
KHcoder 10. 記述統計
抽出語の記述統計機能について、解説しています。TFとDFの違いは、「語」の出現回数と、「語」が出現する段数の違いです。
テキストマイニングツール「KHcoder」の活用メモ
開発者である樋口先生に感謝!
【今回の分析対象テキストはこちらからコピーできます】
記述統計
出現回数(TF)の分布

・「ツール」→「抽出語」→「記述統計」→「出現回数(TF)の分布」
*TFは「分析対象テキスト」のなかで「語」が出現する頻度(回数)
*DFは「分析対象テキスト」のなかで、ある「語」が含まれている「H5」数、「段」数、「文」数を示します。
出現回数(TF)の分布は、「語」が出現する回数をカウントした結果を表示するものです。出力結果の下の部分「■度数分布表」から説明します。
・「出現回数」と「度数」の列
「分析対象テキスト」のなかで、1回出現する「語」が25種類ある、2回出現する「語」が3種類ある、このように読みます。表の縦軸 (行) は計算メジャーです。
8回出現する「語」が1種類あります。それが「まぐろ」です。単純にいえば抽出語リストを「出現回数」と「語数」でクロス集計した表です。
・「パーセント」=「度数」÷「異なり語数」
1行目の67.57は「25÷37」の解です。「累積度数」「累計パーセント」はヒストグラムでおなじみの累計と同じです。
・上の部分「■記述統計」はサマリーです。
「異なり語数(n)」が37語あるということです。
・「出現回数の平均」
下の表の出現回数×度数、つまり(1×25+2×3+3×4+4×2+5×2+8×1)÷37(異なり語数)で算出されます。
加重平均しているということは、1「文」の平均「語」数ではなく(それならば計算式は37「語」÷20「文」になる)、1「語」が1「文」に出現する平均回数ということになります。
・「出現回数の標準偏差」
下の表の標準偏差です。1「語」が1「文」に出現する標準偏差です。
出現回数(TF)の分布のプロット
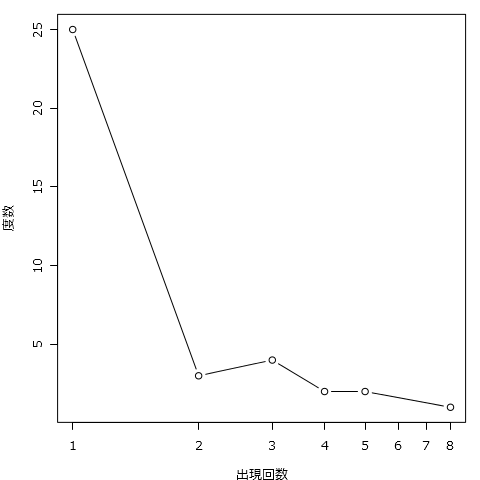
・「プロット」をクリックすると折線グラフが出現します。
