
Coding(KHcoder) 7 対応分析
コーディングの対応分析について、抽出語の対応分析との違いについて解説しています。
コーディング対応分析
対応分析ふりかえり
#もとデータ
魚卵 エビ・イカ マグロ 青魚 貝類 惣菜
[1,] 1 1 1 0 0 0
[2,] 1 1 1 0 0 1
[3,] 1 1 1 0 0 1
[4,] 1 1 0 0 0 1
[5,] 1 0 1 1 0 0
[6,] 0 1 1 1 0 0
[7,] 0 1 0 1 0 0
[8,] 0 1 1 1 0 0
[9,] 0 0 1 1 1 0
[10,] 1 1 1 0 1 0
[11,] 0 0 0 1 1 0
[12,] 0 0 0 1 1 0
#計算用データ
魚卵 エビ・イカ マグロ 青魚 貝類 惣菜
10代 4 4 3 0 0 3
40代 1 3 3 4 0 0
60代 1 1 2 3 4 0
対応分析は段(または文書またはH5)ごとに出現する「コード」数をカウントします。
カウントした値を「外部変数」ごとに集計して計算用データをつくります。
計算用データから青い丸(「コード」)と赤い四角(「外部変数」)をプロットする座標を算出します。プロットのサイズは「コード」が出現する回数です。
「コード」と「抽出語」 設定の違い

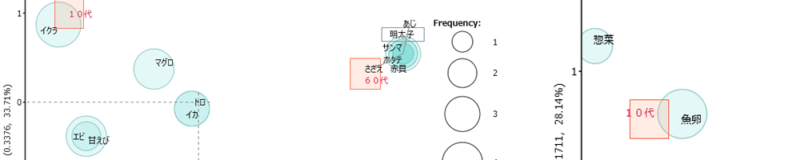
