
RFM分析 – エクセル編
顧客をグループ化し、その特徴を理解しようとするRFM分析。実践では「常連客」「休眠客」のようなグループ化を目的とせず、「購入金額が高い顧客」でも「最終来店日」「来店頻度」には様々なパタンがあって一括りにはできないことを教えてくれるのがRFM分析なのうだろう。とにかくグループ化が難しい!
データ
会員データ
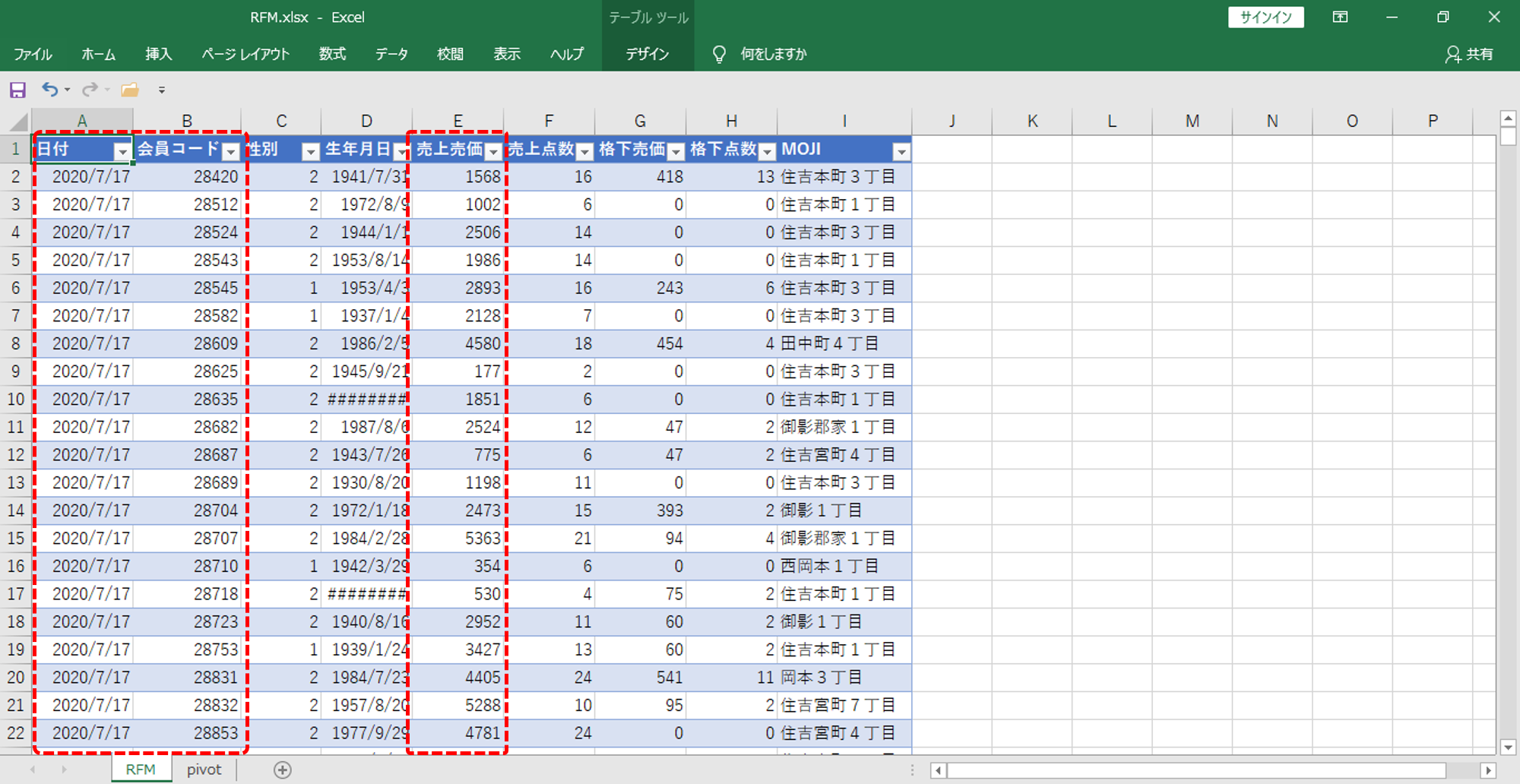
日別・会員別・売上データ
期間:2020年6月1日~2020年11月30日 (6か月間)
会員数:4,159名
実在しない架空のオリジナルデータです。
RFM分析に必要な値
・R (最終購買日)
会員ごとの「日付」 (購入した日) の最大値で算出
・F (購入頻度)
データ期間中 (6か月間) の会員ごとの「会員コード」の個数 (重複可) をカウント
・M (購入金額)
データ期間中 (6か月間) の会員ごとの「売上売価」を合計する
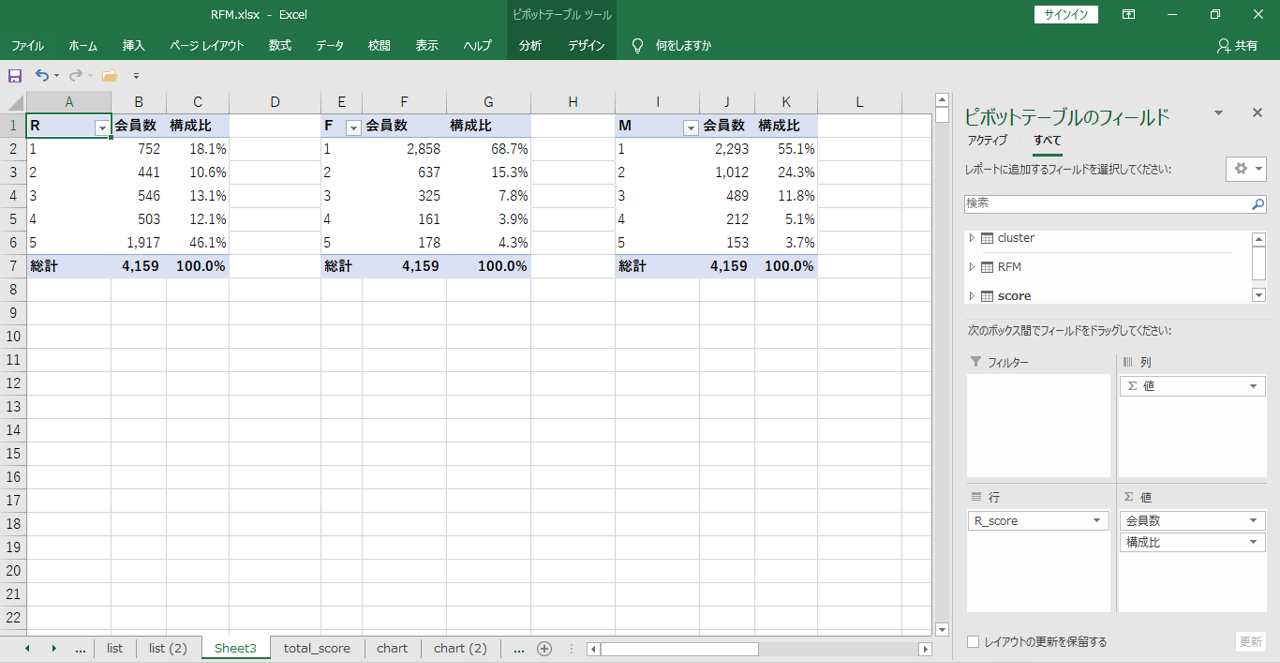
ピボットで値を集計
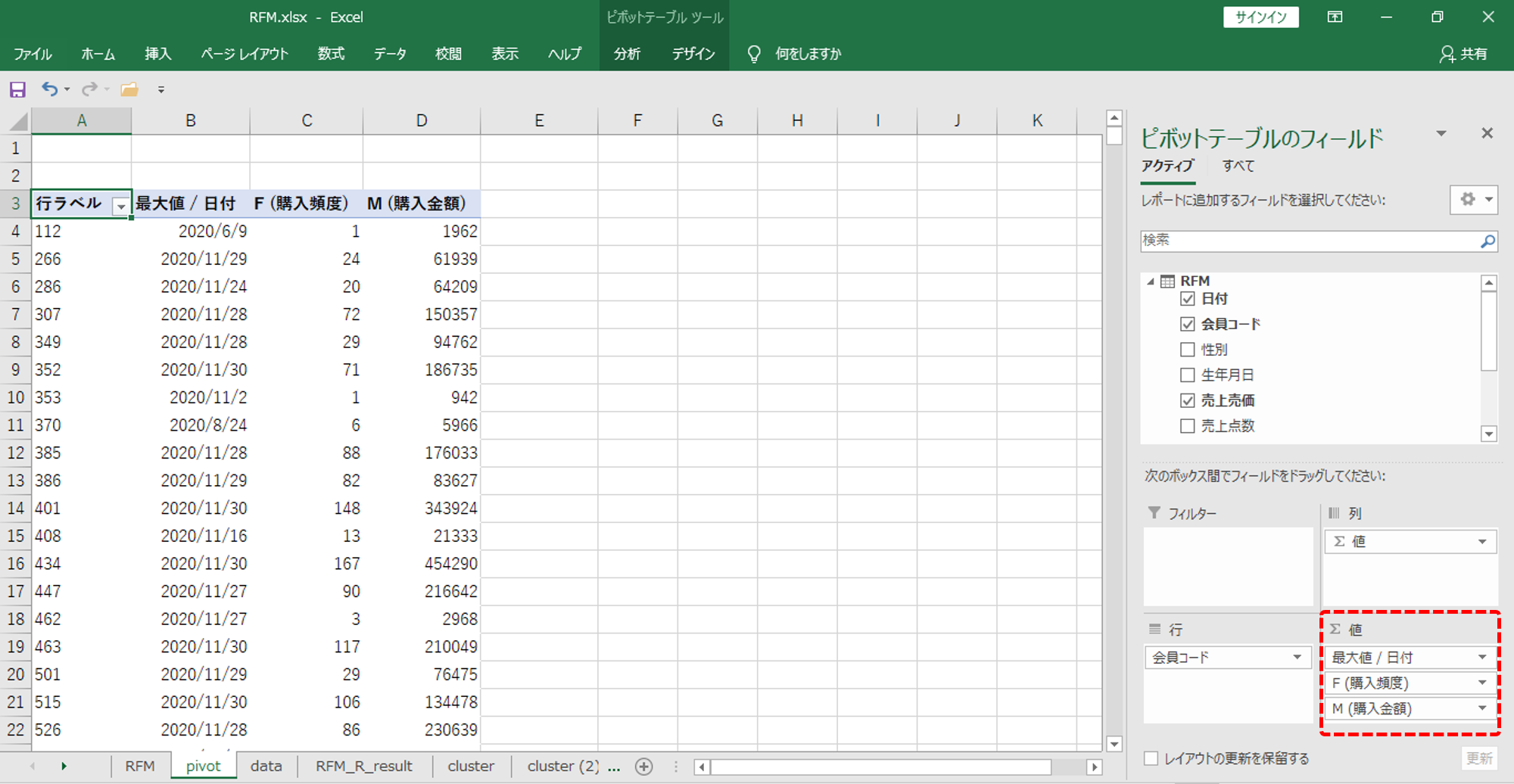
・行は「会員コード」です。
・R (最終購買日)
「日付」を
「値フィールドの設定」→「集計方法」→「最大」