これはエルボー曲線によく似ています。エルボー曲線はおもにクラスター分析のときにクラスター数設定の目安につかいます。他に似たものでABC分析結果もこのような折れ線グラフになります。
ただ、クラスター分析でもABC分析でも重要なのはグラフの左側で、このグラフの左側は出現回数が少ない「語」だからどちらかという分析では右側が重要であるように思います。
そうすると、グラフが大きく折れ曲がる出現回数2回以上の「語」を分析せよ!というふうに読めばよいのだろうと思います。
出現回数(TF)の分布のプロットの構造
| 分析対象テキスト1 | 分析対象テキスト2 | |||
| 文A | まぐろ、サーモン、ハマチ | 文C | まぐろ、サーモン、ハマチ | |
| 文B | まぐろ、サーモン、イクラ | 文D | まぐろ、いか、さば |
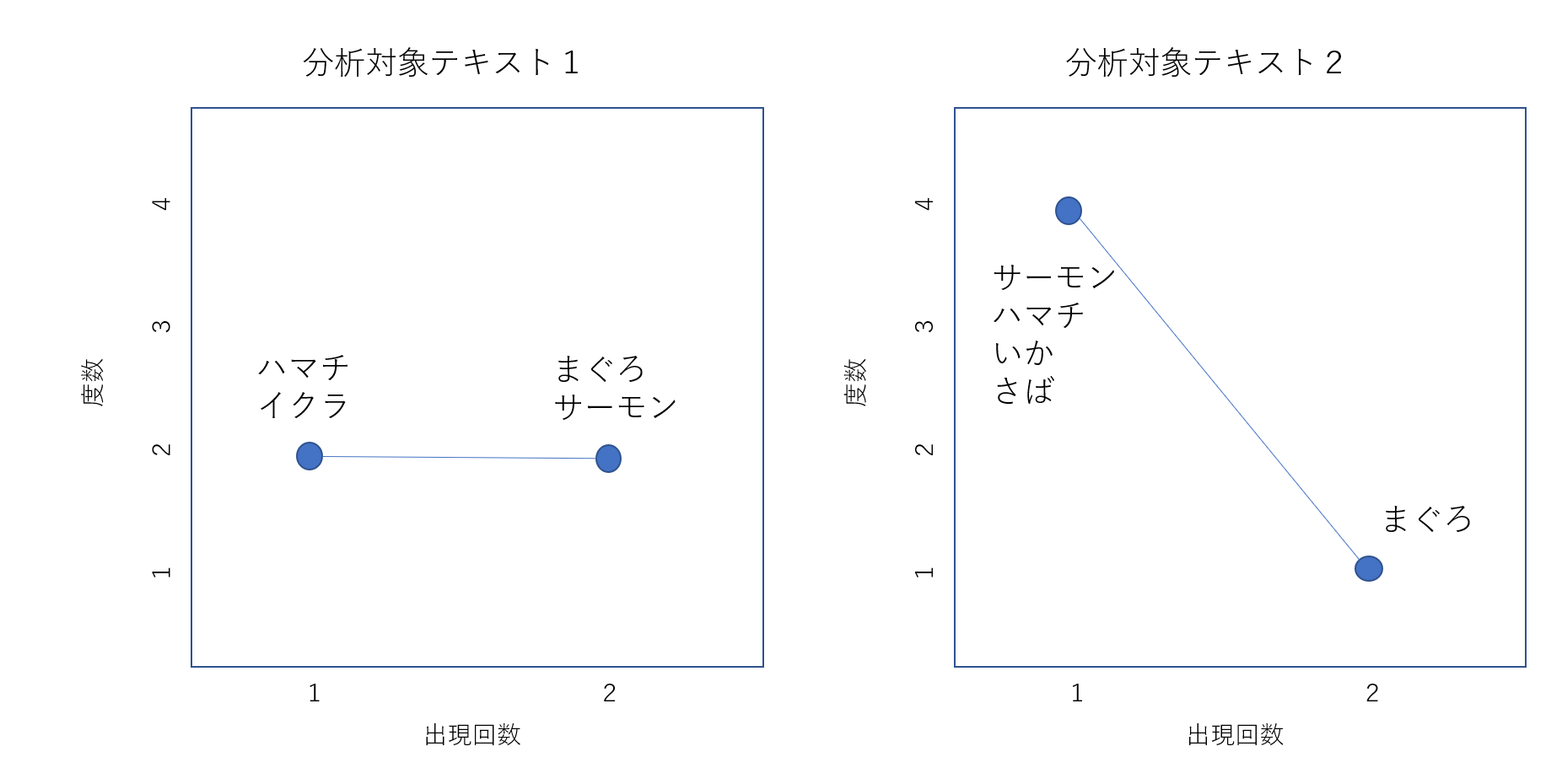
出現回数(TF)の分布のプロット(折線ぐラグ)の構造がどのようになっているのか例で説明します。
・「分析対象テキスト1」は文Aと文Bで構成されています。
「分析対象テキスト1」の場合、1回出現する「語」は2種類(ハマチ・イクラ)、2回出現するる「語」は2種類(まぐろ・サーモン)ですから、折れ線グラフはX軸と平行になります。出現回数の平均は(1回×2語+2回×2語)÷4語=1.5です。
・「分析対象テキスト2」は文Cと文Dで構成されています。
この場合、1回出現する「語」は4(サーモン・ハマチ・いか・さば)、2回出現するる「語」は1語(まぐろ)ですから、折れ線グラフは右肩下がりなります。出現回数の平均は(1回×4語+2回×1語)÷5語=1.25です。
「分析対象テキスト1」の文Aと文Bの差異と、「分析対象テキスト2」の文Cと文Dの差異を考えたとき、文Aと文Bは「まぐろ」「サーモン」の2「語」が共通であらわれ、3語めが「ハマチ」か「イクラ」かの違いです。文Aと文Bは似ているといえます。
・文Cと文Dに共通するのは「まぐろ」だけです。
「分析対象テキスト1」の文Aと文Bの差異よりも「分析対象テキスト2」の文Cと文Dの差異のほうが大きいことに気付きます。
