
TF・IDF 重いことば・軽いことば
TFとは
PPAP
分析について、数人のまえで話をすることがあります。テキストマイニングの説明をするときに、例題として、ペン、パイナップル、アップル、ペンなんかを使うのですが全くウケません。まじめな席であまりにも言葉が軽いのか、そもそもネタが古すぎるのでしょうか。
TF・IDFは文書中に出現する「語」へ重みをつけようという試みです。
重い「語」というが何なのか?単純に考えると、文書中に頻繁に出現する「語」、あるいは文書の結論部分に出現する「語」だろうと想像できます。
コンピューターは「語」の出現回数をあっという間に計算できます。しかし、文書の結論が何なのか、あるいは結論が文書全体のなかのどこにあるのかを見つけ出すことができません。コンピューターは文書を理解することができないからです。
TF・IDFは
・「語」の出現回数が多ければ「重い」という考え方(TF)
・「語」の出現回数は少ないけれども「重い」だろうと計算される「語」の指数(IDF)
これら2つの考え方をミックスした数値です。ただし、ここで言う「重い」というのは読み手の心にずっしりと響く「語」であるのかというとそうではありません。
というのも一方の指数IDFがあくまでも計算式で算出されるだけのものだからです。
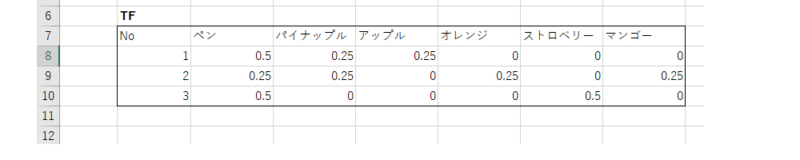
データ
| text | No. |
| ペン、パイナップル、アップル、ペン | 1 |
| ペン、パイナップル、オレンジ、マンゴー | 2 |
| ペン、ストロベリー | 3 |
まず、KHcoderを使います。使うといっても今回はテキストを読み込んで「語」のマトリクス抽出するところまでです。
データのようにあらかじめ「段」へNo.を付与しておきます。No.の列がtextの外部変数になります。
KHcoderへテキストをロードします。
・「前処理の実行」まえに「語の取捨選択」で「使用しない語の指定」へ「、」(読点)を入れてください。
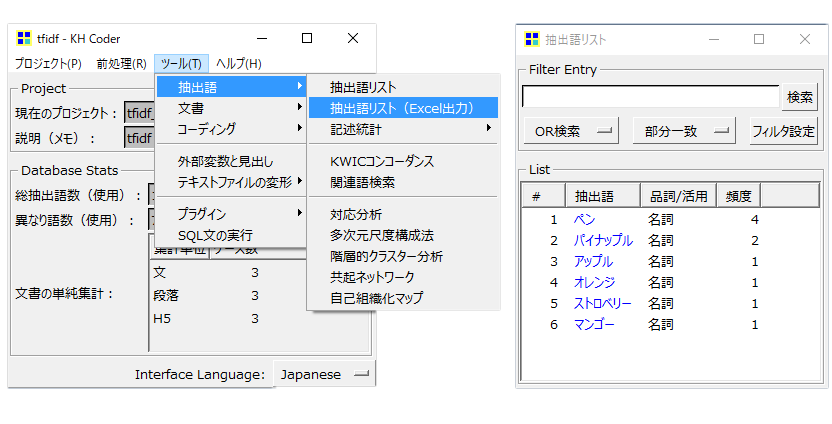
・「ツール」→「抽出語」→「抽出語リスト」で「語」がうまく抽出できているかを確認します。
画像のように6「語」が表示されていればOKです。
TF計算

ロードしたテキストを行を「段」列を「語」にしたマトリクスへ変換して抽出します。
・「ツール」→「文書」→「文書×抽出語」表の出力
・CSV形式で保存します。
KHcoderの役割はここまでです。
<TFの計算式>
TF=「1文中における語の出現回数」÷「1文の総語数」
分子になる「1文中における語の出現回数」は、列C~Hの数値です。
例えば
・「ペン」はNo.1の文書に2回出現しています。
分母になる「1文の総語数」は
・列Bの「length=w」の数値です。(「使用しない語の指定」へ「、」(読点)を入れていないときに「length=w」の数値が正確でないことがあります)
従って、
No.1の文書で「ペン」のTF=2(出現回数)÷4(No.1の総語数)=0.5
特定の「語」が文書に占める構成比のようなものです。
・TFは1文書を構成する「語」数が少なく、特定の「語」の出現回数が多いほど大きくなります。
ある文書のなかでTF値が大きいほど重要な「語」であるという定義が成立するのであればテキストマイニングにおいてTF値は重要な意味を持ち得ます。
IDFについて
IDF計算

