
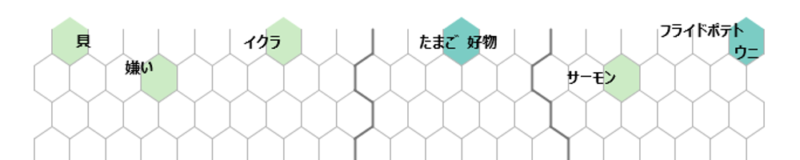
KHcoder 25. 自己組織化マップ(第2回)
自己組織化マップが示すこと
関数「som」
自己組織化マップを作成するためのR関数は「som」です。関数「som」を使用して「語」と「語」の距離を計算します。この距離をもとに「語」をXY座標へプロットし、それぞれの座標にある「語」をどこの六角形へ入れこむのかということを学習によって決定するのだろうと思います。
KHcoderの各種分析機能において「語」と「語」の距離がしばしば登場します。代表的な分析手法が階層的クラスター分析です。階層的クラスター分析結果と自己組織化マップの結果を比較すると妙に似ていることに気が付きます。
自己組織化マップのクラスター
自己組織化マップのクラスター計算式は次のとおりです。
hcl <- hclust( dist(somm$code,method="euclidean"), method="ward.D2" )
#距離を計算するもとデータ
$code
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12]
[1,] -0.289586470 -2.895874e-01 -0.2793403534 -0.289587417 -0.289586778 -0.27964789 -0.283559338 3.157413606 -0.287864372 -0.289478815 -0.2895873726 -0.2895874132
[2,] -0.291126512 -2.911296e-01 -0.2638236154 -0.291129710 -0.291127516 -0.26731485 -0.275065865 3.122481583 -0.279046068 -0.290459030 -0.2911291142 -0.2911296564
