
KHcoder 18. 階層的クラスター分析(抽出語)
階層的クラスター分析手順、結果の見方、Rでの計算ロジックについて解説しています。
テキストマイニングツール「KHcoder」の活用メモ
開発者である樋口先生に感謝!
【今回の分析対象テキストはこちらからコピーできます】
分析手順と結果
抽出語の階層的クラスター分析とは
KHcoderには「抽出語」と「文書」のクラスター分析をそれぞれ行う機能があります。今回は「抽出語」のクラスター分析をとりあげます。
KHcoderでおこなうクラスター分析結果(抽出語)から何を読みとることができるのでしょうか。
クラスター分析結果とは、似ているもの、つまりクラスターを形成してゆく過程と結果をあらわすものです。(クラスター分析の詳細について今回は取り上げないので、こちらをご参照ください。
各「抽出語」の何が似ているのか?というと「出現パターンが似ている」という解説が一般的です。
では、「出現パターン」というのは何なのか?この謎が解ければ分析結果から何を読みとることができるのかという疑問が解けるのだろうと思います。
分析手順
・「ツール」→「抽出語」→「階層的クラスター分析」の順ですすみます。
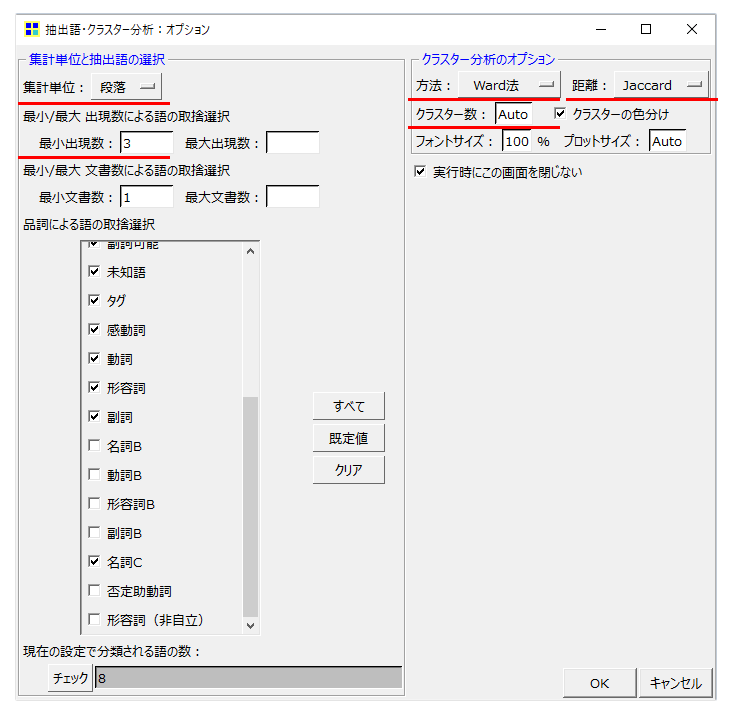
・「集計単位」を「段落」にしました。
この設定に「出現パターン」のヒントがあります。
KHcoderの抽出語分析は、
・「語」が出現する場所
・「語」が出現する回数
これらの両方を分析します。
階層的クラスター分析の「集計単位」を
・「段落」に設定すると、「語」が、どの「段」に何回出現しているのか
・「文」に設定すると「語」がどの「文」に何回出現しているのか
を計算します。
・「最小出現数」は少ない方が解説しやすいので3にしました。
・「クラスター分析のオプション」はデフォルト設定のまま「Ward法」「Jaccard」です。
・クラスター数は「auto」です。
一般的に「階層的」クラスター分析はクラスター数を指定しません。「非階層」クラスター分析はクラスター数を指定する分析と定義されています。
「auto」だからいったんは「階層的」です。あとでクラスター数を直接入力して変更することが可能です。
