
LOD表現(タブロー)
タブローのLOD表現(粒度の問題)とフィルターの関係について説明しています。
LODと粒度
粒度
分析において粒度という言葉がしばしば登場します。
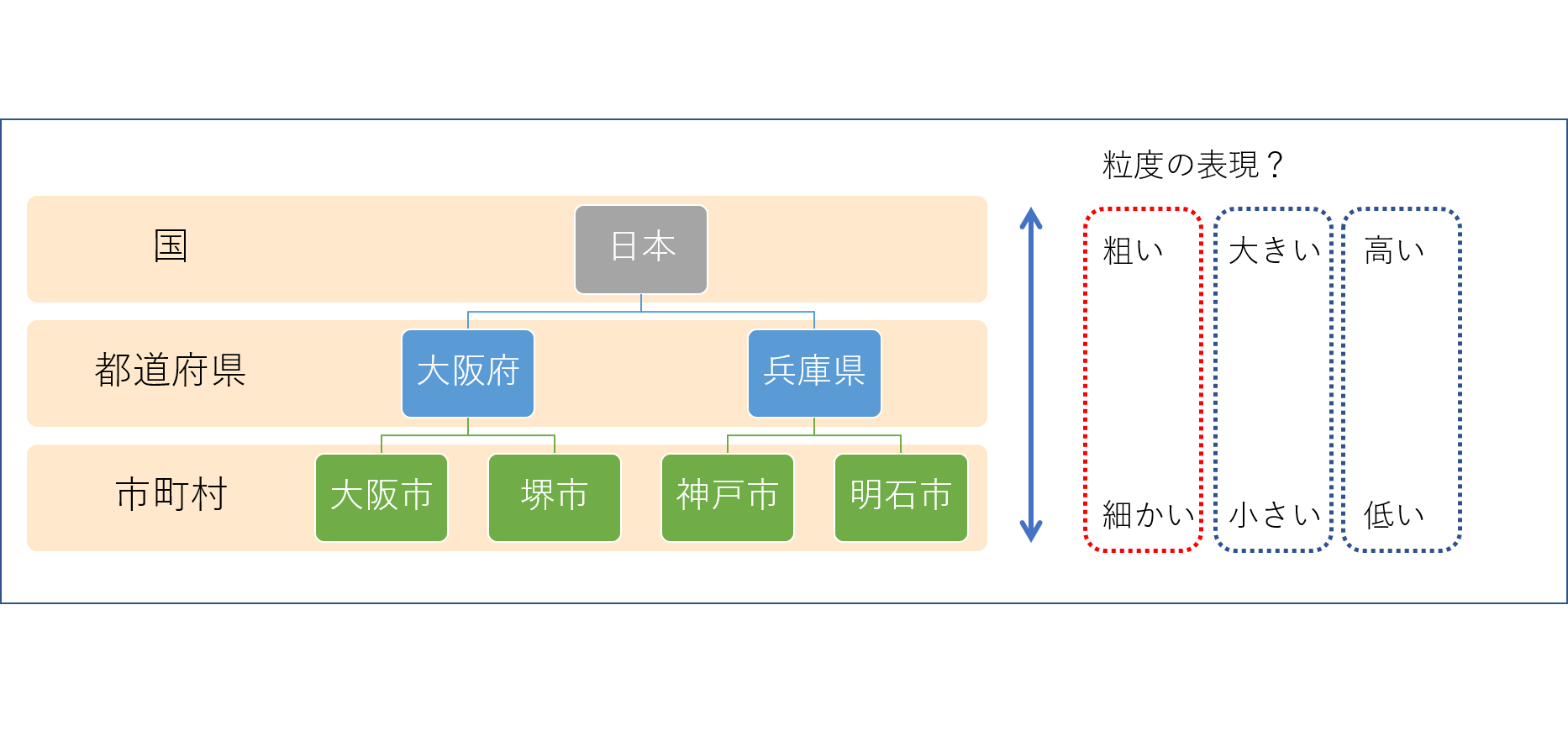
粒度というのは集計の単位、画像で説明すると、例えば人口を集計するときに、
・国単位で集計するのか
・都道府県単位か
・市町村単位なのか。
単純に解説すると、この集計単位が粒度です。分析は粒度を指定して集計するものです。
国の人口合計と都道府県それぞれの人口合計とではもちろん違う数値になります。違う数値であっても日本中の都道府県すべての人口を合計すれば日本国の人口合計と一致します。
粒度を考えるときに最もやっかいなのは粒度(単位)の表現です。
粒度が「粗い・細かい」「大きい・小さい」「高い・低い」などのようにさまざまな表現がなされます。
画像には粒度が高い=国、粒度が低い=市町村、このように表現したものの、本当にそれで正解なのかどうかはっきりしません。粒度が低い=国、粒度が高い=市町村、このようにしても違和感がまるでないわけです。
何が正解なのか知らないので、この投稿では「粗い・細かい」(「粗い=国」「細かい=市町村」)で統一します。粒度というくらいだから「粒(つぶ)」、「粗い・細かい」がよいのだろうと思います。
データ
| 顧客 | 地域 | 商品 | 購入日付 | 購入金額 |
