
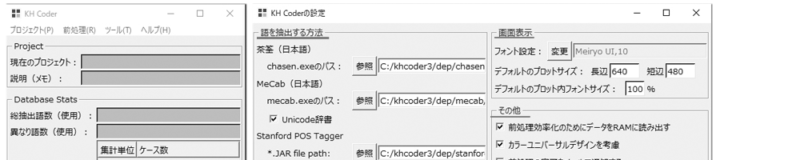
KHcoder 2. 新規プロジェクト
KHcoderの各種機能を確認し、分析対象テキストを読み込みます。
テキストマイニングツール「KHcoder」の活用メモ
開発者である樋口先生に感謝!
【今回の分析対象テキストはこちらからコピーできます】
読込前に
機能確認
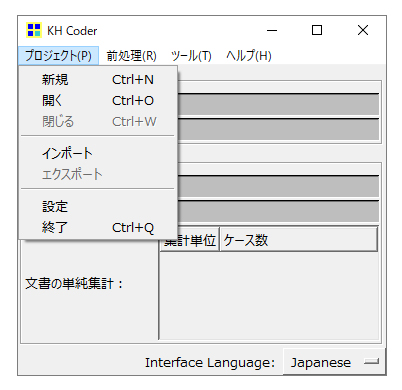
「新規」
分析対象テキストを読み込んで新規プロジェクトを作成します。
「開く」
既存プロジェクトを開きます。既存プロジェクトを開くときに自動保存された「sushi_txt0.txt」と「sushi_var0.txt」がロードされます。
「KHcoder」にはプロジェクトの上書き保存という概念がありません。
各種分析結果、チャートも別途出力して保存しないと残りません。ただ、エクセル出力(抽出語リストなど)、CSV出力(対応分析出力など)を行った場合はひそやかに結果ファイルが自動で保存されています。
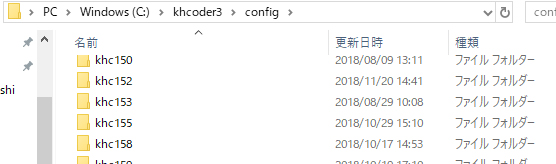
「C:\khcoder3\config」ここにプロジェクトごとにフォルダーができて自動保存されます。
「インポート」「エクスポート」
現在の分析を別のパソコンで行いたい場合に、現在のプロジェクトを「エクスポート」、別のパソコンへ「インポート」して再現できます。
エクスポートできるのは、現在のプロジェクト、現在の状態です。
「設定」
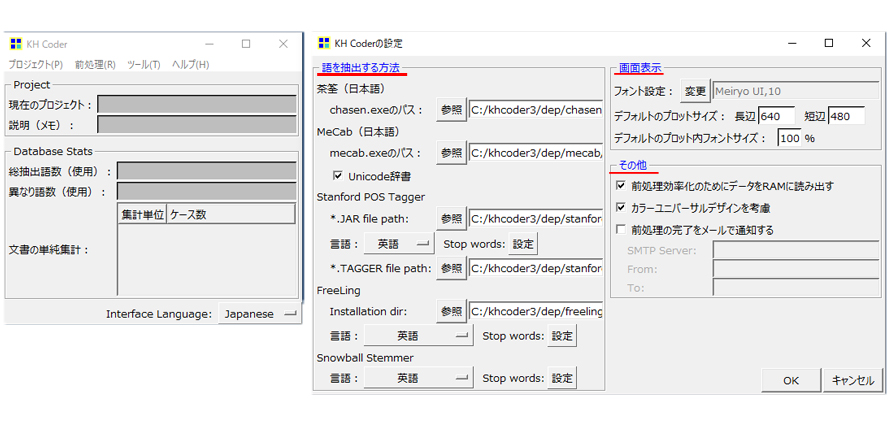
「語を抽出する方法」
分析対象テキストの言語と辞書の設定です。テキストが日本語の場合、変更する必要はありません。
「画面表示」
画面に関する設定です。デフォルトのままが一番使いやすいので変更する必要はありません。
「その他」
デフォルトのままが一番使いやすいので変更する必要はありません。
言語を選択