・F (購入頻度)
「会員コード」を
「値フィールドの設定」→「集計方法」→「個数」
・M (購入金額)
「売上売価」
日付の値は数値が望ましい
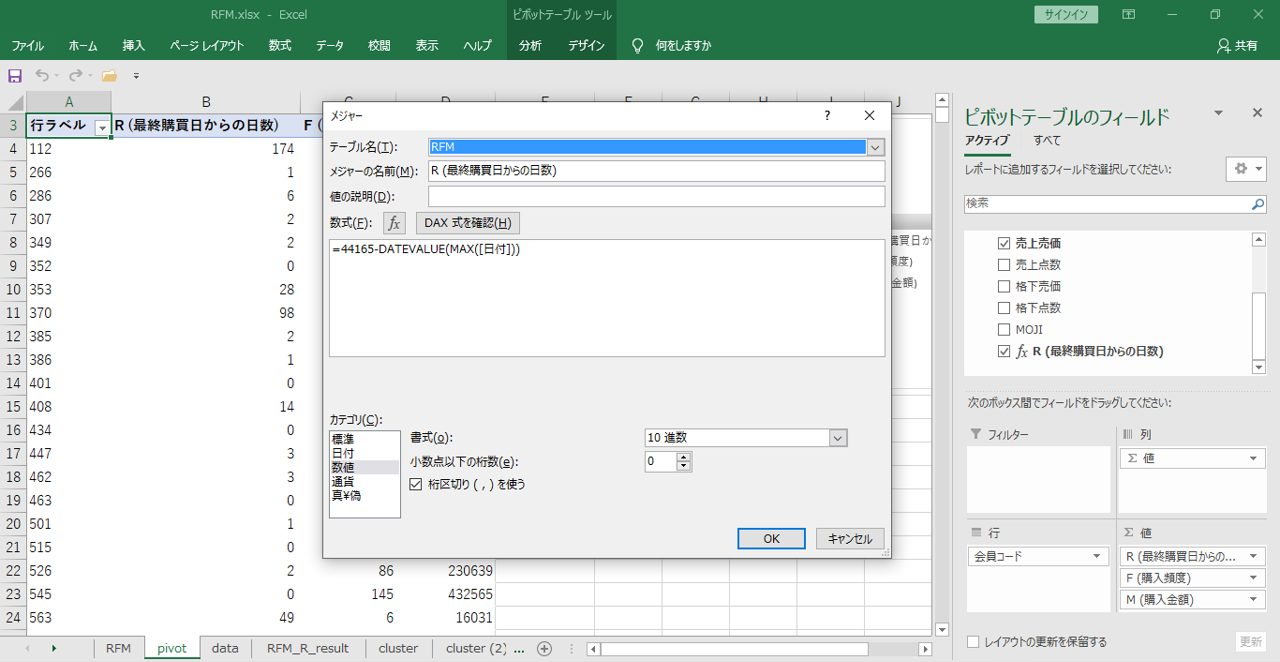
R (最終購買日)が日付形式になっています。
本日と最終購買日の差分を数値へ変換します。最終購買日から現在までの経過日数を算出します。
・現在を2020年11月30日とします。
・2020年11月30日をシリアル値へ変換すると「44165」です。
・最終購買日をシリアル値へ変換して、現在との差分を算出します。
# DAX式 =44165-DATEVALUE(MAX([日付]))
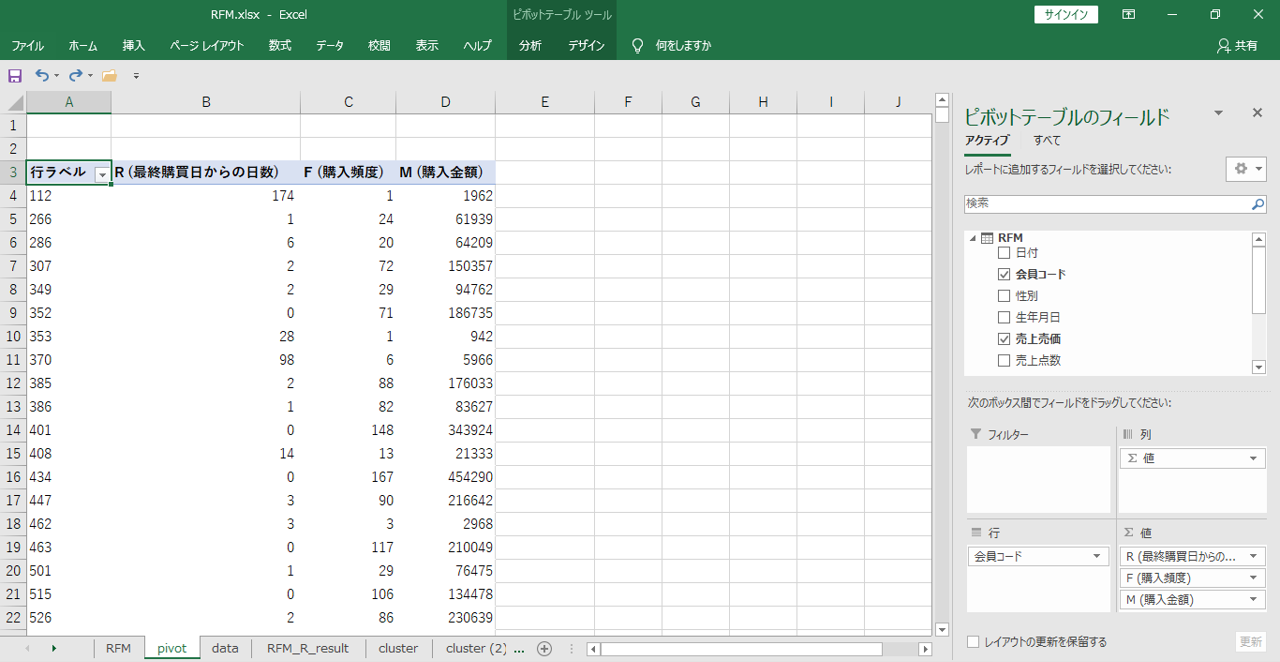
RFM分析のもとになるデータはこれで完成です。
グループ化
データを見える化
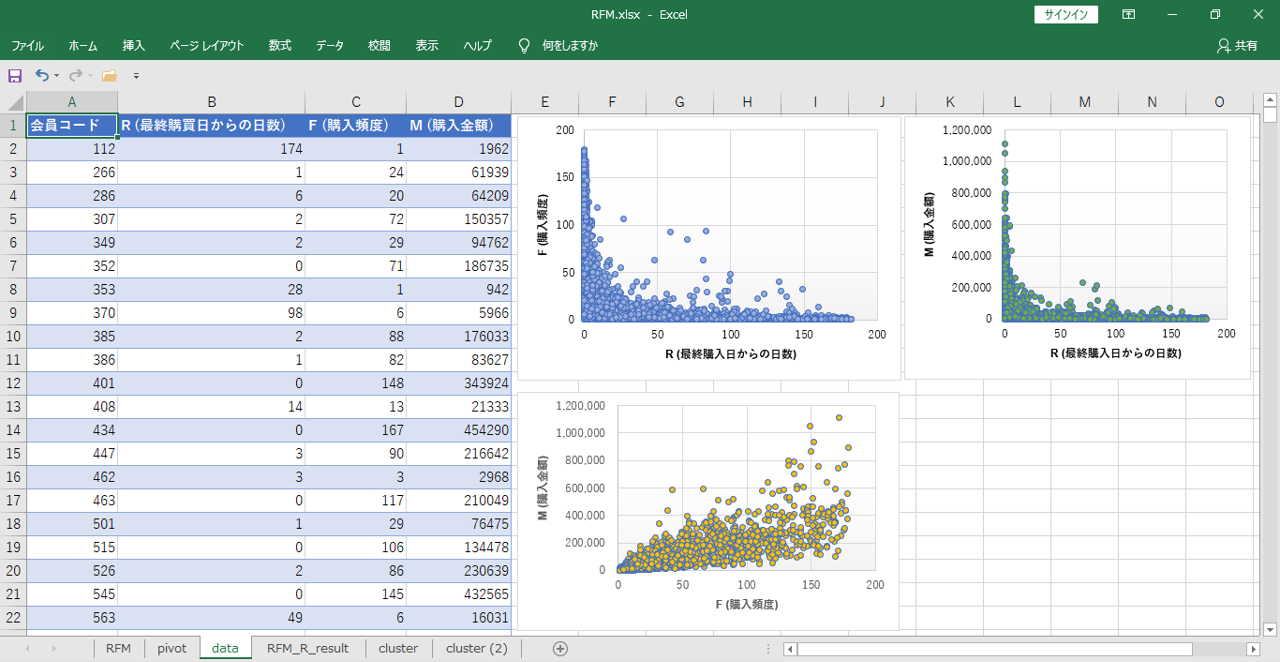
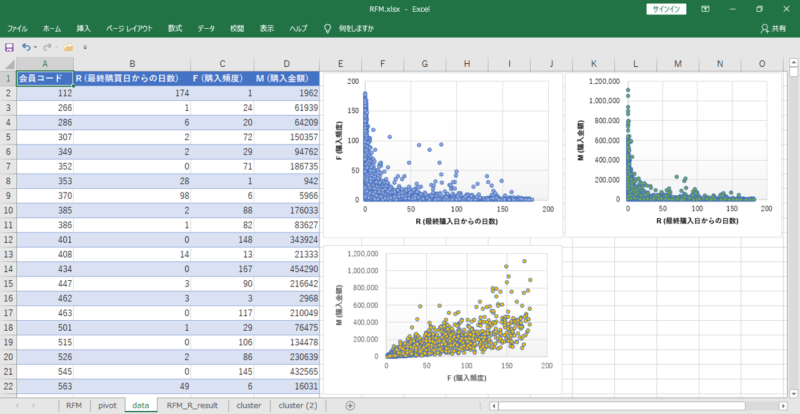
データは3変数です。
・R (最終購買日)
・F (購入頻度)
・M (購入金額)
3種類の2次元散布図を作成することができます。
さて・・・どのように顧客をグループ化するのか?