| A | 東京 | P | 9月1日 | 1,000 |
| A | 東京 | Q | 11月1日 | 10,000 |
| A | 東京 | R | 12月1日 | 100,000 |
| B | 東京 | P | 11月1日 | 2,000 |
| B | 東京 | R | 12月1日 | 100,000 |
| C | 横浜 | Q | 10月1日 | 30,000 |
| C | 横浜 | R | 12月1日 | 200,000 |
自作データです。なぜ、はじめに粒度について書いたのかというとLOD表現は粒度と密接に関連しているからです。
このデータの、
・粒度が粗い=地域
・粒度が細かい=顧客
として、LOD表現を実践します。データの地域別購入金額<合計と顧客別購入金額の合計は一致します。
LOD表現の基本計算式
<LOD表現の基本計算式>
{sum([購入金額])}
このように計算式を{}でくくります。
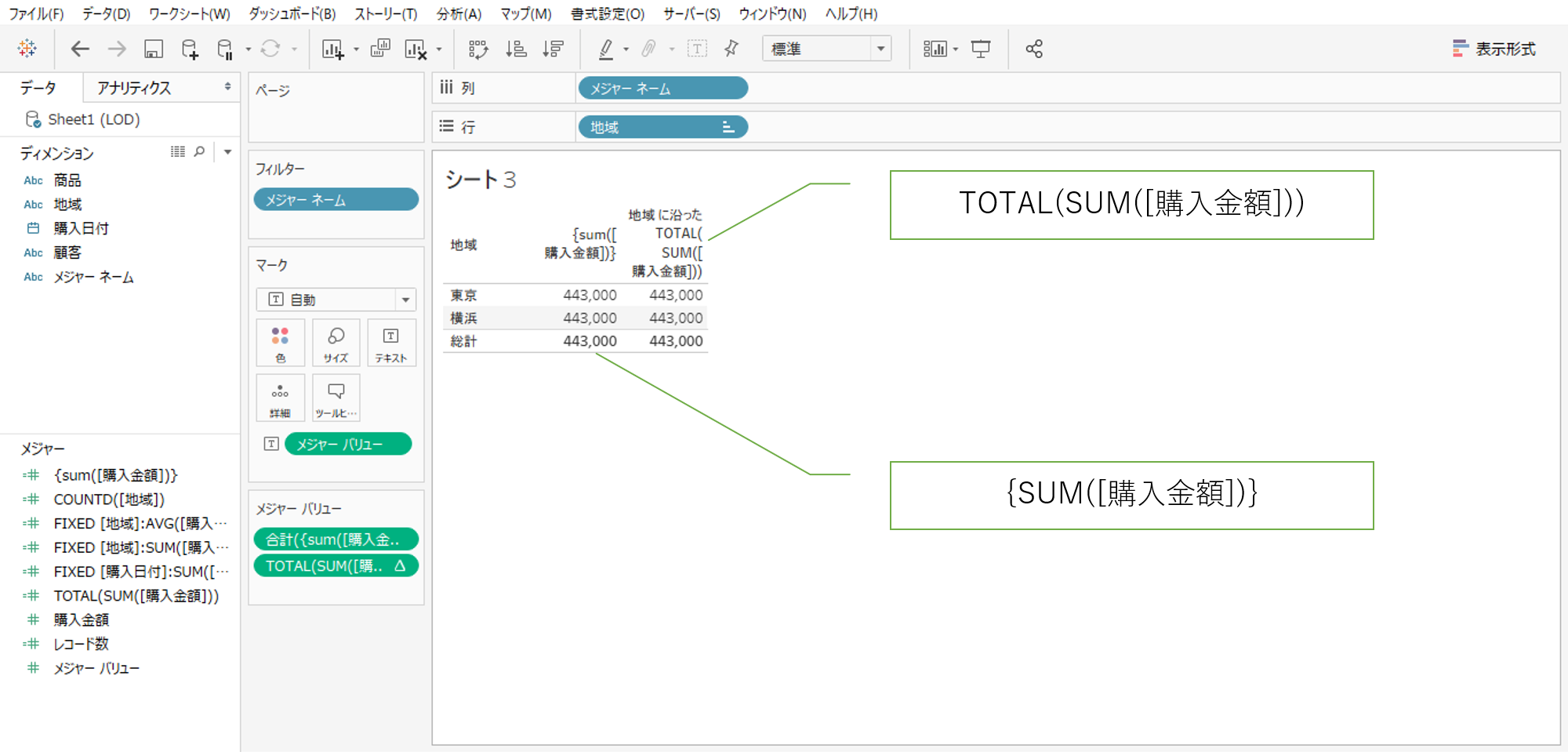
一見「TOTAL(SUM([購入金額]))」と同じ結果になるようにみえますが、実は違います。
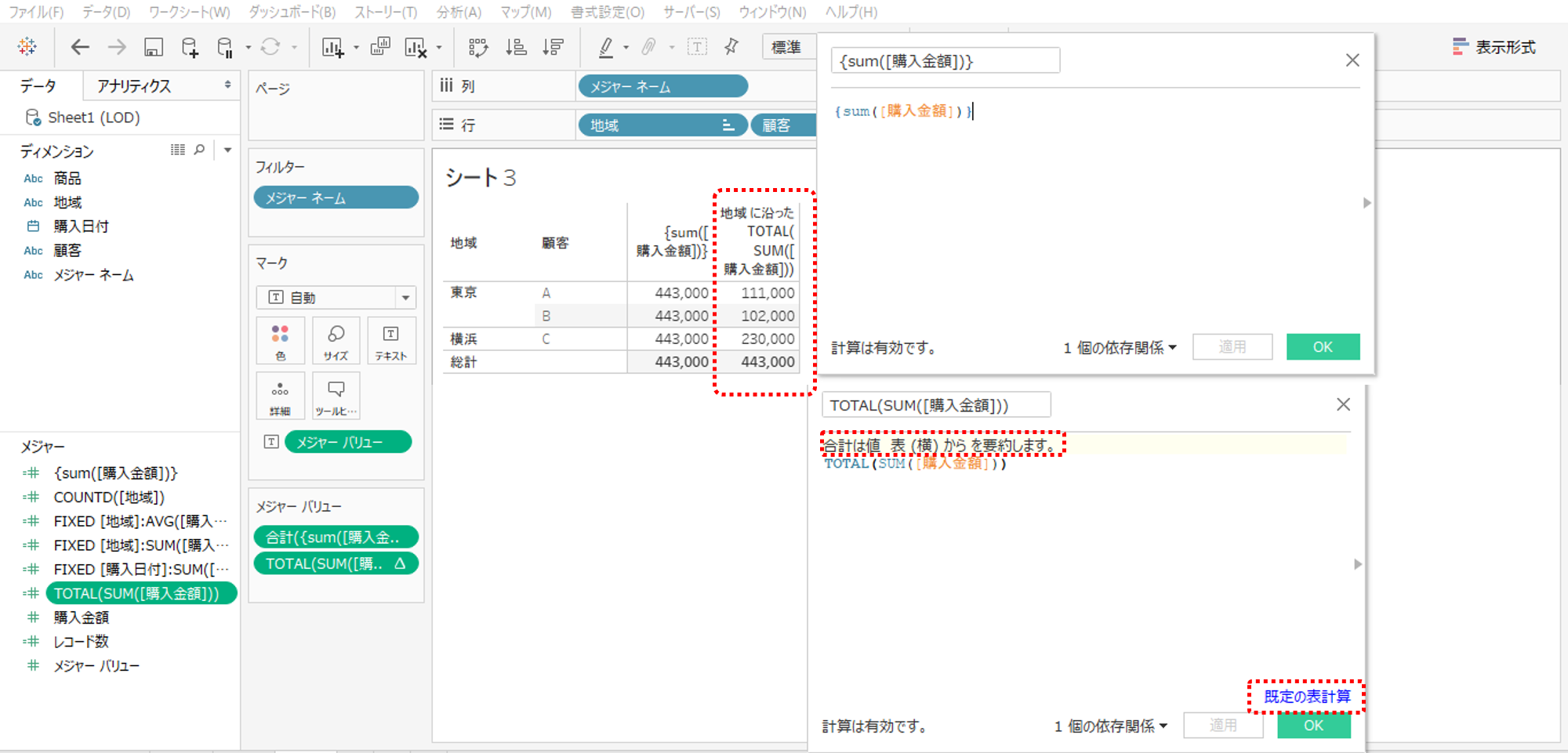
・顧客(ディメンション)を行シェルフへ追加します。
顧客(ディメンション)を追加するということは、表計算の粒度を地域から顧客へ変更した、粒度を細かくしたということです。
