
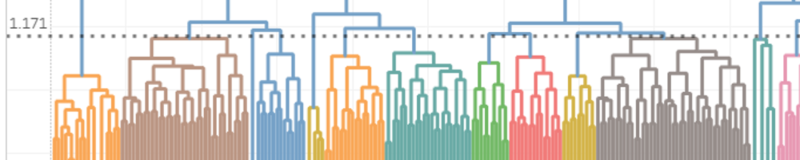
タブローでデンドログラム(樹形図)を描く
たいがいのことができるタブロー、はたして、デンドログラムを描画できるのでしょうか?
クラスター分析
デンドログラムとは
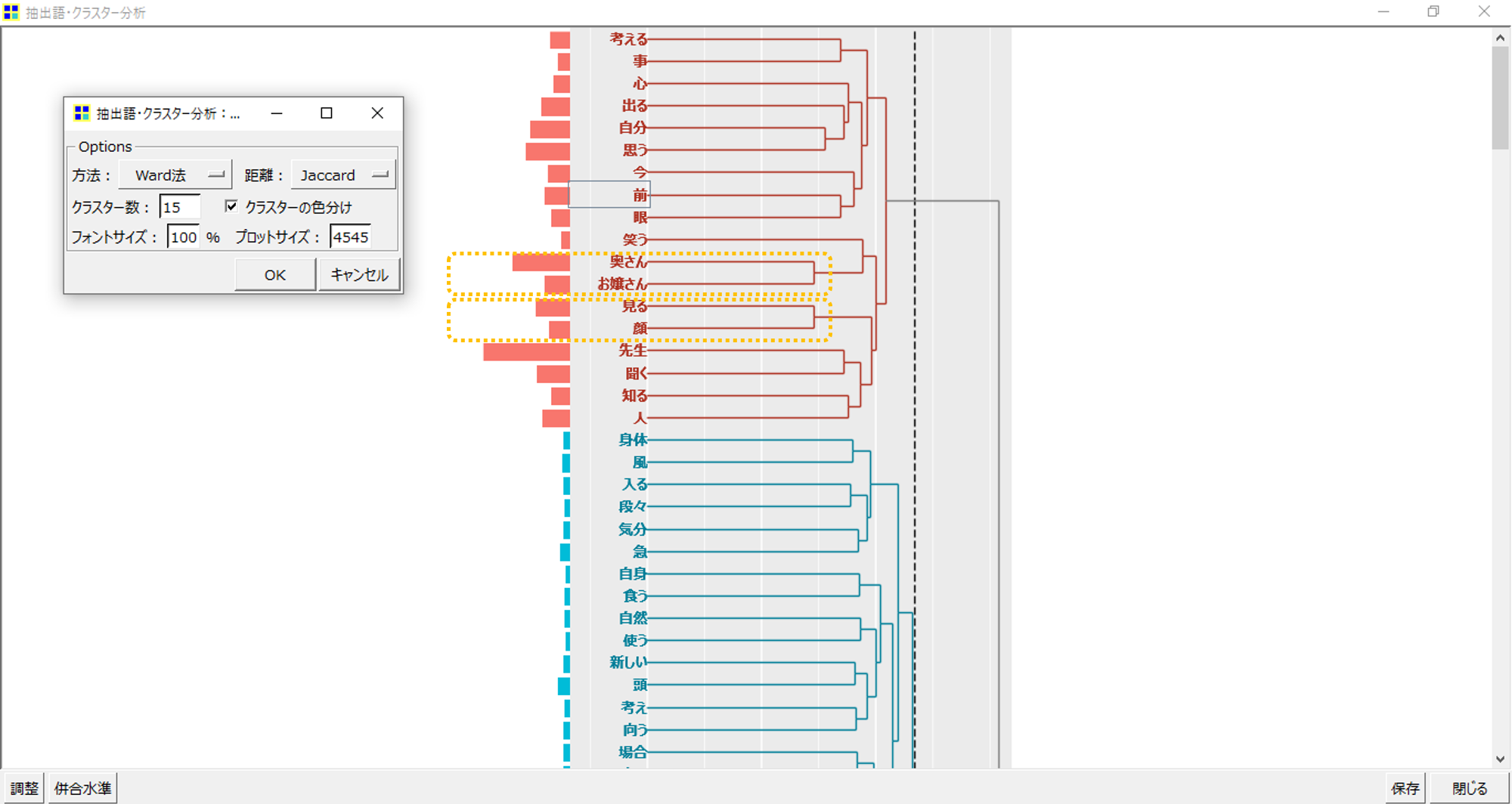
KHcoderで階層的クラスター分析(抽出語)を実行します。最小出現回数=20(語数225)、方法=Word、距離=Jaccard、このように設定しました。クラスター数15の分析結果が表示されます。この樹形図がデンドログラムです。
このデンドログラムは左側から見ていきます。(一般的には下から見るものが多い)
・「奥さん」と「お嬢さん」、「見る」と「顔」がいちばんはじめに、かつ同時に群をつくります。群とはクラスターになる前のかたまりです。
・次に「自分」と「思う」が群になります。次々と群が形成されてクラスターが形成されます。
縦に伸びる破線と右横へ伸びるデンドログラムの線との交点から左側にある群のかたまりが1つのクラスターです。