分析結果
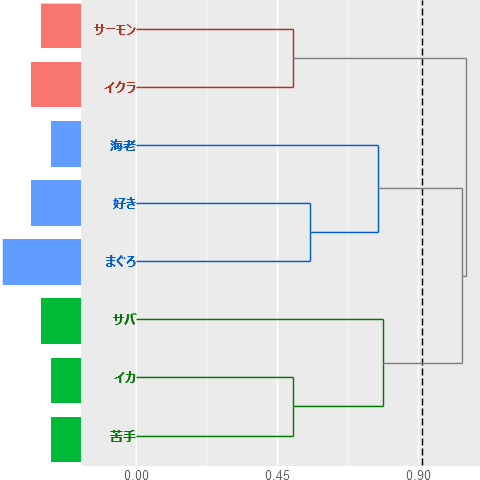
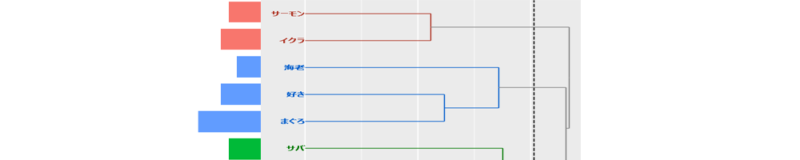
クラスターが3個形成されました。クラスター形成の過程をみていきます。樹形図を左からたどると、
・はじめに「サーモン・イクラ」の群(そのままクラスターになる)
と「イカ・苦手」の群が同時に形成されます。
・次に「好き・まぐろ」の群が形成されます。
・さいごに、「好き・まぐろ」の群に「海老」が加わるクラスターと「イカ・苦手」の群に「サバ」が加わるクラスターが同時に形成されます。
・この時点で「サーモン・イクラ」「好き・まぐろ・海老」「イカ・苦手・サバ」のクラスター数が3になります。
ちなみに樹形図の左側にあるバーは「語」が出現する回数を示します。
この結果から解ることは、
・例えば(青いクラスター)、「好き」「まぐろ」「海老」の出現パターンが似ているということです。
しかし、「出現パターン」の意味が理解できないので残念ながら分析結果から何かを読みとることは難しい感じがします。
計算方法
データ
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [サーモン] 1 1 0 1 0 0 0 0 0 0 0 1 [サバ] 0 0 0 0 1 0 1 0 0 0 1 1 [イカ] 0 1 0 0 0 0 1 0 0 1 0 0 [好き] 1 0 0 0 1 1 1 0 0 1 0 0 [苦手] 0 1 0 0 0 0 1 0 0 0 0 1 [まぐろ] 1 1 1 0 1 1 0 1 1 1 0 0 [イクラ] 1 1 1 1 1 0 0 0 0 0 0 0 [海老] 0 0 1 0 0 1 1 0 0 0 0 0
クラスター分析用のマトリクス型データです。
・行が「語」
・列が「段」のid(KHcoderは「段」にidを付与している)です。
・数値は「語」が「段」に出現する回数です。
このデータに基づいて「語」と「語」の距離を算出してクラスターを形成します。
出現パターンとは
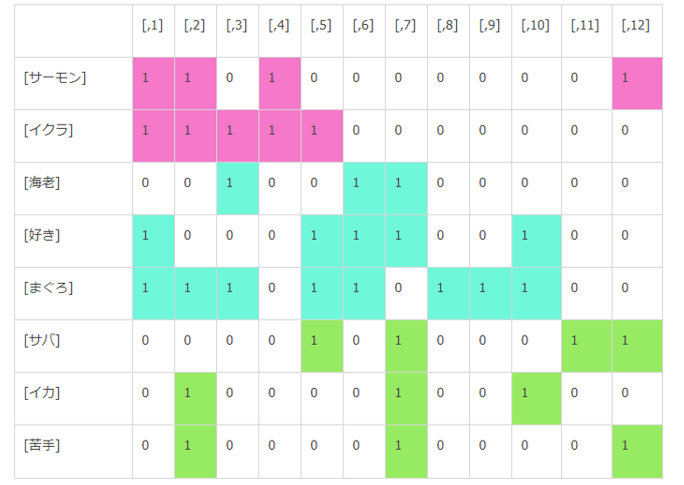