粒度を細かくすることで、ふたつの計算結果は違うものになります。
「TOTAL(SUM([購入金額]))」は表示のとおり、顧客(ディメンション)に従い表計算を行います。
結果的に表計算に従って粒度が細かいほうの顧客を単位に計算します。一方の「{sum([購入金額])}」は計算結果に変化がありません。
「{sum([購入金額])}」の{}に意味があるようです。
{}は粒度に関することであり、現在の計算式は最も粗い粒度、表のディメンションにかかわらずデータソース全行の合計を計算しているということです。
・{}内にディメンションを指定しなければ最も粗い粒度で集計する
・{}のなかに集計したい粒度(ディメンション)を指定すれば、指定した粒度で計算すできる仕組みです。
LOD表現を確認する
タブローの平均とは
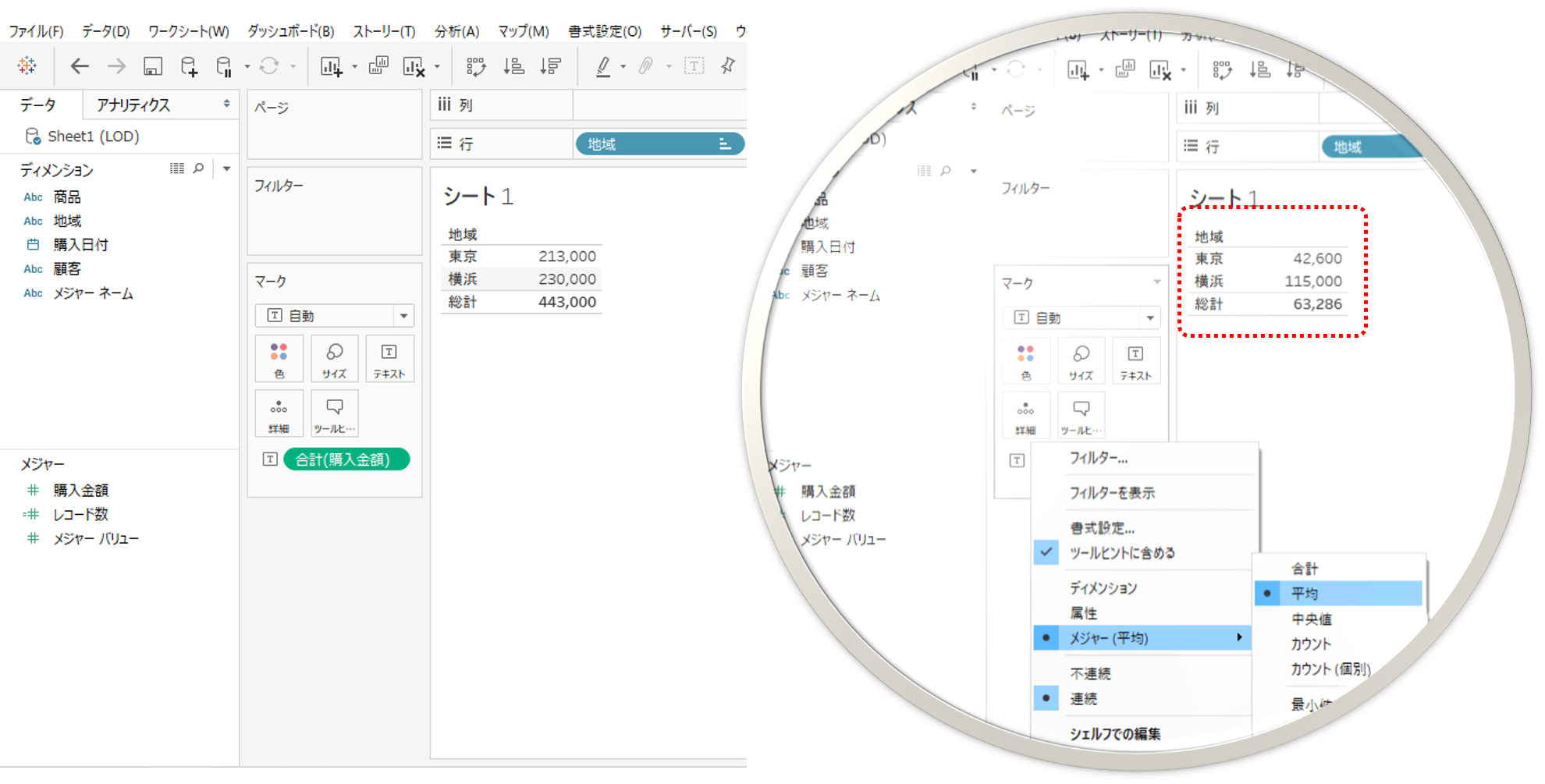
・地域を行シェルフへ購入金額をテキストへドロップします。
タブローはまず「集計=合計」が基本動作になります。合計は表に従って計算されるので、表示される数値は地域別の購入金額合計です。
タブローで平均計算をします。
・テキストへドロップした「合計(購入金額)」を右クリック
・メジャー(合計)→平均を選択します。
すると数値が平均へとかわります。
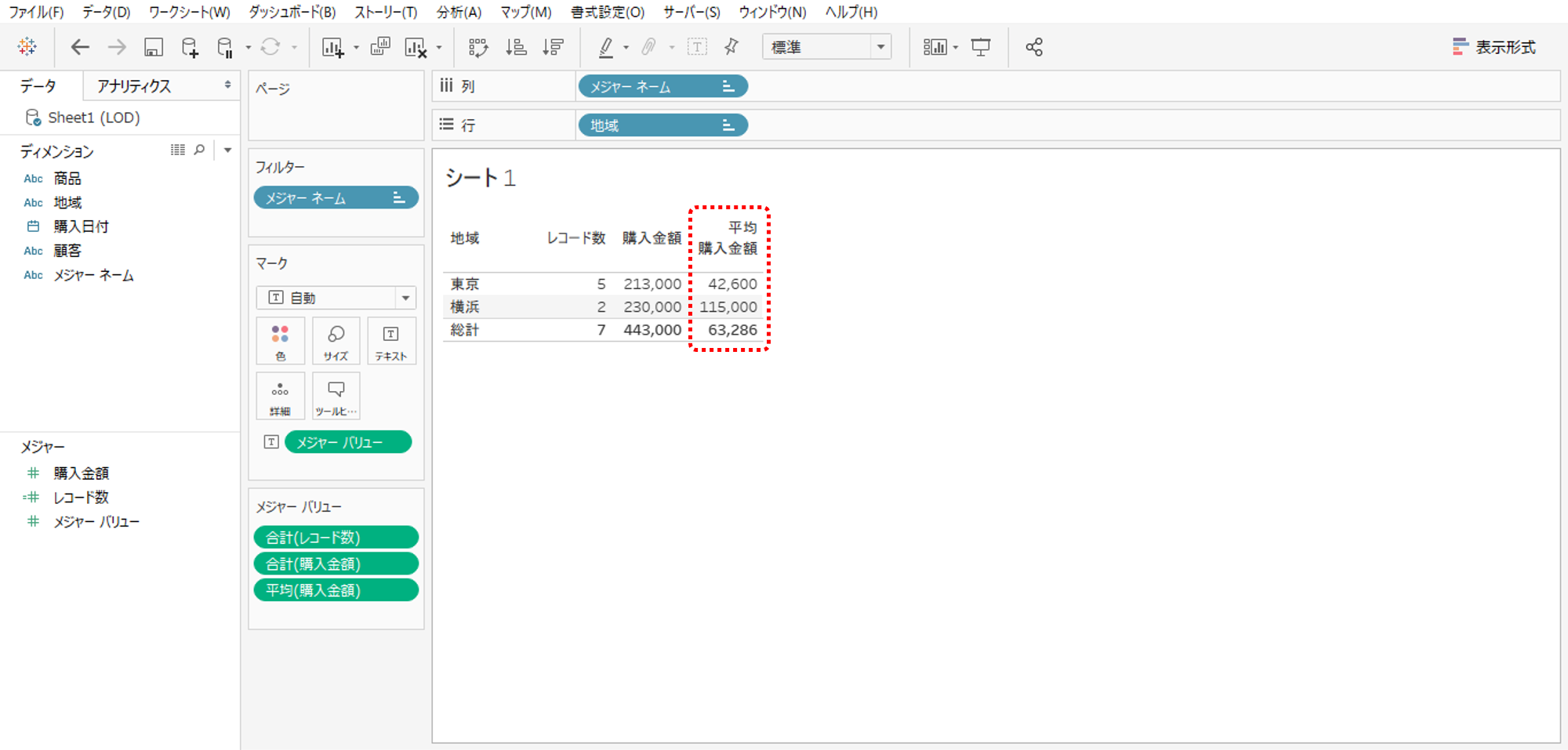
では、この平均とは?分子が購入金額合計であることは確かです。分母は何でしょうか?
