
KHcoder 19. クラスター分析(文書)
文書のクラスター分析とは?対応分析や決定木分析でも文書間の類似性や違いをあらわすことができる。
テキストマイニングツール「KHcoder」の活用メモ
開発者である樋口先生に感謝!
【今回の分析対象テキストはこちらからコピーできます】
クラスター分析(文書)
抽出語のクラスター分析との違い
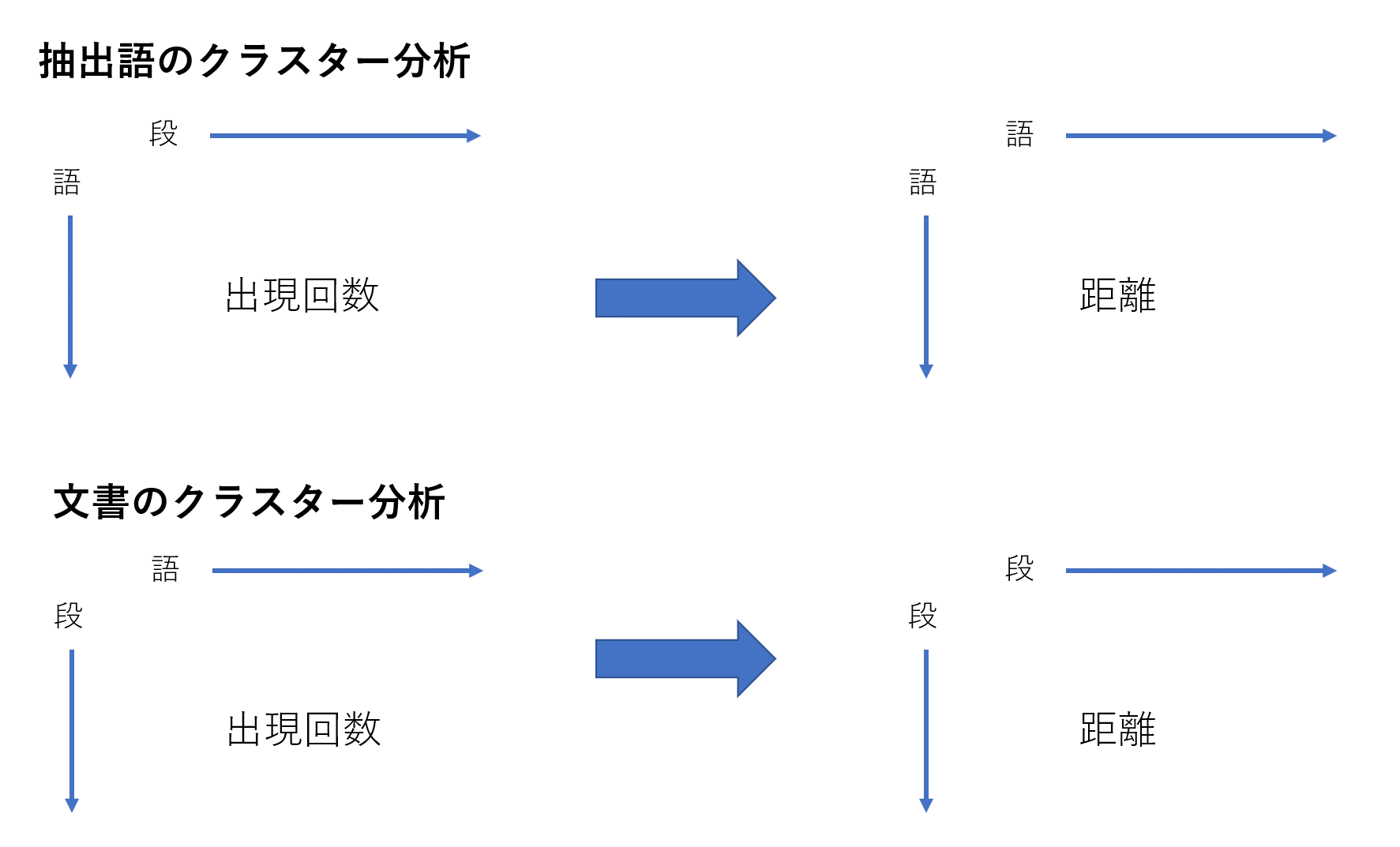
抽出語の階層的クラスター分析は「語」をクラスタリングします。
図のように「語」が行、「段」(文書)が列のマトリクスを用意して「語」がどの「段」に何回出現するのかを基準に、「語」と「語」の距離を計算した結果を用いてクラスターを形成します。
今回解説する文書のクラスター分析は
・文書(「H5」・「段」・「文」)をクラスタリングします。
「語」のクラスター分析とは逆に
・行が「段」列が「語」のマトリクスから
・「段」と「段」の距離を計算してクラスターを形成します。
文書のクラスター分析は「段」(文書)にどのような「語」が何回出現するのかを計算して類似している「段」をクラスタリングします。
分析手順

・「ツール」→「文書」→「クラスター分析」
・集計単位を「段」、最小出現数を3に設定しました。
・その他の設定はすべてデフォルトです。
・一番下の「クラスター数」がデフォルトで10に設定されたのでそのまま進みます。
