
KHcoder21. 共起ネットワーク(第2回) Rの計算
外部変数の共起ネットワーク、R内の計算・描画ロジックについて解説しています。
テキストマイニングツール「KHcoder」の活用メモ
開発者である樋口先生に感謝!
【今回の分析対象テキストはこちらからコピーできます】
外部変数の共起ネットワーク
操作方法
・「ツール」→「抽出語」→「共起ネットワーク」の順でクリックします。
・共起ネットワークの設定画面が開きます。
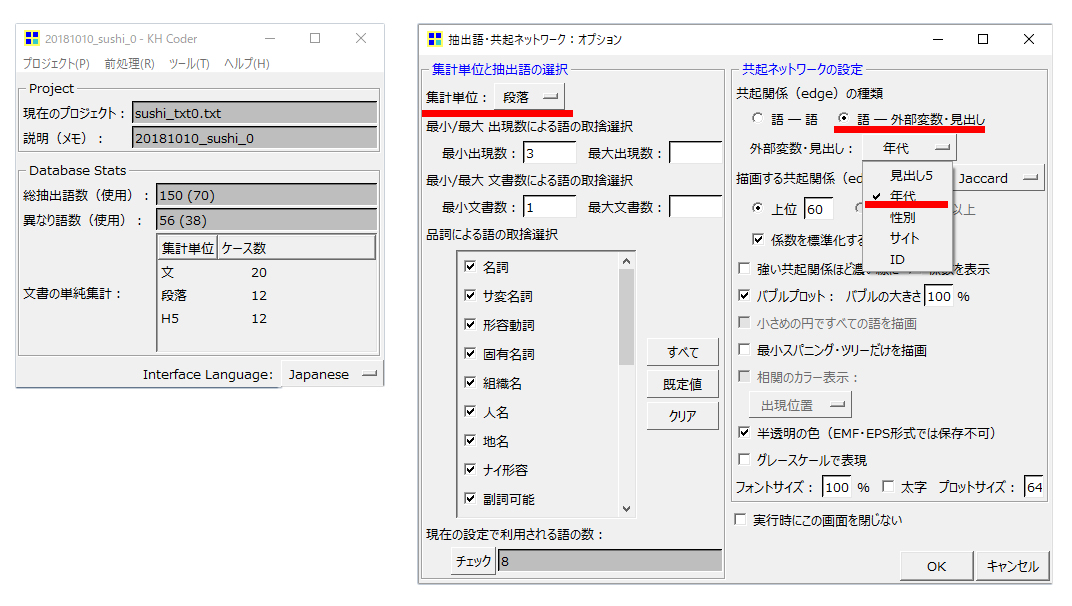
左側の
・「集計単位」を「段落」
・「最小出現数」を3に設定します。
右側
・「共起関係(edge)の種類の「語-外部変数・見出し」のラジオボタンを選択します。
・すると「外部変数・見出し:」の 四角い部分が濃い文字にかわります。デフォルトでは「見出し5」になっていると思います。
・「見出し5」の部分をクリックするとドロップダウンで「分析対象テキスト」に含まれている「外部変数」の一覧があらわれます。今回は「年代」で分析をおこないます。
・「年代」を選択して
・「係数を表示する」をクリック、「OK」をクリックすると分析結果が開きます。
「段」と「文」
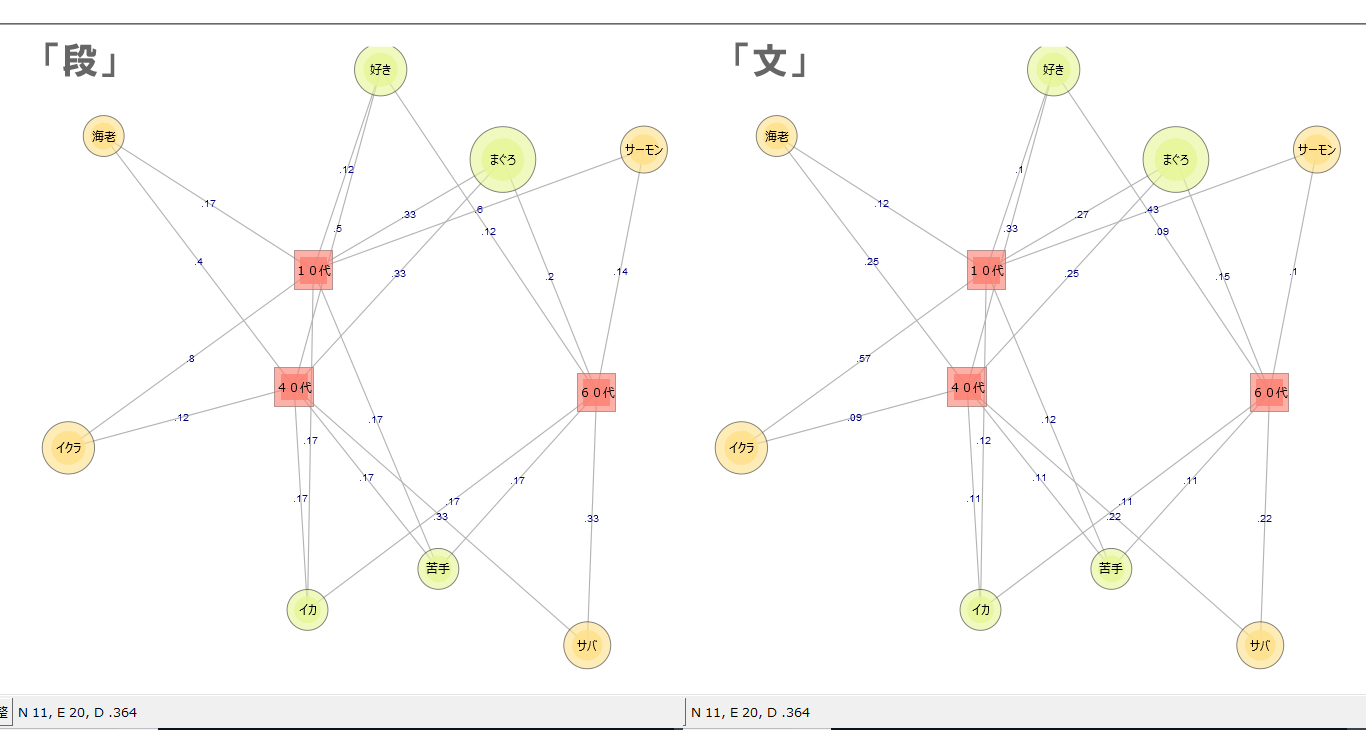
画像の左側が「段」、右側が「文」です。
今回の「分析対象テキスト」では「段」の分析も「文」の分析も同じ共起ネットワーク図になりました。ただし表示されている「係数」に違いがあります。
「係数」はJaccard係数です。Jaccard係数は、
・「段」で分析すると「語」が含まれる「段」数
・「文」で分析すると「語」が含まれる「文」数が計算の単位になります。
