

Coding(KHcoder) 1 コーディングとは
KHcoderには「抽出語分析」と「コーディング分析」があります。今回は、コーディングとはどのようのことなのか、「表記揺れの吸収」との違いなどについて解説しています。
Coding編で使用しているデータ
table
| テキスト | 年代 | 性別 | サイト | ID |
| イクラ、トロ、エビ | 10代 | 男 | A | 1 |
| たまご、イクラ、マグロ、イカ | 10代 | 女 | A | 2 |
| イクラ、エビ、マグロ、コーン | 10代 | 男 | A | 3 |
| イクラ、ツナサラダ、甘えび | 10代 | 女 | A | 4 |
| イクラ、マグロ、サバ | 40代 | 男 | A | 5 |
| ハマチ、赤身、エビ | 40代 | 女 | A | 6 |
| イカ、エビ、サバ | 40代 | 男 | B | 7 |
| ハマチ、ブリ、トロ、甘えび | 40代 | 女 | B | 8 |
| マグロ、ホタテ、サンマ | 60代 | 男 | B | 9 |
| トロ、明太子、イカ、さざえ | 60代 | 女 | B | 10 |
| サンマ、あじ、赤貝、ハマチ | 60代 | 男 | B | 11 |
| サバ、あじ、サンマ、さざえ | 60代 | 女 | B | 12 |
コーディングファイル
*魚卵 イクラ or 明太子 *エビ・イカ エビ or イカ or 甘えび *マグロ マグロ or トロ or 赤身 *青魚 サバ or サンマ or ハマチ or あじ or ブリ *貝類 さざえ or ホタテ or 赤貝 *惣菜 たまご or コーン or ツナサラダ
今回のCoding(KHcoder)編から分析対象テキストがかわります。
前回の分析対象テキストはコーディング機能を説明するのには少しややこしいので単純な形式に変更します。分析対象テキストは好きなすしネタだけを記載しています。
コーディングファイルは分析対象テキストに出現する「語」をすべて網羅しています。また、分析対象テキストの「語」対コーディングファイルの「コード」の対応関係は ”複数” 対 ”1” です。”複数” 対 ”複数” にすると、これまたややこしくなるのでこのあたりも単純化しています。
今回のコードは、すしネタをカテゴリーごとにまとめるようなかたちでつくりました。