今回の「分析対象テキスト」は12段で構成されています。「クラスター数」が多くても段数が少ないので、出力される結果の樹形図を目で追えば類似している「段」を確認することができます。
段数が多い場合は目視で確認することが難しくなるので、クラスター数を少なくしたほうが結果を読みやすくなります。「分析対象テキスト」の「段」数に応じてクラスター数を調整しながら何度か試してみることをオススメします。
結果

・分析結果が開きます。
・クラスター1の文書数が2になっています。これはクラスター1が2つの「段」で構成する構成されているという意味です。
・クラスター1を選択した状態で→「文書検索」をクリック
・「文書検索」(画像の右上)が開きます。クラスター1を構成する2つの「段」が表示されます。
「段」数が2、「共起」が2ですからクラスター1を構成する2「段」で「まぐろ」が共起していることがわかります。
・「特徴語」をクリックします。
・「関連語検索」が開いて共起の関係と「まぐろ」のJaccard係数を確認することができます。
「まぐろ」だけが唯一共起している「語」であることがわかります。ここでのJaccard係数は重要ではないと考えていますが、ちなみに計算方法を解説しておきます。
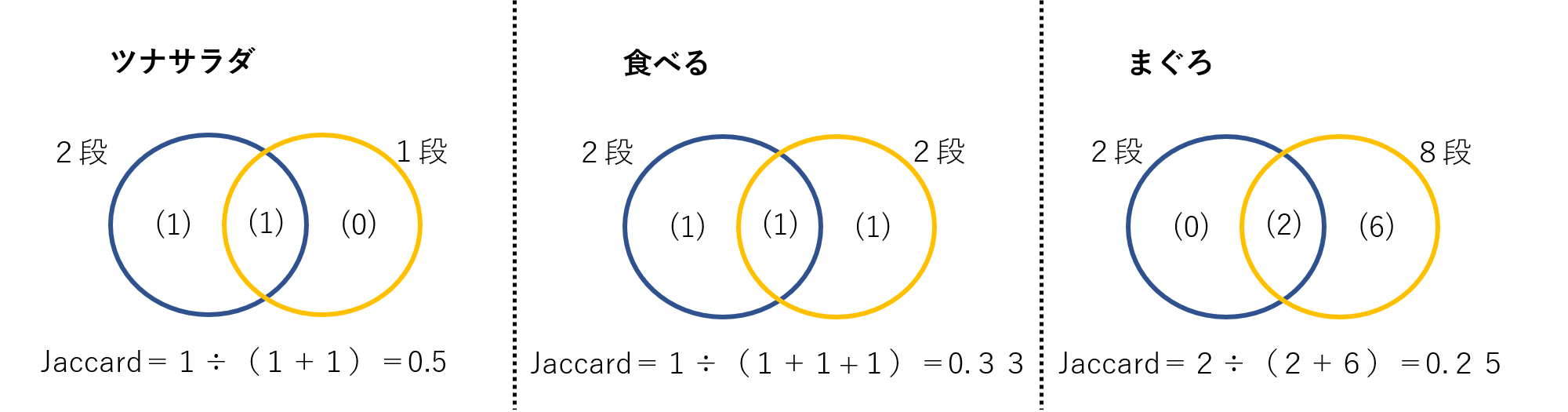
選択したクラスターは2「段」ですから左側(青色の円)の集合は常に2になります。
右側(黄色い円)の集合は「分析対象テキスト」全体のなかで「語」が出現する「段」数ですから「語」により違ってきます。
「段」が同じクラスターになるということ
