
KHcoder 9. 抽出語機能
抽出語リスト、エクセルでの出力、KWICコンコーダンスについて解説しています。
テキストマイニングツール「KHcoder」の活用メモ
開発者である樋口先生に感謝!
【今回の分析対象テキストはこちらからコピーできます】
抽出語リスト
抽出語について
繰り返しになりますが。KHcoderは「分析対象テキスト」のなかで「語」が出現する場所と「語」が出現する回数を計算して分析結果をビジュアル化します。
抽出語というのはまさに分析単位の「語」のことで、最小の分析単位ということになります。そして最終的なテキストマイニング分析結果は、この抽出語の抽出方法いかんによって大きく違うものになります。
抽出されている「語」が分析対象になるから、逆に抽出されていない「語」は分析対象になりません。仮に「分析対象テキスト」のなかで100回使用されている「語」であっても抽出されていなければ完全に無視されます。
また、意味不明の「語」が抽出されていると当然ながらそれが分析対象になるので、分析結果に意味不明のまま登場することになります。
重要な「語」が意味不明の「語」に追いやられて埋没することもあります。KH coder へ「分析対象テキスト」を読み込んでからまず確認するのが「抽出語」です。
そして分析結果を見ながら、また抽出語へ立ち戻り抽出方法を変更することもしばしばあります。
抽出語リスト
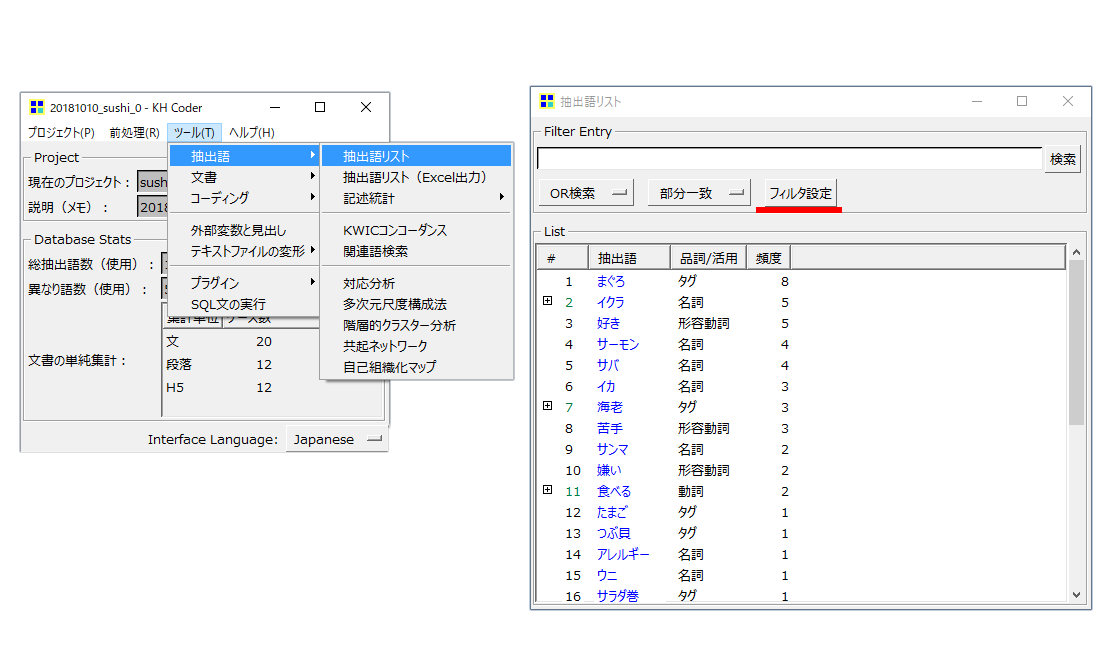
・「ツール」→「抽出語」→「抽出語リスト」の順でクリックします。
頻度降順で抽出語が表示されます。
・頻度は「語」の出現回数です。
「語」が出現する「段」数や「文」数ではありません。
分析結果としてあらわれる数値が、「語」の出現回数なのか、「語」が出現する「段」あるいは「文」数なのかはしっかり理解しておく必要があります。
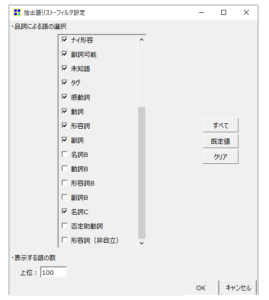
・「フィルター設定」をクリックます。
デフォルトの状態の状態では品詞にフィルターがかかっていていくつかの品詞が除外されています。
はじめから、
名詞B、動詞B、形容詞B、副詞B、否定助動詞、形容詞(非自立)が除外されています。
はじめからいくつかの品詞のチェックが外れています。
