

KHcoder 6. 表記揺れの吸収ファイル書き換え
表記ゆれの吸収の機能・実践。「語」の増やし方、ファイルの増やし方について解説しています。
テキストマイニングツール「KHcoder」の活用メモ
開発者である樋口先生に感謝!
【今回の分析対象テキストはこちらからコピーできます】
表記揺れの吸収とは
語の出現場所と出現回数
そもそもテキストマイニングとは?何を計算しているのかというと、「語」が出現する場所と「語」が出現する回数の組み合わせを計算しています。
「語」が出現する場所とは「H5」「段」「文」「外部変数」のことです。
例えば、対応分析では「外部変数」ごとに「語」が出現する回数をカウントします。従って、「分析対象テキスト」がどのような「H5」「段」「文」「外部変数」で構成されているのかと同時に、「語」が何回出現しているのかがたいへん重要なのです。
ところが、前回のお題にした「iPad」「i-Pad」「アイパッド」のように製品名の「iPad」を示す「語」が多様なかたち (字面) で「分析対象テキスト」に出現することが多々、多々どころかほとんど、あります。
KHcoderは「iPad」「i-Pad」「アイパッド」をそれぞれ別の「語」と認識するので、それぞれ別々に出現回数をカウントすることになります。
現在のコンピューターでは字面の違いイコール別の「語」となるのがその性能の限界だろうと思います。半角カタカナを全角カタカナに変換して1「語」として抽出できるだけでも大したものだと思います。
異字同義語を統一します
「iPad」「i-Pad」「アイパッド」をどれか1「語」に統一することを可能にできるのが、表記揺れの吸収機能です。
「iPad」「i-Pad」「アイパッド」を「iPad」にまとめることができるのです。そうなれば「iPad」だけの出現回数をカウントできます。
この機能は特に名詞系の「語」について有効です。
「マック」「マクド」「マクドナルド」を「マクドナルド」に一本化する、「スマホ」「スマートフォン」を「スマホ」に、「渋谷」「シブヤ」を「渋谷」に一本化することで出現回数のカウント精度をアップすることができます。
表記揺れの吸収実践
抽出語リストを確認する
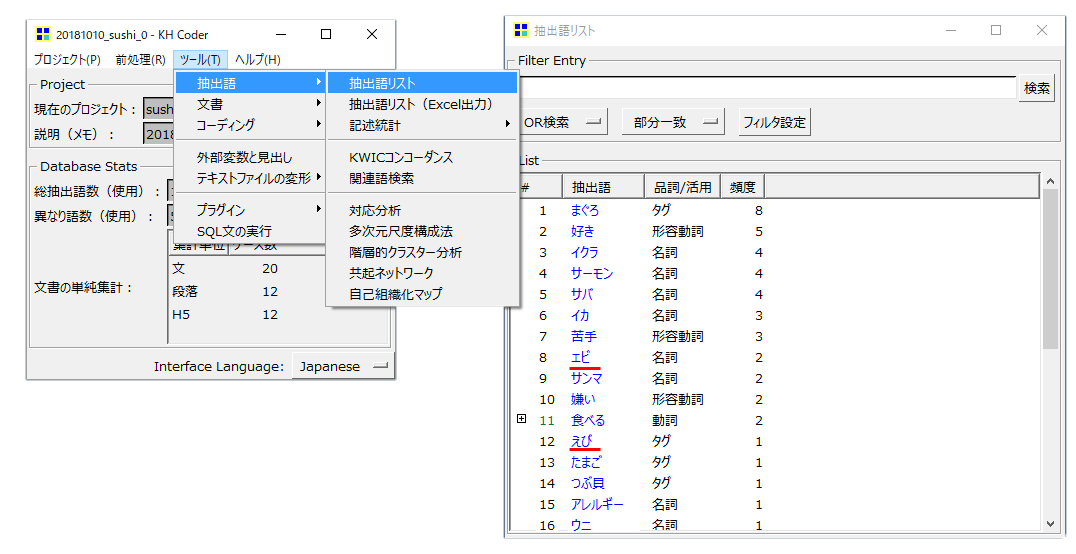
抽出語リストをよく見ると、「エビ」「えび」の同義語があります。
このまま分析に入ると「エビ」「えび」は別の「語」として出現回数をカウントされて分析が実行されます。
そこで、「エビ」「えび」をひとつの「語」にします。その他では「イクラ」「いくら」もあります。
今回は、
・「エビ」「えび」→「海老」
・「イクラ」「いくら」→「イクラ」
このように変更する手順を解説します。
表記揺れの吸収ファイルを確認