タブローの平均計算の分母は常にレコード数です。
計算式「AVG([購入金額])」もまったく同じ計算結果になります。通常の計算式での平均は表計算をします。総計の行も、購入金額合計÷レコード数合計になります。
LOD表現ができる計算式
タブローでLOD表現が可能な関数は
・FIXED
・INCLUDE
・EXCLUDE
です。
この投稿では、使いやすく、わかりやすい「FIXED」を解説します。
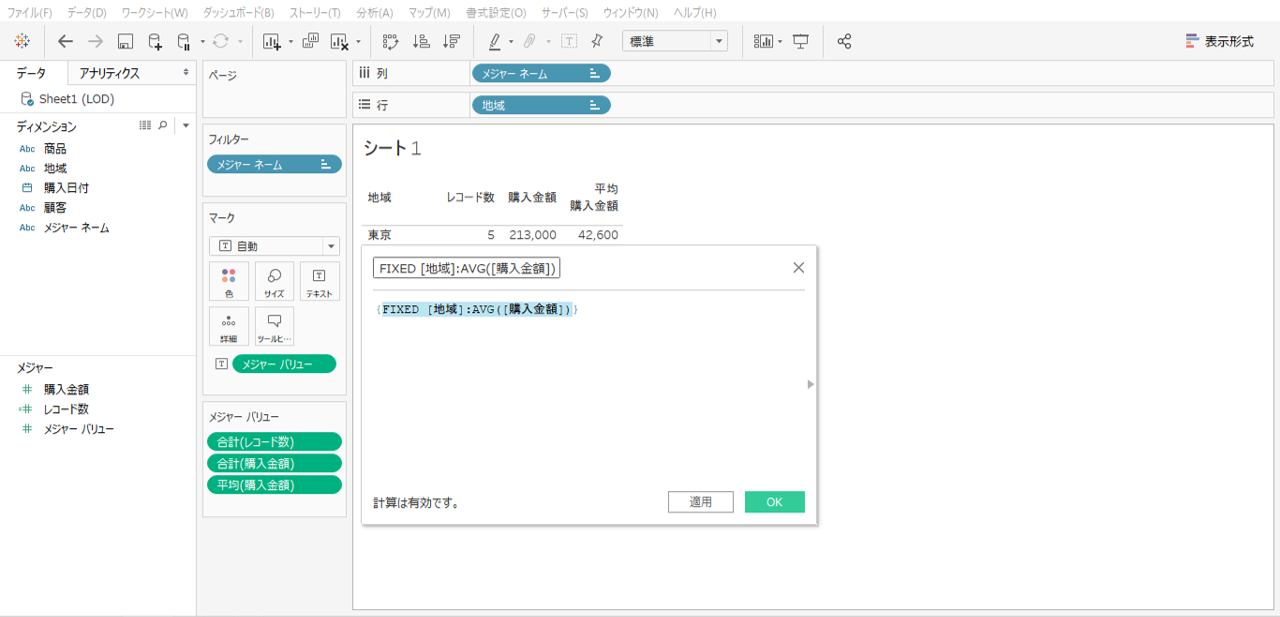
計算式を作成します。
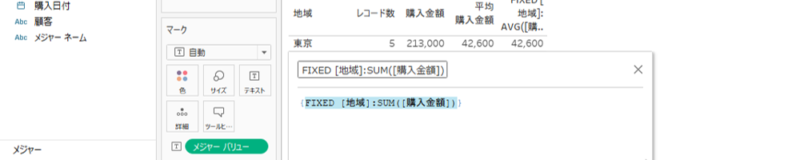
{FIXED [地域]:AVG([購入金額])}
・LOD表現で使用する関数を{}でくくります。
LOD表現で使用する関数とは、{}のなかで粒度を指定するための関数だといえます。
計算式は、
・集計の粒度=地域
・計算方法=平均
を意味します。
総計が妙だ
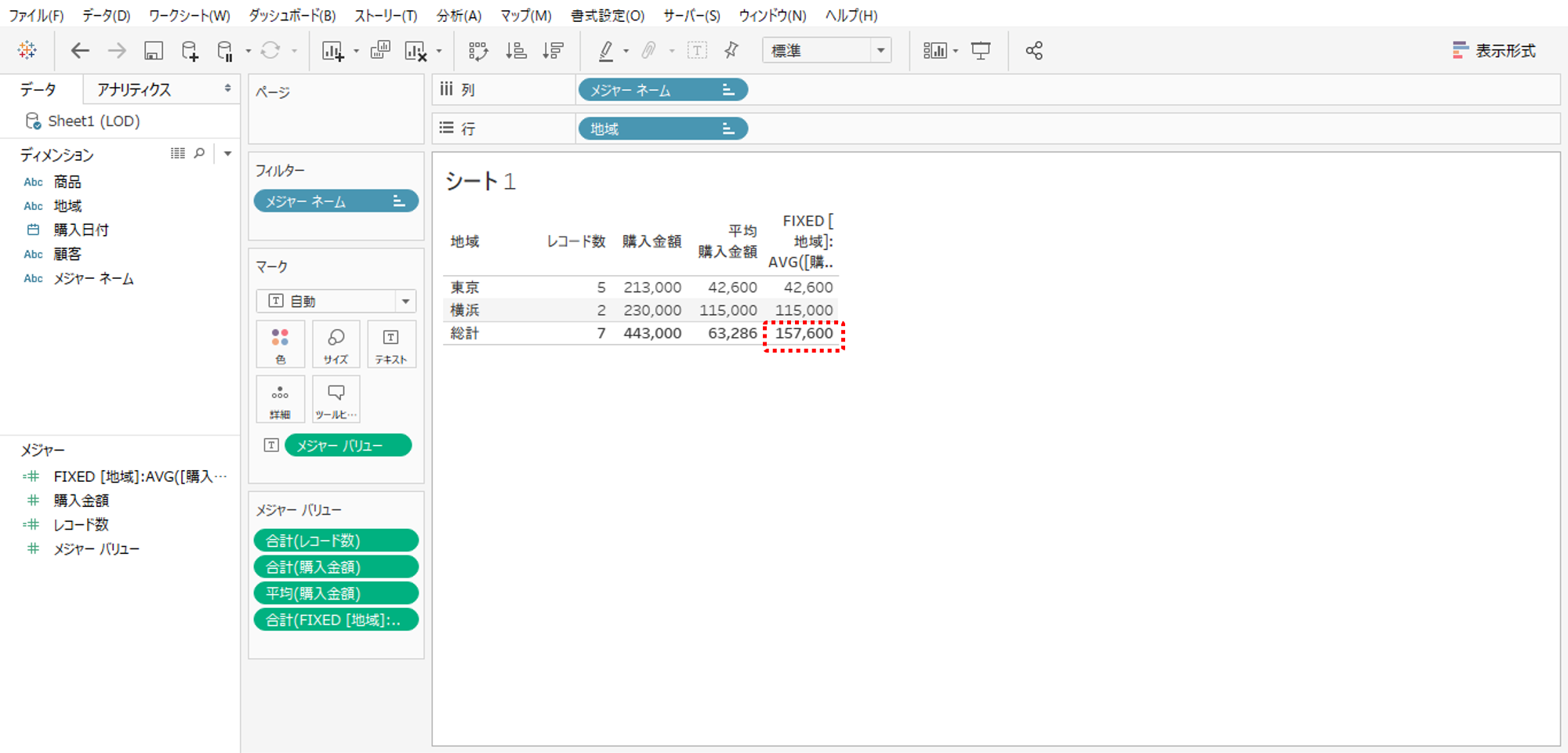
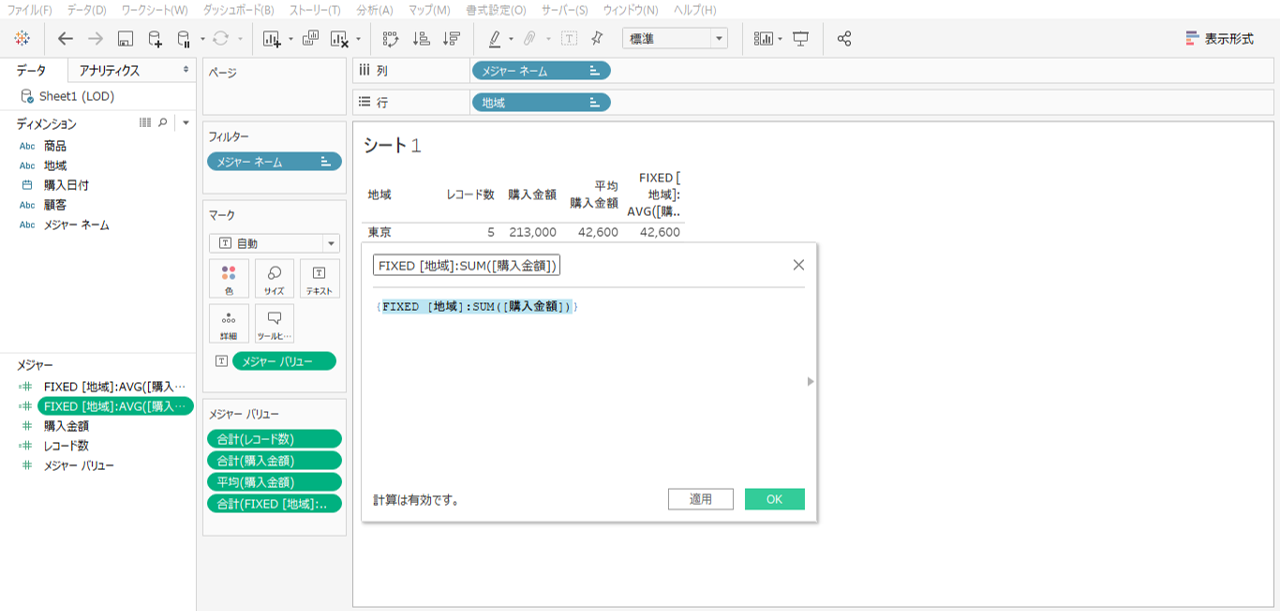