これら除外されている品詞は各種分析のときにもデフォルトの状態では、はじめから除外されています。
助詞や助動詞はそもそも品詞としてさえありません。確認したい場合はチェックを入れるか、「すべて」を押してから「OK」を押します。
「語」は上位100になっているので、もっと多くをみたいときは、数値を変更して「OK」を押します。
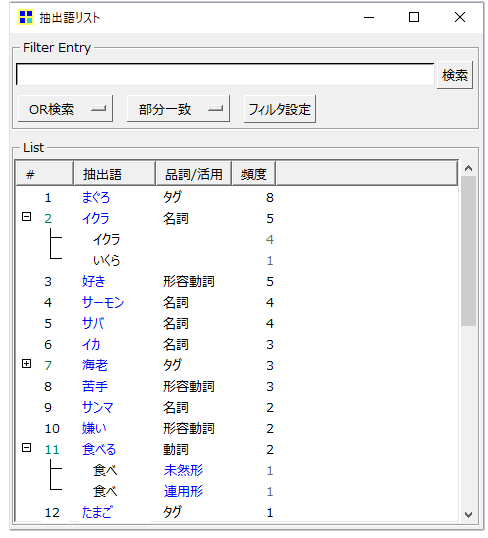
・左端にある⊞マークを押すと「語」が開きます。
「イクラ」は「イクラ」と「いくら」を「イクラ」1語で抽出しています。
KHcoderは「語」の活用形をひとつの「語」にまとめる機能があります。
「食べる」という「語」は分析対象テキストにはないけれど「食べ」を「食べる」として抽出しています。
抽出された「語」を確認することは本当に重要です。
抽出したい「語」がバラバラになっていたり、余計な文字ががくっついているようなこともあります。出現回数上位の「語」は必ずチェックすることをオススメします。
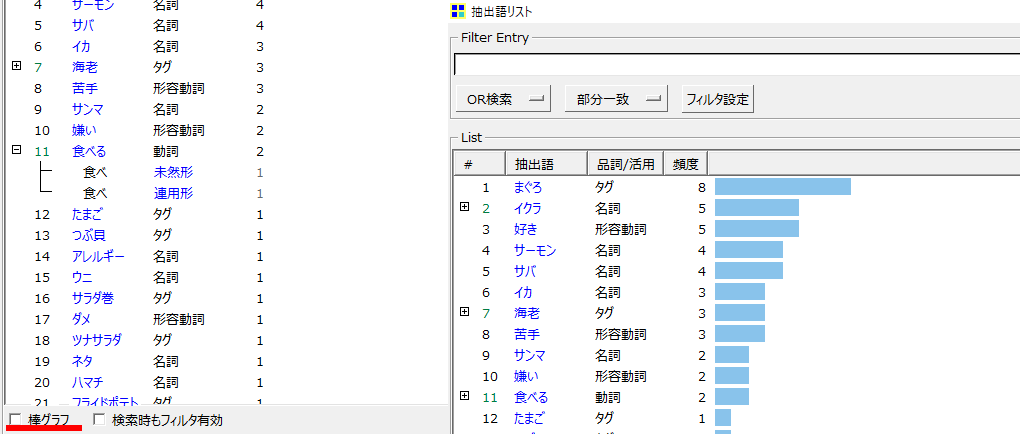
抽出語リストのウインドウを画面いっぱいに広げると左下にチェックボックスがあります。
・棒グラフにチェックすると表示が棒グラフに変ります。
「OR検索」「部分一致」は検索フィルターの設定です。
・検索窓へ「語」を入力、フルタ―を選んで「検索」を押します。
・検索窓へ2語以上を入力するときは、あいだにスペース(半角でも全角でもOK)を入れます。
KWICコンコーダンス
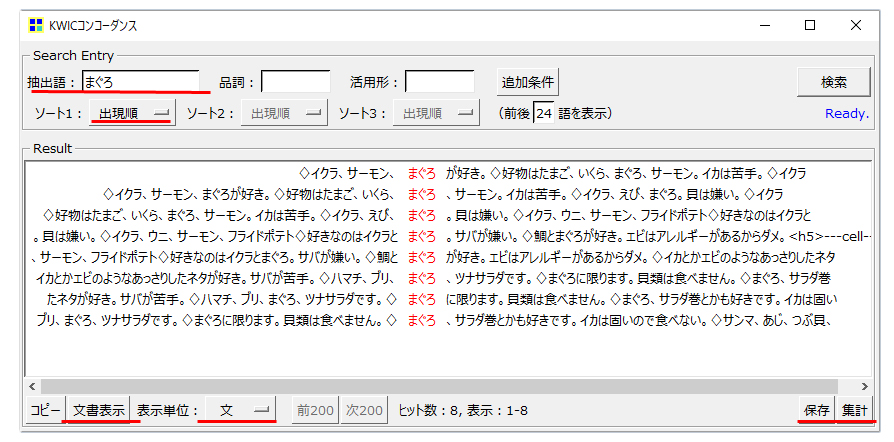
・抽出された「語」をクリックするとKWICコンコーダンスが開きます。
「まぐろ」をクリックすると「まぐろ」という「語」が「分析対象テキスト」のなかでどのような使われ方になっているのか、「まぐろ」を含む前後の「語」を含めた「文」「段」を表示できます。
使われ方が難しい「語」で、例えば「よい」がどのように使われているのかなどを確認できます。
詳しい機能は後述します。
抽出語リスト(EXcel出力)
抽出語リストの形式
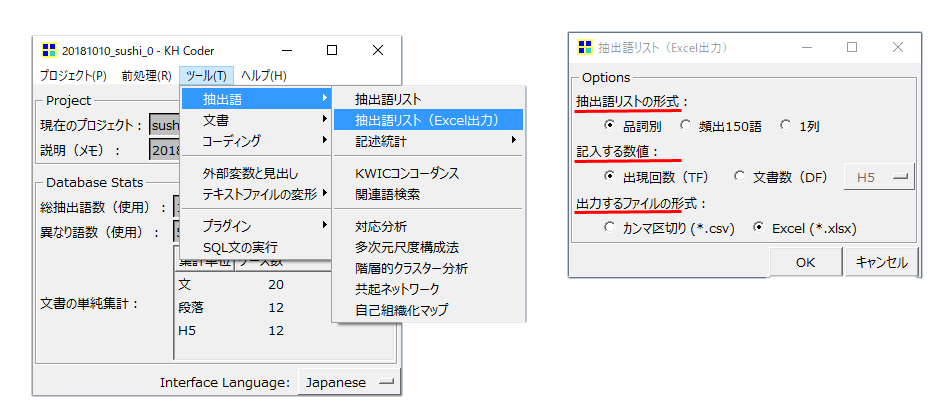
デフォルトは「品詞別」です。
・デフォルトのまま「OK」を押します。