左画像が抽出語。右画像がコーディングでおこなう対応分析です。
それぞれの違いは青い丸でプロットする「抽出語」・「コード」の選択方法です。
・抽出語の場合は「語」の出現回数、段(または文書またはH5)に「語」が出現する回数、品詞のどれか、あるいはそのなかの複数組み合わせを選択できます。
・コードの場合は「コード」の選択のみ、コードは3個以上が必要です。
抽出語の場合は選択した「語」を含まない「段」は除外されます。同様に、コードの場合もコードを含まない「段」は除外されます。
もちろんコーディングされていない「語」は除外されます。
「コーディング」と「抽出語」 結果の違い
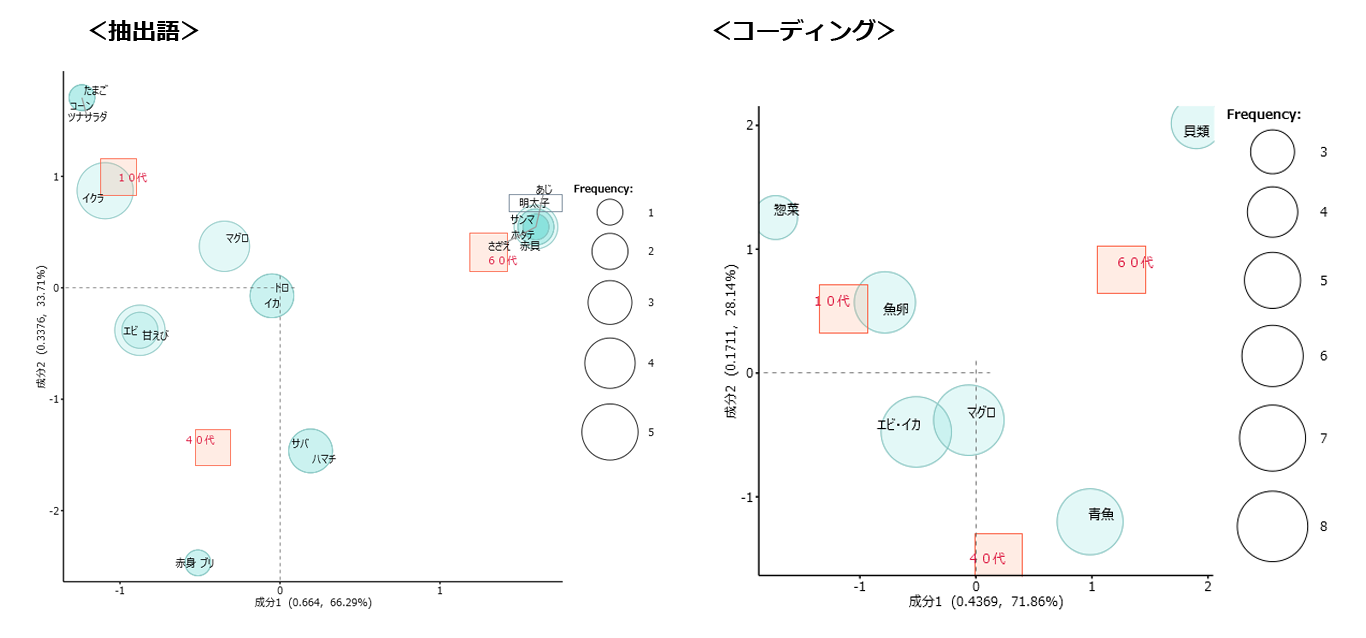
分析の粒度が「語」から「コードに切り替わります。「語」よりも見やすくなります。カテゴリーや価格帯などで年代の嗜好を見極めたいときに有用です。
「語」の書き換え
コーディングでは不可能
*いくら イクラ *さんま サンマ *海老 エビ
「スマホ」や「スマートフォン」など同意異語を「スマートフォン」に統一して対応分析したいときにコーディングで対応できるのでしょうか。
正解はほぼできません。
例題として「イクラ」→「いくら」、「サンマ」→「さんま」、「エビ」→「海老」に書き換えるコーディングファイルを作成して実験してみます。