「段」数イコール「文」数の場合、Jaccard係数は一致します。「段」に含まれる「文」数が多いほどJaccard係数は低くなります。
「段」と「文」のどちらがよいのか?この選択は「分析対象テキスト」の内容によります。とにかく「段」と「文」の両方を試してみることをオススメします。
では、Jaccard係数はどちらが正しいのか?というと、どちらも正確です。これはどちらの係数を採用するかという課題よりも、Jacaard係数は共起の関係が強いか弱いかを示すだけのものなのだと理解すればよいと思います。
「語」数を増やす
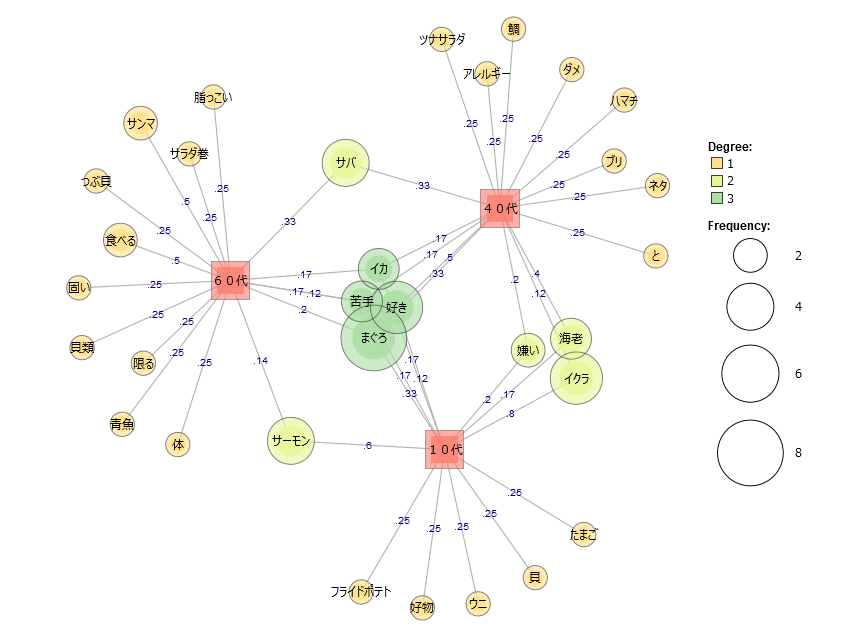
・「集計単位」を「段落」
・「最小出現数」を1に設定しました。
共起ネットワークは「語」数を調整するといい感じの見え方になります。
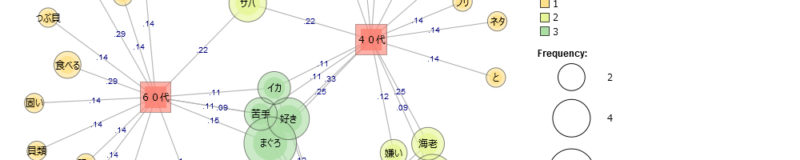
・10代・40代・60代に囲まれた中心部分にプロットされている「語」はそれぞれの年代に出現する(共起している)「語」です。
・一方で年代を示す赤い四角の外側にプロットされている「語」はそれそれの年代に特徴的に出現する「語」に分類されます。
「対応分析」でおこなった「抽出語×外部変数」の分析と同じようなことが可能になります。「対応分析」結果と比較すると、「共起ネットワーク」のほうが、共起の関係が線で示されて数値化されているので見やすいように思います。
共起ネットワークの計算方法
Rで確認
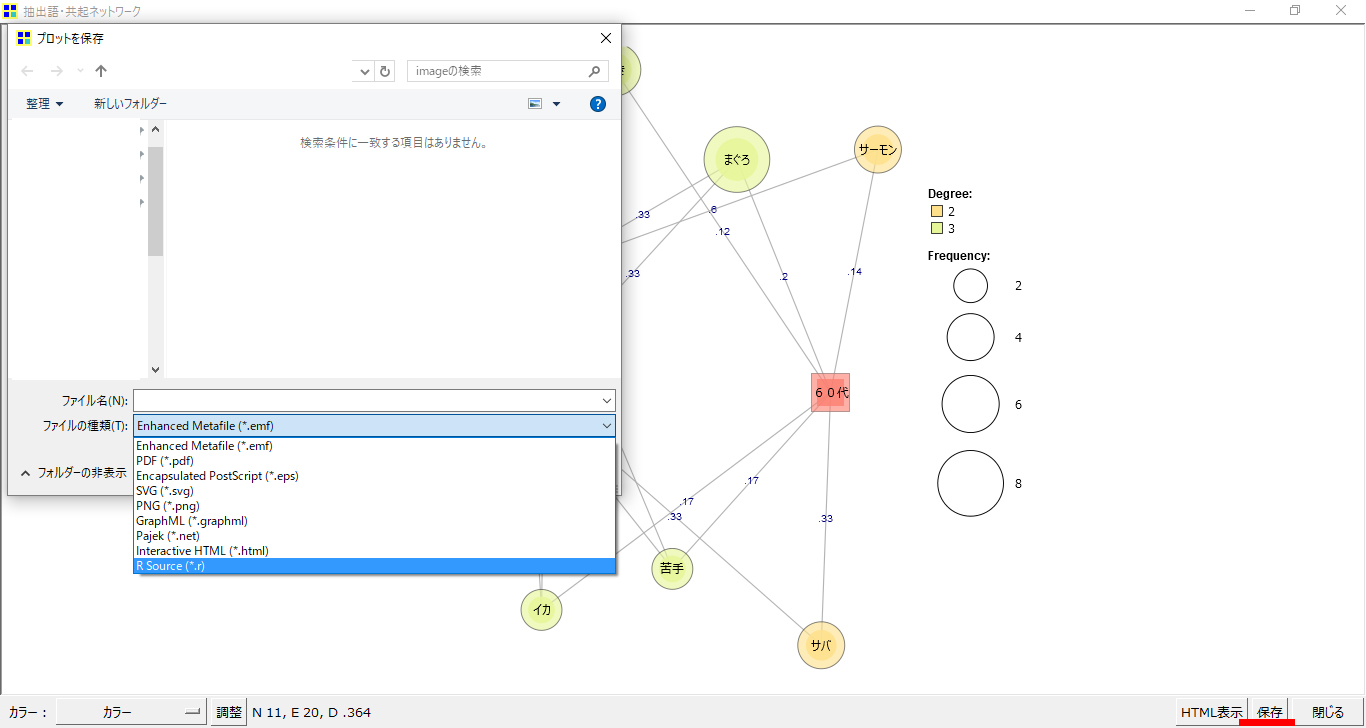
説明を簡単にするために
・「集計単位」を「段落」
・「最小出現数」を3に設定しました。
・共起ネットワーク図の右下「保存」をクリックします。ファイル格納用の窓が開きます。
