
KHcoder 14. 対応分析(第1回)
対応分析の初期設定から操作手順、結果の見方。赤い四角と青い丸について解説しています。
テキストマイニングツール「KHcoder」の活用メモ
開発者である樋口先生に感謝!
【今回の分析対象テキストはこちらからコピーできます】
対応分析設定
分析対象にする「語」数を制限する機能

<最小/最大出現数による語の取捨選択>
この「分析対象テキスト」ではデフォルトで2が設定されます。
「分析対象テキスト」の総語数等からKHcoderが分析に適切な語数をデフォルトで示してくれます。基本的にはKHcoderに従います。
・まずは変更せずそのまま分析してみます。
結果をみてから変更することはよくありますが、程々の数値にとどめておくべきです。
・小さい数値に設定するということは、多くの「語」を分析対象にすることになります。
全部みたい!というのが本音としても、あまりにも多い「語」数にすると結果が見にくくなる、あるいは、分析処理に時間を要する、または、固まって動かなくなることもあります。
・今回は、以下の説明を解りやすくするために3に設定しました。
<最小/最大文書数による語の取捨選択>
・分析対象にする「語」数を設定(制限)する機能です。
・すぐ下にある「文書とみなす単位」ボタンとセットで使います。
この機能は文書数を設定するものではありません。設定するのは「語」の取捨選択ですから1文書以上に出現する「語」、とか、2文書以上に出現する「語」のように分析対象にする「語」数を設定する機能です。
・「文書とみなす単位」=5「段」のとき
「語」が出現する「段」数が5以上あるかないかを判定します。5「段」以上のに出現する「語」を分析することになります。
・「文書とみなす単位」=5「文」のとき
「語」が出現する「文」数が5以上あるかないかを判定します。5「文」以上に出現する「語」を分析することになります。
「文書とみなす単位」のボタンを分析単位だと勘違しがちですが、対応分析は「語」が出現する「段」数、「文」数とは無関係です。
<品詞による語の取捨選択>
・デフォルトでいくつかの品詞が除外されています。
・除外されている品詞の中に重要な「語」が含まれている場合は分析対象にしてください。
分析方法の設定
<分析に使用するデータ表の種類>
対応分析の活用シーンで最も多いのが「外部変数」と「語」の分析です。
・「抽出語×外部変数」をチェック
・窓のなかの「外部変数」を選択します
・「外部変数」の複数選択が可能ですが、分析手法としてはオススメしません。
