
KHcoder 15. 対応分析(第2回)
KHcoder対応分析の計算ロジックを解説しています。.csv出力したデータ表をタブローで分析することもできます。
テキストマイニングツール「KHcoder」の活用メモ
開発者である樋口先生に感謝!
【今回の分析対象テキストはこちらからコピーできます】
対応分析計算
分析結果から計算過程を確認する

・「語」を青い丸、「外部変数」を赤い四角でプロットしたものが対応分析結果です。
・プロットのサイズは「語」が出現する回数に比例します。
では、プロットする位置をどのように計算しているのでしょうか。対応分析は「語」が出現する場所と、それぞれの場所で「語」が出現する回数を計算して座標を決定します。
対応分析の場合、「語」が出現する場所というのが「外部変数」(年代)です。
座標とサイズ
KHcoderには対応分析結果を保存する機能があります。
・画像のように「保存」をクリックするとウインドウが開きます。
・ファイル形式のCSVを選択して名前をつけて保存します。
| type | frequency | size | X1 | X2 | |
| サーモン | col | 4 | 48.34253 | -1.40036 | 1.347641 |
| サバ | col | 4 | 48.34253 | 1.60736 | 1.016691 |
| イカ | col | 3 | 41.18967 | 0.269291 | 0.683758 |
| 好き | col | 5 | 54.64433 | 0.799822 | -0.91115 |
| 苦手 | col | 3 | 41.18967 | 0.269291 | 0.683758 |
| まぐろ | col | 8 | 70.45727 | 0.100565 | 0.102116 |
| イクラ | col | 5 | 54.64433 | -1.60635 | -0.64639 |
| 海老 | col | 3 | 41.18967 | 0.261464 | -2.19637 |
| 10代 | row | 39 | 39.06397 | -1.22473 | 0.005505 |
| 40代 | row | 52 | 52.25827 | 0.811937 | -1.0164 |