・「KHcoder3」フォルダー内「plugin_jp」フォルダーを開きます
・「z1_edit_words3.pm」このファイルがあるか無いかを確認します。
・ファイルが無い場合は、
表記揺れの吸収(KH Coder 3対応および機能改善)
開発者 樋口先生の掲示板から「plugin_jp」フォルダー内へダウンロードします。
表記揺れの吸収は「z1_edit_words3.pm」ファイルによって機能するしくみです。
このファイルを「分析対象テキスト」ごとにカスタマイズすれば、異字同義語を1「語」に一本化することができるようになります。
「z1_edit_words3.pm」の変更
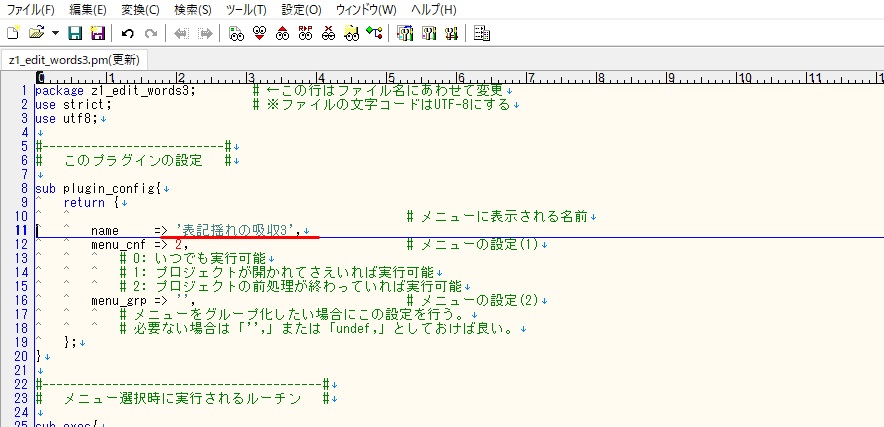
・「z1_edit_words3.pm」をテキストエディタで開きます。
ワードはダメです。
・11行目を変更します。
・’表記揺れの吸収’→’表記揺れの吸収3’
これは念のための変更です。
「plugin_jp」フォルダー内に「z1_edit_words.pm」ファイルがある場合、ここを変更しておかないとうまく作動しない可能性があるからです。

'友達' => [ '友人', '旧友', '親友', '盟友', '友', ],
30行から37行がひとつのブロックです。
・ここを書き換えます。
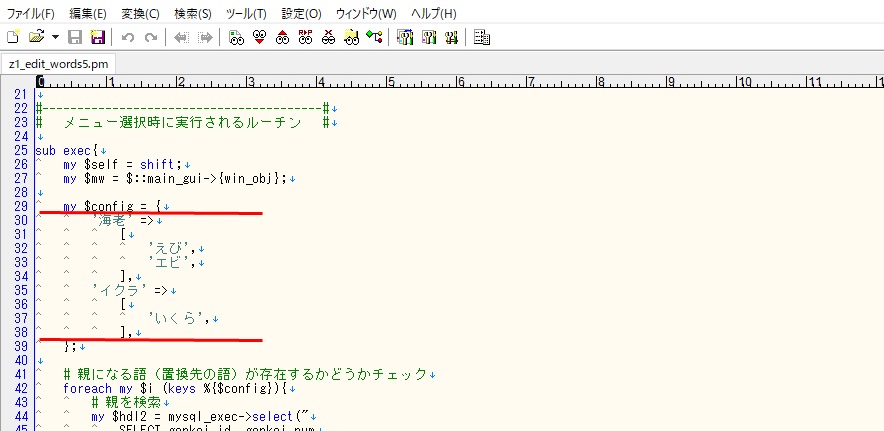
'海老' => [ 'えび', 'エビ', ], 'イクラ' => [ 'いくら', ],
・このように書き換えます。
・不要な行は削除します。
・上書き保存して閉じます。
「語」を増やす方法
my $config = {
ここの間へ上記のようなブロックを追加します。
};表記揺れの吸収実行

・「KHcoder」をいったん終了します。
・「プロジェクト」→「開く」からプロジェクトを開きます。
・「ツール」→「プラグイン」をクリックしたときに「表記揺れの吸収3」があるはずですからクリックします。
分析途中で「z1_edit_words3.pm」ファイルを書き換えた場合も「KHcoder」をいったん終了してください。
確認します

・「ツール」→「抽出語」→「抽出語リスト」
「海老」が抽出されました。
・以前は「エビ」×2回、「えび」×1回でしたが「海老」×3回になっています。
・「いくら」「イクラ」が合体して5回になりました。
プラグインが反映されていないときは、
・「前処理」→「前処理の実行」→「表記揺れの吸収」をやってみる。
・それでもダメならファイルへの記述が間違えている可能性があります。
ちなみに「前処理」を実行すると「表記揺れの吸収」はいったんリセットになります。分析途中で「前処理」を実行した場合は再度「表記揺れの吸収」を実行してください。
分析対象テキストを書き換えているのではありません

この機能を使うと「エビ」「えび」が「海老」に書き換わったように見えます。抽出語リストには「海老」が抽出されます。これは、分析対象テキストが書き換わるものではありません。
「エビ」「えび」が「海老」に見えているだけです。
・「ツール」→「抽出語」→「抽出語リスト」→「海老」をクリックします。
・「KWICコンコーダンス」が開きます。
「海老」という「語」はありません。書き換わったのではなくて、置き換わったのです。「海老」は「エビ」「えび」の活用形に置き換わりました。
ファイルの増やし方

「z1_edit_words3.pm」ファイルへどんどん「語」を追加することが可能です。「語」を追加することで各種分析対象テキストへ適用できようになります。
しかし、このファイルの一部は適用したいが、一部は適用したくない場合もあります。そうなるとファイルを増やす必要があります。
変更する箇所は
・ 1行目
・z1_edit_words5
・ファイル名の末尾を変更します。
・11行目
・’表記揺れの吸収5′
・メニューに表示される名前の末尾を変更します。
・変更したファイル名「z1_edit_words5」で同じフォルダーに保存します。
「KHcoder」をいったん終了してリスタートすると「表記揺れの吸収5」ができているはずです。