つまり、折線グラフの左肩が下がるということは
・「分析対象テキスト」を構成する文と文との差異が大きいほど右肩が下がる。
・文と文が似ていると右肩の下がり方がゆるやかになる。
このように考えることができそうです。出現回数の平均値が小さいと同様に文と文の差異が大きく、平均値が大きいと文と文が似ているといえます。
従って、出現回数(TF)の分布のプロット(折線ぐラグ)は線の傾き具合を見るものであろうと思います。
それぞれの文に共通して出現する「語」数が多いほど傾きが緩やかになります。
出現回数(TF)の分布のプロットの下のボタン

プロットの下に「出現回数(X)」ボタンがあります。
デフォルトで「出現回数(X)」、図の左側、出現回数(X軸)のスケールがデフォルメされています。「
出現回数(X)と度数(Y)」をクリックすると度数(Y軸)がデフォルメされ、プロットを結ぶ線が消えます。
「なし」をクリックするとX軸、Y軸ともにスケールのデフォルメが解消されます。
その他の記述統計機能
出現文書数(DF)の分布
今度は、DFです。カウントするのは「H5」「段」「文」のどれかの数です。
・画像での設定は「段」です。
表の見方は上から
・26種類の「語」は、どこかの1「段」に出現する
・3種類の「語」は、どこかの2「段」に出現する
このように読みます。「段落」のボタンでその他の「H5]「文」を選択することができます。
プロットをクリックするとTFと同様のプロット折線グラフが開きます。プロットの操作はTFと同じです。
出現回数×文書数のプロット
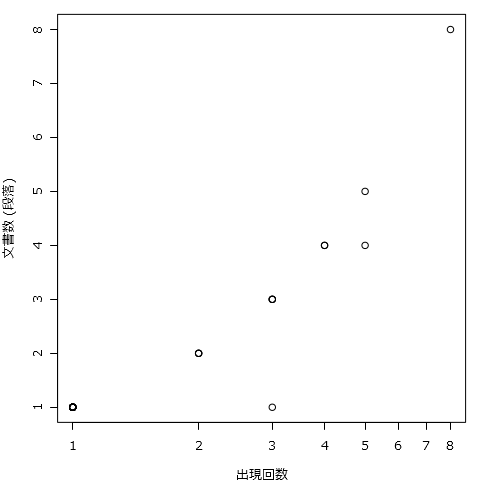
・横軸(X軸)が「語」の出現回数
・縦軸(Y軸)が文書(H5、段、文)数をプロットしています
「段落」のボタンと「出現回数(X)」ボタンの使い方はTFのときと同じです。
記述統計とは、テキストマイニングの基本になる「語」が出現する回数(TFの分布)、「語」が出現する場所の数(DFの分布)を統計記述したものです。
TFの分布もDFの分布も単独でみるとき数値自体にそれほどの注意をはらう必要はありません。
【今回の分析対象テキストはこちらからコピーできます】