各コードが回転すしのタッチパネルの各ページ該当するようなイメージです。例えば、「10代が最もタッチするパネルのページはどこか?」のような問いにたいする分析結果を得ることができるのだろうと思います。
コーディングとは
分析対象を切り替える
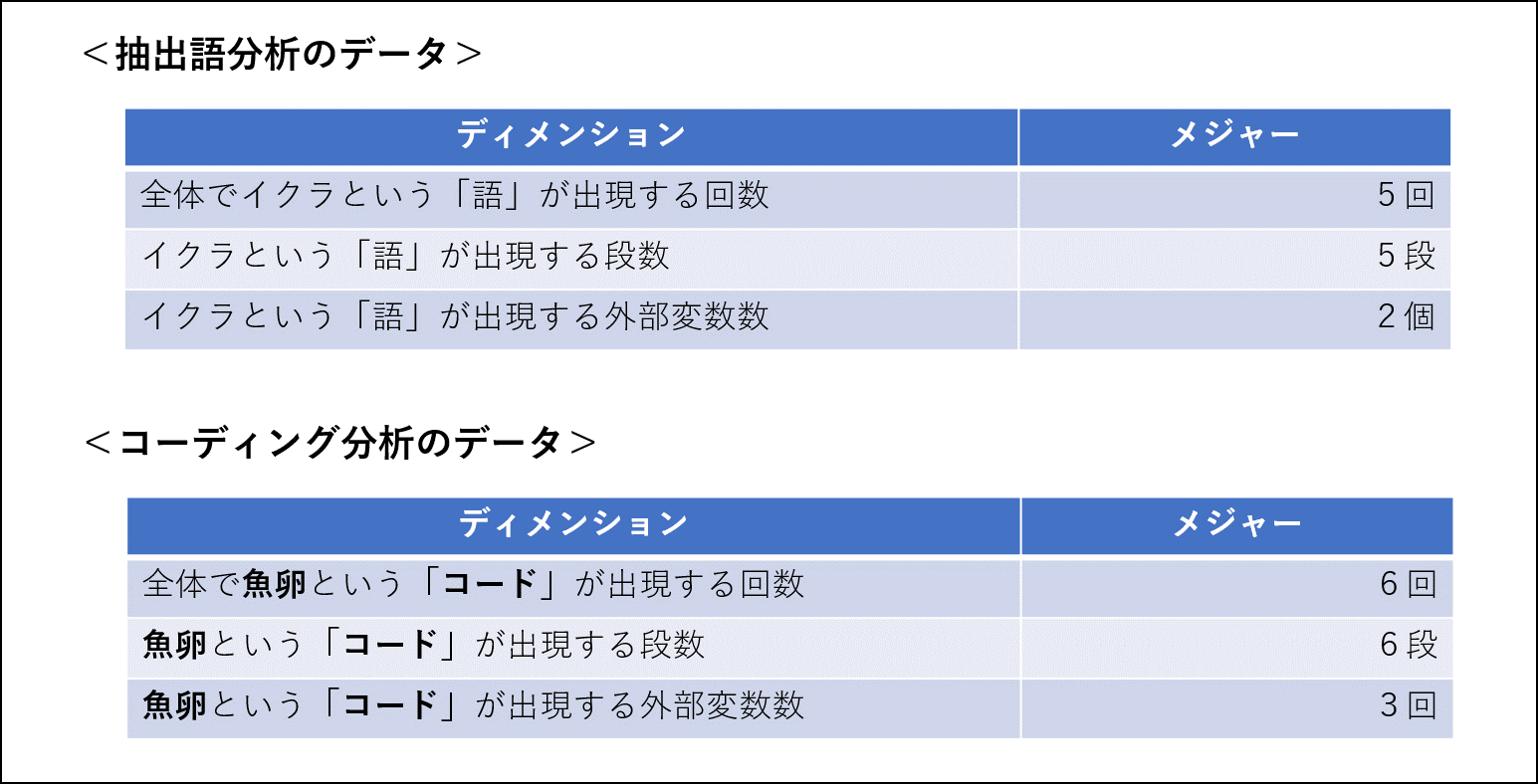
テキストマニングの分析対象は基本的に「語・段・文・外部変数」です。「語・段・文・外部変数」がディメンションになります。
メジャー(値)は、どのような「語」が、どこの段・文・外部変数に何回出現するのか、あるいは特定の「語」が出現する「段・文・外部変数」数です。
つまり「語」の出現回数と「語」が出現する「段・文・外部変数」数がメジャーです。メジャーは”数量”です。
テキストマイニングツールは「ディメンション」と「メジャー」をつくる、それらをを統計解析する、解析結果を描画することを仕事にしています。
売上高=100万円、客数=3,000人、このようにはじめからディメンションとメジャーを与えられているようなデータ分析と、テキストマイニングとの決定的な違いがここにあります。(対応分析(第1回) テキストマイニングツールの仕事)
コーディング分析とは
コーディング分析とは分析対象を「語」から「コード」へ切り替えることです。
「語」から「コード」への切り替えはコーディングファイルの読み込みによって可能になります。
今回はコーディングファイルで「イクラ」と「明太子」という「語」から「魚卵」というコードをつくりだしているのです。言い換えるとコーディングファイルであたらしいディメンションをつくます。ディメンションが切り替えられれば集計されるメジャーの数量も必然的に変わります。
コーディング分析とは「コード」と「コード」の関係、「コード」と「段・文・外部変数」との関係分析になります。
「コード」と「段・文・外部変数」の関係に「語」との関係を加えて同時に分析することはできません。例えば抽出語分析では「コード」の出現回数をカウントしません。逆にコーディング分析では「語」の出現回数をカウントしません。
表記揺れの吸収との違い
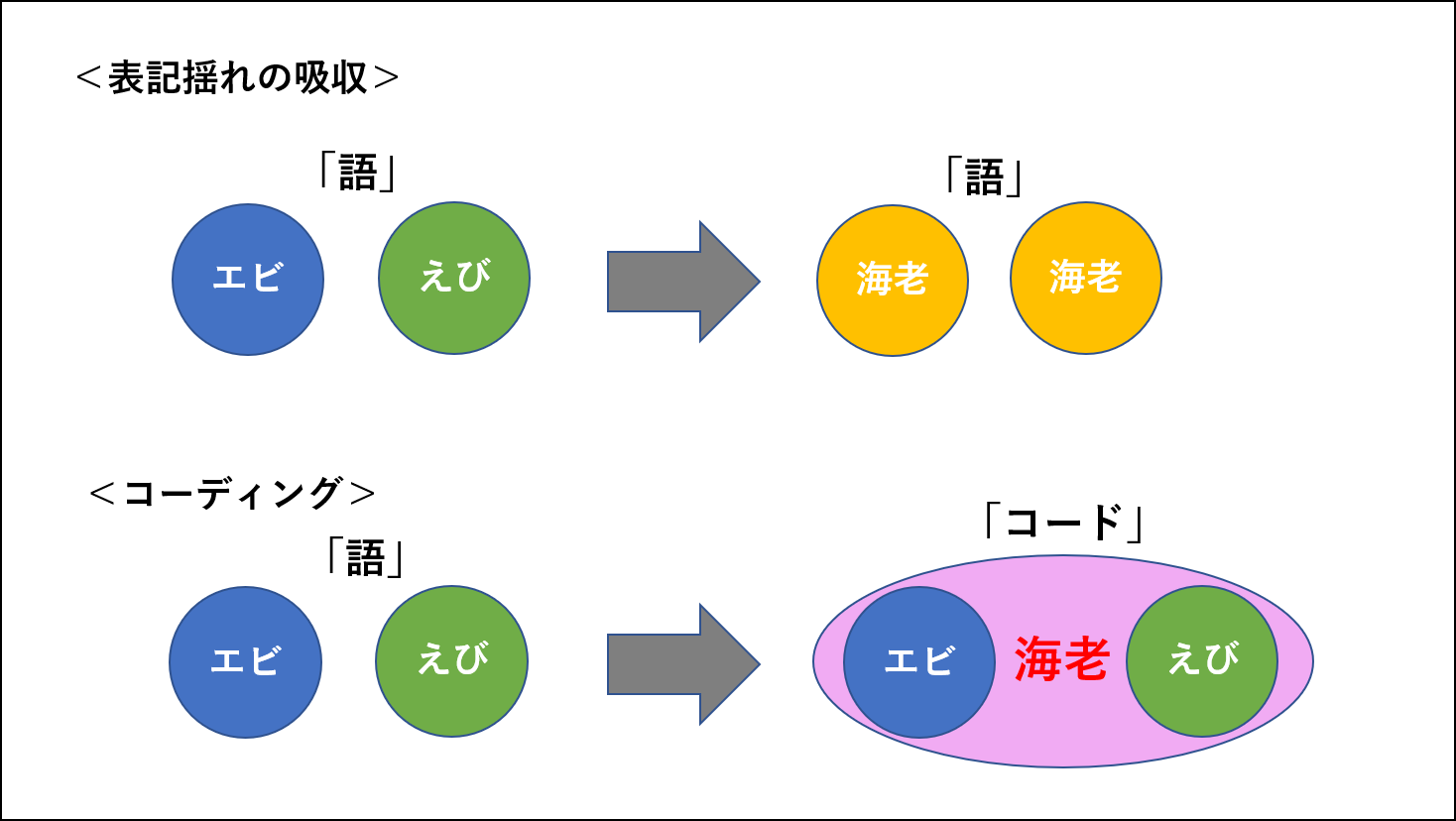