「{FIXED [地域]:AVG([購入金額])}」の結果を表示しました。
各行は一般式と一致するものの総計が妙な数値になります。
・LOD表現の総計は行の総計、つまり、縦方向の表計算をしています。
このLOD表現の計算式は「AVG([購入金額])」ですから、あくまでも分母は指定した粒度(地域)のレコード数です。
ここからは想像ですが、指定した粒度(地域)に総計はありません。従って、平均を計算できない、この計算式の総計は縦方向の表計算になるのではなかろうかと思うわけです。
実はLOD表現の落とし穴です。よく間違えます。「{FIXED [地域]:AVG([購入金額])}」で地域を指定しているのだから総計は、購入金額合計(443,000)÷地域の数(2)になるだろうと。
総計が正確になる計算
地域数2で購入金額合計を割った数値になる計算式は
{FIXED [地域]:SUM([購入金額])}
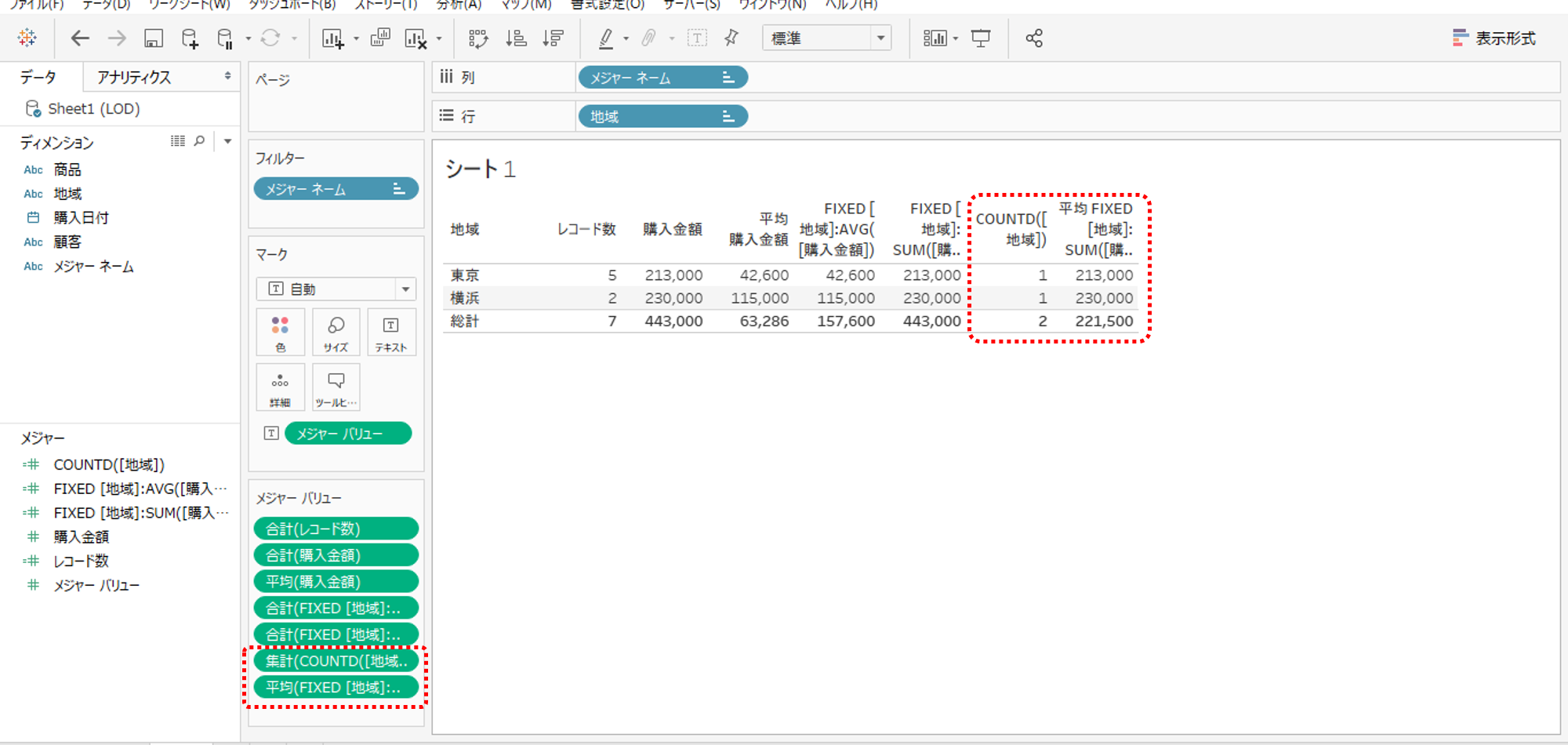
そして、集計方法を「平均」へ変更します。
{FIXED [地域]:SUM([購入金額])}を平均するということは、