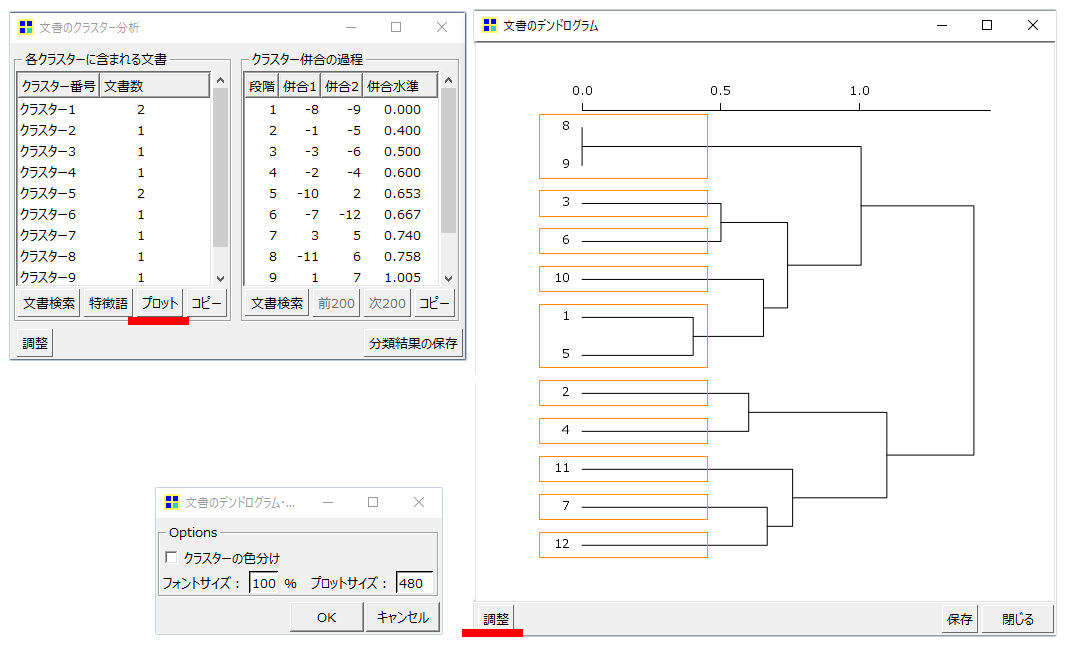
・「プロット」をクリックします。樹形図が開きます。
同一クラスターになる「段」と「段」は「語」の出現の仕方が似ています。
・分析結果からID8とID9がまっ先にクラスターを形成します。
ですからコンピューターは、このID8とID9がすべての「段」に先んじて似ているという計算をしているということです。
| ID | テキスト |
| 8 | ハマチ、ブリ、まぐろ、ツナサラダです。 |
| 9 | まぐろに限ります。貝類は食べません。 |
ID8とID9はこのような内容です。先に書いた通り共起しているのは「まぐろ」だけです。
| ID | テキスト | 年代 |
| 1 | イクラ、サーモン、まぐろが好き。 | 10代 |
| 2 | 好物はたまご、いくら、まぐろ、サーモン。イカは苦手。 | 10代 |
感覚的にはID1とID2のほうがよほど似ていると思うのですが、ID1とID2は最後の最後までくっつきません。
ID8とID9がまっ先にくっつく理由として、共起している「語」が「まぐろ」だけであり、逆に言うと「まぐろ」以外はすべて違う「語」だからこそ似ている「段」とう計算結果になるのだと想像できます。
ID1とID2は「まぐろ」「イクラ」「サーモン」が共起していて、それ以外がちょっと違う。だからID1とID2のほうがID8とID9よりも似ていると、おそらく多くの人が判断すると思います。人間の感覚的な判断とコンピューターの計算結果のあいだににズレがあるように感じます。