<差異が顕著な語を分析に使用>
・デフォルトのままでOKです。
<原点から離れた語のみラベル表示>
・デフォルトのままでOKです。
・出力結果が見えにくい場合はチェックしてやり直してください。
<バブルプロット>
・デフォルトではチェックされていませんが、チェックしてください。
・出力結果が見えにくい場合はチェックを外してやり直してください。
<原点付近を拡大>
・デフォルトのままでOKです。
・中央付近に「語」が集中しすぎて出力結果が見えにくい場合はチェックしてやり直してください。
ただし出力結果は見えやすさを優先するものですから、純粋な解析結果とは違うものになります。
<プロットする成分>
・デフォルトのままでOKです。
・外部変数が2項目のみの場合は、自動でX軸1・Y軸1になります。
<実行時にこの画面を閉じない>
・チェックすることをオススメします。
チェックしておくと、分析をやり直すたびに「ツール」→「抽出語」→「対応分析」をクリックする必要がなくなります。
出力画面解説
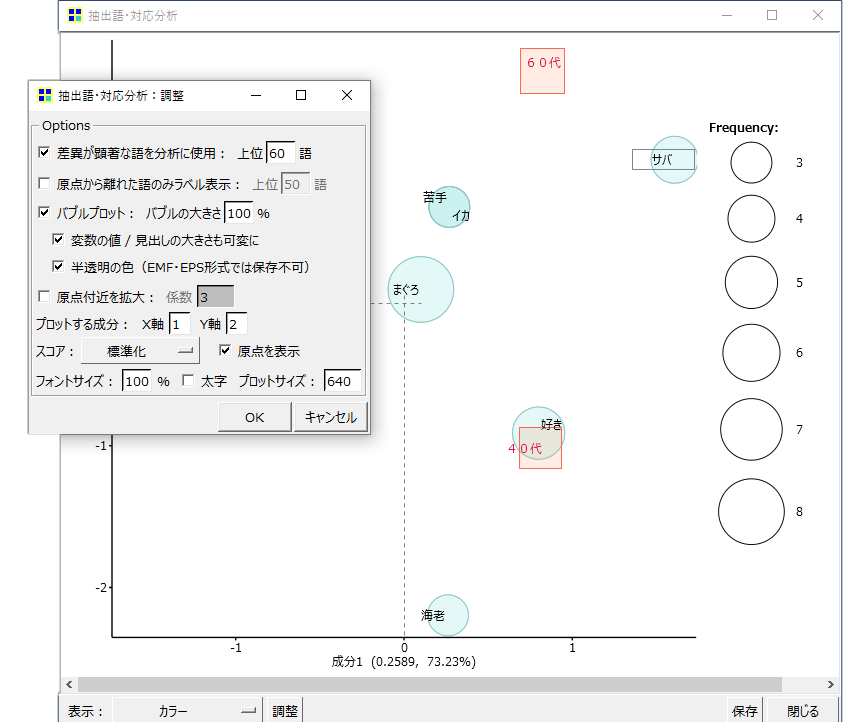
・左下の「調整」をクリックするとウインドウが開きます。
結果が見にくいとき、バブルプロットにチェックをわすれたとき等、この画面で調整します。
・右下の出力をクリックすると分析結果を画像やデータでほぞんすることができます。
・主にPNG、CSV、Rsorceを使います。
・プロットされている「語」をクリックすると「KWICコンコーダンス」が開きます。
分析結果の見方
青い丸と青い丸の位置関係
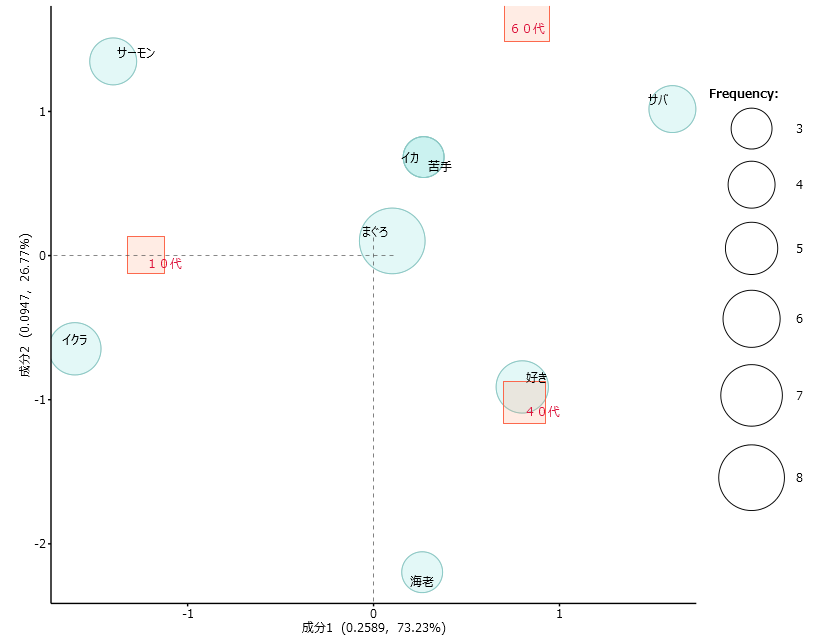
・青い丸は「語」
・赤い四角は「外部変数」です。
対応分析結果は、青い丸と青い丸、青い丸と赤い四角、赤い四角と赤い四角の位置関係をみます。
<青い丸と青い丸>
「苦手」と「イカ」は完全に一致しています。
| テキスト | 年代 |
| 好物はたまご、いくら、まぐろ、サーモン。イカは苦手。 | 10代 |
| イカとかエビのようなあっさりしたネタが好き。サバが苦手。 | 40代 |
| まぐろ、サラダ巻とかも好きです。イカは固いので食べない。 | 60代 |
| サバ、あじ、サンマのような青魚が体にいい。脂っこいサーモンとかは苦手です。 | 60代 |
「イカ」が出現している場所は
・10代で1回
・40代で1回
・60代で1回
「苦手」が出現している場所は
・10代で1回
・40代で1回
・60代で1回
「苦手」と「イカ」が出現する外部変数は全く同じです。「語」が出現回数も3回で同じですから、ぴったりと重なります。