クラスター数が15ということは、破線とデンドログラムの線との交点が15個あるということになります。(クラスター分析(第1回) 好きと苦手の境界線)
タブローでデンドログラムを描画するには
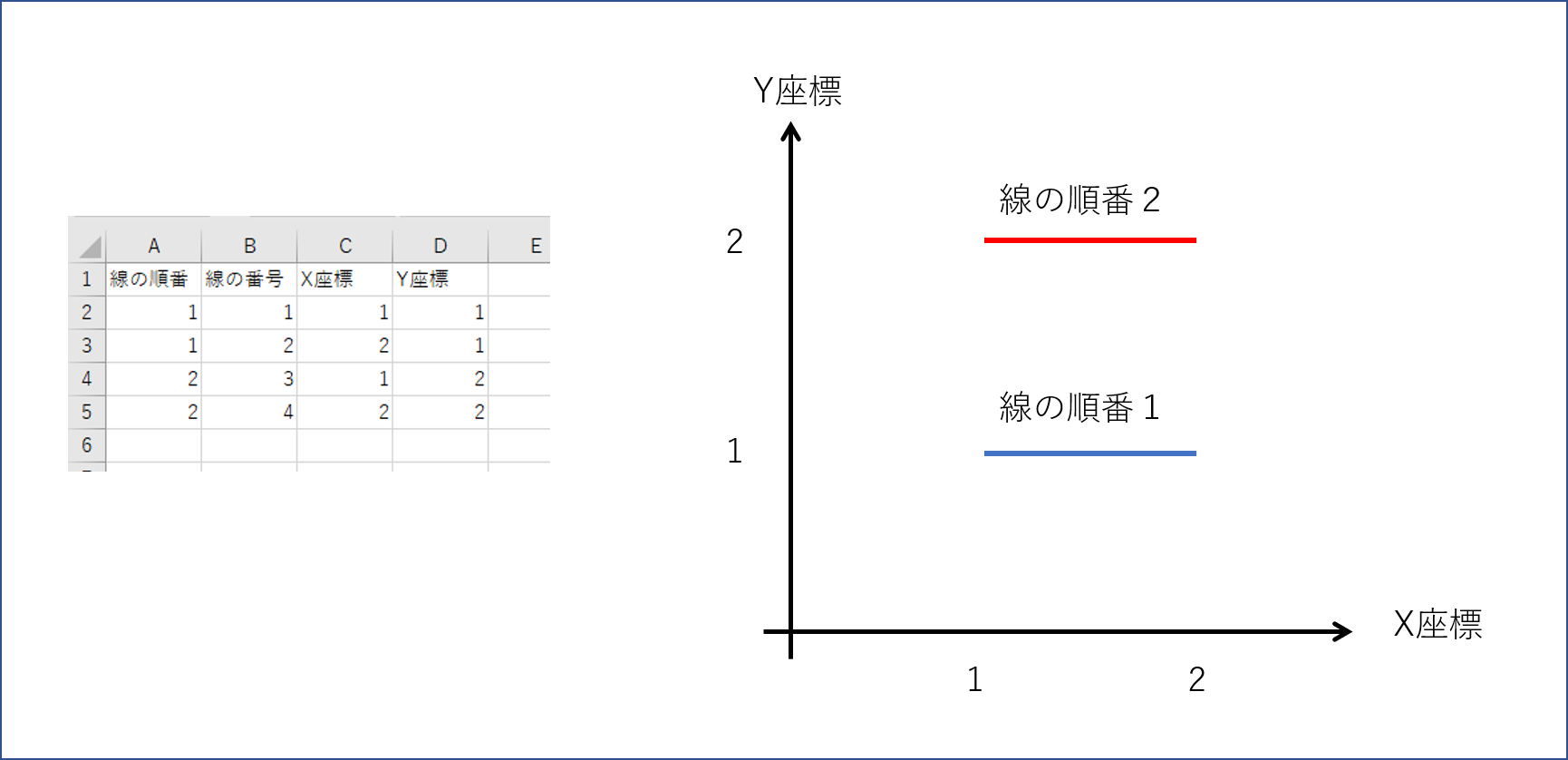
デンドログラムの構造から、ラベルになる「語」を横軸=ゼロ、縦軸=一定間隔の連続数へプロットすればよいことがわかります。
問題は線をどのようにプロットするのか?です。
タブローには点A(Xa座標、Ya座標)から点B(Xb座標、Yb座標)へ直線を描画する機能があります。
直線を描画するデータには、線の順番、線の番号、X座標、Y座標が必要です。
線の番号1のXY座標(スタート座標)から線の番号2のXY座標(エンド座標)へと、線の順番1の直線を描画します。座標設定によって縦横ナナメに直線を描画することが可能です。
Rからデータをアウトプットする
Rのデータ
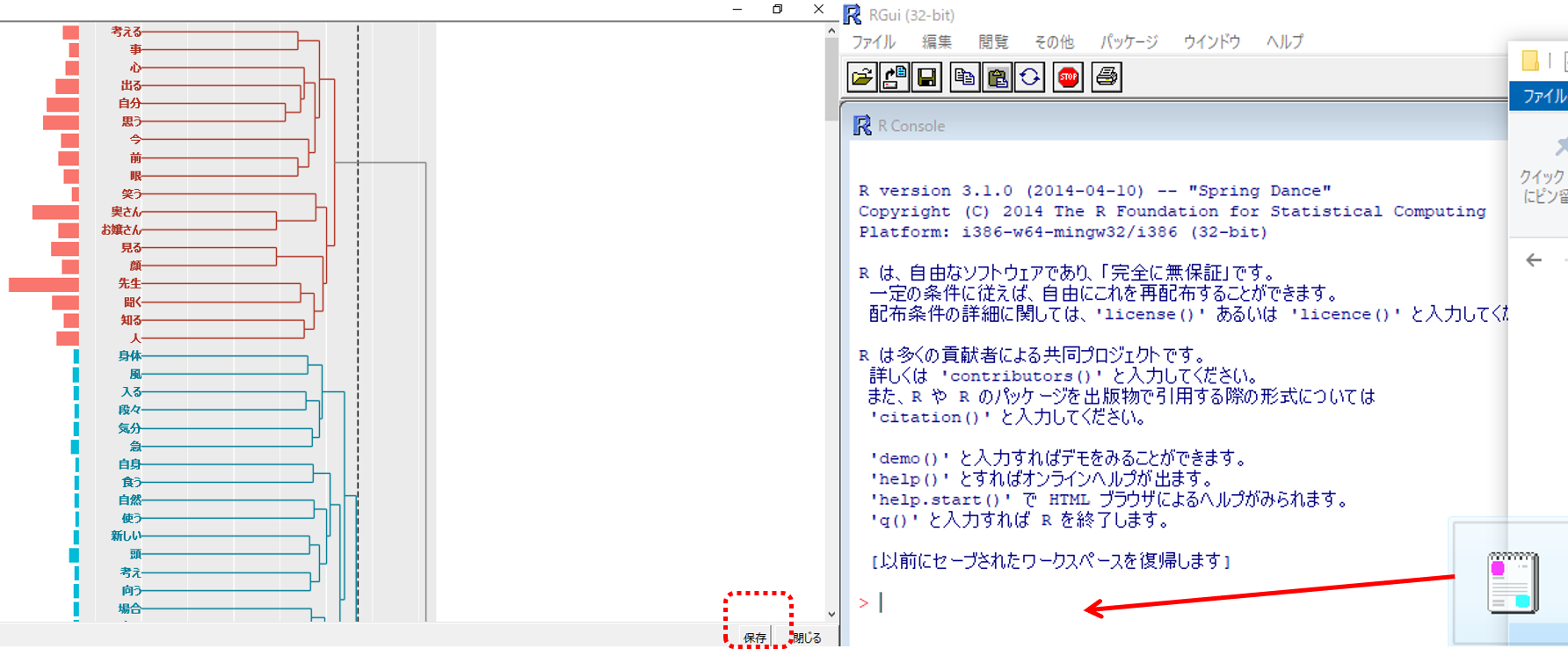