表記揺れの吸収は分析対象テキストに出現する「語」を、ある「語」の活用形に変換する手順です。(KHcoder 6. 表記揺れの吸収ファイル書き換え)活用形に変換したあとも「語」は「語」のままです。
従って、分析方法は抽出語分析です。コーディングは「語」から「コード」をつくります。「コード」の分析方法はコーディング分析です。「語」と「コード」はそれぞれ別々のディメンションです。
粒度との違い
| テキスト | 年代 | 世代 |
| イクラ、トロ、エビ | 10代 | 平成 |
| たまご、イクラ、マグロ、イカ | 10代 | 平成 |
| イクラ、エビ、マグロ、コーン | 10代 | 平成 |
| イクラ、ツナサラダ、甘えび | 10代 | 平成 |
| イクラ、マグロ、サバ | 40代 | 昭和 |
| ハマチ、赤身、エビ | 40代 | 昭和 |
| イカ、エビ、サバ | 40代 | 昭和 |
| ハマチ、ブリ、トロ、甘えび | 40代 | 昭和 |
| マグロ、ホタテ、サンマ | 60代 | 昭和 |
| トロ、明太子、イカ、さざえ | 60代 | 昭和 |
| サンマ、あじ、赤貝、ハマチ | 60代 | 昭和 |
| サバ、あじ、サンマ、さざえ | 60代 | 昭和 |
コーディングは複数の「語」を1語にまとめるというイメージがあります。ディメンションをまとめたり、細分化したりすることを粒度の変更といいます。
例えばテキストマニングでは外部変数がディメンションですから、粒度の変更とは外部変数変更(追加や削除も含めて)のことです。
表のように10代を平成へ、40代と60代を昭和へまとめると平成世代が好むすしネタ、昭和世代が好むすしネタを分析することが可能になります。
また、分析単位を「段」から「文」へ切り替えることも粒度の変更です。ですからコーディングは粒度の変更であるといっても構いません。
関東地方は「茨城県、栃木県、群馬県、埼玉県、千葉県、東京都、神奈川県」です。
一般的な分析で茨城県が関東地方と東北地方の両方に同時に含まれることはありません。
ところがテキストマイニングのコーディングでは、ある「語」を複数のコードに含めることが可能です。このあたりが一般的な粒度の変更と違うところです。
またテキストマイニングのコーディング分析はコードを含まない「段・文・外部変数」ははじめから分析の対象から除外します。コーディングはフィルター機能でもあるといえます。