AVG{FIXED [地域]:SUM([購入金額])}と同じ
SUM([購入金額])/COUNTD([地域])これも同じ
LOD表現とフィルター
指定した粒度(ディメンション)のフィルター
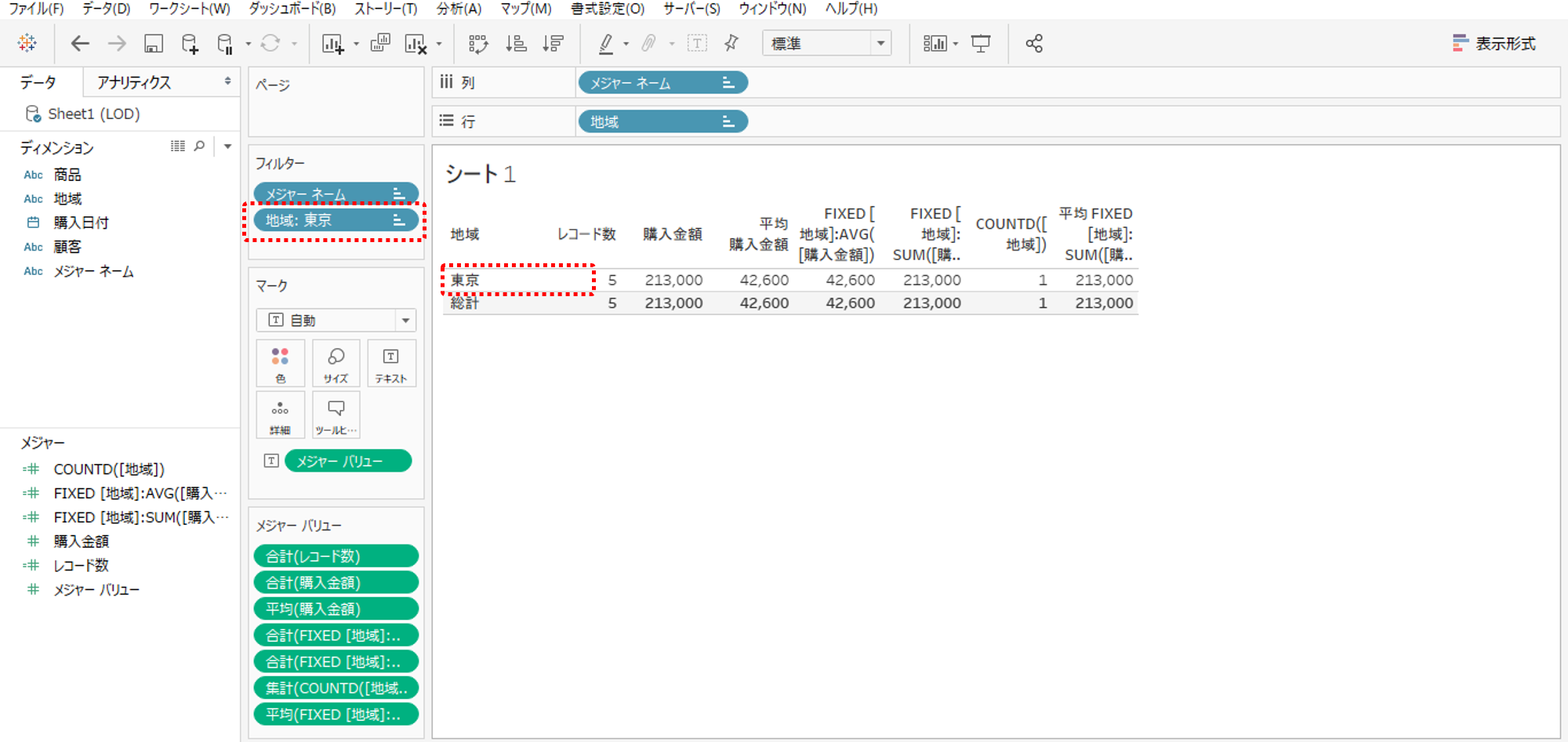
LOD式で地域を粒度として指定しています。
・フィルターで東京・横浜のうち横浜を除外して東京だを保持します。
このときLOD式はフィルターに従って、つまり、表に従って計算されるようにみえます。
指定しない粒度(ディメンション)のフィルター
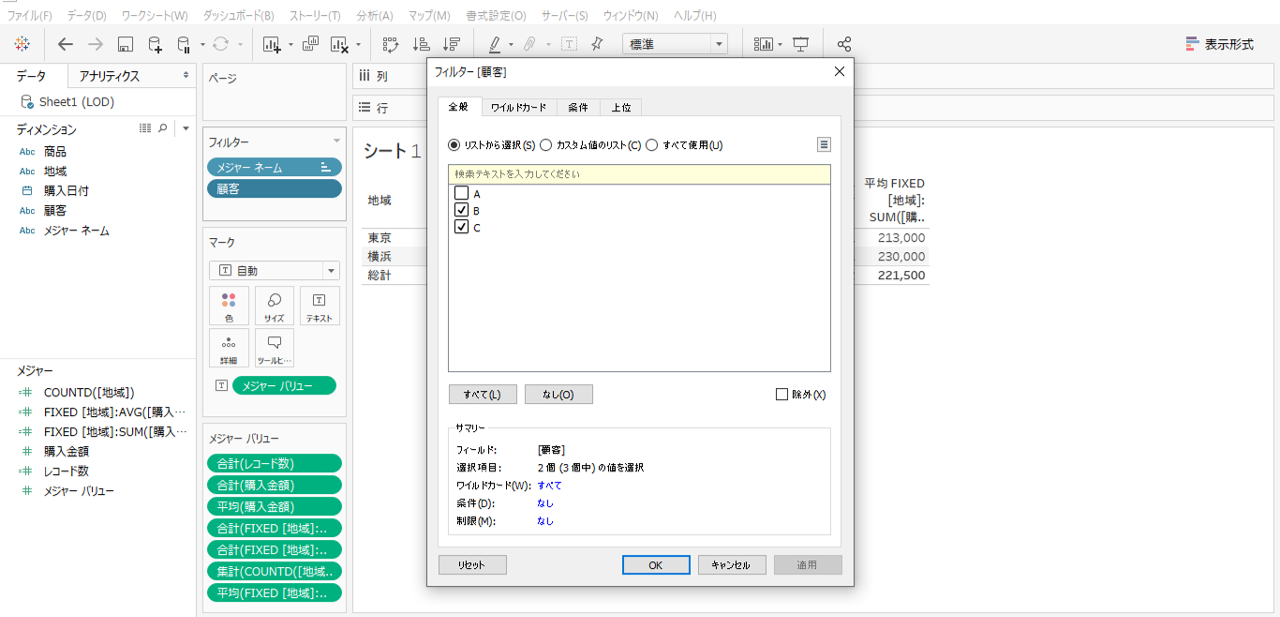
顧客をフィルターします。
・A・B・C、3名のうちAを外してB・Cの2名にします。
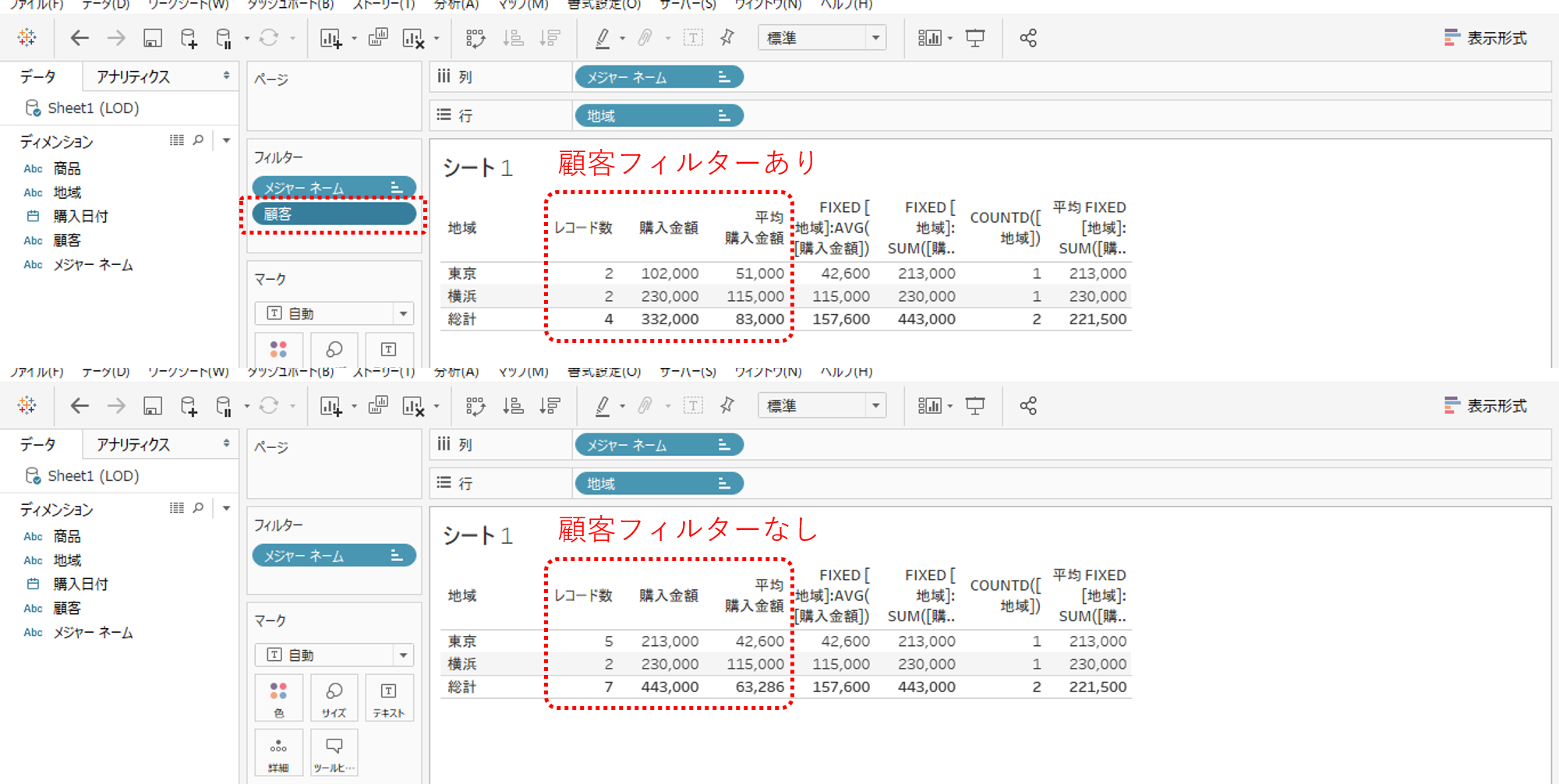
画像上部分は顧客をフィルターしたもの。画像下部分は顧客をフィルターしないものです。
<一般計算式のとき>
一般式の計算結果は顧客がフィルターされて減少しているから、レコード数、購入金額、平均購入金額のいずれもフィルターにしたがって再計算されます。