スコアカード方式 (一般的)
| スコア | R (最終購買日) | F (購入頻度) | M (購入金額) |
| 5 | 1週間以内 | 120回以上 | 300,000円以上 |
| 4 | 2週間以内 | 90回以上 | 200,000円以上 |
| 3 | 1か月以内 | 60回以上 | 100,000円以上 |
| 2 | 2か月以内 | 30回以上 | 30,000円以上 |
| 1 | 2か月を超える | 30回未満 | 30,000円未満 |
このようなスコアカードを作成します。
合計方式
| 会員 | R (最終購買日) | F (購入頻度) | M (購入金額) | 合計スコア |
| A | 3日 | 100回 | 100,000円 | |
| Aのスコア | 5 | 4 | 3 | 12 |
| B | 3日 | 40回 | 300,000円 | |
| Bのスコア | 5 | 2 | 5 | 12 |
会員ごとにスコアを合計し、スコアごとのグループを作成します。
| 合計スコア | 会員数 | 会員コード |
| 15 | 10 | 10名の具体的なコード |
| 14 | 20 | 20名の具体的なコード |
| 13 | 40 | 40名の具体的なコード |
| 最低スコア3まで |
合計スコアでグループ化すると、最低スコア3から最高スコア15までの13グループをつくることができます。
課題は、AもBも同一のグループになることです。
・Aの来店頻度100回にたいしてBは40回
・Aの購入金額10万円にたいしてBは30万円
感覚的にAとBは違うように思います。
細分化方式
| グループ | R (最終購買日) | F (購入頻度) | M (購入金額) | 合計スコア | 会員コード |
| 15 | 5 | 5 | 5 | 15 | 10名の具体的なコード |
| 14_1 | 5 | 5 | 4 | 14 | 20名の具体的なコード |
| 14_2 | 5 | 4 | 5 | 14 | 15名の具体的なコード |
| 14_3 | 4 | 5 | 5 | 14 | 20名の具体的なコード |
| 13_1 | 5 | 5 | 3 | 13 | 10名の具体的なコード |