人とコンピュータとの境界線
コーディングのところで「ヤバイ」をとりあげました。
「ヤバイ」はGoodなのかBadなのかをコンピュータは判断ができません。人は「ヤバイ」を前後の文章、全体の文脈、あるいは「ヤバイ」と言った人の過去の発言内容、性格などを総合的に鑑みて「ヤバイ」をGoodかBadかに仕分けることができます。
コンピューターにとって「ヤバイ」は文字列(記号)であって、それがどこに何回出現しているとか、前後に現れる「語」は何が多いといった計算をあっという間にこなしますが、ことばの意味を理解するところまでは現在到達していません。
それでは、人はID1とID2がなぜ似ているように思うのかというと「まぐろ」「イクラ」「サーモン」が寿司ネタを意味し、寿司ネタを意味する「語」が共起しているからです。
「分析対象テキスト」は好きな寿司ネタがテーマです。
従って人は寿司ネタを中心に文書の意味を考えるはずです。それならコンピューターにたいして、出現する「語」が寿司ネタであるのかどうかの意味を与える方法か、寿司ネタではない「語」を除外する方法かを教えればこの課題は解決できそうです。
コンピューターに意味を与える方法がコーディングです。
しかし文書のクラスター分析ではコーディングが利用できません。従って寿司ネタではない「語」を除外する方法でやってみます。こうすれば寿司ネタ以外の「語」の共起が除外されます。そして共起している「語」が多い「段」と「段」がクラスタリングされればOKです。