| 60代 | row | 59 | 58.67776 | 0.823885 | 1.642015 |
保存したCSVの内容です。
・いちばん左の列に「語」と「外部変数」があります。
・「type」は[col」と「row」があります。
・「col」はcolumn(列)の略です。「col」が「語」です、青い丸で描画します。
・「row」が「外部変数」、赤い四角で描画します。
・「frequency」は「語」が出現する回数です。
・「語」の出現回数に比例して「size」が決まります。
「サーモン」4回の「size」が48.34253にたいして「まぐろ」は8回出現しているのに70.45727です。「サーモン」の2倍にはなりませんが、気にすることはありません。
全体がうまくキャンバスサイズに入ること、「語」が重なり見えにくくなることを回避するための措置です。
・「X1」が横軸(X軸)の座標です。
・「X2」がY軸(縦軸)の座標です。
Rで計算
Rへ渡すデータ

KHcoderからRへ渡しているデータを確認します。
・「保存」→「R Source」を選択します。
・ディレクトリを指定してファイルを保存します。
・「khcoder3」→「Rgui.bat」をクリックします。
「Rgui.bat」は32-bit版のR
「Rgui64.bat」は64-bit版のRです。
いずれも【R version 3.1.0】です。私が別途インストールしているR【R version 3.4.4】ではうまくことが運ばないことがあります。
・「Rgui.bat」(32-bit版)を起動することをオススメします。
・名前を付けて保存した「R Source」をテキストエディタで開きます。
・「R Source」の先頭から51行目あたりまでをコピーしてRへ貼り付けます。
ここまでがRへ渡しているデータです。
Rへ渡されたデータ
>d サーモン サバ イカ 好き 苦手 まぐろ イクラ 海老 [1,] 1 0 0 1 0 1 1 0 [2,] 1 0 1 0 1 1 1 0 [3,] 0 0 0 0 0 1 1 1 [4,] 1 0 0 0 0 0 1 0 [5,] 0 1 0 1 0 1 1 0 [6,] 0 0 0 1 0 1 0 1 [7,] 0 1 1 1 1 0 0 1 [8,] 0 0 0 0 0 1 0 0 [9,] 0 0 0 0 0 1 0 0 [10,] 0 0 1 1 0 1 0 0 [11,] 0 1 0 0 0 0 0 0 [12,] 1 1 0 0 1 0 0 0