<LOD計算式のとき>
全く計算結果に変化がありません。
フィルタリングで東京だけを保持したときにLOD式が表に従って計算しているようにみえるのは、表のディメンション(地域)とLOD式で指定している粒度(地域)とフィルターの地域が一致しているからです。
実際には、表のディメンション(地域)は無関係にLOD式で指定している粒度(地域)とディメンションフィルターの地域だけに従って計算しているのです。
LOD計算式で指定していない粒度のフィルターを使用しても、フィルターされないことがわかります。
フィルター優先順位

LOD表現が表計算に従わないならフィルターの優先順位は画像のようになるはずです。
LOD表現とフィルターのVIZ
購入金額合計と地域
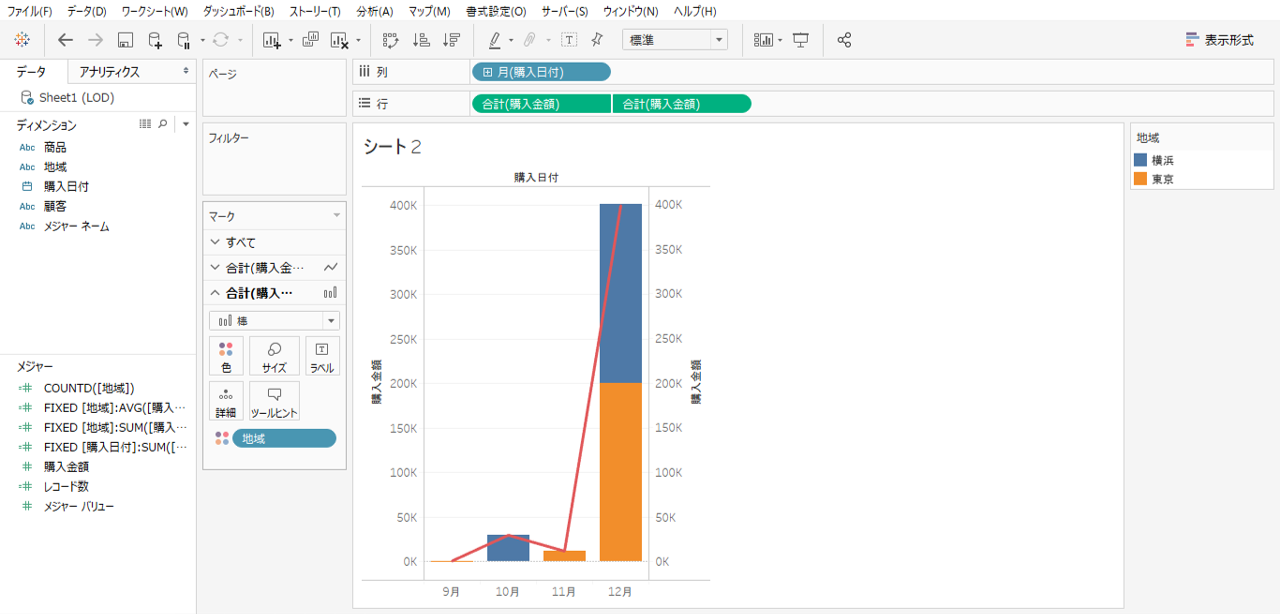
画像のように折線と棒の二重軸グラフを描きます。折線も棒も購入金額合計を示します。棒は地域(東京・横浜)で色分けしてあります。
さて、このグラフで
・折線を東京と横浜の売上金額合計
・棒を東京だけの売上金額にすることができるのでしょうか。

・地域をフィルターで東京だけに設定します。