寿司ネタだけ
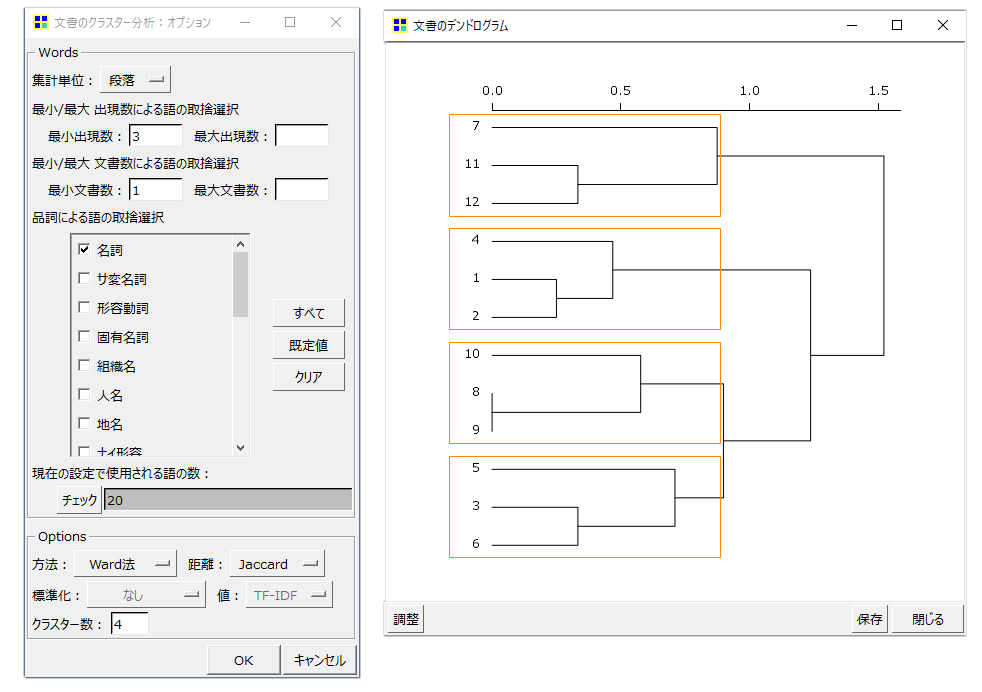
・「最大出現数」を3、品詞を「名詞」と「タグ」だけに設定しました。
これで「サーモン」「サバ」「イカ」「まぐろ」「イクラ」「海老」の6「語」がクラスター分析の対象「語」になります。見やすいようにクラスター数を4で設定しました。

結果をまとめました。注目点は「まぐろ」「イクラ」を含まないクラスター①が形成されて、それが最後まで他のクラスターとくっつかないことです。
クラスター②、③、④の内容をみると、よくできている感じがします。今回は偶然なのか何かしりませんが、文書のクラスター分析の対象になる「語」を絞り込むことでちょっといい感じのクラスタリングができるようなことがあります。
別の方法でやってみる
対応分析
「段」と「段」の関係(距離)をあらわす方法としては「対応分析」があります。
クラスター分析と同様に
・「最小出現数」を3
・品詞を「名詞」「タグ」に設定します。「
段」をプロットする方法は「抽出語×文書」で「段落」を選択するか、今回のテキストのようにあらかじめ外部変数で段落IDを付与している場合は「抽出語×外部変数」でIDを選択します。
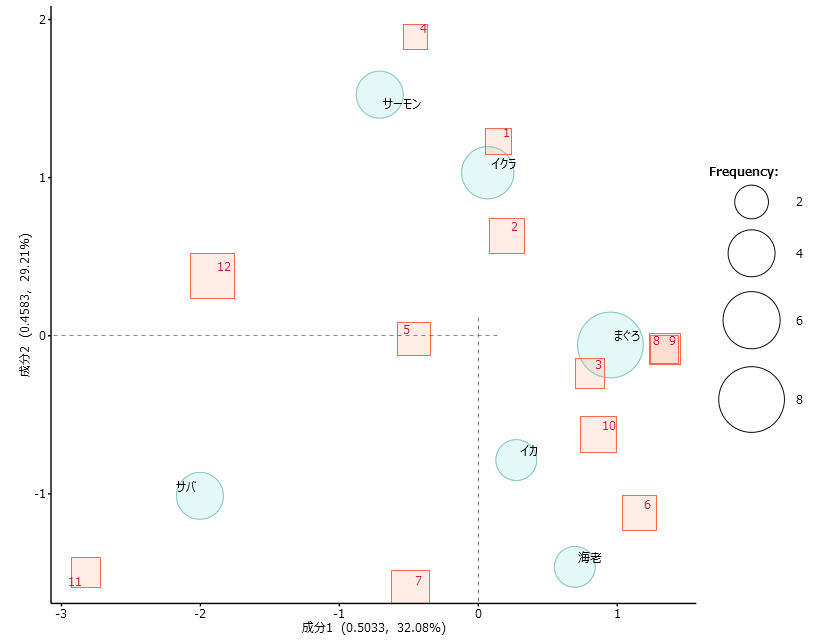
結果が表示されます。残念ながら対応分析にはクラスター形成機能がないので、タブローでクラスターを形成して確認します。