合計スコアをさらに細分化します。
3変数あるので、
・5×5×5=125グループができます。
これではグループ数が多すぎます。管理可能なグループ数になるように、いくつかのグループをまとめます。
そうなると、結局は合計スコアでのグループ化の結果に近づきます。
細分化方式をどのように見える化するのか
<課題>
・変数が3種類ある。
3次元の見える化が望ましいが表現も理解するのも難しい。
・125グループある。
表が125行になる。チャートでも125系列になる。それぞれのグループの特徴を表現することが難しい。
そうなると、会員をグループごとに分類できたとしても具体的なアクションへは至らないだろう。
<解決方法>
・見たいグループだけを抽出して見える化する
たとえば、
・R (最終購買日) スコアが「1」 (最近の来店実績がない) のグループ
AND
・M (購入金額) スコアが高いグループ
見える化手順
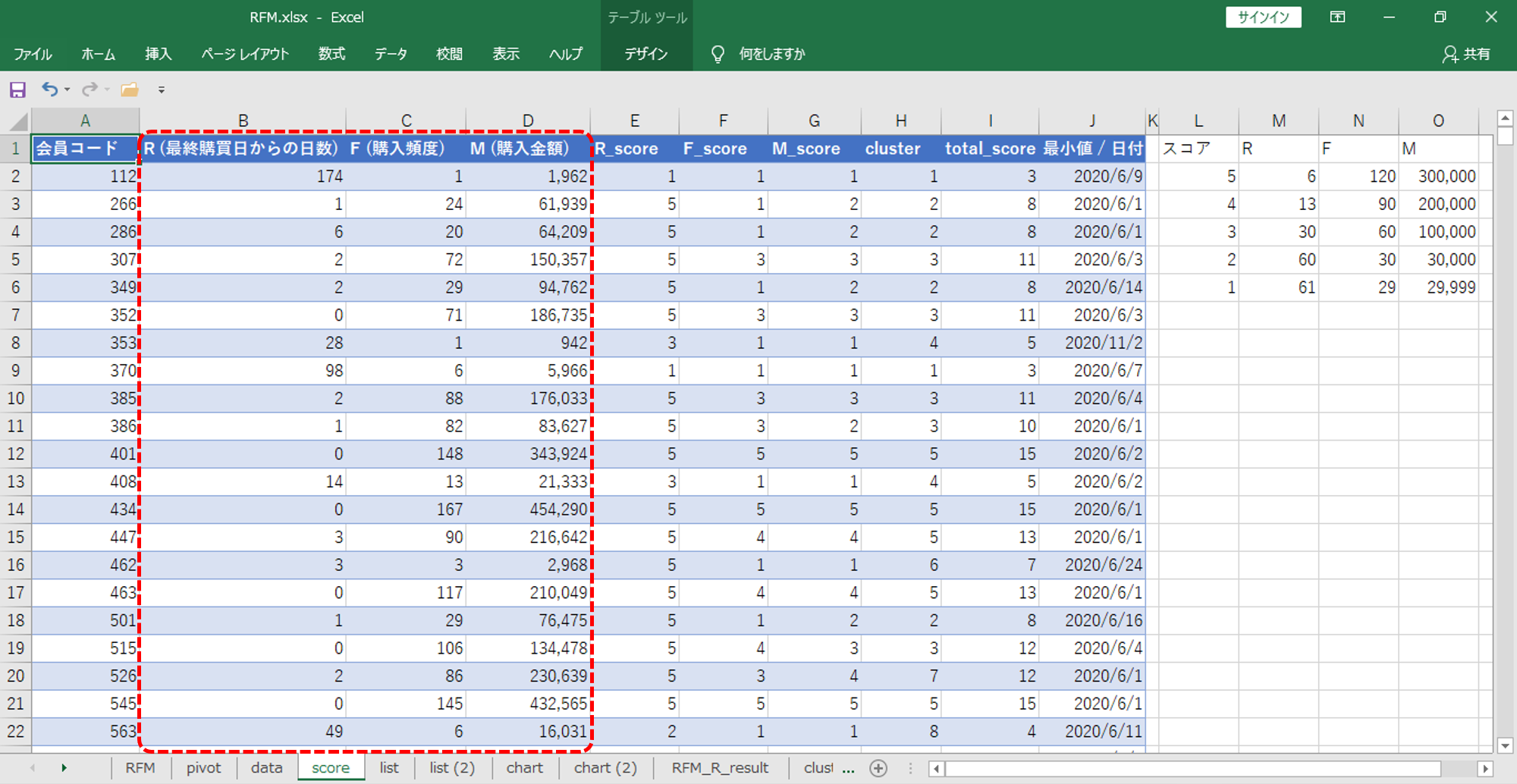
スコア
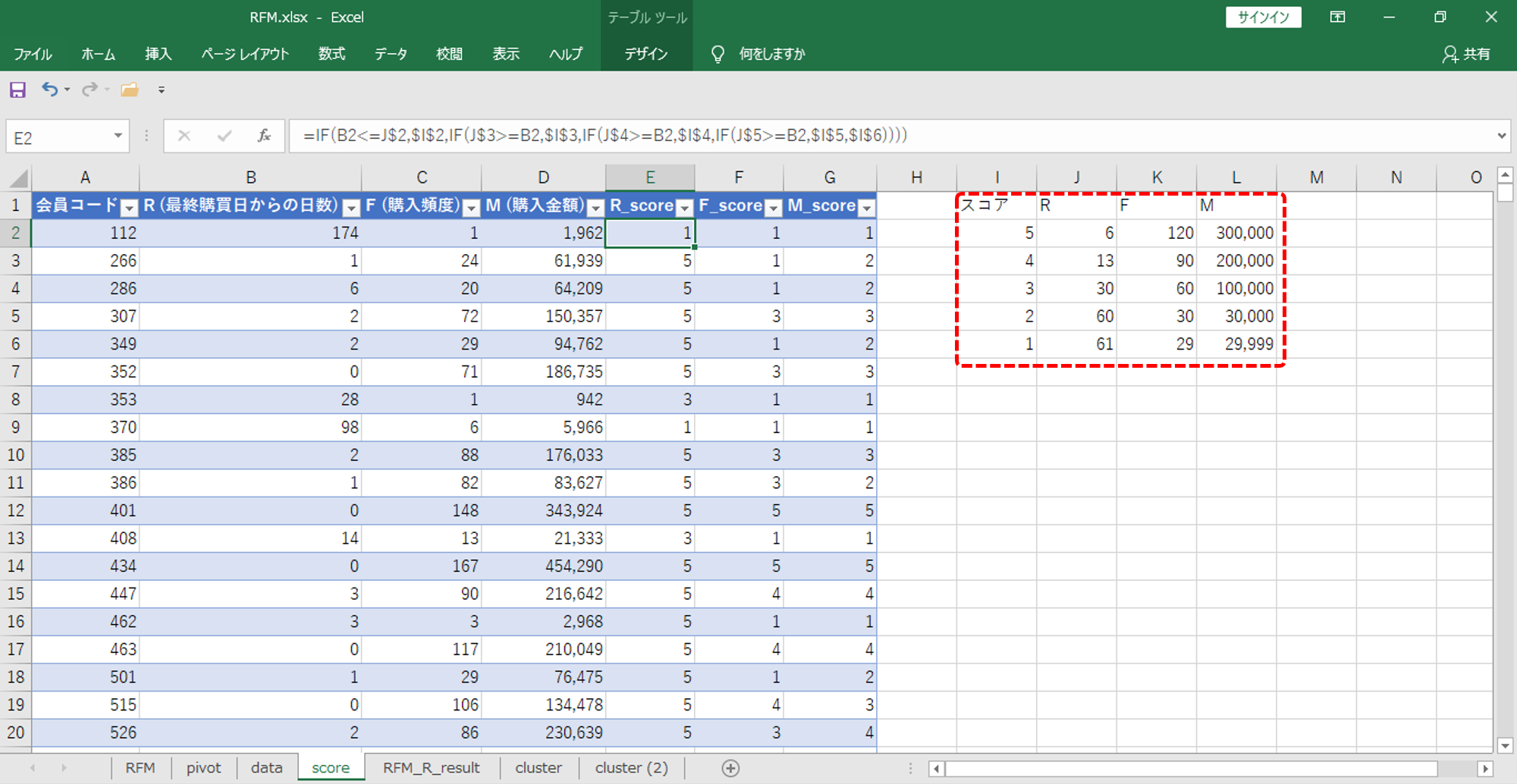
スコアカードを作成します。
今回のスコアとそれぞれの値についての根拠はありません。
食料品スーパーを想定しているので、
・「トップグループ顧客なら最終購買日は1週間以内だろう」
・「トップグループ顧客なら3日に2回は来店するだろう」
・「トップグループ顧客なら1か月あたり一般的な食料品支出額5万円は購入するだろう」
これらの想定と、散布図を見ながら決めました。
スコアカードができたら、会員コードごと・RFMごとにスコアを与えます。
その他の値
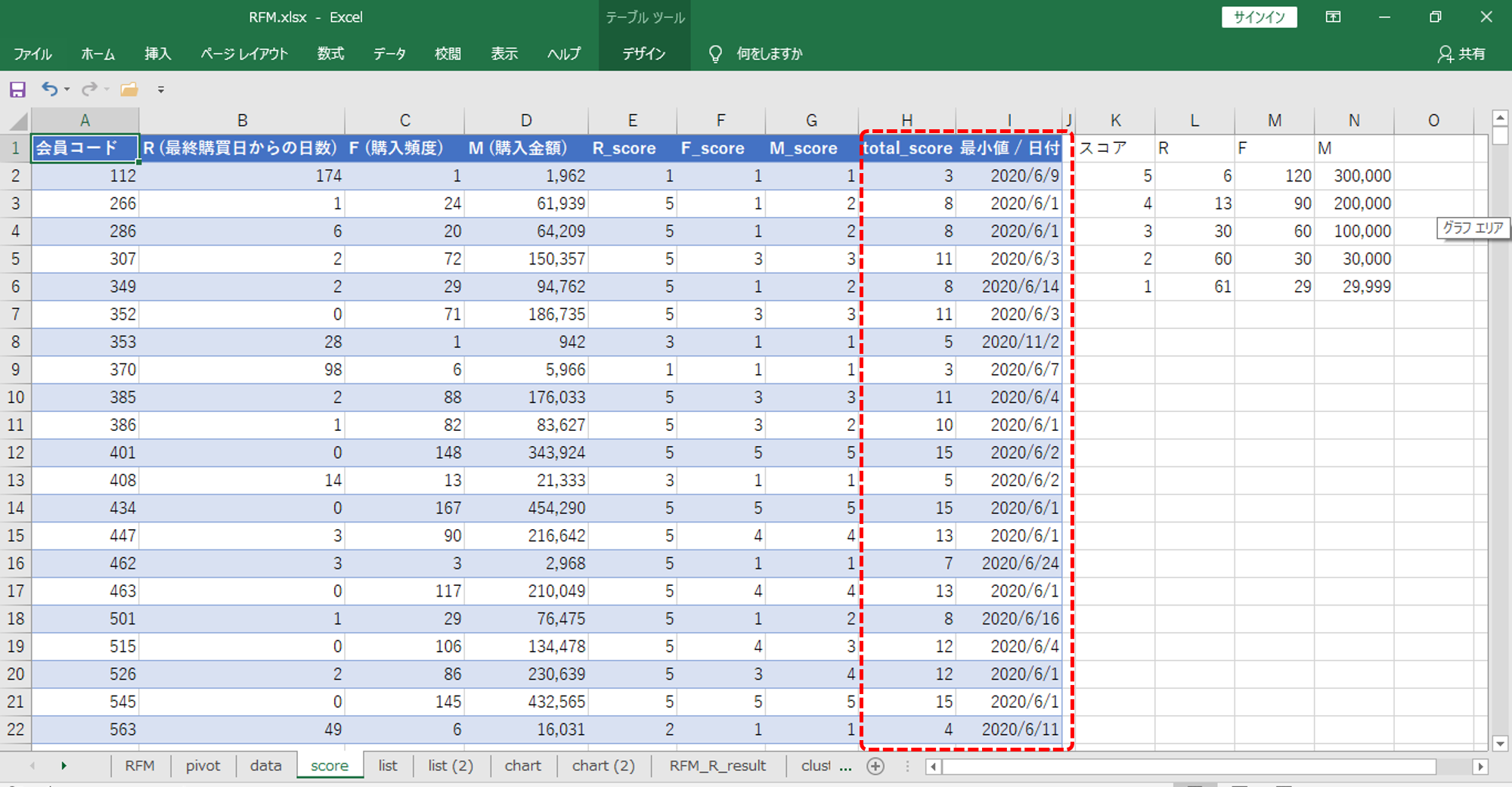
・RFMのスコアを合計します。
スコア合計方式でも分類できるようになります。
・会員コードごとの「日付」の最小値
会員コードごとの初回購入日になります。
Aさんは7月に新規会員になった (初回購入した) 、Bさんは8月からの会員・・・ということがわかります。
リレーションシップ
・もとデータ (日別・会員別・売上データ) とリレーションシップします。
・リレーションフィールドは「会員コード」です。
会員コードを特定する