・ファイルの種類から「R Souce」を選択して名前を付けて保存します。
Rを起動して、保存した「R Souce」ファイルを空白部分にドラッグ&ドロップします。
以下にエラー f(...) : 関数 "brewer.pal" を見つけることができませんでした
このようなエラーメッセージが表示される場合は関数 “brewer.pal”を使用できるパッケージを開く必要があります。
#RColorBrewerを開きます library(RColorBrewer) #描画します p
このようにRへコマンドを入力します。
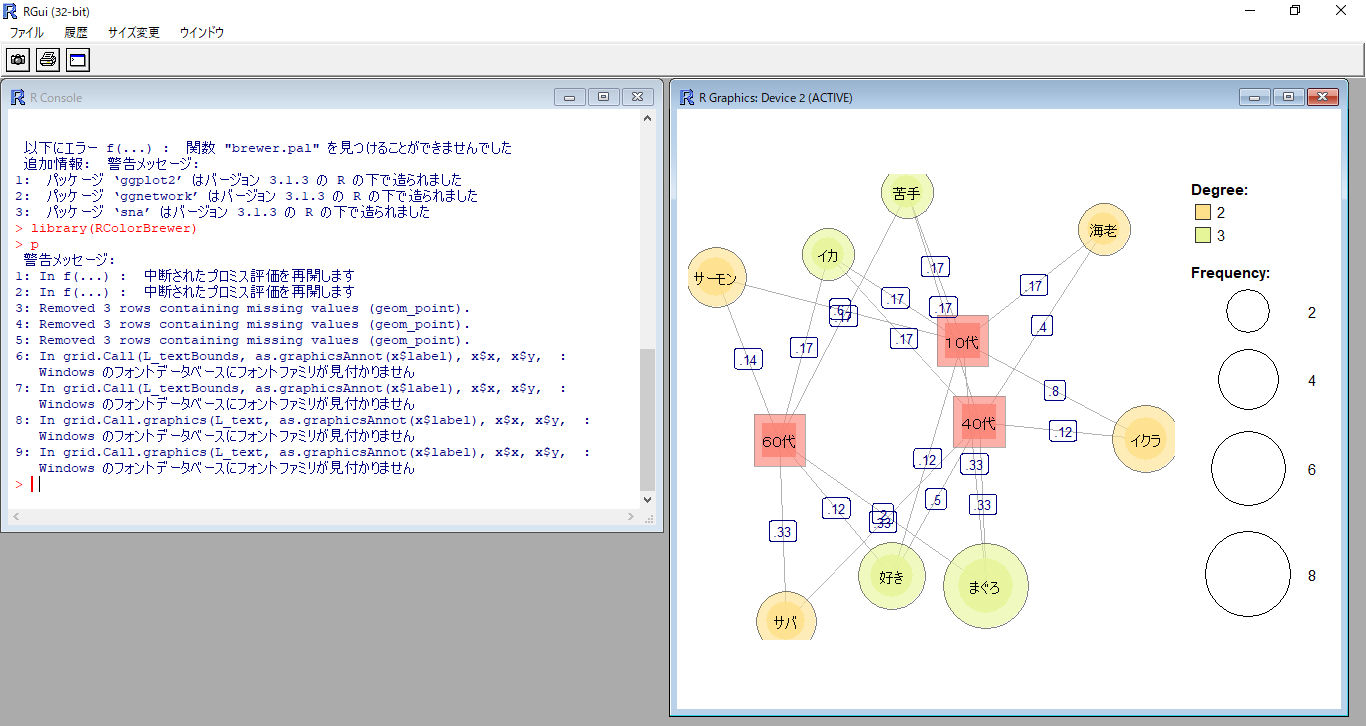
グラフィックデバイスが開いて結果が表示されます。
KHcoderの結果とRの結果に違いがあります。
・ノードをプロットする座標の上下左右が逆になります。
この現象はRのバージョンによって起こるようです。3種類のRバージョンで試してみましたが左右だけが逆になることもありました。上下左右の逆転は特段の問題はないので気にすることはありません。Jaccard係数はもちろんすべて同じになります。
描画の元になっている数値
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] サーモン 1 1 0 1 0 0 0 0 0 0 0 1 サバ 0 0 0 0 1 0 1 0 0 0 1 1 イカ 0 1 0 0 0 0 1 0 0 1 0 0 好き 1 0 0 0 1 1 1 0 0 1 0 0 苦手 0 1 0 0 0 0 1 0 0 0 0 1 まぐろ 1 1 1 0 1 1 0 1 1 1 0 0 イクラ 1 1 1 1 1 