・Rへ「d」を入力してエンターを押します。
行(row)が12行×列(column)が「語」のクロス集計表があらわれます。
これがRへ渡している
・「語」が「段」へ出現する回数のデータです・
Rの計算
・「R Source」の52行目あたりから130行目あたりまでをコピーしてRへ貼り付けます。
・「d」と入力してエンターを押します。
>d サーモン サバ イカ 好き 苦手 まぐろ イクラ 海老 10代 3 0 1 1 1 3 4 1 40代 0 2 1 3 1 3 1 2 60代 1 2 1 1 1 2 0 0
「d」が
・「外部変数」が行
・「語」が列
マトリクス形式へ変更されています。
値は「語」が出現する回数です。「語」が出現する「段数」や「文数」ではありません。
座標計算
・関数「corresp」を使用して計算します。
131行目の「corresp」が座標を計算する関数です。
c <- corresp(d, nf=d_max )
・Rへ131行目の関数をRへ貼り付けて結果を表示します。
c <- corresp(d, nf=d_max ) エンター
・「c」 エンター
計算結果を表示します。
c<- corresp(d, nf=d_max ) >c First canonical correlation(s): 0.5088535 0.3076726 Row scores: [,1] [,2] 10代 -1.2247325 0.005504619 40代 0.8119366 -1.016398884 60代 0.8238849 1.642015104 Column scores: [,1] [,2] サーモン -1.4003601 1.3476411 サバ 1.6073600 1.0166915 イカ 0.2692910 0.6837580 好き 0.7998224 -0.9111483 苦手 0.2692910 0.6837580 まぐろ 0.1005648 0.1021164 イクラ -1.6063537 -0.6463887 海老 0.2614640 -2.1963749
CSVで出力した座標と一致しているはずです。
語数を変更
