

年次経済財政報告(経済財政白書)第4回
言葉の出現回数を時間軸へプロットして、言葉の流行をみえる化してみようとする大胆なチャレンジ、いよいよ最終回。
抽出語が登場した時期
甲子園初出場
高校野球甲子園大会で「今回が初出場」、「3年連続5回目の出場」、「10年ぶり2回目の出場」、このような出場校紹介がよくなされます。
過去から現在までの甲子園出場校のデータがあって、高校名を検索して一致する高校名がなければ「初出場」、一致する高校名の出現回数をカウントすれば出場回数、今大会の年度と前回出場した年度の差分が「何年ぶり」、このようにデータベースを集計しているのだろうと思います。
年次経済財政報告(経済財政白書)のテキストマイニングは時間軸が主なテーマです。
・ある抽出語が分析対象テキストにはじめて出現したのはいつなのか?
・どのくらい連続(年度)して出現しているのか?どのくらいの間隔(年度)で出現したり消えたりしているのか?
今回はこれらをビジュアル化することにチャレンジでしてみます。
抽出語の初出現はいつか
データソースは前回の投稿時に作成した、抽出語に出現した年度と出現回数、クラスターがくっついたものです。
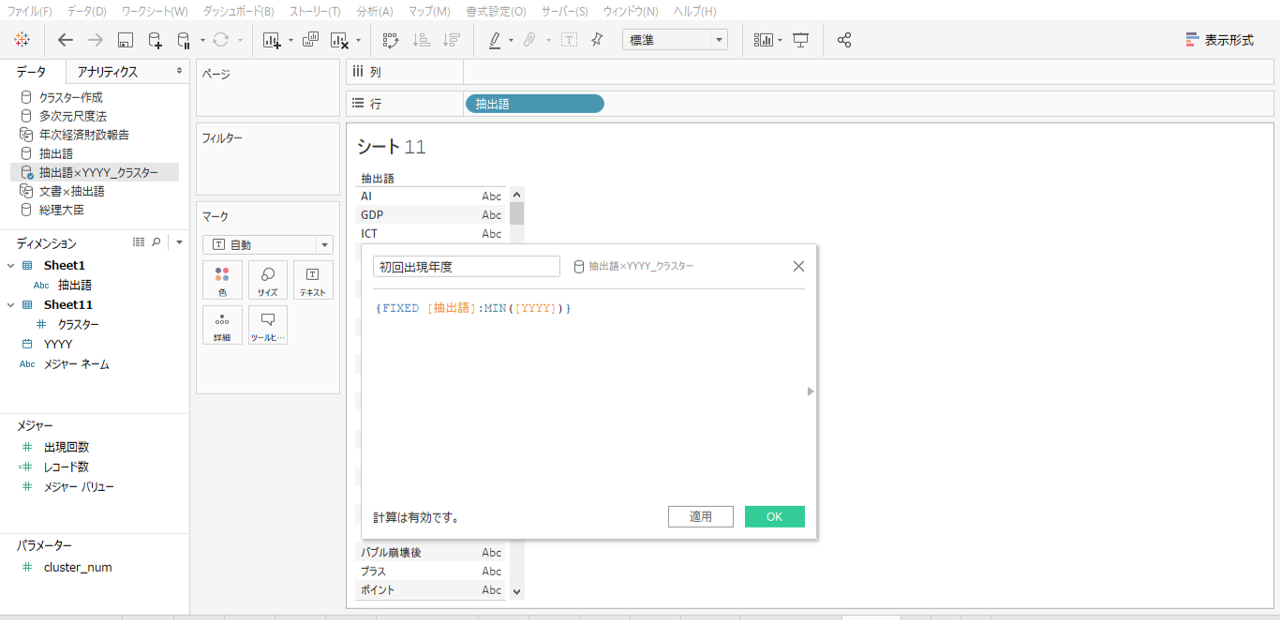
タブローのLOD表現を使用して抽出語が初出現した年度のディメンションをつくります。