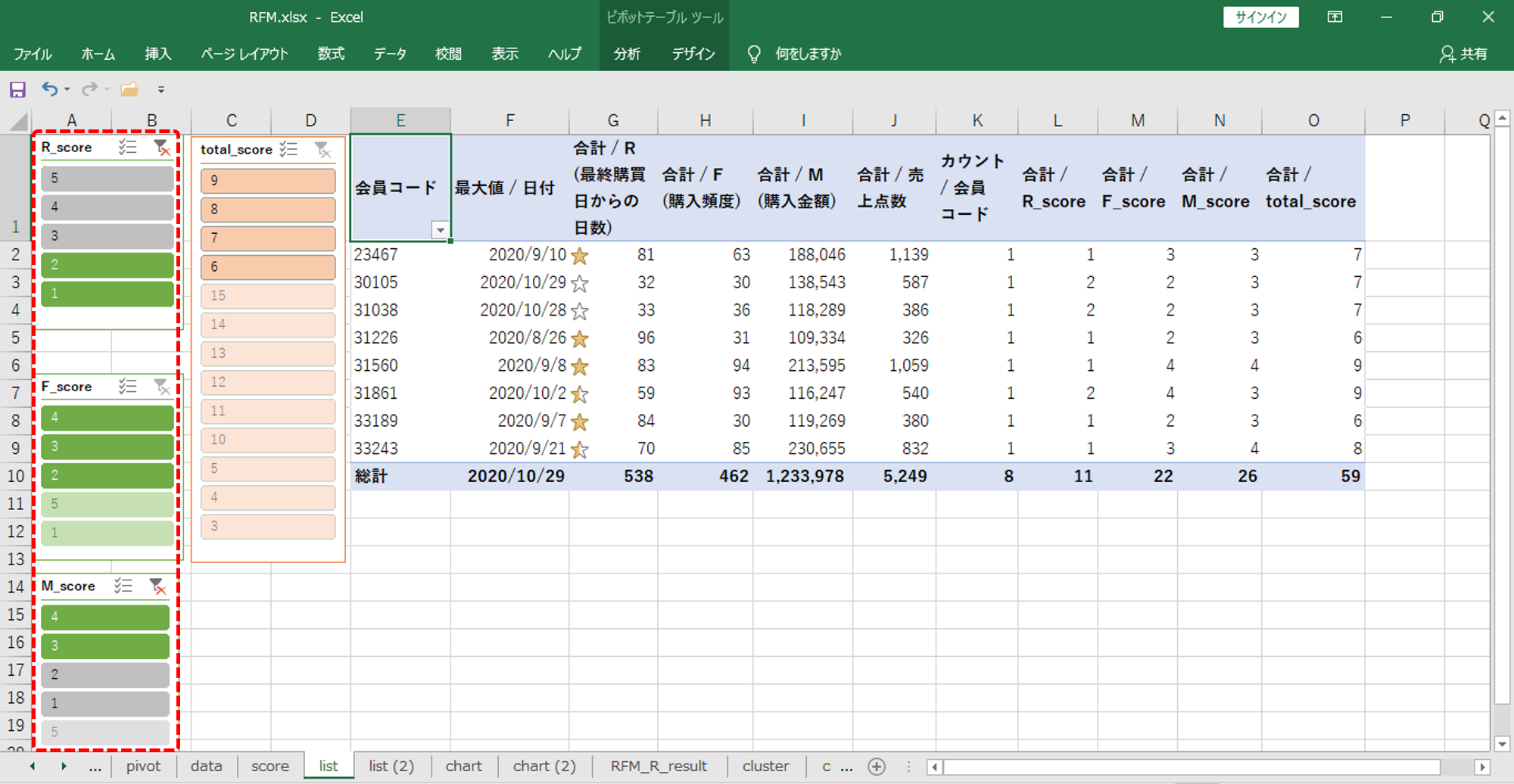
ピボットテーブルを作成します。
・列が「会員コード」
・値が
「日付」の最大値 (日別・会員別・売上データ)
「R (最終購買日からの日数)」
「F (購入頻度)」
「M (購入金額)」
「会員コード」の重複しない個数
「RFMそれぞれのスコア」
「RFMの合計スコア」
・RFMそれぞれのスコアと合計スコアをスライサーに設定します。
・R (最終購買日) スコアが低いグループを選択
・M (購入金額) が高いグループを選択します。
かつては高い購入金額、最近は来店購入がなくなった8名の会員をみつけることができました。
・再び来店していただく
・現在の高スコア会員を離脱させない
これらの対策が必要です。
この8名が
・過去にどのような商品を購入していたのか?
・住所、年齢、性別などの属性は?
・6か月よりも前に遡って、どのような購買履歴があるのか?
具体的アクションのヒントが見つかるかもしれません。
チャート
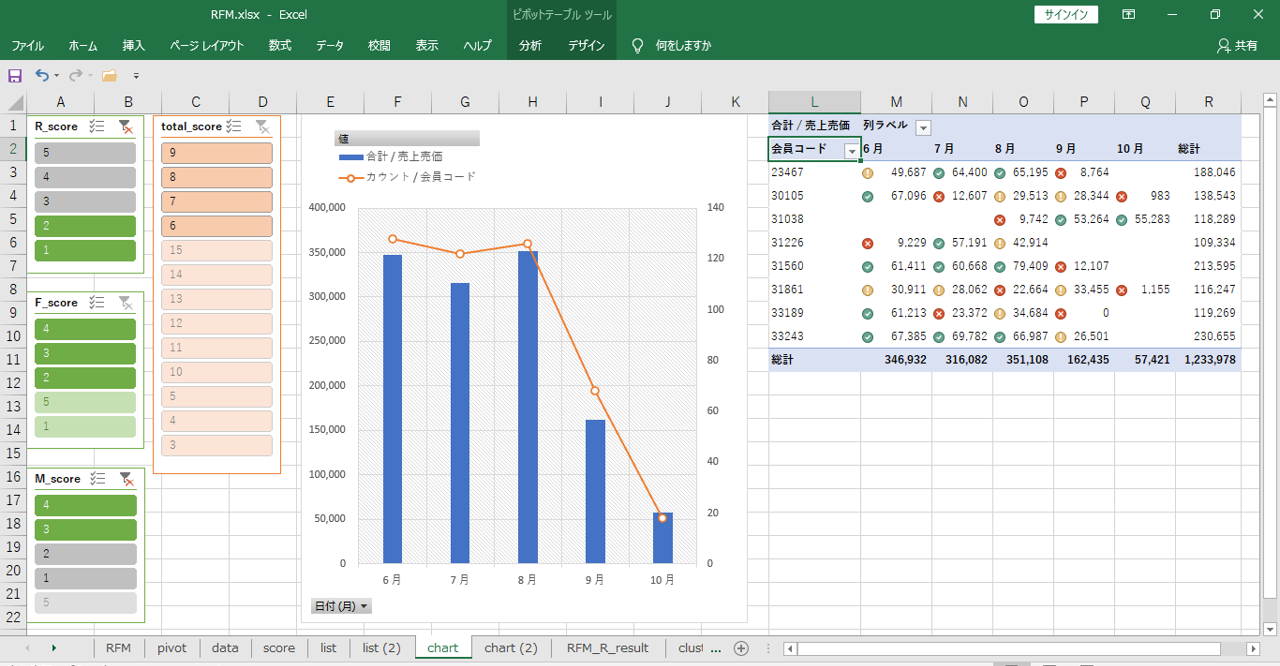
グラフを作成します。
・列が「日付の月」(日別・会員別・売上データ)
・値が
「売上売価 (合計)」(日別・会員別・売上データ)、「会員コード (個数)」(日別・会員別・売上データ)
・組み合わせグラフ
11月は購入額ゼロになってしまった8名の月別購入額・来店回数のグラフです。
もしも8名が引き続き来店購入されていたら、11月の売上はおよそ30万円アップしていたかも!
ピボットテーブルを作成します。
・行が「会員コード」
・列が「日付の月」(日別・会員別・売上データ)
・値が「売上売価 (合計)」(日別・会員別・売上データ)
・条件付き書式でアイコンセットを挿入します。
じわりじわりと購入金額が漸減するということではなく、突然に来店しなくなるパタンが多いようです。
特徴的な会員を発見する
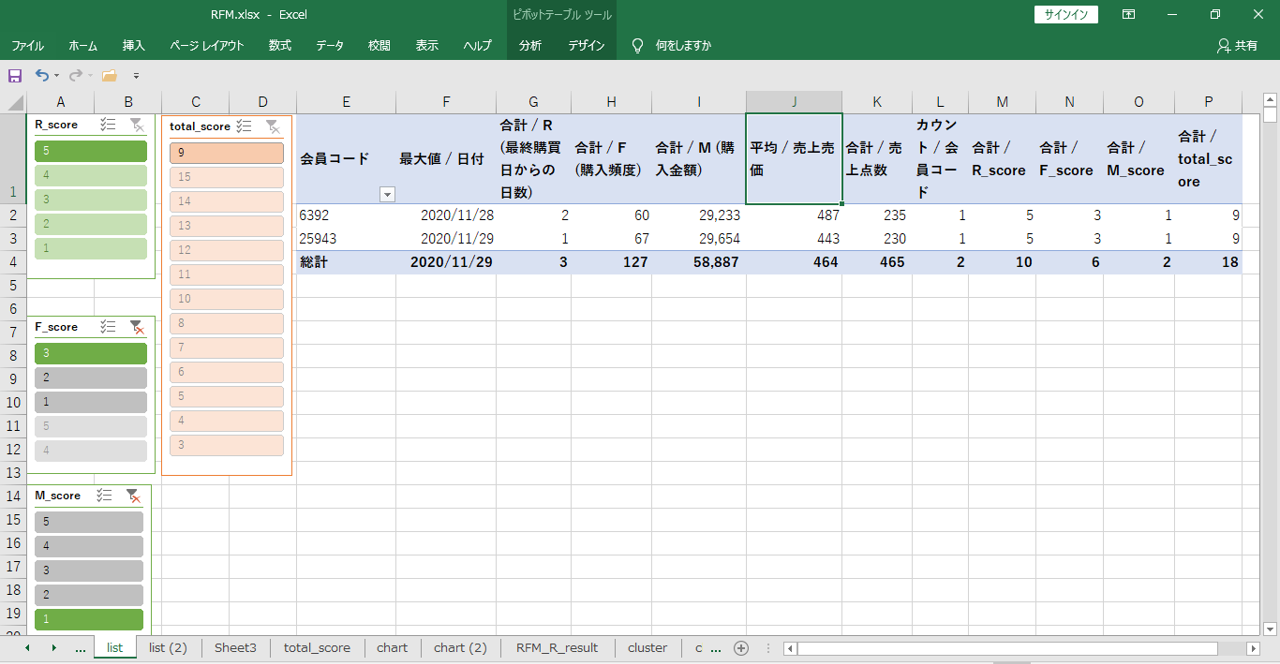
Mのスコアが1、Fのスコアが3です。
3日に1回は来店購入があります。昨日か一昨日に来店購入があります。1回あたり購入額は500円未満です。この会員は常連客なのかどうか?