・KHcoderの階層的クラスター分析結果の右下「保存」をクリック
・ファイルの種類=RSource形式で保存します。
・保存したファイルをRのワークスペースへドロップします。
・Rから必要なデータをCSV形式で取り出します。
#語のリスト write.csv(labels, "ディレクトリ名/ラベル.csv") #語のクラスター write.csv(cutree(hcl,k=15), "ディレクトリ名/語のクラスター.csv") #語をプロットするXY座標 write.csv(ddata$labels, "ディレクトリ名/ラベルの座標.csv") #線のスタート座標とエンド座標 write.csv(ddata$segments, "ディレクトリ名/線.csv") #線のクラスター write.csv(seg_cl, "ディレクトリ名/線のクラスター.csv")
「語」をプロットするためのデータ
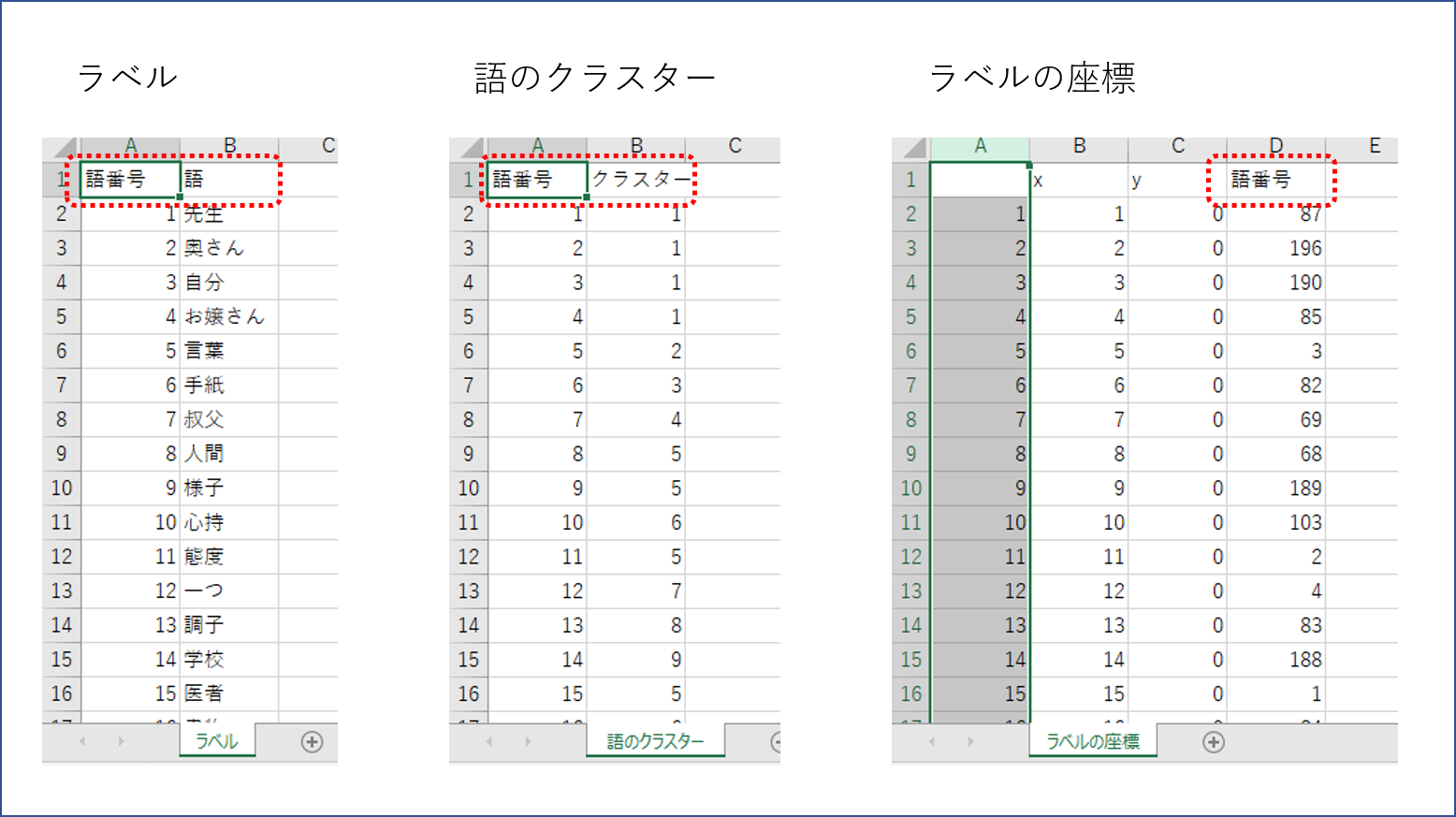
出力した各CSVファイルを開いて列目を書き換えます。