0 0 0 0 0 0 0 海老 0 0 1 0 0 1 1 0 0 0 0 0 10代 1 1 1 1 0 0 0 0 0 0 0 0 40代 0 0 0 0 1 1 1 1 0 0 0 0 60代 0 0 0 0 0 0 0 0 1 1 1 1
KHcoderからRへ送り込んでいるデータです。行が「語」と「外部変数」これらがノードなりますに。列は「段」のマトリクスデータです。
描画は2つの要素で構成されます。
① ノードをプロットする座標とプロットのサイズ
② 各ノードを繋ぐ直線とその太さ
lay_f [,1] [,2] サーモン 0.0000000 0.80227004 10代 0.5720435 0.65330938 イカ 0.2596102 0.85458268 好き 0.4090761 0.10659369 苦手 0.4442144 1.00000000 まぐろ 0.6261782 0.08181915 イクラ 1.0000000 0.42434664 海老 0.9023758 0.91361444 サバ 0.1612691 0.00000000 40代 0.6108623 0.46495769 60代 0.1460531 0.42226283
Rへ「lay_f」と入力してエンターを押します。これが「語」をプロットする [,1] =X座標、[,2]=Y座標です。
freq [1] 4 4 3 5 3 8 5 3 4 4 4
Rへ「freq」と入力してエンターを押します。プロットのサイズです。
プロットのサイズ=出現回数ですね。