語数を変更すると結果がかわる
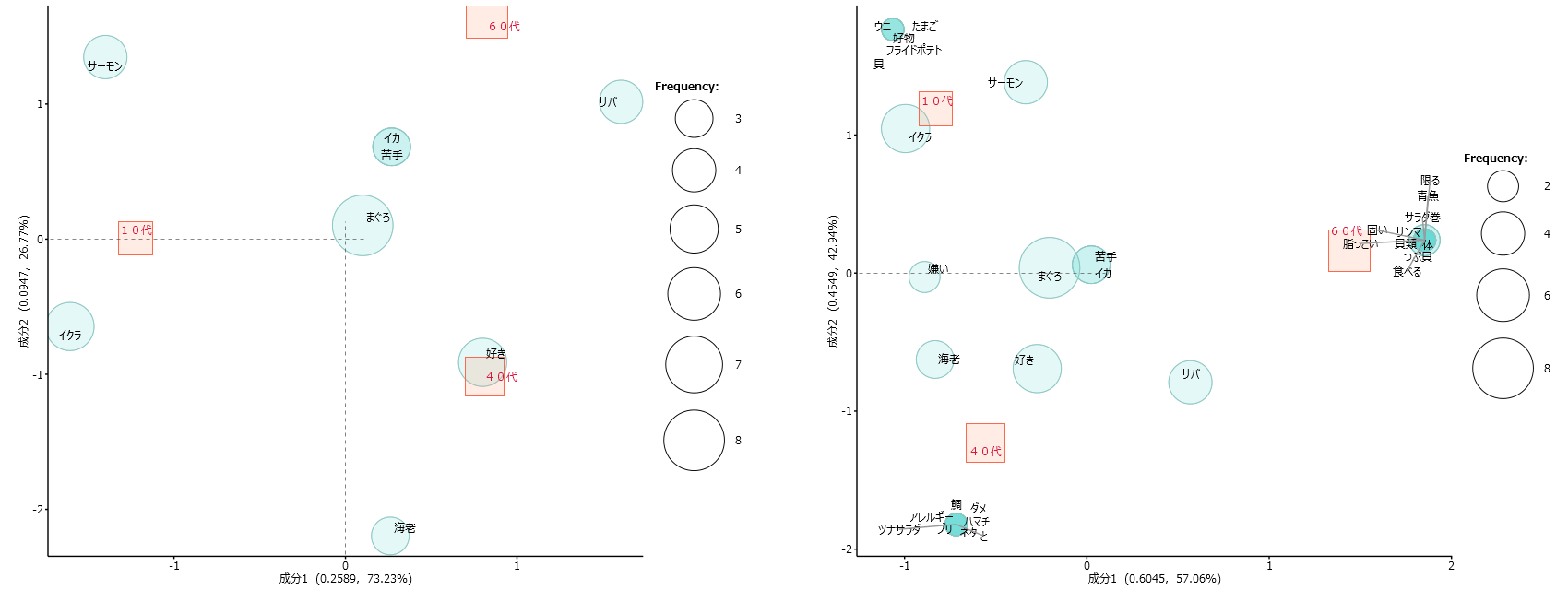
・左図は「語」の出現回数3回以上
・右図は「語」の出現回数1回以上の分析結果です。
KHcoderからRへ渡すデータが違えば分析結果が異なります。
それにしても左図と右図では赤い四角の位置がずいぶん違うし、「海老」「サーモン」のような語がプロットされる位置が大きくことなります。
分析対象テキストを確認してみましょう。
| テキスト | 年代 | 性別 | サイト | ID |
| イクラ、えび、まぐろ。貝は嫌い。 | 10代 | 男 | A | 3 |
| 鯛とまぐろが好き。エビはアレルギーがあるからダメ。 | 40代 | 女 | A | 6 |
| イカとかエビのようなあっさりしたネタが好き。サバが苦手。 | 40代 | 男 | B | 7 |
・「海老」は10代で1回、40代で2回出現しています。
「海老」は、
・10代の赤い四角と40代の赤い四角を結んだ線上
・40代方向へプロットしてもらいたいのですが、
・左図ではかなり下へプロットされます。
違いをより明確に表現しているとはいえ、デフォルメしすぎ感を否めません。「海老」「サーモン」「サバ」などの位置は右図のほうがいい感じがします。
出力した.csvへタブローで接続する
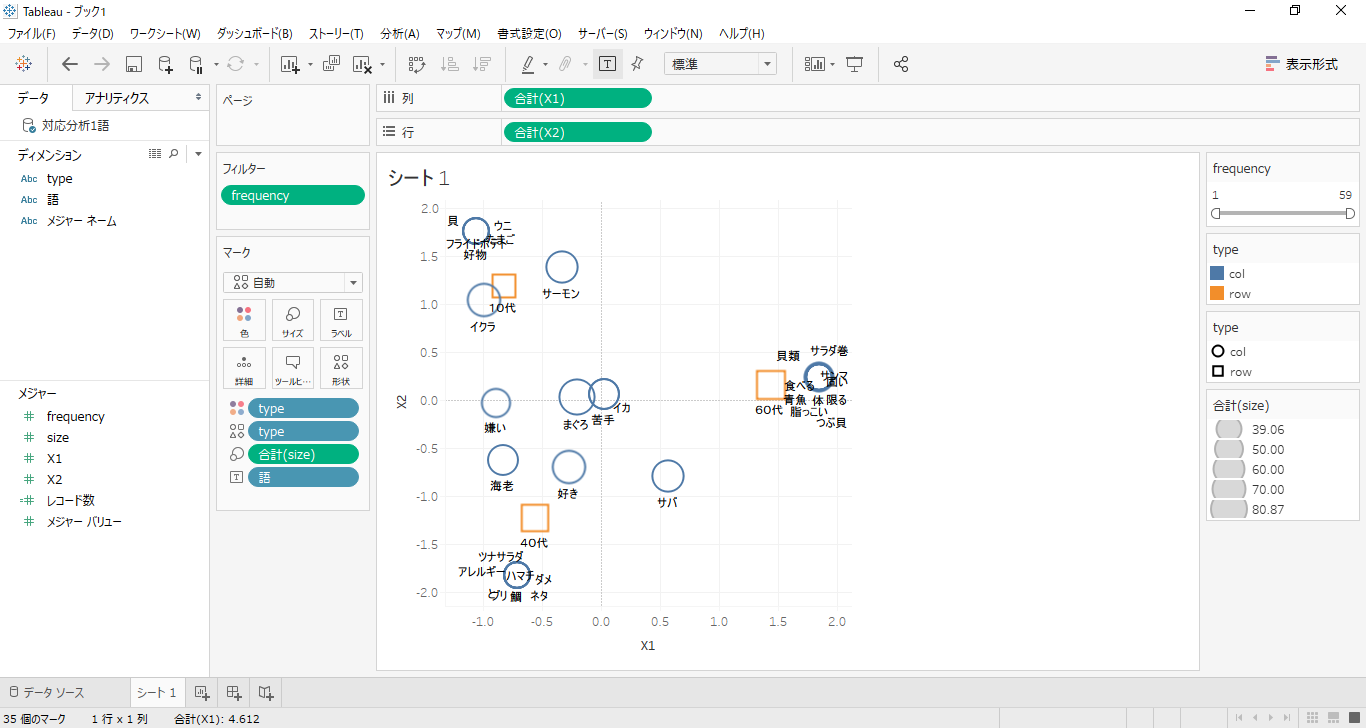
対応分析結果をCSVで出力することができます。出力したCSVをタブローで接続します。(エクセルよか他のBIツールでもOK)
タブローの手順は、
・左の列名が抜けているので「語」にしました。
・列シェルフへX1
・行シェルフへX2を入れます。
・「色」と「形状」が「type」、サイズが「size」
・「ラベル」が「語」です。
KHcoderと同じような描画が完成しました。
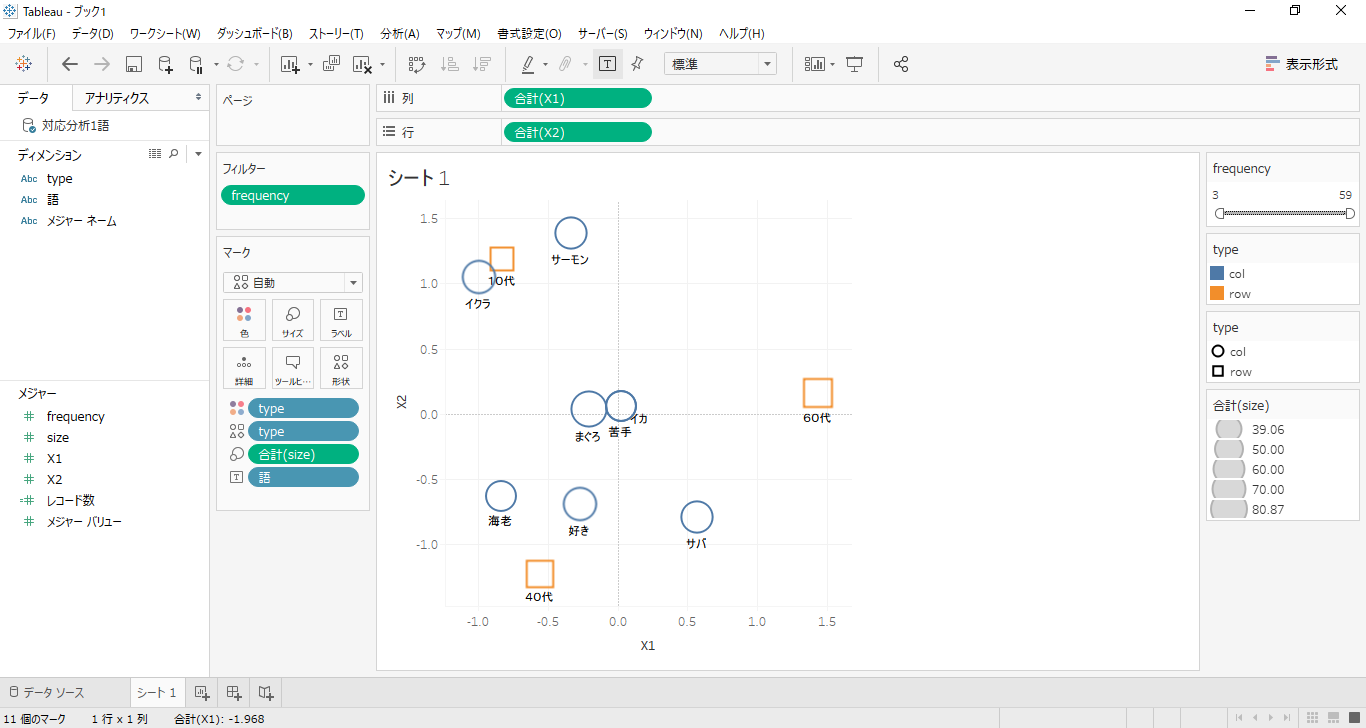
・「Frerency」をフィルターに設定して「3」以上に設定します。
データは1「語」以上のCSVだから、「語」数を変更しても座標が変化することはありません。何となくいい感じです。
Rのグラフィック機能をまったく使いこなすことができない私でも、慣れたツールなら色を変えるとかフォントサイズを変えるようなことが簡単にできるメリットもあります。