行が「語」列が「品詞」のエクセル表が開きます。
「語」の横の列の数字は分析対象テキストのなかで、その「語」が出現する回数です。
このファイルは保存する必要がありません「khcoder3」「config」「khc155」フォルダーの中へ表記のファイル名で自動保存されます。
名詞、形容動詞、動詞、形容詞のあたりを中心に「語」がうまく抽出できているのかをチェックします。
出現回数上位によくわからない「語」が抽出されているときは抽出すべき「語」がバラバラに分解されていることが結構あります。
品詞「タグ」は強制抽出した「語」です。

・「抽出語リストの形式」=「頻出150語」
このような表になります。50語の列×3列の表です。個人的には使用したことがありません。

・「抽出語リストの形式」=「1列」
これは頻繁に利用します。出現回数降順で抽出されますが、「抽出語」の列を降順・昇順にならび替えて「語」をチェックします。例えば「スマホ」と「スマートフォン」が混在しているとかに気付きます。
記入する数値

・「記入する数値」=「文書数(DF)」に設定
デフォルトで「H5」になっている部分をクリックできるようになります。。
「H5」は「語」が出現する「H5」をカウントします。
・「段落」の場合は「語」が出現する「段」数をカウントします。
・「文」を選択した場合は「語」が出現する「文」数をカウントします。
・「記入する数値」=「文書数(DF)」
これも便利です。「文書数 (H5)」は「段落」のことです。「語」が出現する「段」数をカウントしています。「語」が出現する回数ではありません。

サンプルデータはアンケート様式ですから「文書数 (h5)」=回答者数 です。例えば「まぐろ」は12人中8人がアンケートに記載している「語」だということがわかります。
何に活用できるのか

① 「語」のチェックです。
② 「コーディング」するときのファイルとして使います。
③ 分析するときのデータとして使います。
エクセルですから簡単にグラフ化等ができます。
レポーティングの元データとして、活用できます。
【今回の分析対象テキストはこちらからコピーできます】