折線も棒も東京の売上金額を示します。フィルターは表全体へ適用されます。
一般式は表に従って計算します。横浜を除いて東京だけにフィルタリンスすれば、表全体が東京だけになります。
LOD表現とフィルターで解決
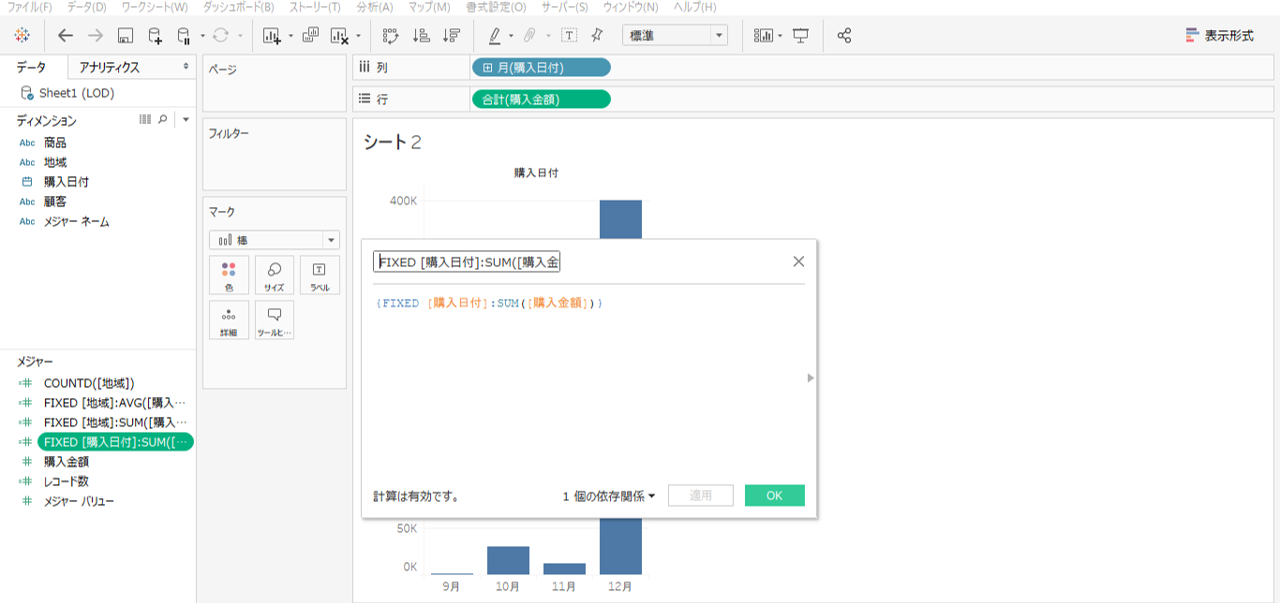
LOD式内へフィルターしないディメンションを指定します。
地域ではないディメンションです。横軸が購入日付なので「購入日付」を指定します。
{FIXED [購入日付]:SUM([購入金額])}
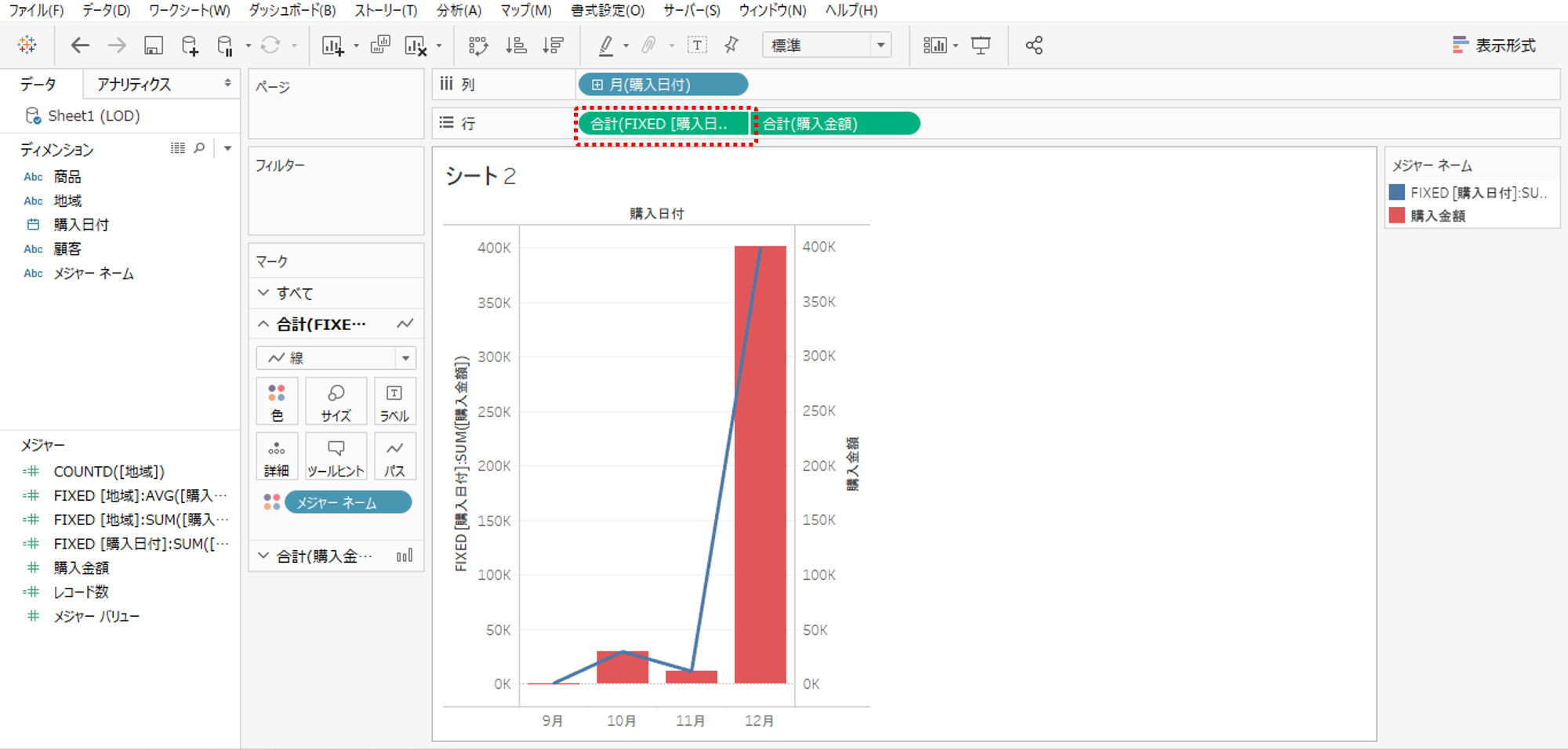
・行シェルフの一方の購入額を「{FIXED [購入日付]:SUM([購入金額])}」へ変更します。
・形状は線です。
折線と棒の値が一致していることを確認します。
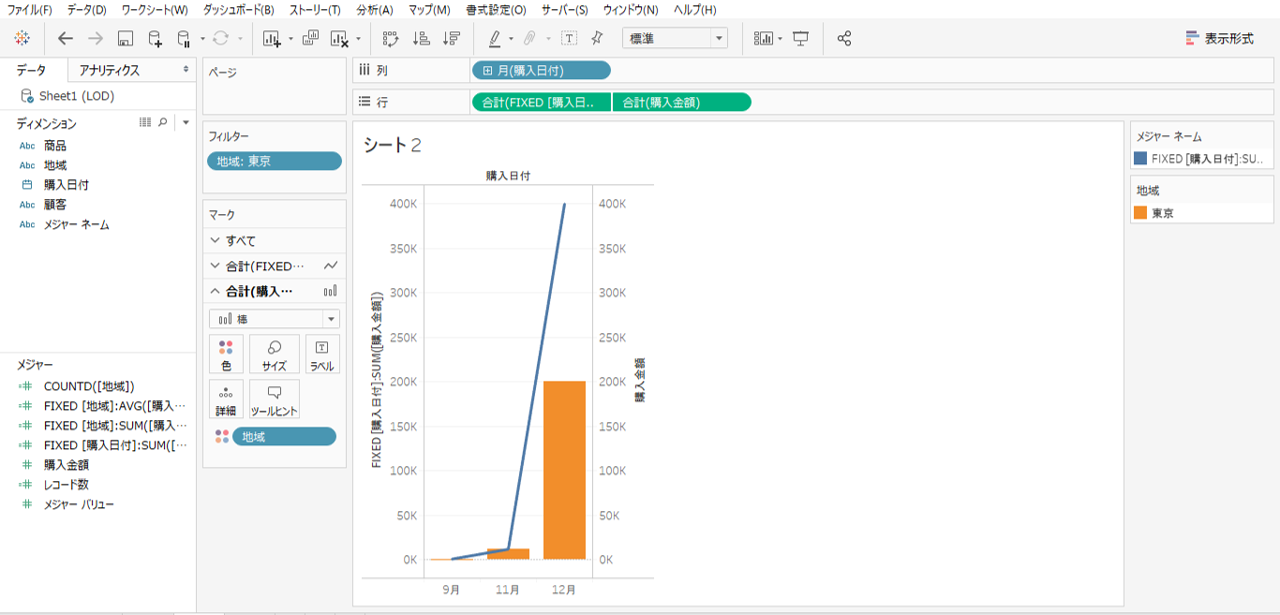
・地域でフィルタリングして東京だけを保持します。
・LOD式の折線はフィルタリングまえと同様です。
・一般式の棒はフィルターが適用されることで東京だけの購入金額を示します。