el edge1 edge2 weight elbb.weight_b 1 1 9 0.6312500 0.6000000 2 3 9 0.2656250 0.1666667 3 4 9 0.2304688 0.1250000 4 5 9 0.2656250 0.1666667 5 6 9 0.4062500 0.3333333 6 7 9 0.8000000 0.8000000 7 8 9 0.2656250 0.1666667 8 2 10 0.4414063 0.3333333 9 3 10 0.3007812 0.1666667 10 4 10 0.5820312 0.5000000 11 5 10 0.3007812 0.1666667 12 6 10 0.4414063 0.3333333 13 7 10 0.2656250 0.1250000 14 8 10 0.4976563 0.4000000 15 1 11 0.3746094 0.1428571 16 2 11 0.5353237 0.3333333 17 3 11 0.3946987 0.1666667 18 4 11 0.3595424 0.1250000 19 5 11 0.3946987 0.1666667 20 6 11 0.4228237 0.2000000
直線と太さです。直線は「edge1」と「edge2」のノード間に直線をプロットします。
・1行目は 「edge1」=1=サーモン、「edge2」=9=10代、この2点間を直線で結びます。
データは20行ですから直線の数は20本です。
直線の太さは「elbb.weight_b」(表示する係数も同じ)です。
・サーモンと10代を結ぶ直線の太さは0.6、係数を0.6と表示します。
>KHcoder20. 共起ネットワーク(第1回)
>KHcoder22. 共起ネットワーク(第3回) タブローでネットワーク図