常連客か、否かよりも重要なのは、特徴的な会員から何を発見できるのかということだろうと思います。
・店舗の近所に勤めていてお弁当を購入している
たとえば、このような発見ができれば
・近隣の事業所へお弁当のチラシを配布する
・お弁当の予約を受け付ける
・数量がまとまれば宅配する
いくつかのアクションプランを考えることができます。
初回購入日
RFMのFは購入頻度です。RFM分析の一般的な解説では、
「Fのスコアが低い顧客が少ない場合は新規の顧客が少ない」
ピンとこないロジックのように思うのですが・・・
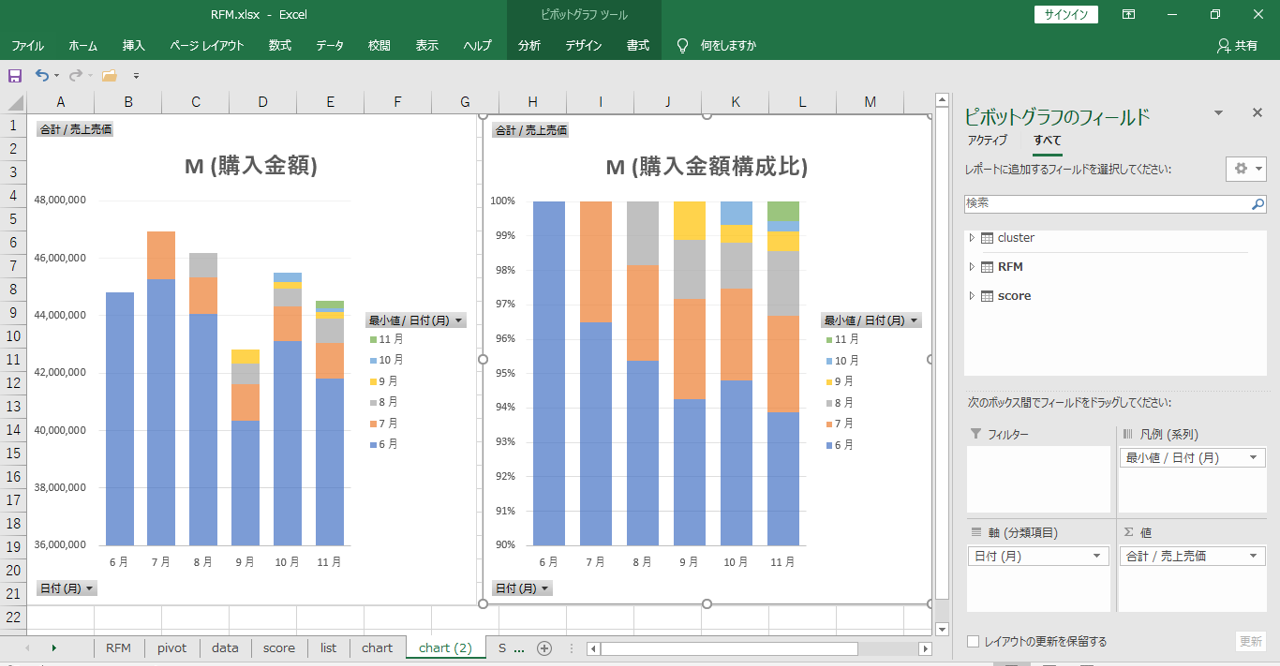
単純に新規顧客は「初回購入日」で見分けることをオススメします。
・軸が「日付の月」(日別・会員別・売上データ)
・値が「売上売価 (合計)」(日別・会員別・売上データ)
・系列が「日付の最小の月」
6月の売上はすべて6月初回購入日の会員で構成されます。このデータは6月から始まるデータだからそうなります。
7月の売上は6月初回購入の会員と7月初回購入の会員で構成されます。
月次で新規会員が上積みされ、過去の会員のうちの一部が消え去り、数か月後に復活することもあります。
チャートから
・7月、8月の新規会員は安定的に継続購入がある
・9月の新規会員は離脱が目立つ
・10月、11月は新規会員の売上が少ない
グループ化に挑戦
合計スコア
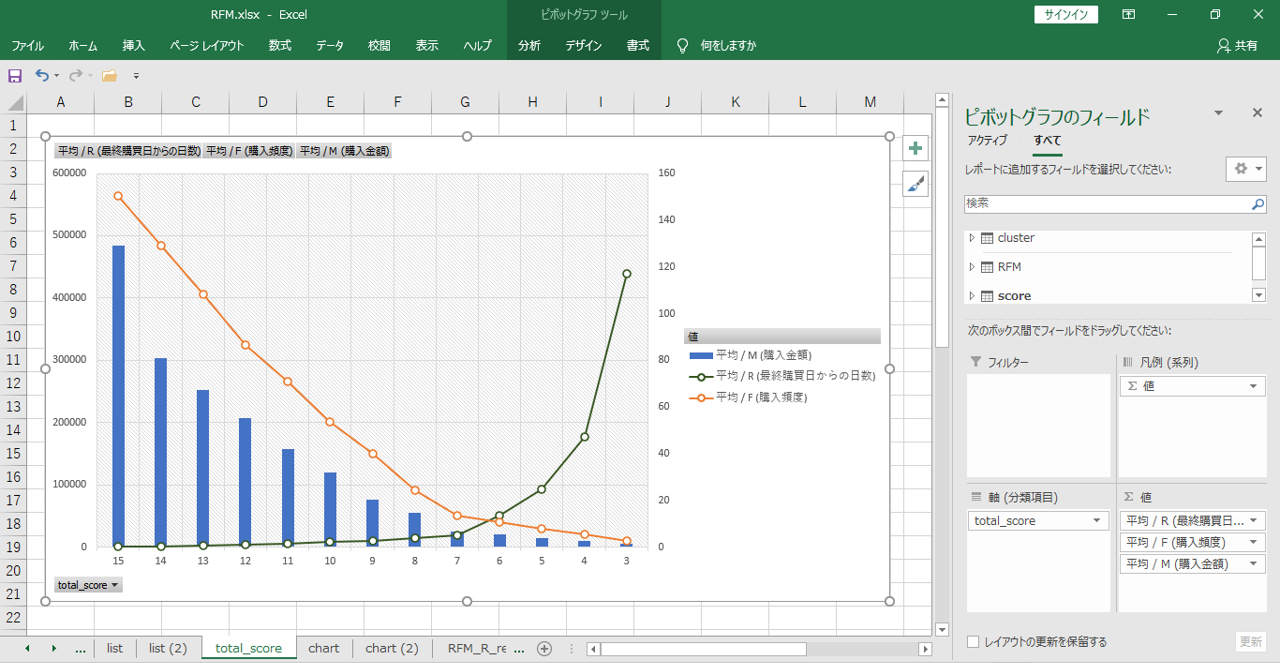
・軸が「合計スコア」