コーディング対応分析では3以上のコードが必要なので3語を書き換えます。
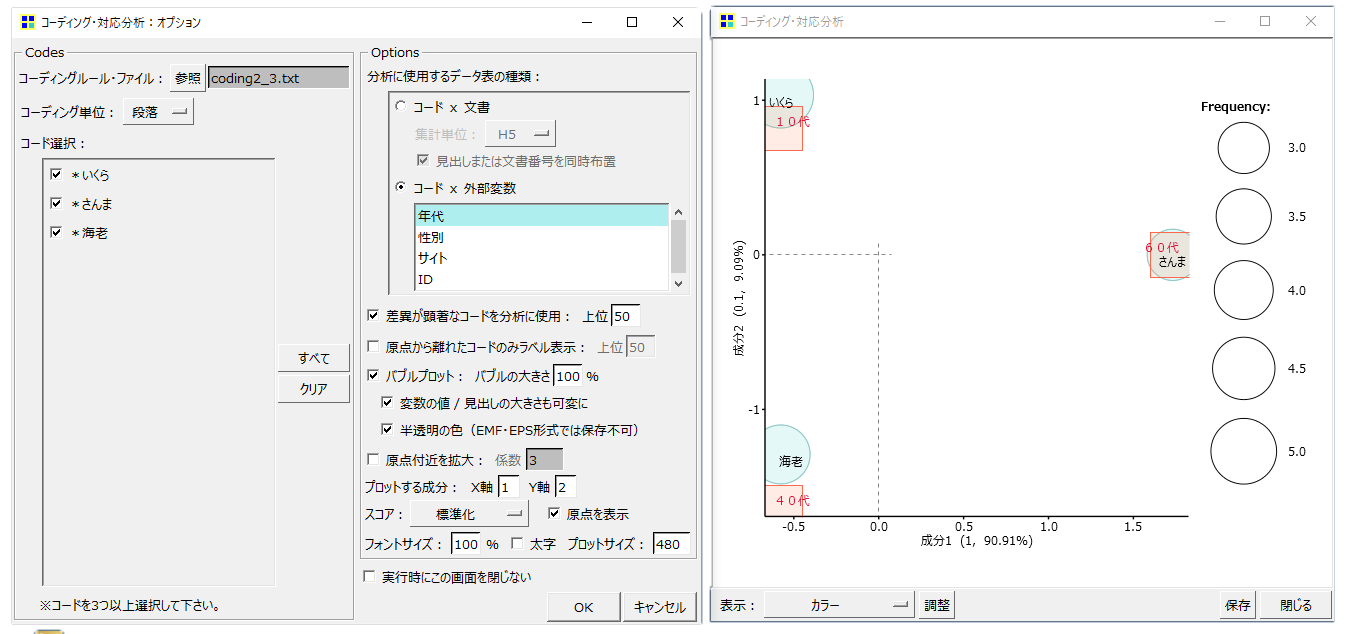
コーディング対応分析ですからコーディングファイルに記載されている「コード」だけにフィルターされます。抽出語対応分析ではないから「語」は分析対象にはなりません。
「語」をコーディングで書き換えることで、コードでありながら「語」の状態で分析しようとするときは、基本的にすべての「語」をコーディングする必要があります。
「語」のまま分析するためには「表記揺れの吸収」をつかいます。
「コード」を「語」のようにみせる
*いくら イクラ *明太子 明太子 *海老 エビ *イカ イカ *甘えび 甘えび *マグロ マグロ *トロ トロ *赤身 赤身 *サバ サバ *さんま サンマ *ハマチ ハマチ *あじ あじ *ブリ ブリ *さざえ さざえ *ホタテ ホタテ *赤貝 赤貝 *たまご たまご *コーン コーン *ツナサラダ ツナサラダ
このようなコーディングファイルなら「語」の書き換えを行ったうえで、「語」と同様の対応分析が可能になります。
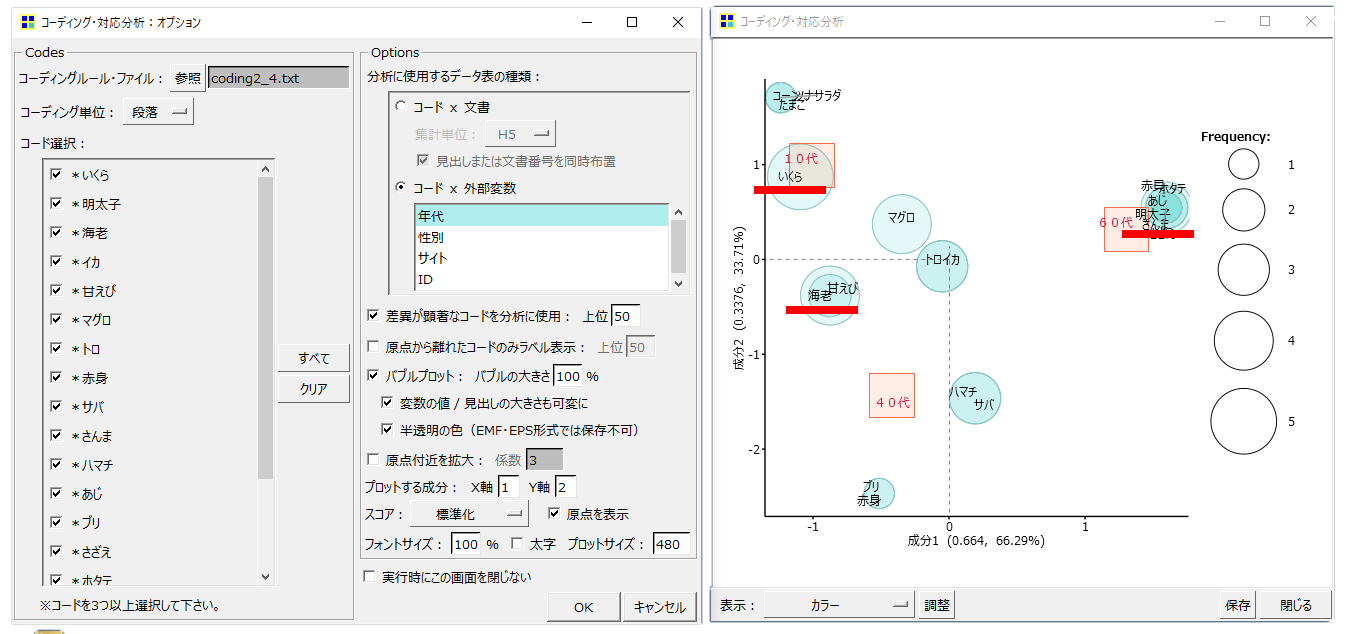
抽出語のときと同じ対応分析、「イクラ」→「いくら」、「サンマ」→「さんま」、「エビ」→「海老」に変換されました。