・「ラベル.csv」:A列を「語番号」、B列を「語」
・「語のクラスター.csv」:A列を「語番号」、B列を「クラスター」
・「ラベルの座標.csv」:D列を「語番号」、A列を削除
これで各データソースを「語番号」で結合することができるようになります。
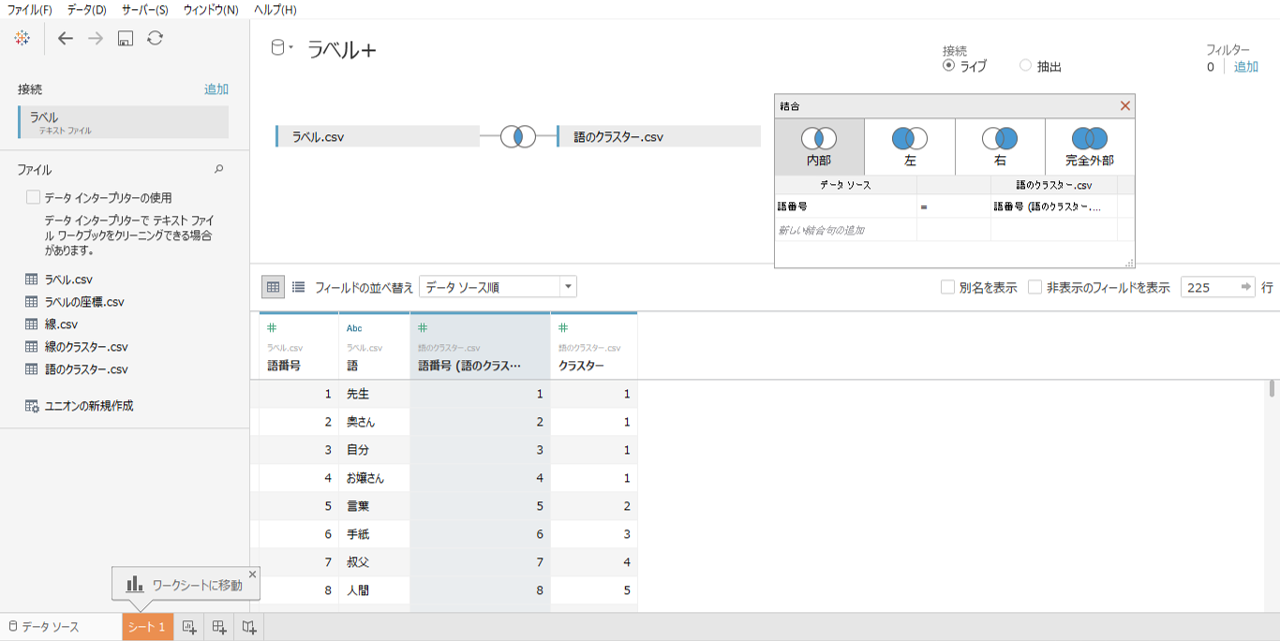
・タブローからデータソースへ接続します。
・「ラベル.csv」と「語のクラスター.csv」を内部結合します。
・結合句は「語番号」です。
・ダブりの「語番号」列は非表示にします。
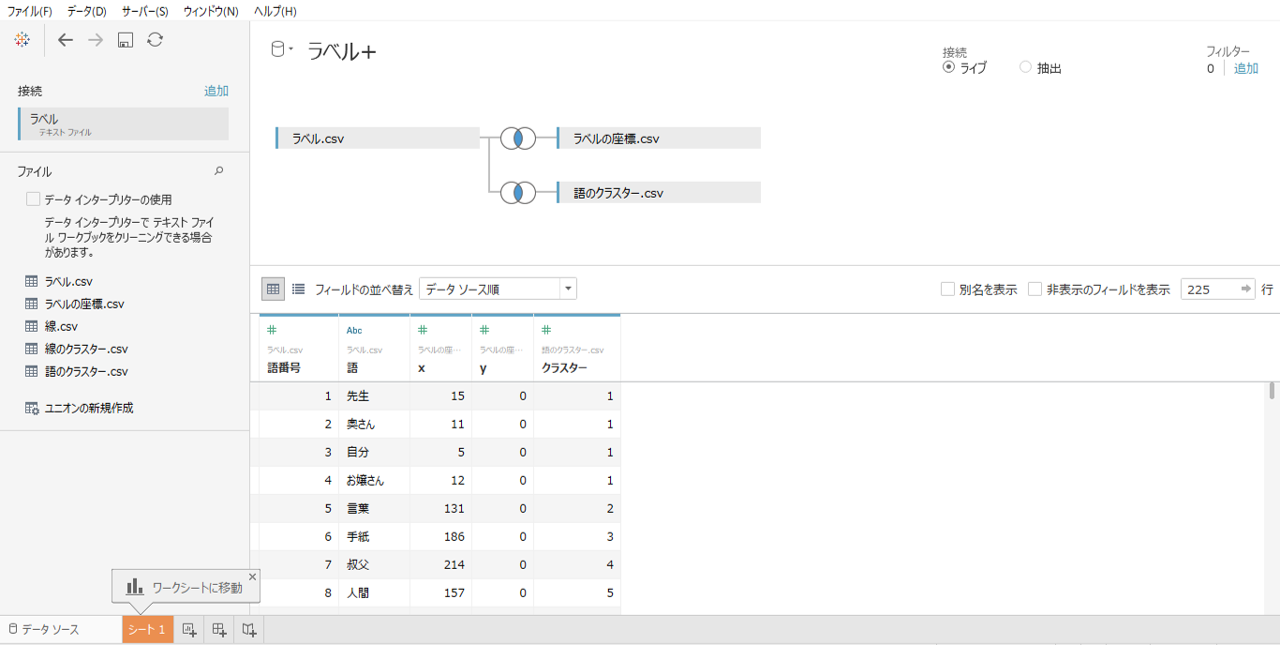
・「ラベルの座標.csv」も同様に「語番号」を結合句に設定して内部結合します。
「線」を描画するためのデータ
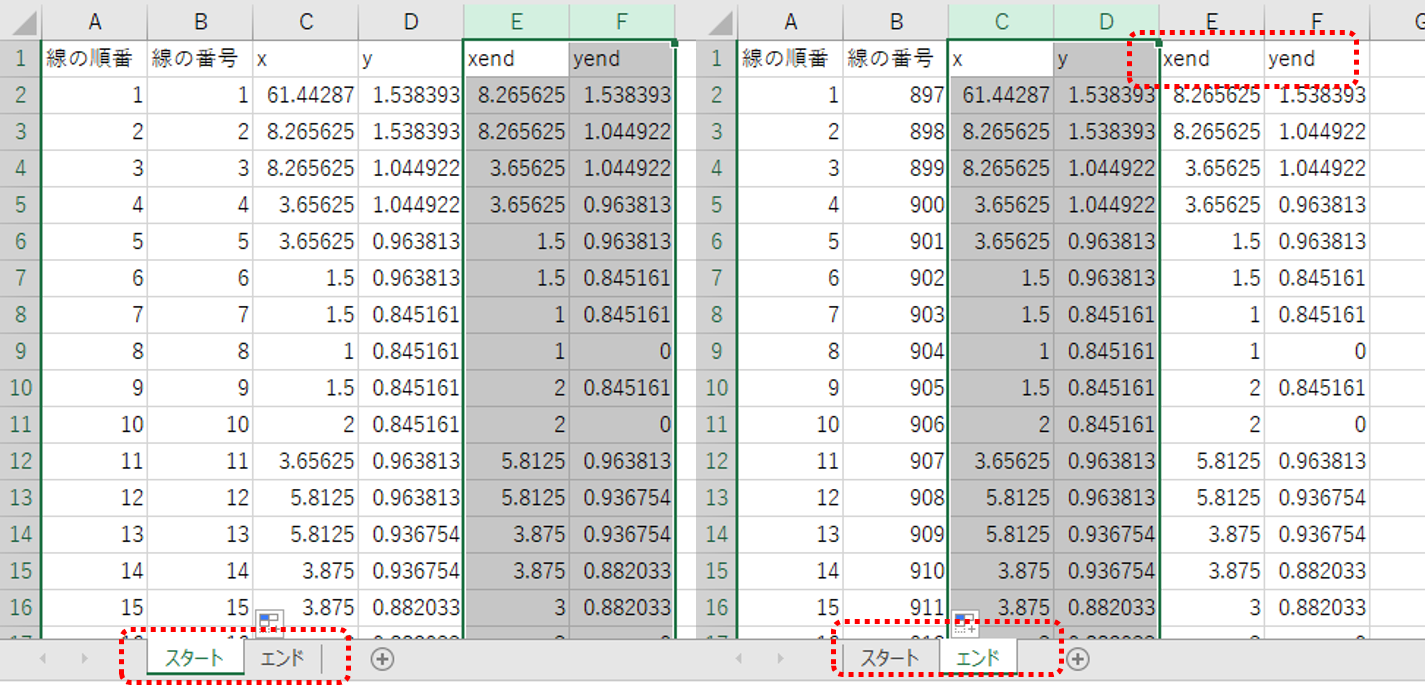
・「線.csv」を開いてシートを複製します。
・スタートのシートはA列名を「線の順番」
・B列へ列を挿入して1から昇順で番号を入力します。