・値がR・F・Mそれぞれの平均
・組み合わせグラフ
それらしくグループ化できているように見えます。しかし、何か特徴的な事象を発見できるかというと難しいと思います。
R・F・Mすべての値が合計スコアと完全に比例しているからです。平均を表示しているからなのか。
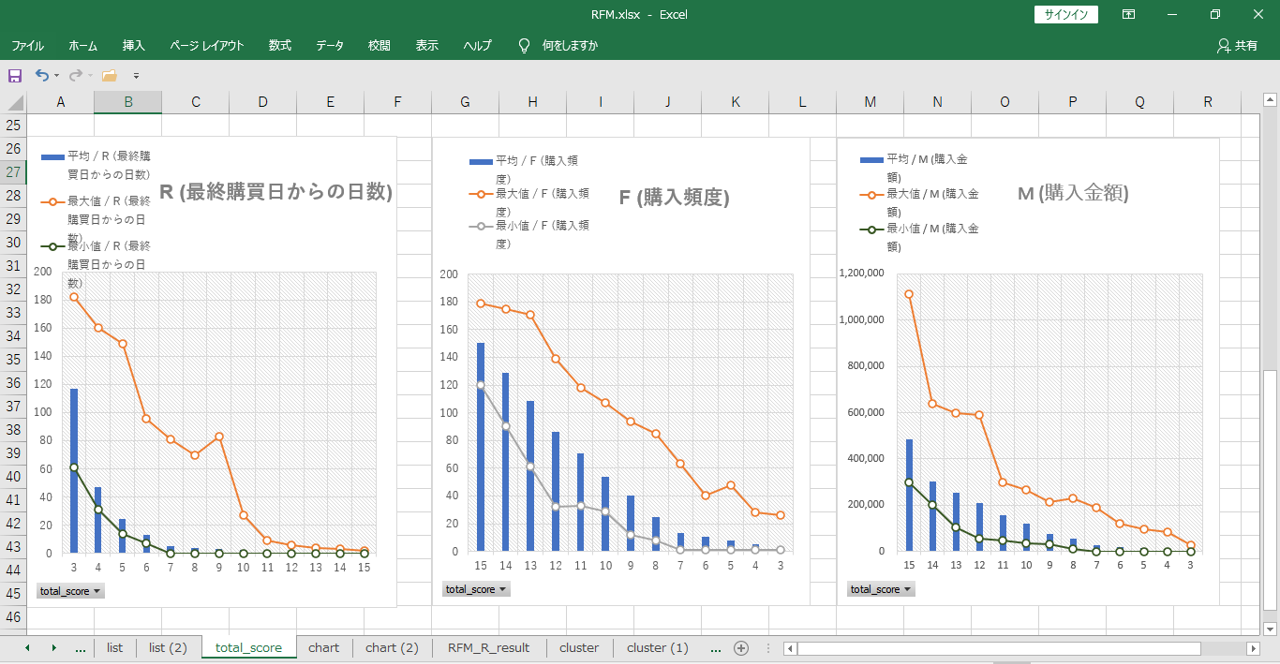
R・F・Mそれぞれの平均値、最大値、最小値を表示します。
例えば、本日来店した会員も2か月以上来店していない会員も同一グループになることがあります。
それぞれの最大値・最小値の幅が大きくグループ化としては厳しいようです。
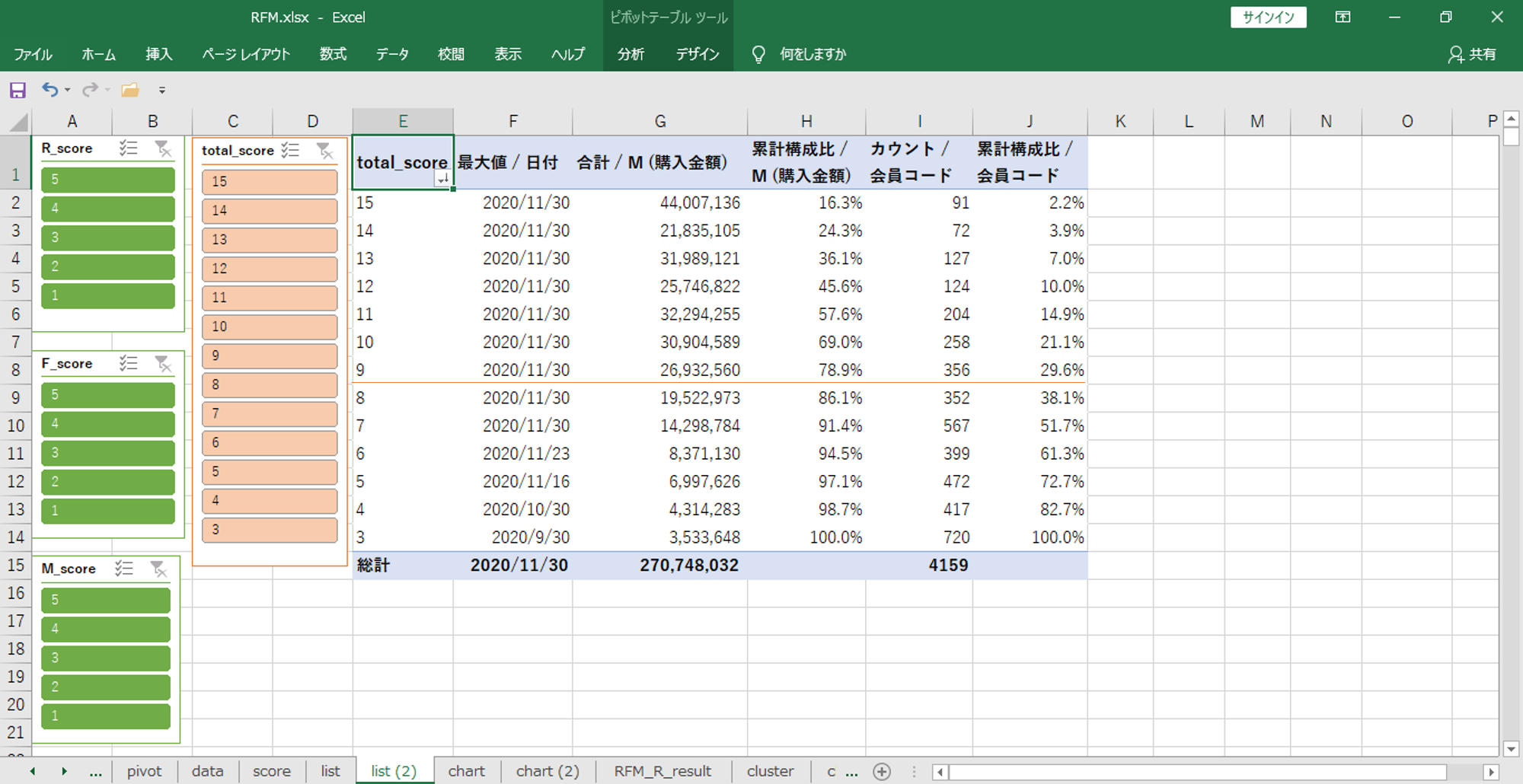
・行が「合計スコア」
・値が
「日付 (最大)」
「購入金額 (合計)」
「購入金額 (割合の累計)」
「会員コード (個数)」=来店回数
「会員コード (個数の割合の累計)」
売上構造の全体を眺めるのにはよい方法だと思います。
やはり、個別会員へドリルダウンするには物足りないようです。
クラスター
クラスターで特徴を捉えることができるのか
合計スコア方式をつかえば全会員を13のグループにわけることができます。ところが、各グループの特徴が見えてこない。
R・F・Mの3変数だから・・・クラスターを形成すればどうか!
スコアでクラスター
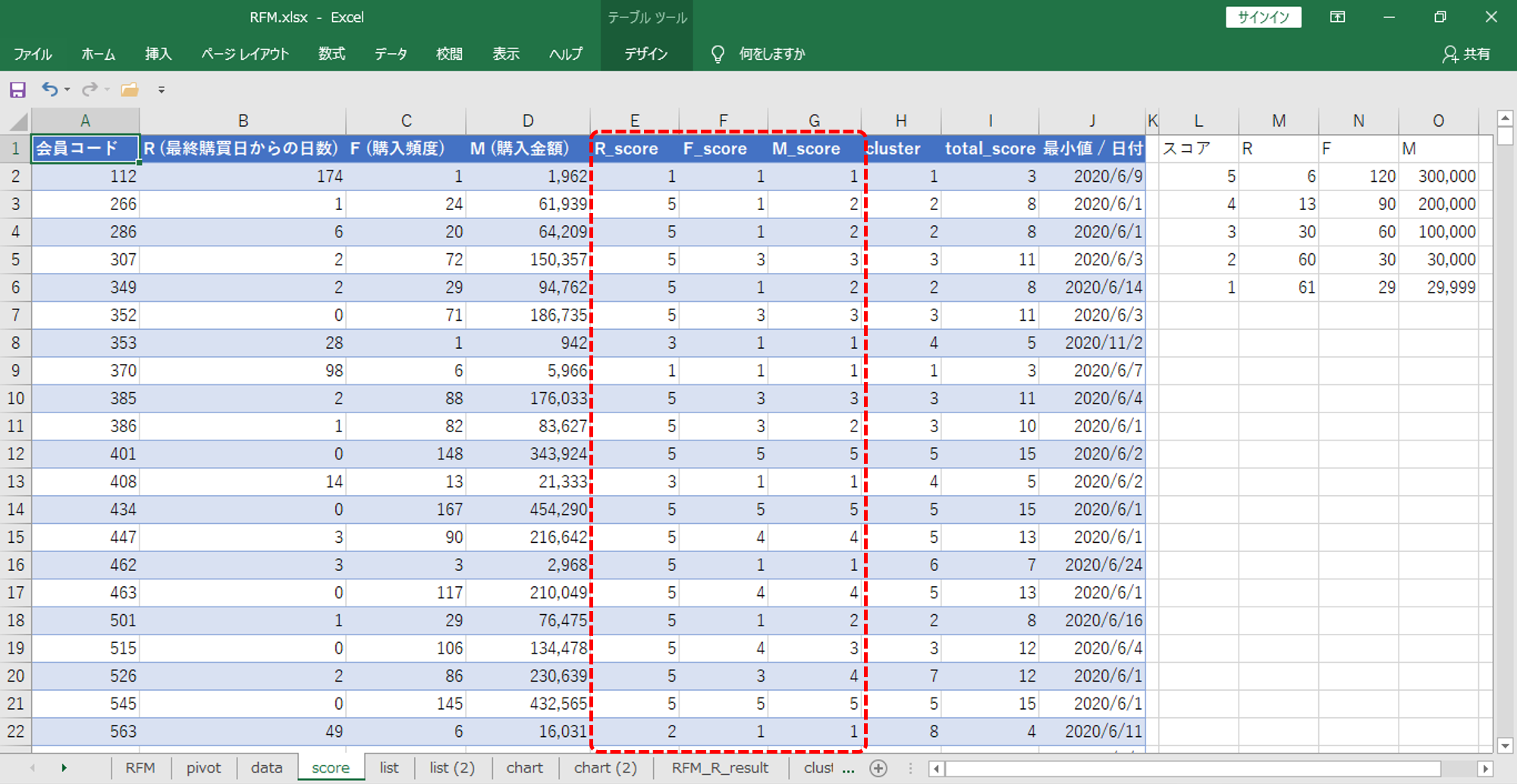
R・F・Mそれぞれのスコアを変数にしてクラスタリングを行います。