#タブローの計算式
{FIXED [抽出語]:MIN([YYYY])}
見慣れない計算式です。LOD表現については後ほど説明します。
「初回出現年度」というディメンションができました。データ形式はカレンダーのマークになっているの「日付」です。
・抽出語を行シェルフへドロップします。
・「初回出現年度」をマークへ入れて内容を確認します。
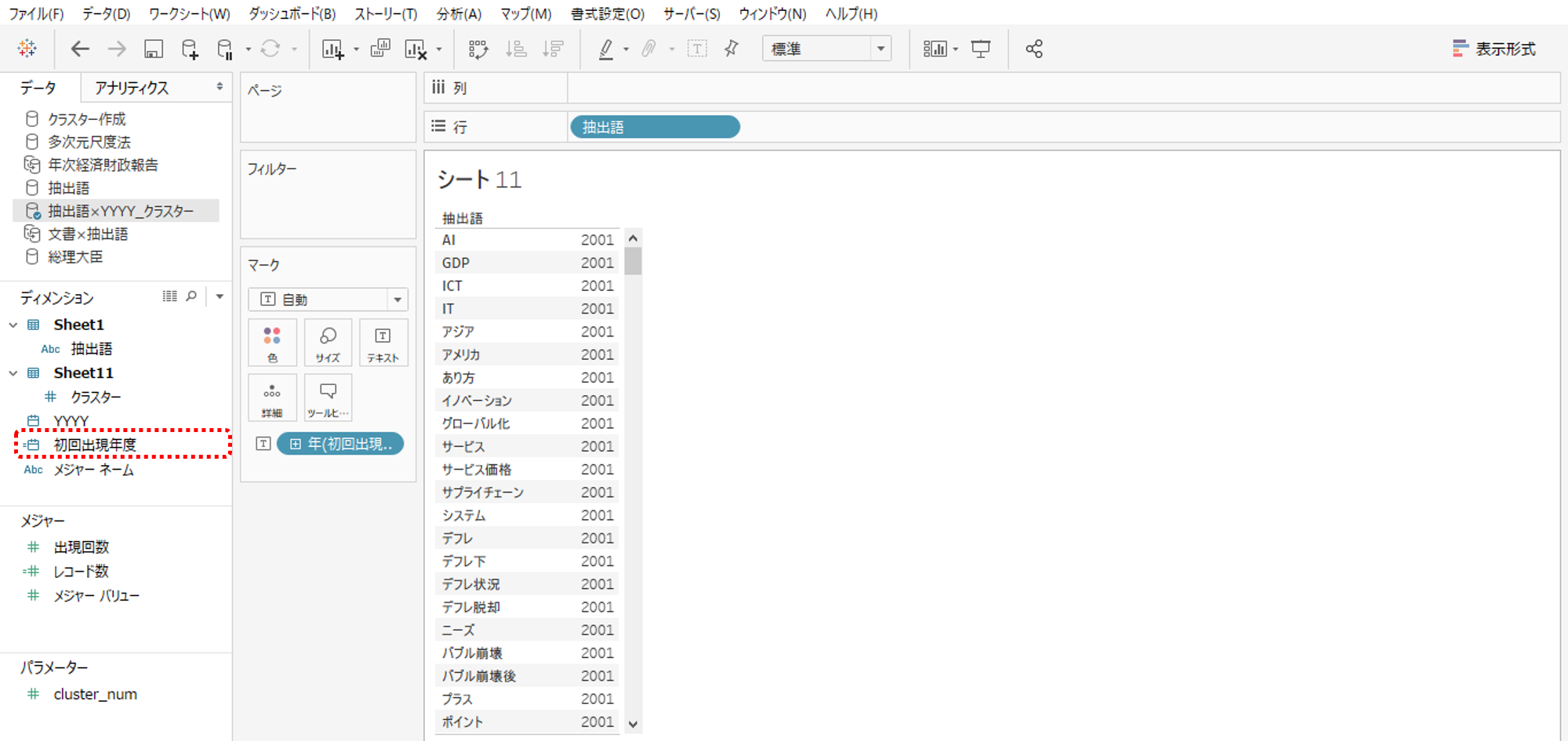
すべて、上から下まで2001になります。抽出語の初回出現年度として正確でありません。
初出現年度が正確でない理由
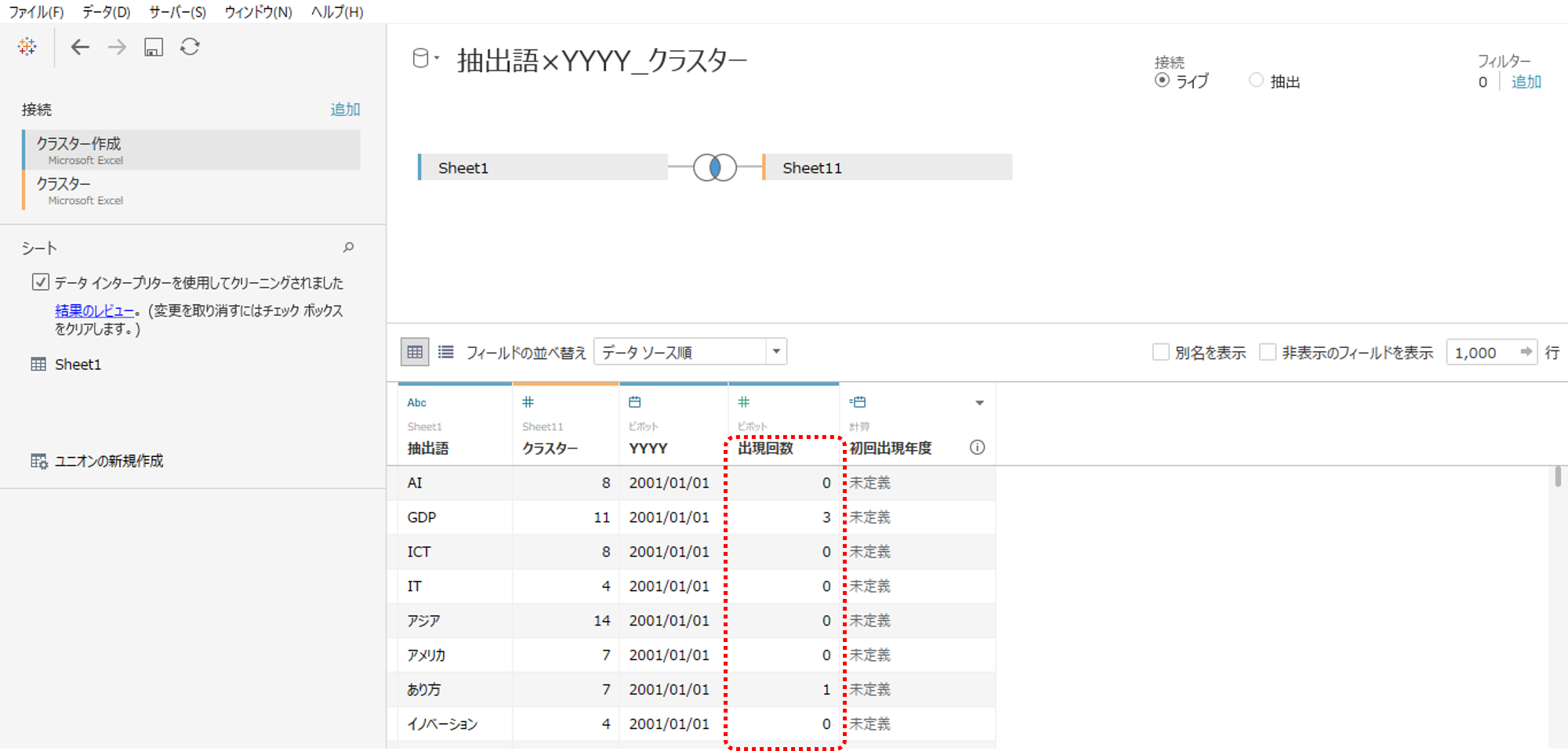