・列名を「線の番号」にします。
・xend、yend、それぞれの列を削除します。
・エンドのシートはA列名を「線の順番」
・B列へ列を挿入してスタートシートの最後尾の「線の順番」から続く数値から昇順で番号を入力します。
・x、y列は削除して、xendをx、yendをy、に書き換えます。
・シートが2枚になったので.xlsxエクセルで保存します。
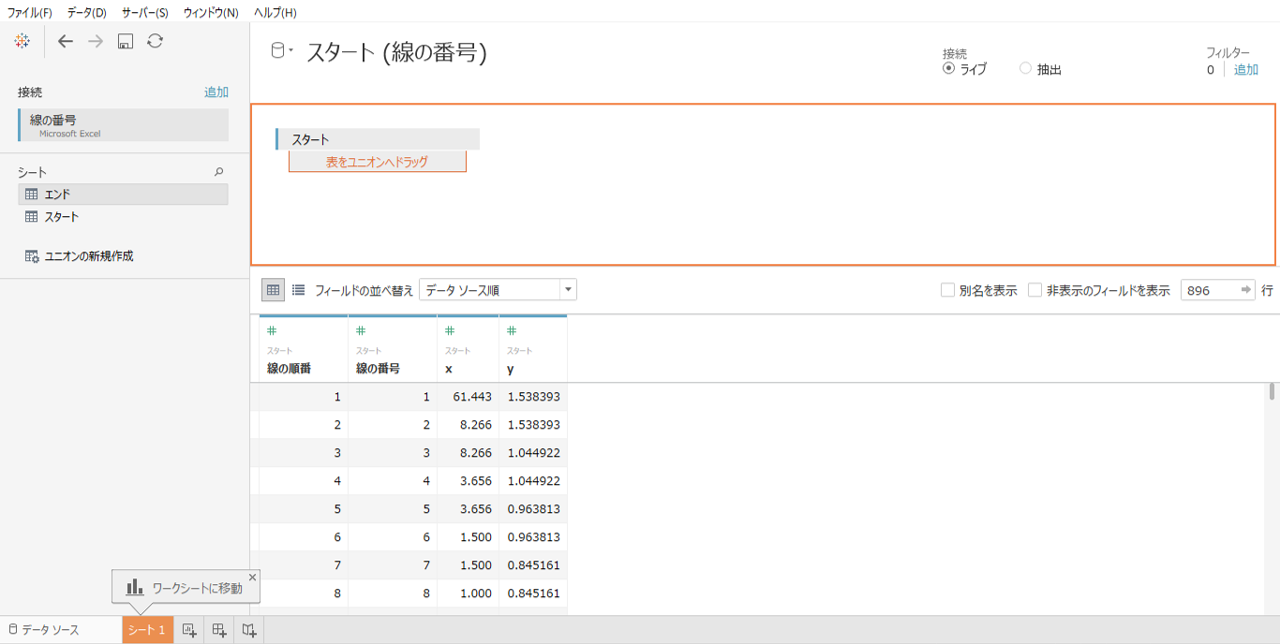
・タブローから「線.xlsx」データソースへ接続します。
・スタートのシートとエンドのシートをユニオンします。
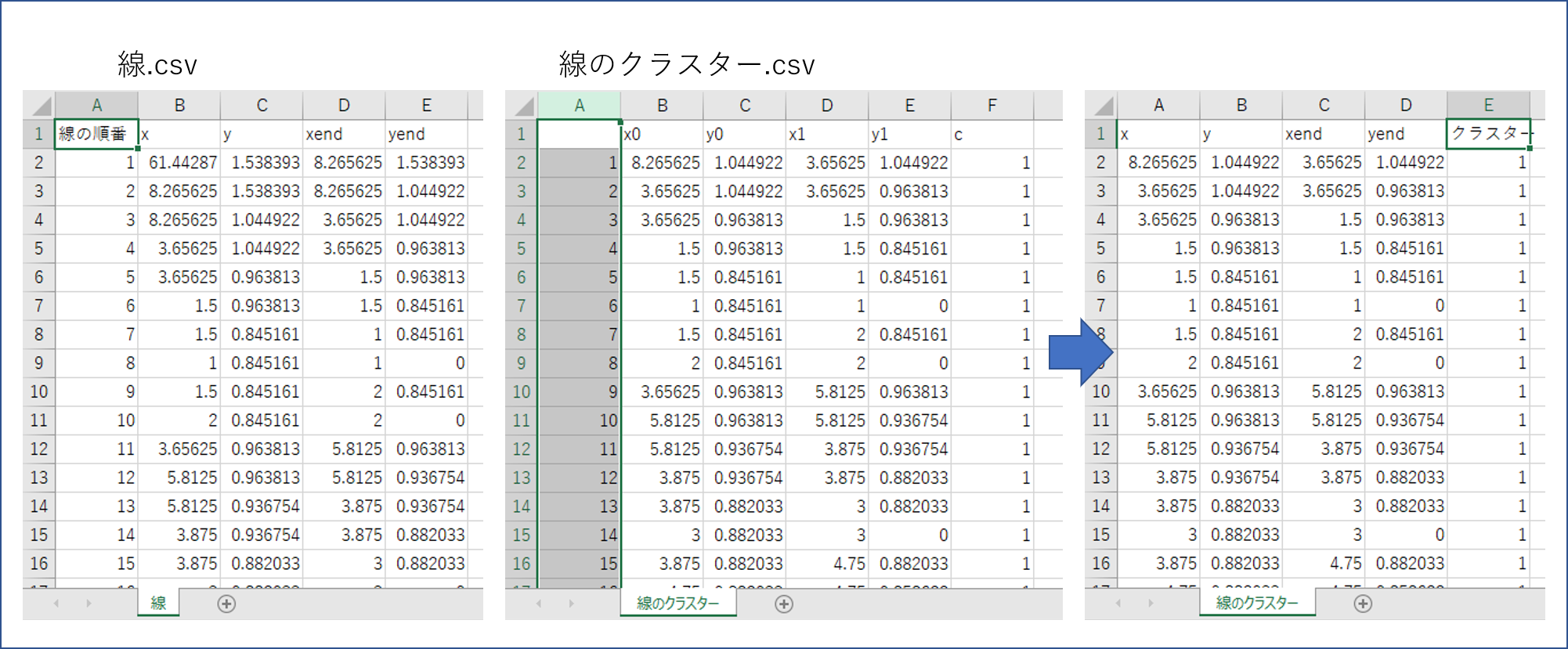
・「線.csv」(エクセルに加工するまえのCSV)を開いてA列名を「線の順番」にします。
・保存して閉じます。
・「線のクラスター.csv」を開いてA列を削除、各列名を「線.csv」と同じにします。
・最終列は「クラスター」です。
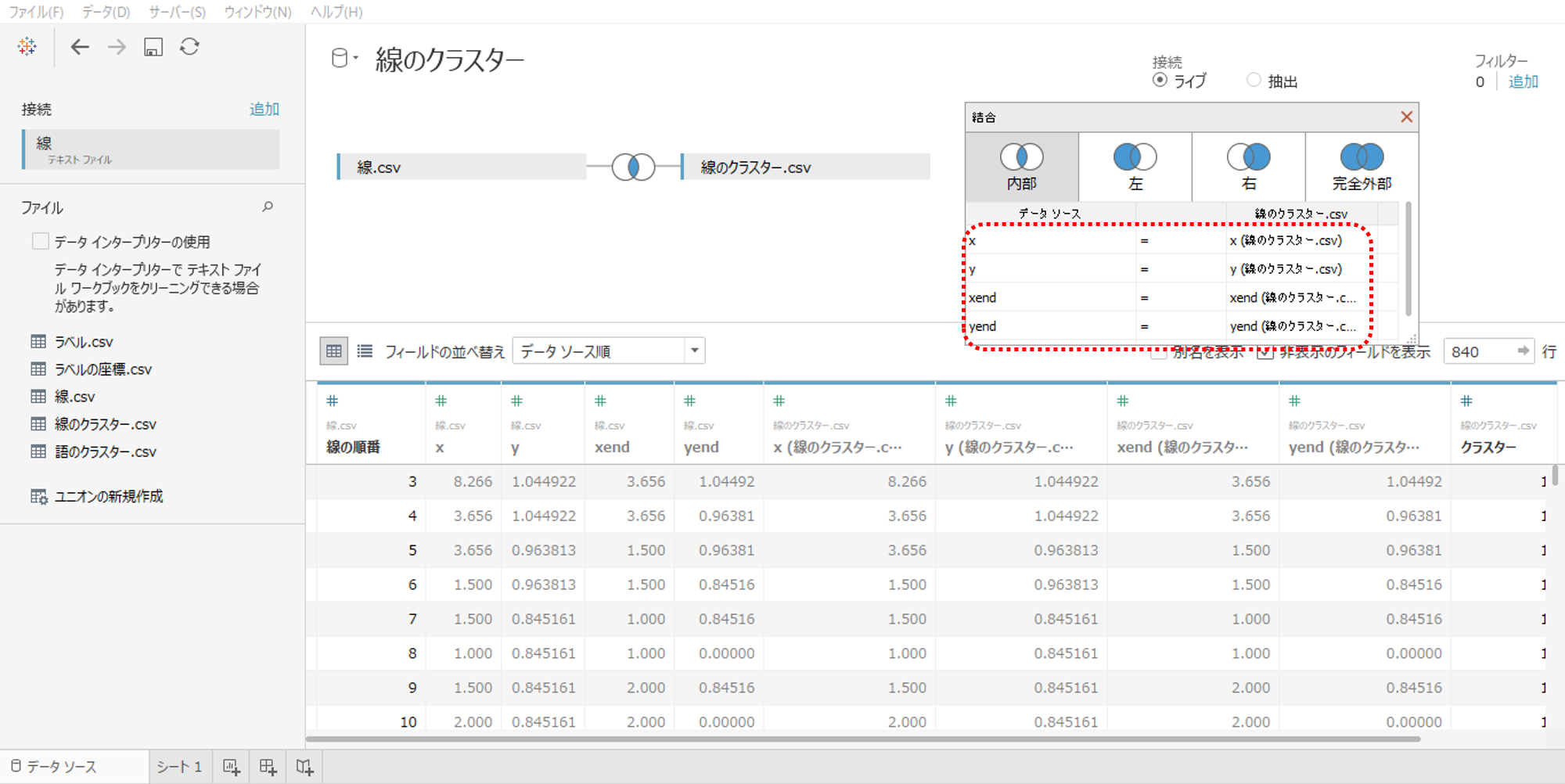
・タブローでデータソースへ接続して