結果をプロットします。R・F・Mそれぞれの値は平均です。
M (平均) 降順に並び替えています。RとFに山あり谷あり、Mの降順と比例しないクラスターがあるあたりが期待できます。
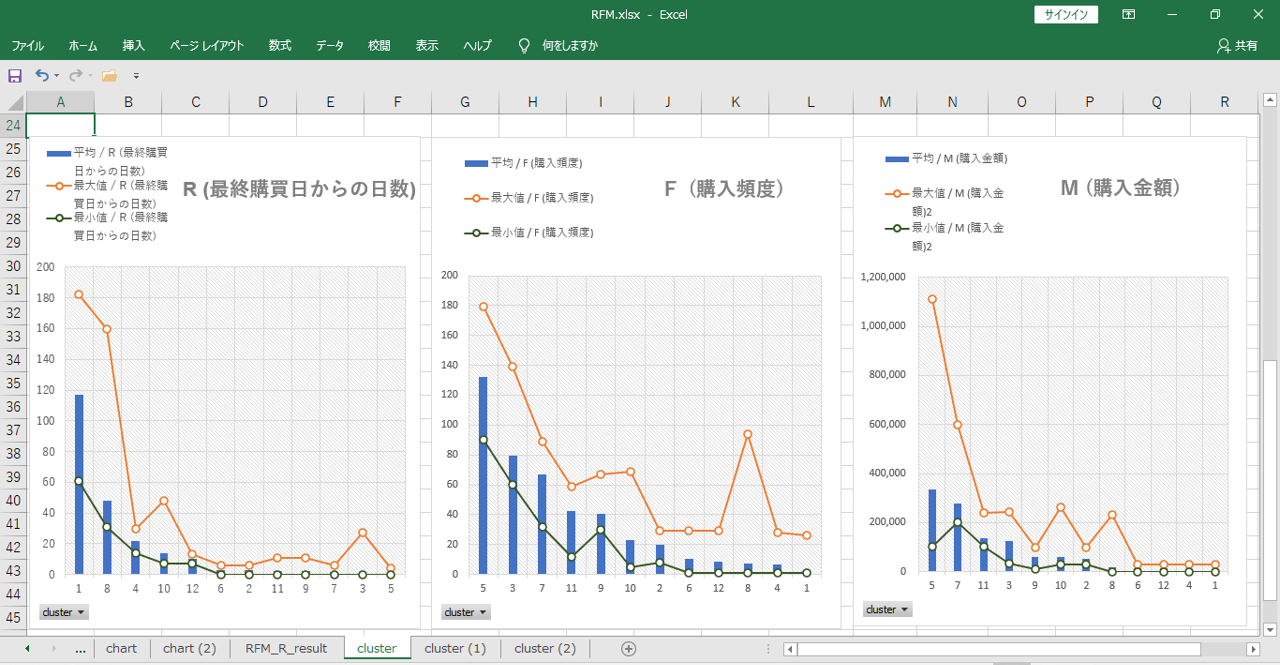
それぞれの最大値と最小値に大きな幅があるように見えますが、感覚的には結構いい線になっているように見えます。何となくですが。
・スコア表の基準値
・スコアの段階数
・データの期間
・クラスター数
これらの調整がフィットすれば、いい感じになるような気がします。
今回は特に、Rのスコア基準値が甘くスコア5が多すぎたみたいです。食料品スーパーを想定したデータなので、スコア5の基準値を2日、スコア4の基準値を5日くらいまで厳しく設定すべきでしたか。
スコアを使用しないクラスター
単純にR・F・Mそれぞれの値を変数に設定してクラスタリングすればよいのでは!
スコア表が要らないし、ややこしいIF文をタイピングする必要がなくなる!
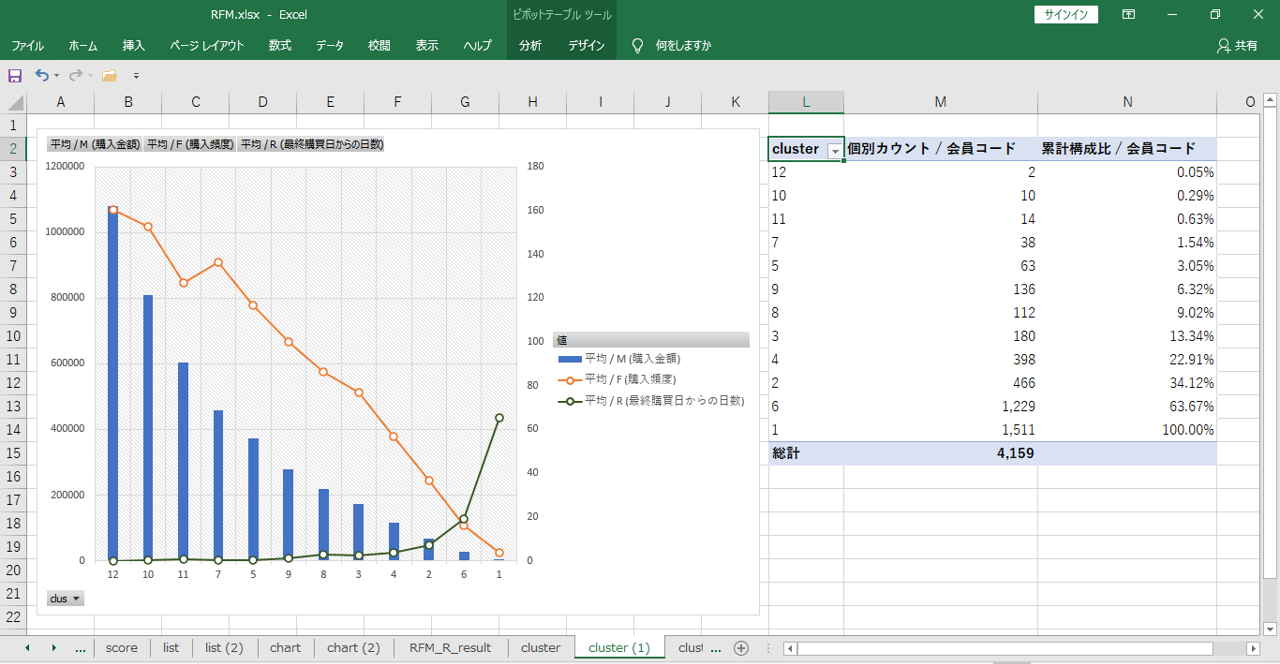
パッと見て、合計スコアと同じように見えます。
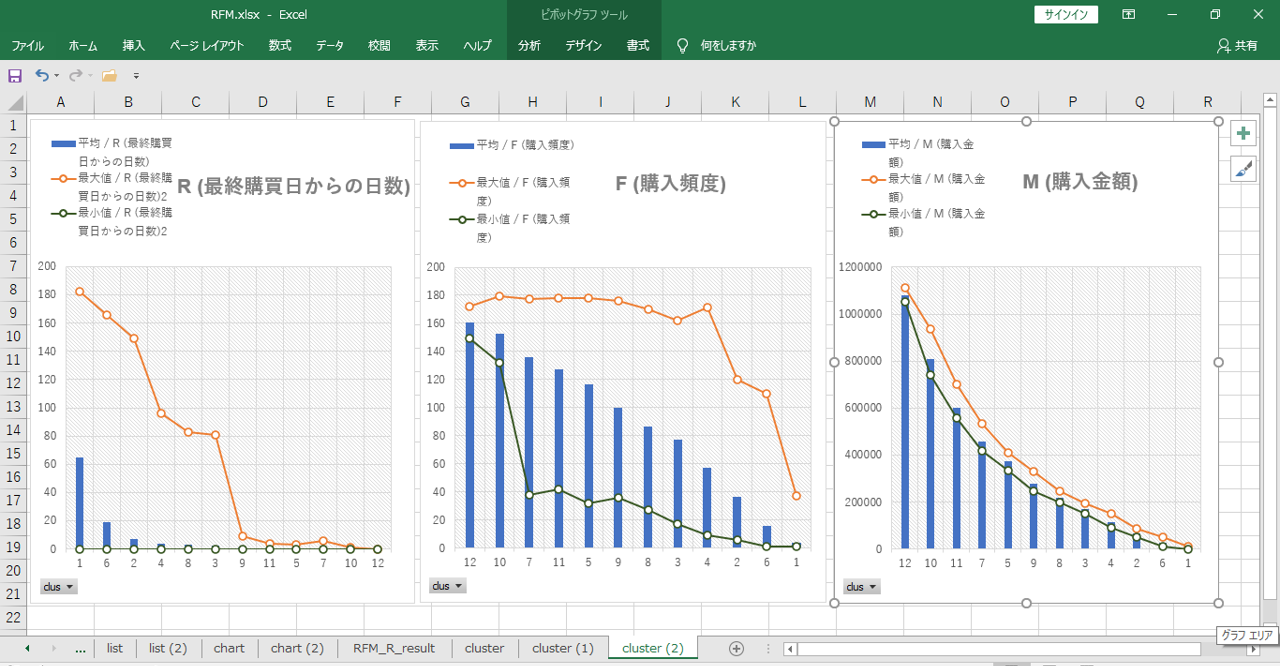
内容はM (購入金額) の大小によってクラスタリングされます。ほぼデシルです。
・スコア表の基準値
・スコアの段階数
・データの期間
・クラスター数
これらの調整でも希望が見えてきません。ちなみに、クラスター数60で試しましたが、残念な結果でした。