クラスター形成に使用するデータは「語」がどの「段」に何回出現するのかを示すものです。
「語」をクラスター分析結果順に並び替えて「語」が出現している「段」に色をつけました。これが「語が出現するパターン」です。
実際には、Jaccard係数が高い「語」と「語」が同一クラスターを形成しやすくなります。
クラスター分析結果とは、「語」と「語」のJaccard係数の関係をビジュアライズしたものだと理解すればよいのですが、クラスター分析の特性上、完全にJaccard係数と一致(または比例)するものではないことに注意が必要です。
Jaccard係数は高いが違うクラスターになる
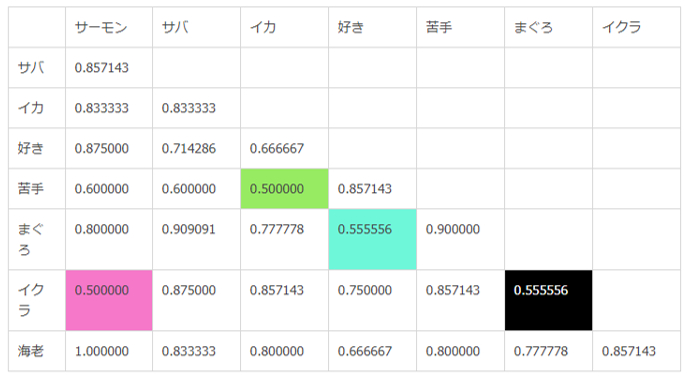
「語」と「語」の距離を算出しました。
クラスター形成の過程は距離が近い「語」どうしが群を形成しクラスターに成長します。
・「サーモン・イクラ」「イカ・苦手」(距離0.5)の群がはじめにできます。距離が同じということは同時に群が形成されるということになります。
・次に「好き・まぐろ」(距離0.555556)が群になります。
・ところが「まぐろ・イクラ」の距離も0.555556で「好き・まぐろ」と同じだから「まぐろ・イクラ」と同時に群を形成するはずです。
しかし、「まぐろ」と「イクラ」は最後までくっつきません。
これは「好き・まぐろ」が先に群を形成しているから、形成された群と「語」の距離を次の計算として開始するために発生する現象です。
この再計算の手法がはじめに設定した「ward法」です。オプションで「群平均法」「最遠隣法」もあります。
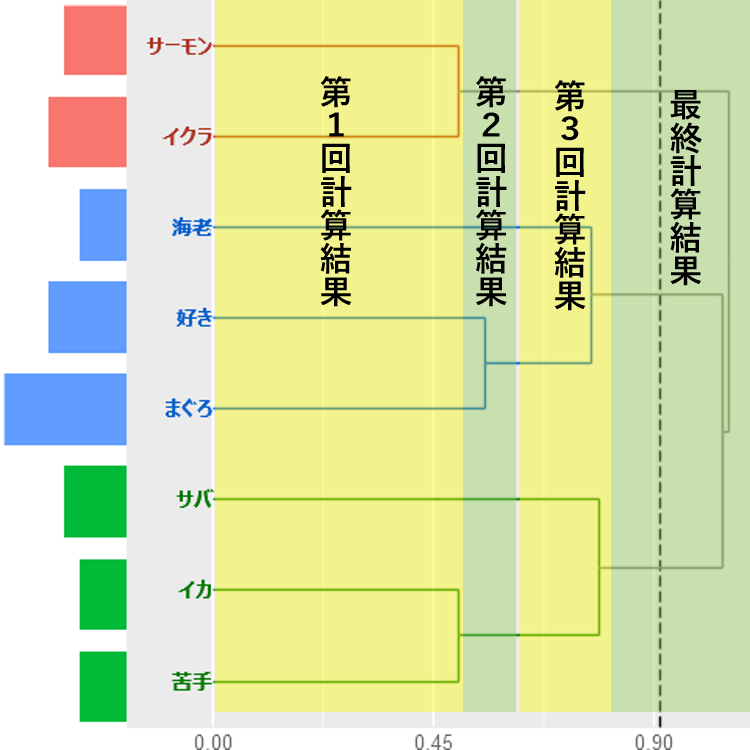
クラスター形成の過程は、
・すべての「語」と「語」の距離を計算する→群を形成する
これで計算はいったん終了
・形成した群と、残りの「語」との距離を計算する→上位の群を形成する
追加で新規の計算がはじまり、いったん終了
・追加計算→くりかえし
計算が完全に終了するまで繰り返す
このように群の形成と再計算の実施によってJaccad係数が高いが同一クラスターにならない現象が発生します。