接続しているデータソースです。
「{FIXED [抽出語]:MIN([YYYY])}」はMIN([YYYY])を返す計算式ですから、YYYYの最小値を表示します。
データソースをみてわかる通り、すべての抽出語のYYYYの最小値は2001です。
問題は出現回数がゼロ(つまり出現していない)のデータがあることなのです。出現回数がゼロの行を削除すれば正確な結果を算出できます。
データ修正
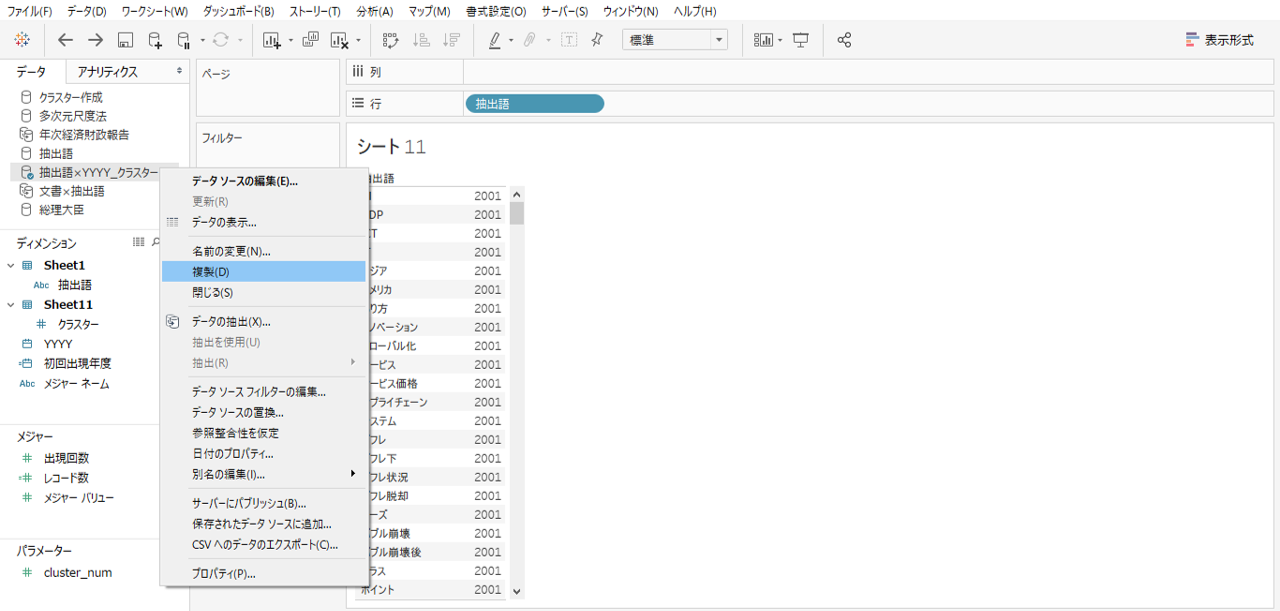
現在のデータソースはほかのVIZで使用しています。これを修正すると既存のVIZが崩れたりする可能性があるため、修正するのは同じデータソースであっても別接続にします。