[3,] -0.296958040 -2.969781e-01 -0.2077787561 -0.296978325 -0.296963366 -0.22209415 -0.244497891 2.919236986 -0.172884894 -0.290164311 -0.2969623967 -0.2969767468
#実際のデータは400行あります。階層的クラスター分析で計算するもとデータは「d」です。「d」は行が「語」、列が「段」のおなじみのマトリクスデータです。自己組織化マップで距離を計算するデータは「somm$code」です。「somm$code」のもとをたどると「d」です。
階層的クラスター分析結果と自己組織化マップの結果を比較すると妙に似ている理由は、どちらもクラスタリングのR関数が「hclust」であり、データの加工過程に違いがあるものの、はじめのデータは行が「語」、列が「段」のマトリクスデータです。
d
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12]
[1,] 1 1 0 1 0 0 0 0 0 0 0 1
[2,] 0 0 0 0 1 0 1 0 0 0 1 1
[3,] 0 1 0 0 0 0 1 0 0 1 0 0比較してみる
「語」と「語」の距離
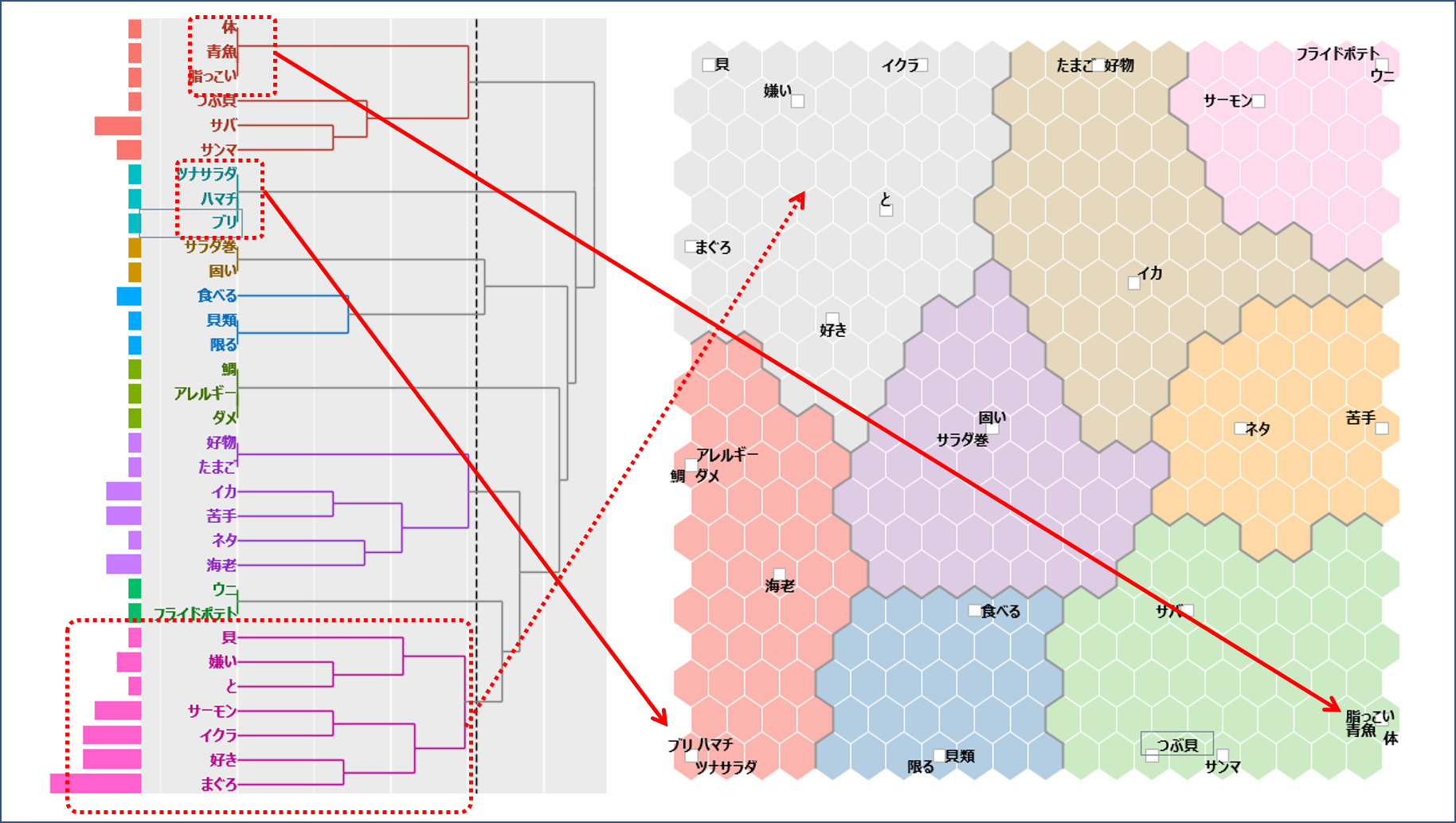
左図が階層的クラスター分析結果、右図が自己組織化マップです。クラスターを形成する「語」が両者で完全に一致はしないものの、確かに似ています。