・「線.csv」と「線のクラスター.csv」を内部結合します。
。結合句は「x」「y」「xend」「yend」です。
・必要な列は「線の順番」と「クラスター」だけですから、その他の列を非表示にします。
デンドログラムを描画
線を描画する
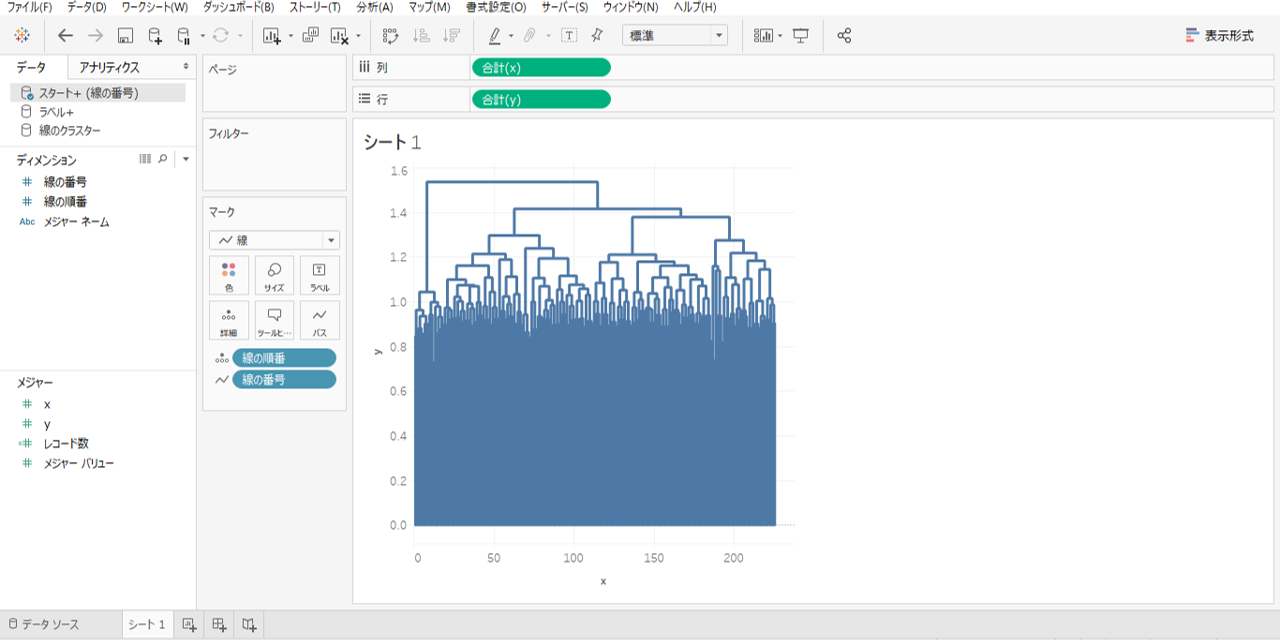
現在、タブローから接続しているデータソースは
①「ラベル+」=「ラベル.csv」と「語のクラスター.csv」と「ラベルの座標.csv」を内部結合したデータ
②「スタート+(線の番号)」=「線xlsx」の27枚のシートをユニオンしたデータ
③「線のクラスター」=「線.csv」と「線のクラスター.csv」を結合したデータ、です。
・「スタート+(線の番号)」をプライマリデータにします。
・「線の番号」「線の順番」メジャーになっていたらディメンションへ変更します。
・xを列シェルフへ
・yを行セルフへドロップします。
・「線の順番」を詳細へドロップしてマークを線に設定します。
・「線の番号」をパスへドロップします。
