | 0 | 0 | 0 | 0 | 2 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
クロス集計表をつくり「段落」ごとに抽出した「語」の出現回数をカウントします。
表のidは「段」に対応する番号です。id2の「段」に「顧客」が1回、「スーパーマーケット」が2回出現していることがわかります。2丁目の住人は「顧客」が1人、「スーパーマーケット」が2人というイメージです。
| データ | 顧客 | バーゲン | トレンド | 原因 | 店舗 | |
| 回帰分析結果を解説 | 1 | 0 | 0 | 0 | 0 | 1 |
| 線形回帰分析(単回帰)とは | 6 | 1 | 0 | 0 | 4 | 0 |
| 分析の視点 | 3 | 8 | 8 | 5 | 1 | 4 |
行が「外部変数」、列が「語」のクロス集計表をつくります。数値は各「外部変数」に出現する「語」の回数です。丁目をまとめると町の住民基本台帳ができます。
仕事2 統計解析
| type | frequency | size | X1 | X2 | |
| データ | col | 10 | 66.00423 | -0.85863 | -0.90105 |
| 顧客 | col | 9 | 63.15217 | 0.916097 | -0.3333 |
| バーゲン | col | 8 | 60.13675 | 1.259173 | -0.13597 |
| : | : | : | : | : | : |
| 回帰分析結果を解説 | row | 296 | 41.46814 | -0.96503 | 1.826303 |
| 線形回帰分析(単回帰)とは | row | 472 | 47.52756 | -1.26693 | -1.21701 |
| 分析の視点 | row | 1010 | 61.00429 | 0.872449 | -0.08655 |
クロス集計したデータを解析します。「R」の関数は「corresp」です。図のような結果を得ることができます。
・「X1」が横軸の座標
・「X2」が縦軸の座標、
・「size」はプロットするバブルの大きさです。
・「type」が「col」の場合は水色の丸
・「row」の場合は赤色の四角でプロットします。
「col」の座標をアイテムスコア、「row」の座標をカテゴリースコアといいます。スコア=得点とするより座標としたほうが解りやすいと思います。
ここではじめて丁目・町の緯度経度(座標)がわかります。
緯度経度に従って丁目・町をプロットします。対応分析とは「語」の出現回数と出現場所(「外部変数」「段」)を数量化して「語」をプロットする座標を算出することです。
仕事3 分析結果プロット
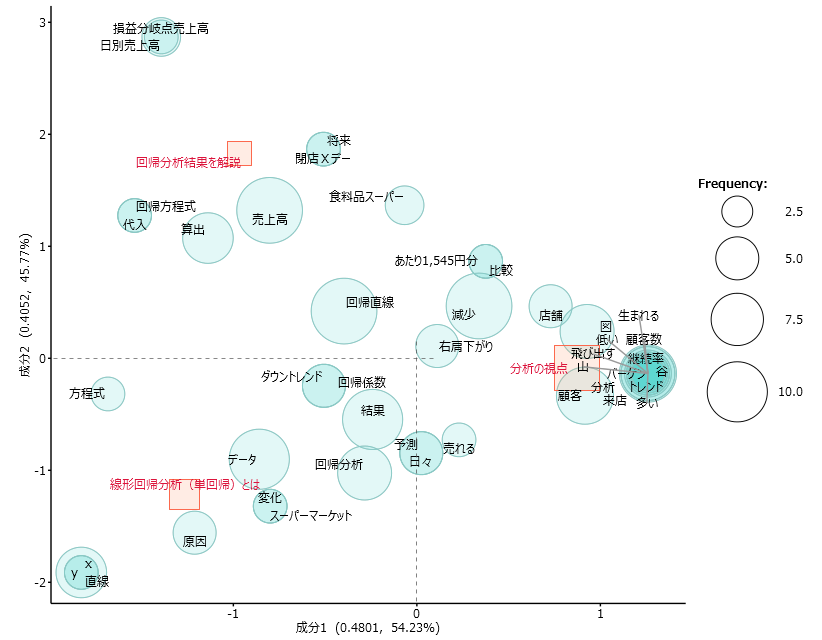
語の座標とサイズに従ってプロットします。ビジュアルが美しいのもテキストマイニングツールの特徴です。