第一段階で
①「体」・「青魚」・「脂っこい」
②「ツナサラダ」・「ハマチ」・「ブリ」
③「サラダ巻」・「固い」
④「貝類」・「固い」
⑤「鯛」・「アレルギー」・「ダメ」
⑥「ウニ」・「フライドポテト」
これらの群が同時に形成されます。はじめに群を形成するということは「語」と「語」の距離が近いということです。
また、同時に形成されるということは、例えば、①の「体」と「青魚」の距離と②の「ツナサラダ」と「ハマチ」の距離が同一値であることを意味します。
自己組織化マップをみると第一段階で群を形成した各「語」が同一の六角形内へプロットされていることがわかります。従って自己組織化マップへプロットされる「語」の座標はクラスター分析で使用する距離とほぼ同一のものと考えてもよさそうです。
クラスターとクラスターの距離
「体」を含むクラスターと「貝」を含むクラスターが対角に配置されています。階層的クラスター分析では一番上のクラスターと一番下のクラスターですから、クラスター間の距離が最も遠い関係にあります。距離が遠いことをビジュアル化しようとすれば四角いキャンバスへの描画ですから対角に配置するのがわかりやすいと思います。
対角には「ツナサラダ」を含むクラスターと「ウニ」を含むクラスターが配置されています。
自己組織化マップだけで読んでみる
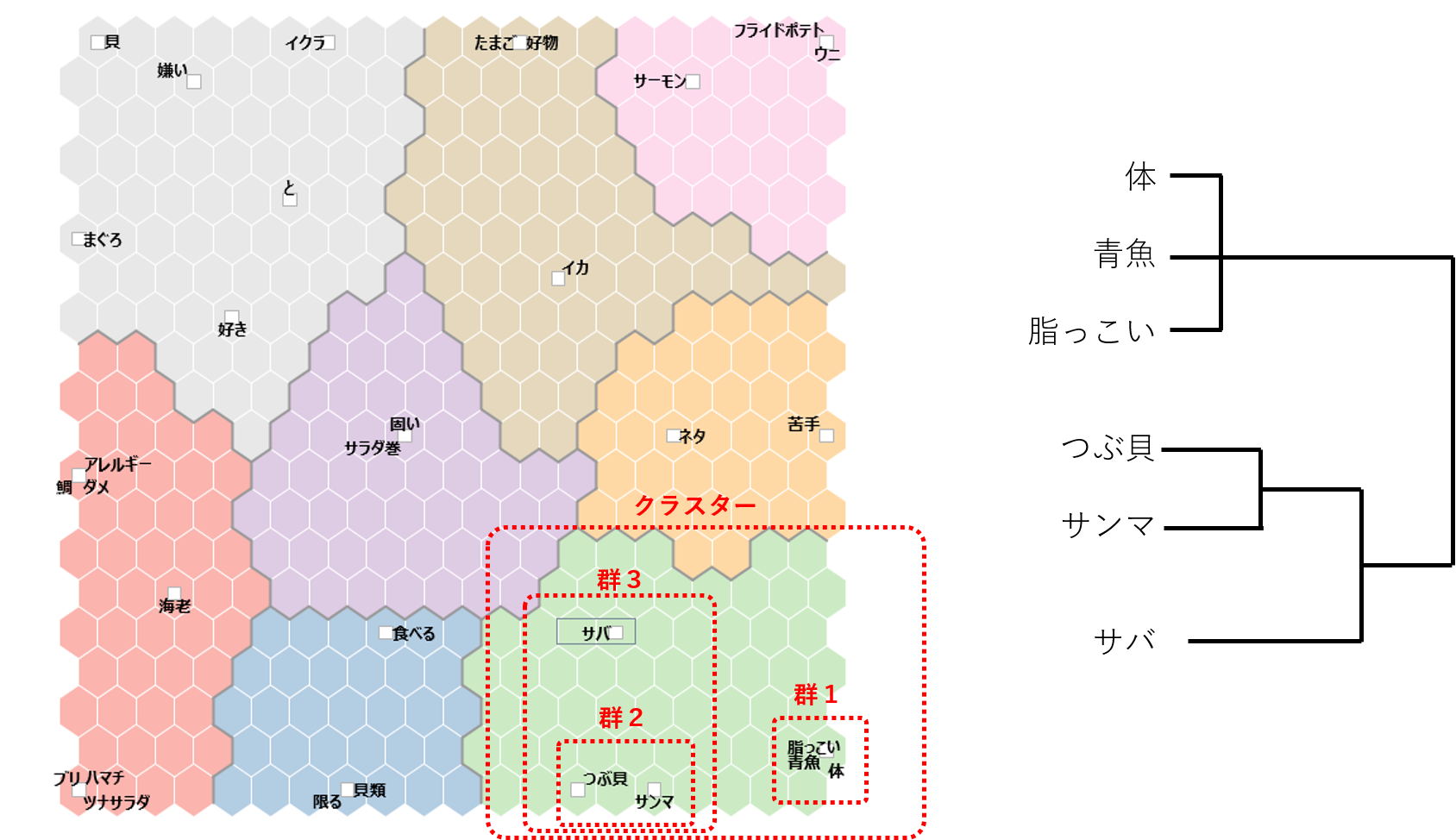
自己組織化マップの右下の部分を読んでみます。
第一段階で「体」・「青魚」・「脂っこい」が群1を形成する。第二段階で「つぶ貝」・「サンマ」が群2を形成する。第三段階で群2と「サバ」が群3を形成する。群1と群3がくっついてクラスターを形成する。このような感じでしょうか。
>KHcoder 24. 自己組織化マップ(第1回)