これで線の描画は完成です。
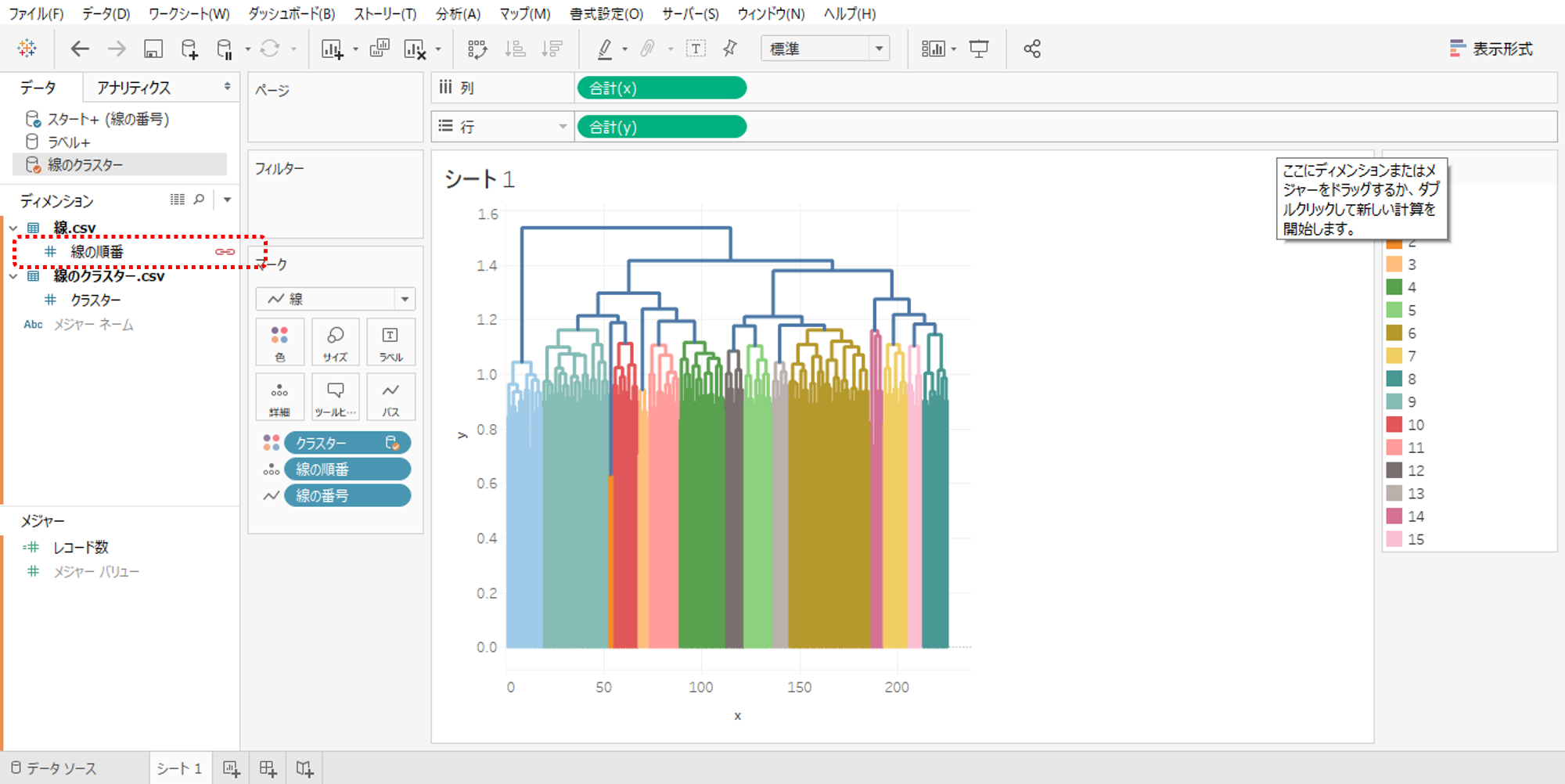
・データソースを「線のクラスター」へ移動して「線の順番」でデータブレンドします。
・クラスターを色へドロップします。
・クラスターがメジャーになっていたらディメンションへ変更してください。
語をプロットする
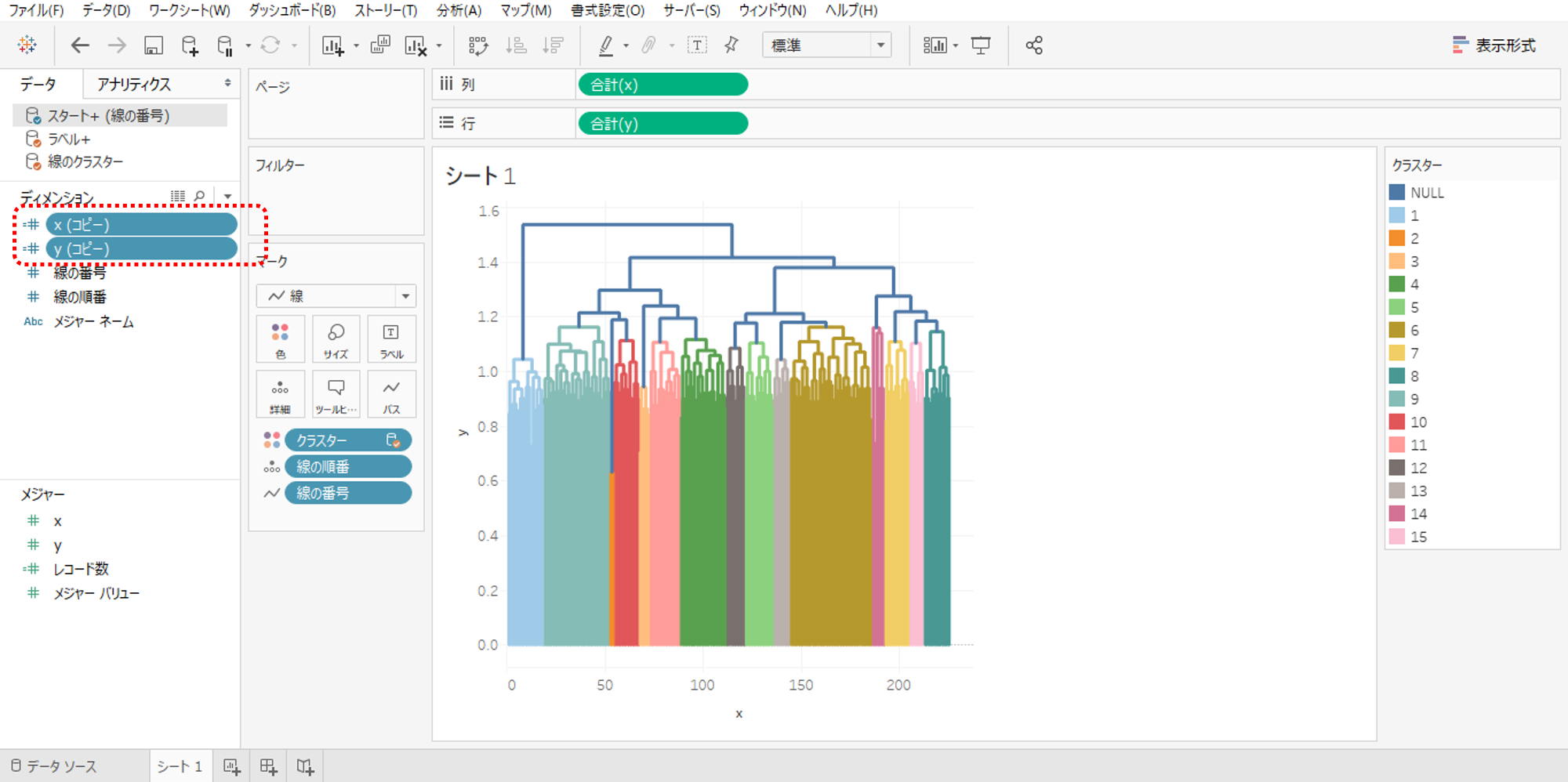
・データソース「スタート+(線の番号)」へ戻り
・メジャーの「x」「y」を複製してディメンションへ移動します。
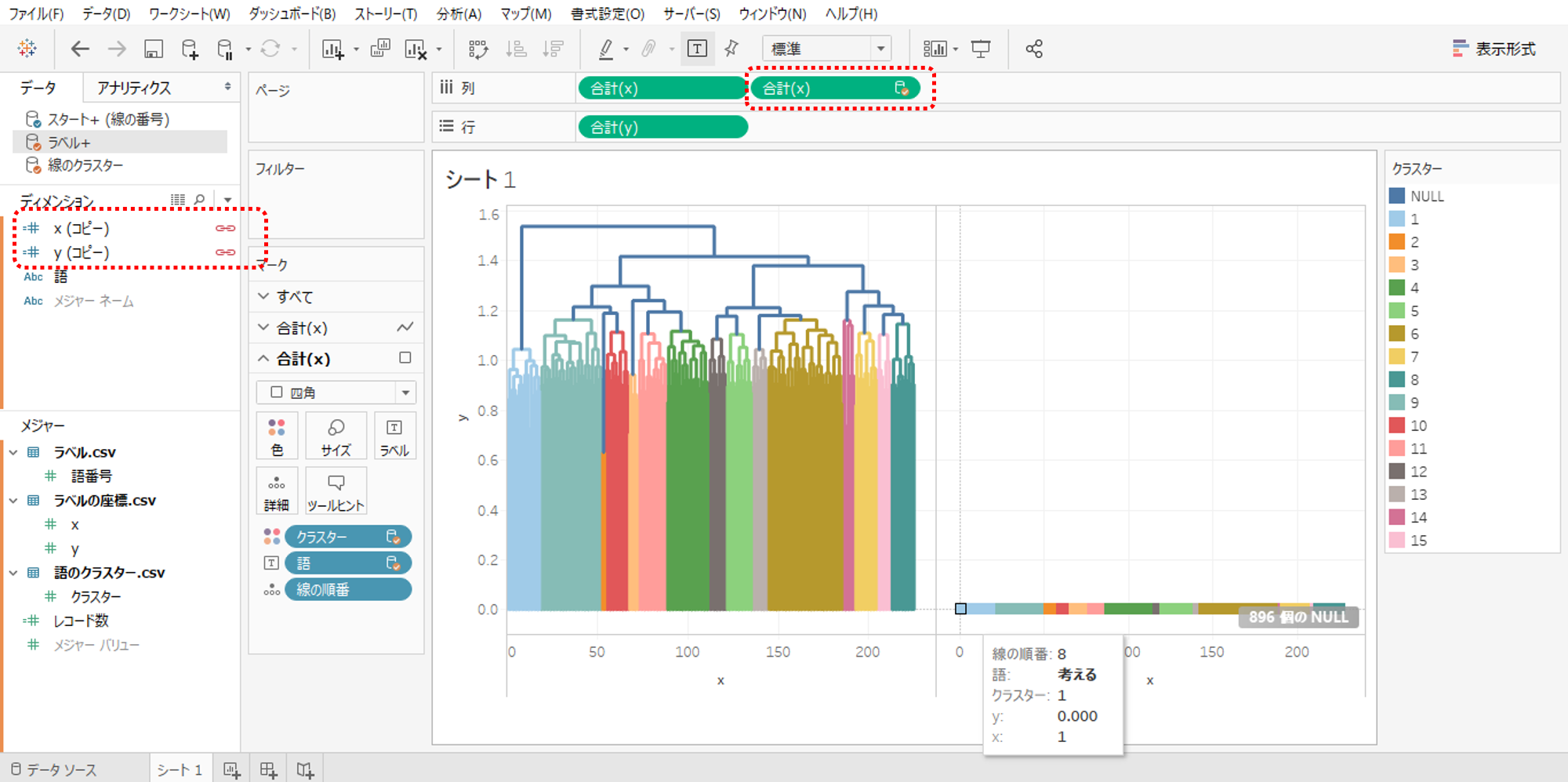
・データソース「ラベル+」へ移動してメジャーの「x」「y」を複製してディメンションへ移動します。
・「x(コピー)」「y(コピー)」でデータをブレンドします。
・「ラベル+」データソースの「x」を列シェルフへドロップします。
・「線の番号」をパスから外して
・「語」をラベルへドロップします。
・形状を四角へ変更してください。これで語のプロットは完成です。