・青い丸の位置は各外部変数ごとに出現する回数で決まります。
「イカ」・「苦手」の近くにある「まぐろ」は、各外部変数に対して「イカ」・「苦手」と同じような出現をしている「語」になります。
青い丸と赤い四角
青い丸の位置は各外部変数ごとに「語」が出現する回数で決まるわけです。
赤い四角の近くにある青い丸はその外部変数のなかに多く出現しているといえます。
| テキスト | 年代 |
| イクラ、サーモン、まぐろが好き。 | 10代 |
| 好きなのはイクラとまぐろ。サバが嫌い。 | 40代 |
| 鯛とまぐろが好き。エビはアレルギーがあるからダメ。 | 40代 |
| イカとかエビのようなあっさりしたネタが好き。サバが苦手。 | 40代 |
| まぐろ、サラダ巻とかも好きです。イカは固いので食べない。 | 60代 |
実際に「好き」は
・10代で1回
・40代で3回
・60代で1回
それぞれ出現しています。
そうなると、「好き」は青い四角の「40代」の近くにプロットされます。
赤い四角と赤い四角
・赤い四角は各外部変数に出現する「語」の種類と出現回数で決まります。
・赤い四角どうしが近くにある場合、出現する「語」の種類と回数が似ているといえます。
仮に10代と40代の赤い四角が四角にあれば、10代の嗜好と40代の嗜好は似ていると考えることができます。
ただし対応分析はできるだけ違いを強調する傾向にあるため、
・外部変数が3のとき正三角形を描こうとします。
画面を目いっぱい使おうと努力します。
ちなみに「外部変数」が12あるIDで分析するとこのような結果になります。
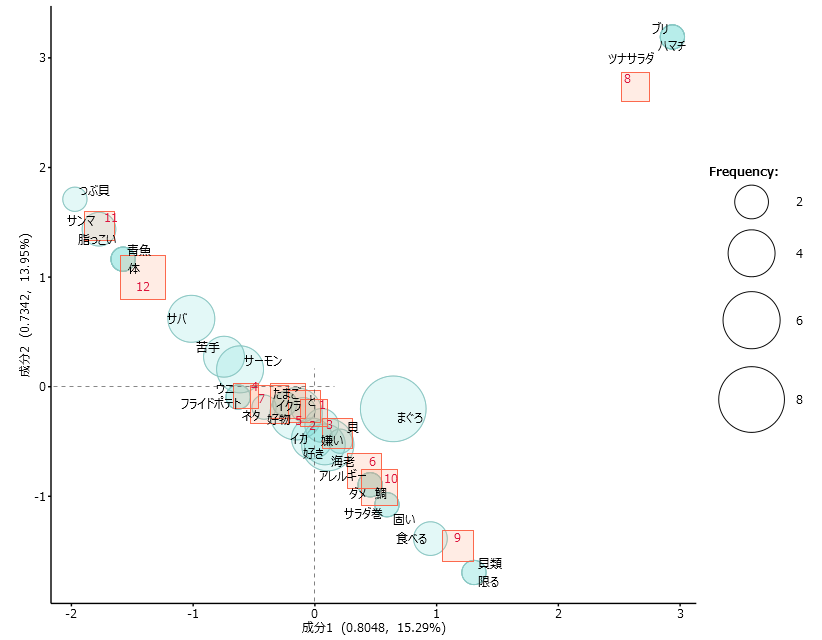
| テキスト | 年代 | 性別 | サイト | ID |
| ハマチ、ブリ、まぐろ、ツナサラダです。 | 40代 | 女 | B | 8 |
・「8」だけ、ぽつんとした位置になります。
もともとのテキストはこのようになっています。「まぐろ」を含むから、もっと左下にプロットしてもよいと思いますが「ツナサラダ」「ブリ」「ハマチ」を含んでいるためぽつんとプロットされました。
スケールには意味があるのか
スケールの数値にはほとんど意味がありません。
対応分析や共起ネットワーク図は世界地図にようなものです。世界地図は球面を平面に描きます。
日本を中心にした平面世界地図で世界各国の
・位置(角度・方向)
・距離
・各国の大きさや形状(中心にある日本さえ)
これらを同時に満たす平面地図はありません。