<IDFの計算式>
IDF=log(「全文書数」÷「語が出現する文書数」)+1
・「全文書数」は、textの行数合計ですから常に3です。
・「語が出現する文書数」は、5行目のcount数です。
例えば「ペン」は文書No.1、2、3のすべてに出現するから3です。「ペン」が文書全体のなかで出現する回数4ではないことがポイントです。
「パイナップル」は文書No.1、2に出現するから「語が出現する文書数」は2になります。
・IDFは特定の「語」が出現する文書数が少ないほど大きくなる
・特定の「語」が出現する文書数が多いほど小さくなります。
つまり、まれに出現する「語」がその文書を特徴づけている、そのような「語」が重要な「語」であるという定義が成立すのであれば、IDF値が大きい「語」が重要な「語」として意味をもちます。
IDF値が大きい「語」が読み手の心に響く重い「語」であるのかどうかをコンピューターは判断できません。それを判断するのはあくまで読み手です。
TFとIDFの違い
TF値とIDF値は概ね反対方向に動きます。
それではIDFはTFの反対のものだと思いやすいのですが、反対のものではありません。別のものなのです。
・TFの計算式は「語」が出現する回数
・IDFの計算式は「語」が出現する「文書数」で成り立っています。
ですからTFは文書ごとに算出します。
・No.1の文書の「ペン」のTFは0.5
・No.2の文書の「ペン」のTFは0.25、このようになります。
IDFは文書ごとではなく、「分析対象テキスト」全体のなかで「語」ごとに1値だけを算出します。「語」の出現回数と「語」が出現する「文書数」の違いはテキストマイニングでよく認識間違いされるところです。
・TFは多く出現する「語」によって文書を分別するための道具
・IDFはまれに出現する「語」によって文書を分別するための道具だといえます。
TF-IDFとは
計算式

TF・IDF=TF×IDF
TF・IDFは、
・多く出現する「語」によって文書を分別するための道具であるTFと
・まれに出現する「語」によって文書を分別するための道具であるIDF
これら両方を同時に使ってみた!ものです。
大きくなる指数と小さくなる指数なら、掛け算をすればいい感じになるだろうという、論理的にはかなり大胆なものです。
実際にTF・IDFを算出すると、
・No.3文書の「ストロベリー」のTF・IDF値が高くなります。
「アップル」「オレンジ」「マンゴー」「ストロベリー」の出現回数はいずれも1回です。
「ストロベリー」のTF・IDF値が大きくなる理由は、
・「ストロベリー」が出現する文書No.3の総語数が少ない(2語)から、それだけです。
・「アップル」「オレンジ」「マンゴー」「ストロベリー」のIDF値はすべて2.58です。
・「アップル」「オレンジ」「マンゴー」のTF値はすべて0.25です。
・No.3文書の「ストロベリー」だけTF値が0.5です。
その結果、No.3文書の「ストロベリー」のTF・IDF値が高くなります。
それではTF・IDF値が高い「ストロベリー」とい「語」自体が何か心に響く重い「語」なのかどうか。このあたりの判断はとても難しいですね。
では「ストロベリー」を含むNo3.の文書に何か特徴があるのか?
3段のテキストを比べると感覚的にNo.3の文書はNo.1、2と比較して少し違うように思います。
結局、TF・IDFは「語」の重さをあらわすとしても、”重さ=心に響く”ではなく、”重さ=「語」と「語」の違いをあらわす数値”、「語」と「語」の違いをスケールにして文書の違いをはかる道具だといえそうです。
ペン、ペン、ペン・・・

・文書No.1へ「ペン」を100回出現させます。
・文書No.1の「ペン」のTF=100÷102=1.0です。
・「ペン」のIDF=log(3÷3)+1=1.0です。
・文書No.1の「ペン」のTF・IDF=1×1=1です。
TF=文中における語の出現回数÷文の総語数ですから、TF値が1.0を超えることはありません。
またIDF=log(全文書数÷語が出現する文書数)+1ですから、1文書内における語の出現回数とは無関係です。
何度も何度も同じ「語」を繰り返されると「語」が重くなるどころか軽くなってしまいます。「しつこいから、もうええわ」のところでストップしているわけです。
・結果として文書No.3に1回だけ出現する「ストロベリー」よりも「ペン」のTF・IDF値は小さくなります。
・また、文書No.1の「パイナップル」「アップル」のTF・IDFがゼロになります。
これはNo.1の「パイナップル」「アプル」のTF値がほぼゼロになるからです。会議に、やかましいオッサンが1人いて他のひとの意見がかき消されている状況です
ということは、
① TF・IDF値が1以下かつ1に近い値の特定の「語」が出現する文書。
例えば
・「ペン」が100回出現する文書と「ペン」が99回出現する文書は似ている。
・「ペン」が100回出現する文書と「パイナップル」が100回出現する文書には違いがある。
② TF・IDF値が1を超える「語」を含む文書。
・「ペン」が100回出現し「ストロベリー」が1回出現する文書と「ペン」が1回・「ストロベリー」も1回出現する文書には違いがある。
③ TF・IDF値が高い「語」が違う文書。
例えば
・「アップル」のTF・IDF値が高い文書と「ストロベリー」のTF・IDF値が高い文書には違いがある。
④ 複数の文書を比較して特にTF・IDF値が高い「語」がないとき。
・TF・IDFで分類することができない。