描画を重ねる
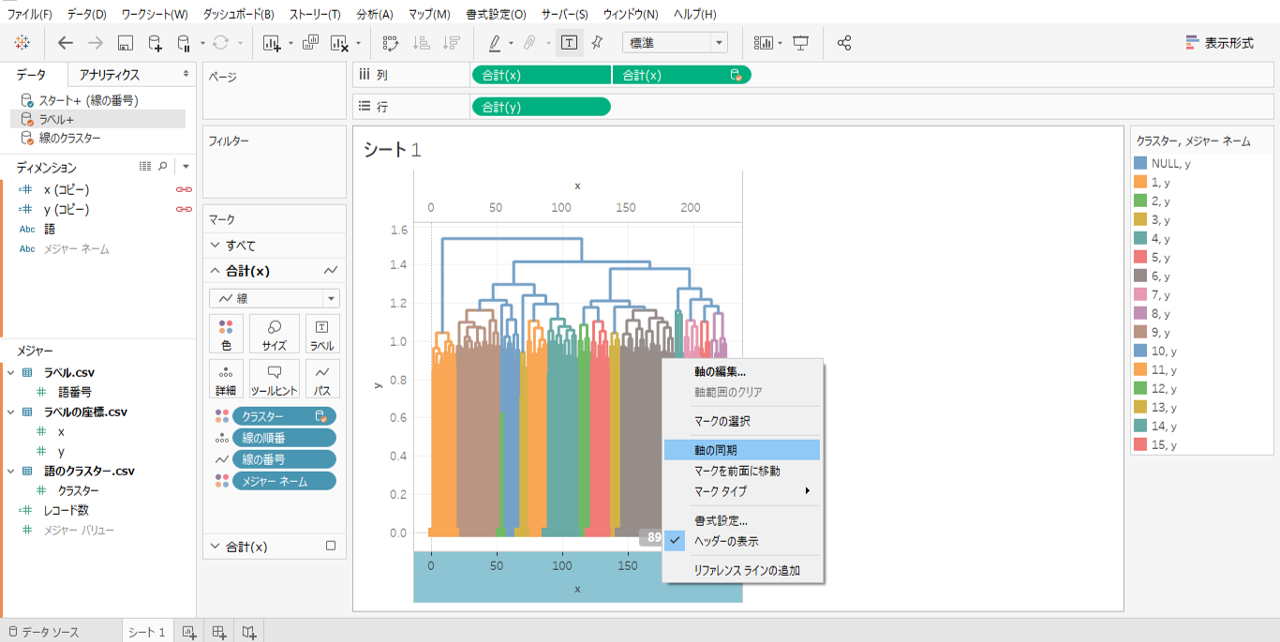
・「x」を右クリックして二重軸を選択します。
・x軸を右クリックして軸の同期を選択します。
仕上げ
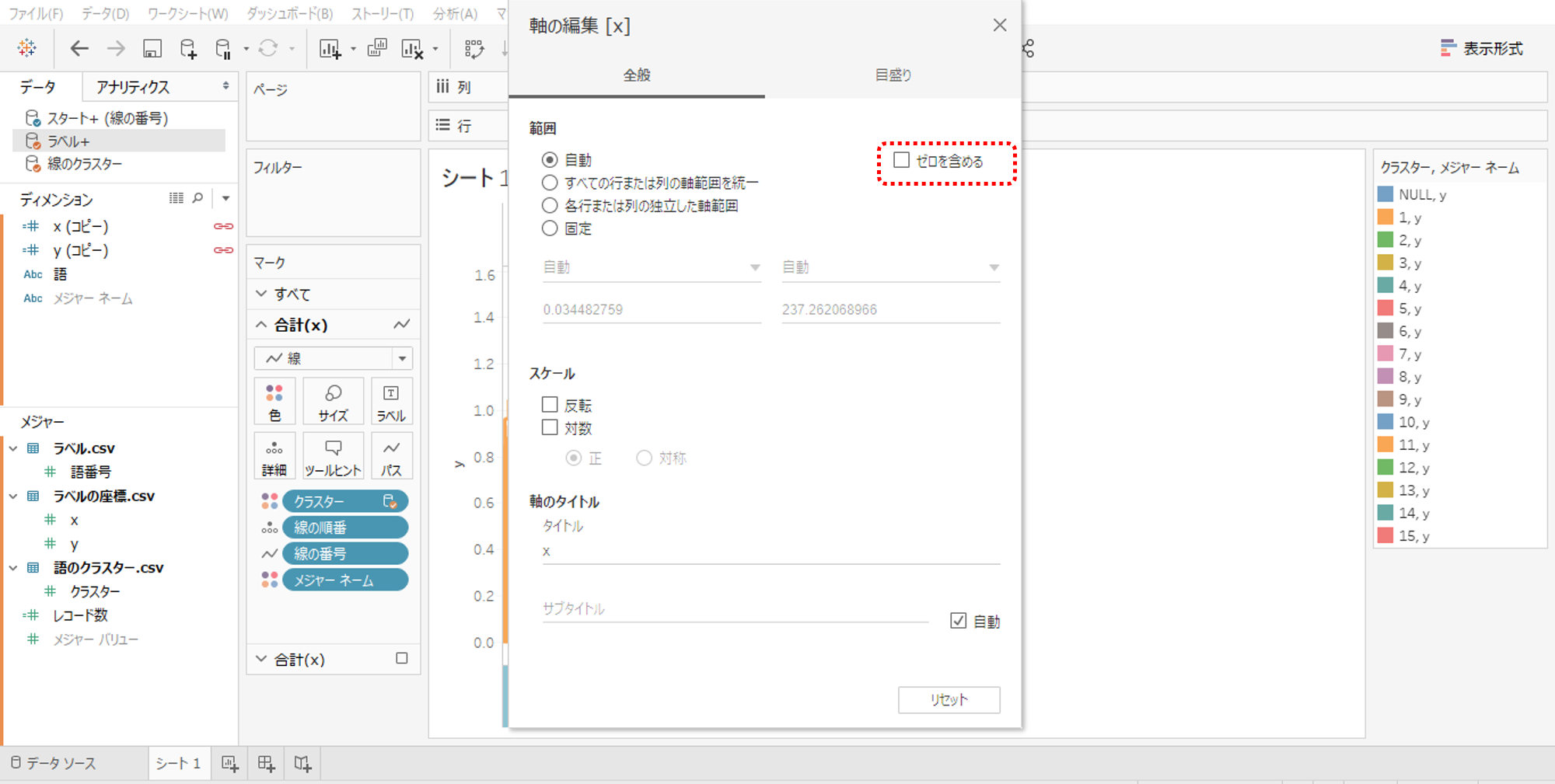
・軸の編集を開いてゼロを含めるのチェックを外します。
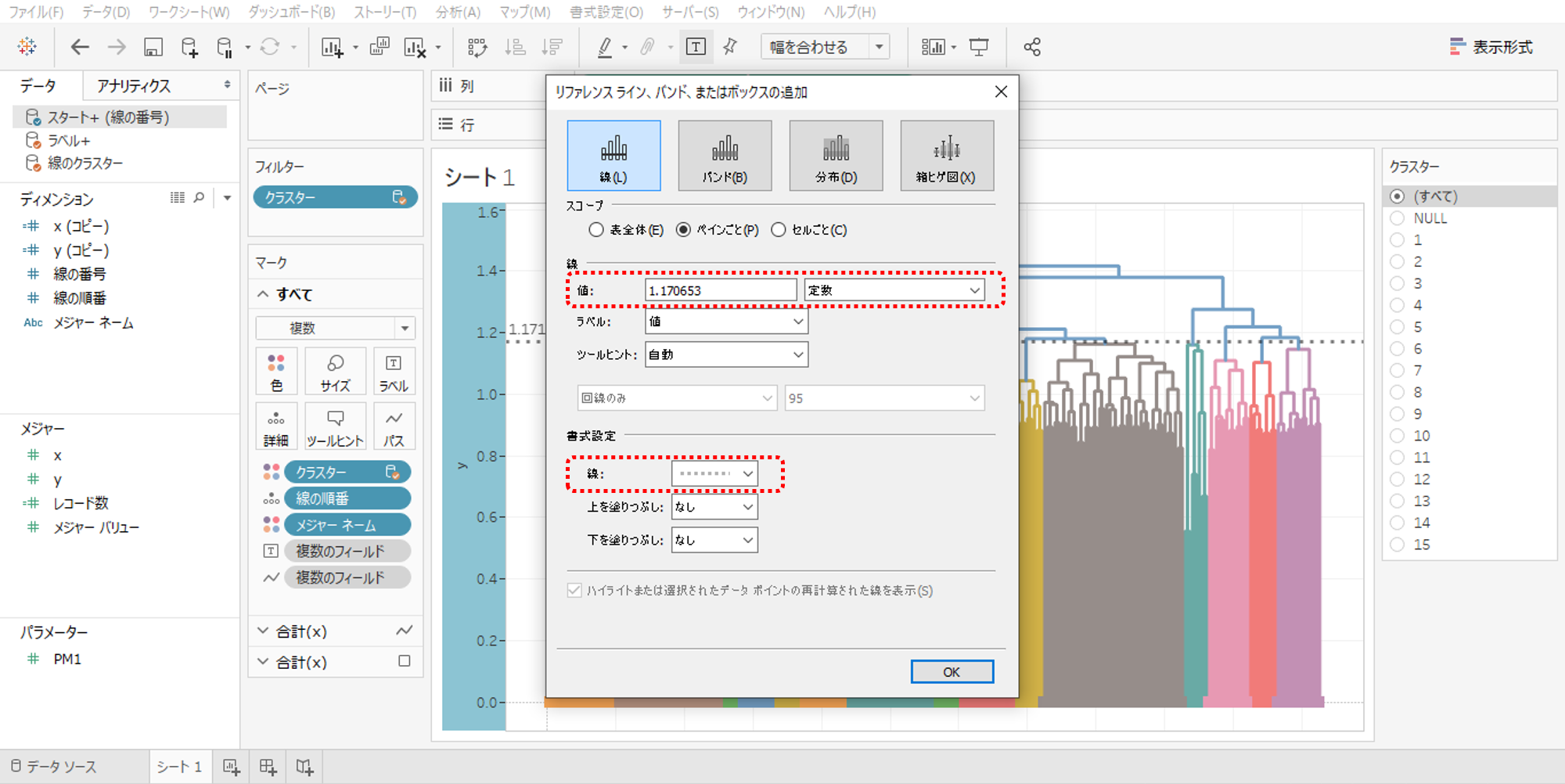
・リファレンスラインを追加します。
・値は定数にします。
・線をグレーの破線にします。
#定数の求め方 cutpoint #このようにRへ入力して表示される数値です。
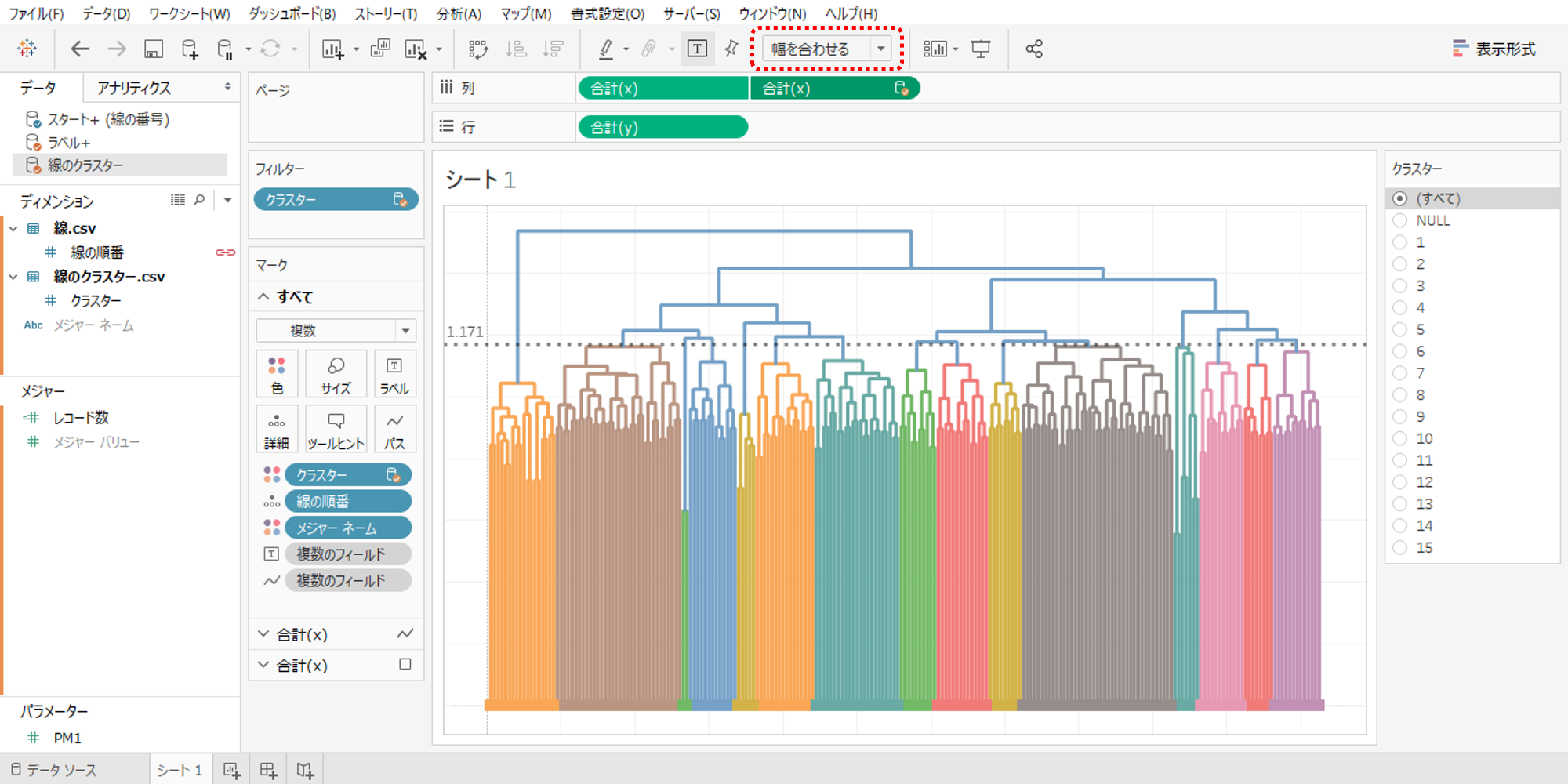
・「幅を合わせる」に設定するとシート全体に描画が広がります。
・クラスターをフィルターに設定します。
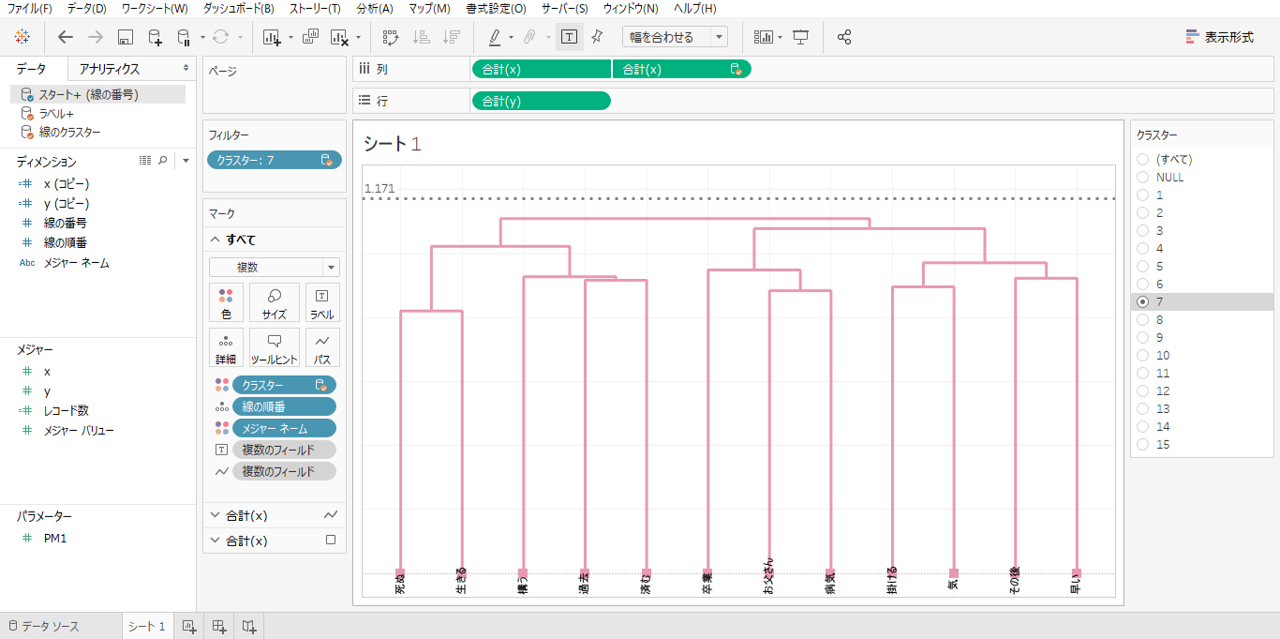
・フィルターでクラスターを選択すると詳細を確認することができます。