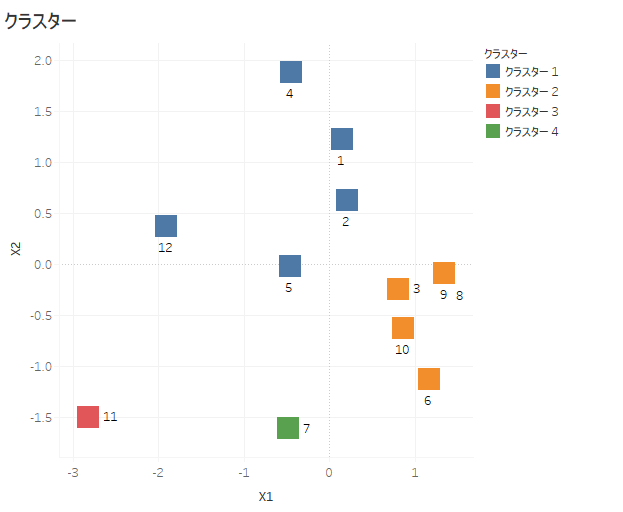
・対応分析結果をCSVで保存します。
・タブローからCSVへ接続します。
・横軸をX1、縦軸をX2
・赤い四角(row)だけをプロットしてクラスター数4で分析します。
ID7とID11が他のプロットから大きく離れます。
「語」数を絞ったため共起する「語」が「サバ」だけになってしまったことが原因です。ともかくクラスターは形成されました。「語」数や「品詞」の設定次第では、「対応分析」結果をクラスタリングすることができそうです。
決定木分析
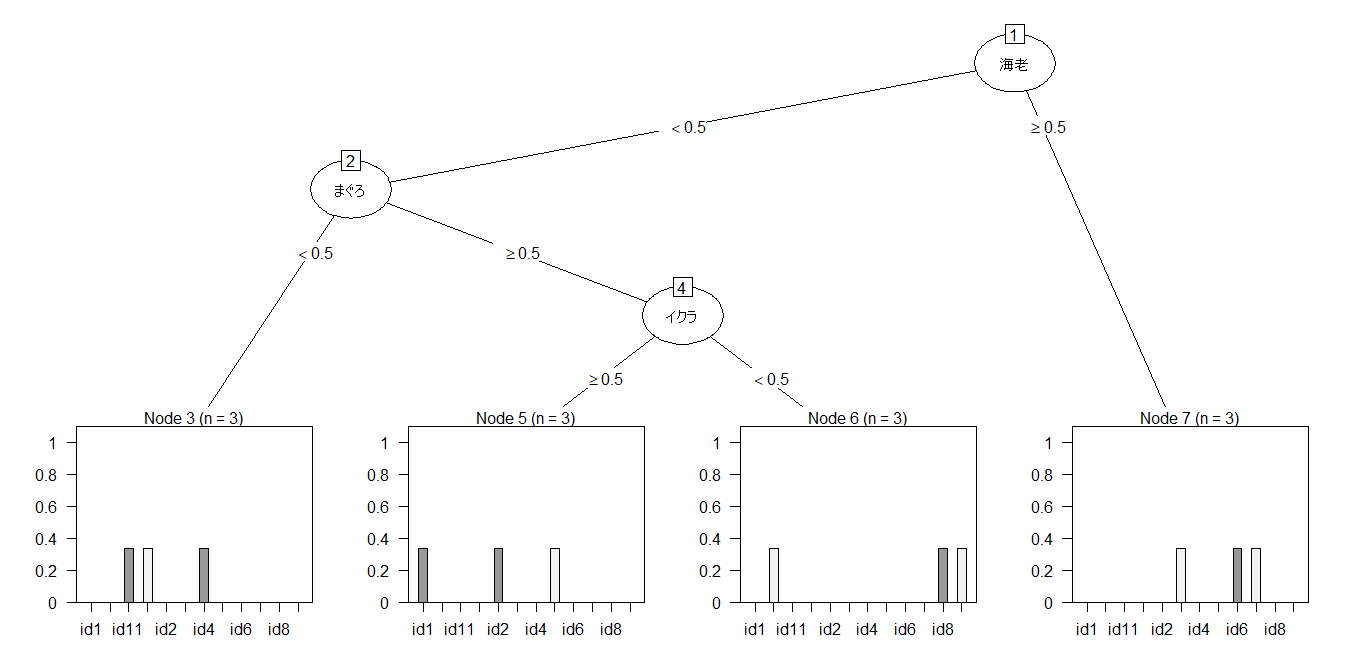
決定木分析で「段」を分類してみました。(決定木分析はこちらをご参照ください)
・はじめに「海老」の有無で分かれます。
・「海老」がないグループが「まぐろ」の有無で分かれます。
・「まぐろ」があるグループが「イクラ」の有無で分かれます。
最終的に左から
{海老がない・まぐろがない}
{海老がない・まぐろがある・イクラがある}
{海老がない・まぐろがある・イクラがない}
{海老がある}の4ノードに分かれました。
決定木分析でもいい感じの結果になりました。
ただし、決定木分析の場合は分析対象になる「語」数が多くなると複雑化されてはっきりとした結果がでない傾向になりますし、何より結果が見にくいという欠点があります。
逆に対応分析のプロットからクラスターを形成する手法は「語」数が比較的多いほうがそれらしい結果がでやすくなります。