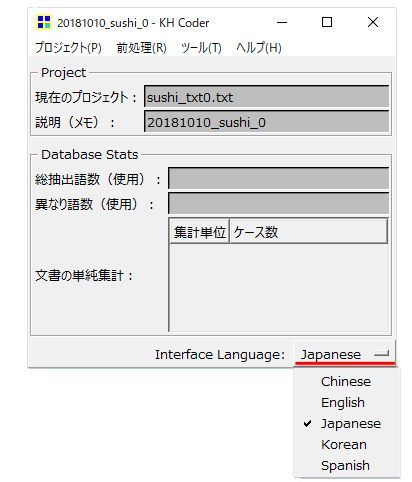
デフォルトで「Japanese」が設定されています。日本語以外の場合は変更してください。
分析対象テキストファイル読込
テキストファイル読込

分析対象ファイル:「参照」
・参照をクリックして
・分析対象ファイルを選択します。
ファイル形式は聞いてこないので、ファイルをダブルクリックします。
分析対象とする列
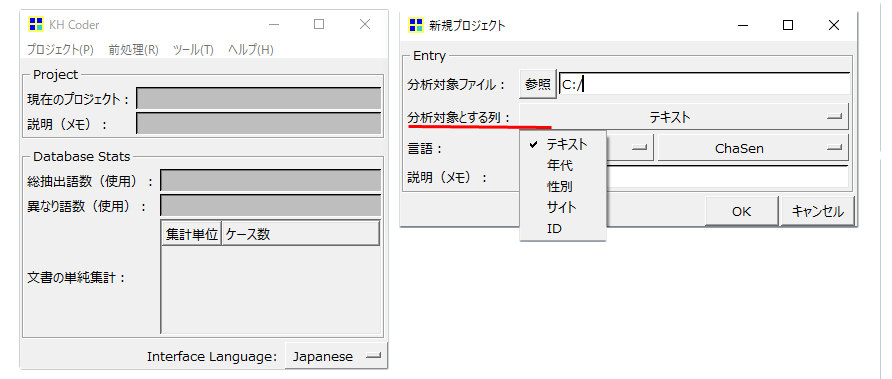
エクセル、CSV形式の場合、デフォルトの状態でファイルのいちばん左列が表示されます。
ファイルを作成する際に、いちばん左(A列)へ分析対象テキストを配置するのはこのためです。
言語を選択
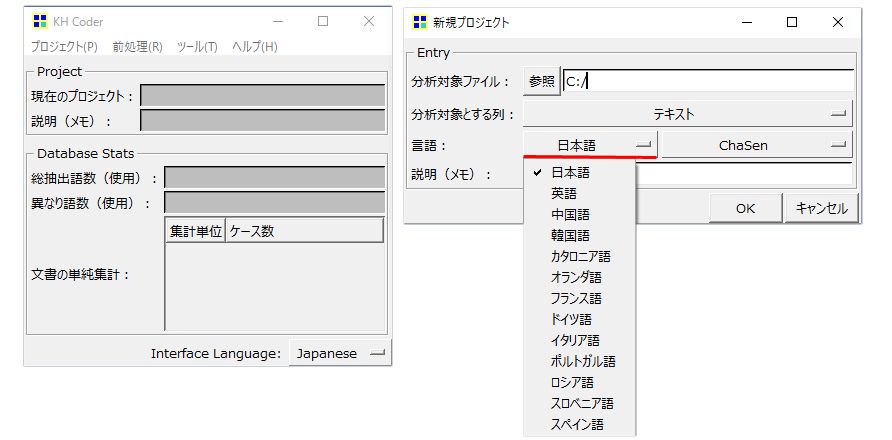
ここでも言語を選択できます。しかも、最初の選択肢よりも多い・・・
辞書を選択
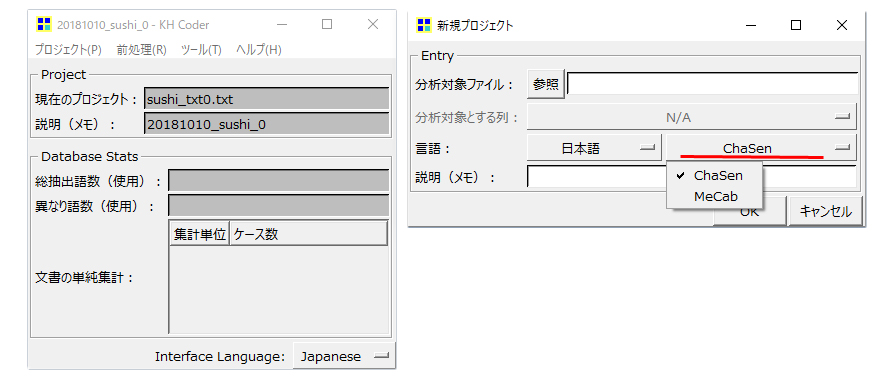
辞書とは
「文」を構成する「語」をどのように取り出すのかを規定しています。
<例えば>
「新聞紙を破る」
「新聞」「紙」「破る」と3語に取り出す
「新聞紙」「破る」と2語に取り出す
辞書によって「語」の取り出し方が少し違います。
・「ChaSen」「MeCab」のどちらかを選択します。
個人的にはデフォルトで設定されている「ChaSen」を使用しています。
・辞書を書き換えると別のパソコンでの再現性が失われます。
辞書の書き換えにはチャレンジしないほうがよいと思います。「強制抽出語」「コーディング」「表記揺れの吸収」などの機能でほぼ対応できます。
説明(メモ)
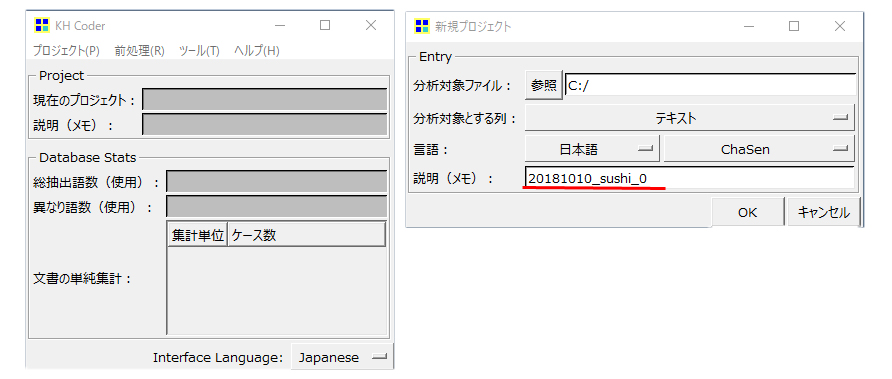
日付や番号で管理することをオススメします。
前述しましたが、分析対象テキストの修正再読み込みは頻繁にあります。だんだん訳が分からなくなりますので分かりやすく管理します。
【今回の分析対象テキストはこちらからコピーできます】