同一データへ別接続する方法は
・再度データソースへ接続するか
・データーソースを複製する
どちらかです。
このデータは2種類のデータソースを結合していて再接続するのには手間がかかります。今回は複製します。
・データペインを右クリック→複製を選択します。
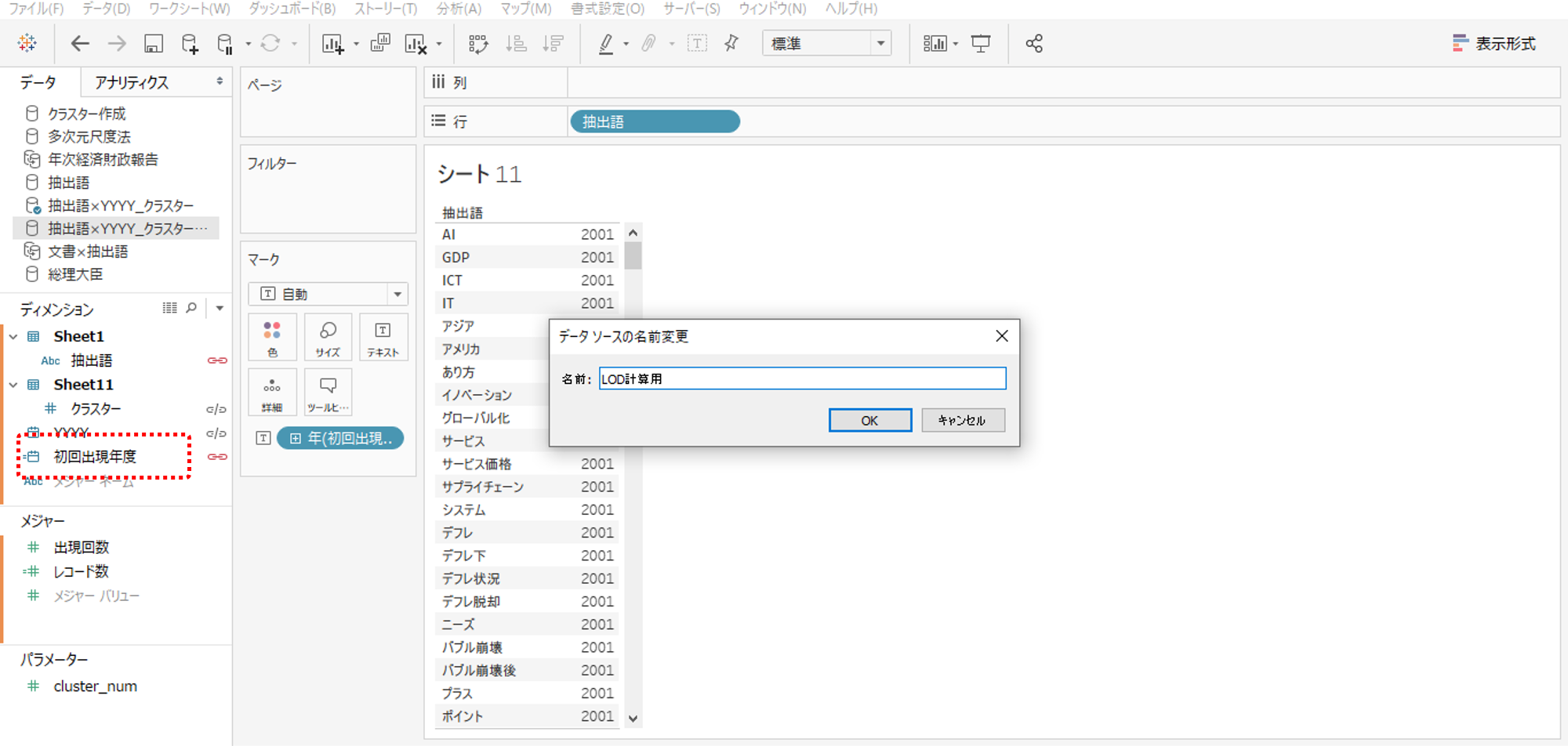
・複製したデータソースを右クリック→名前の変更を選択します。
・窓が開いたら名前を入れて完成です。名前は「LOD計算用」にしました。
ありがたいことに複製前のデータで作成した計算式も複製されます。こはすばらしい機能!
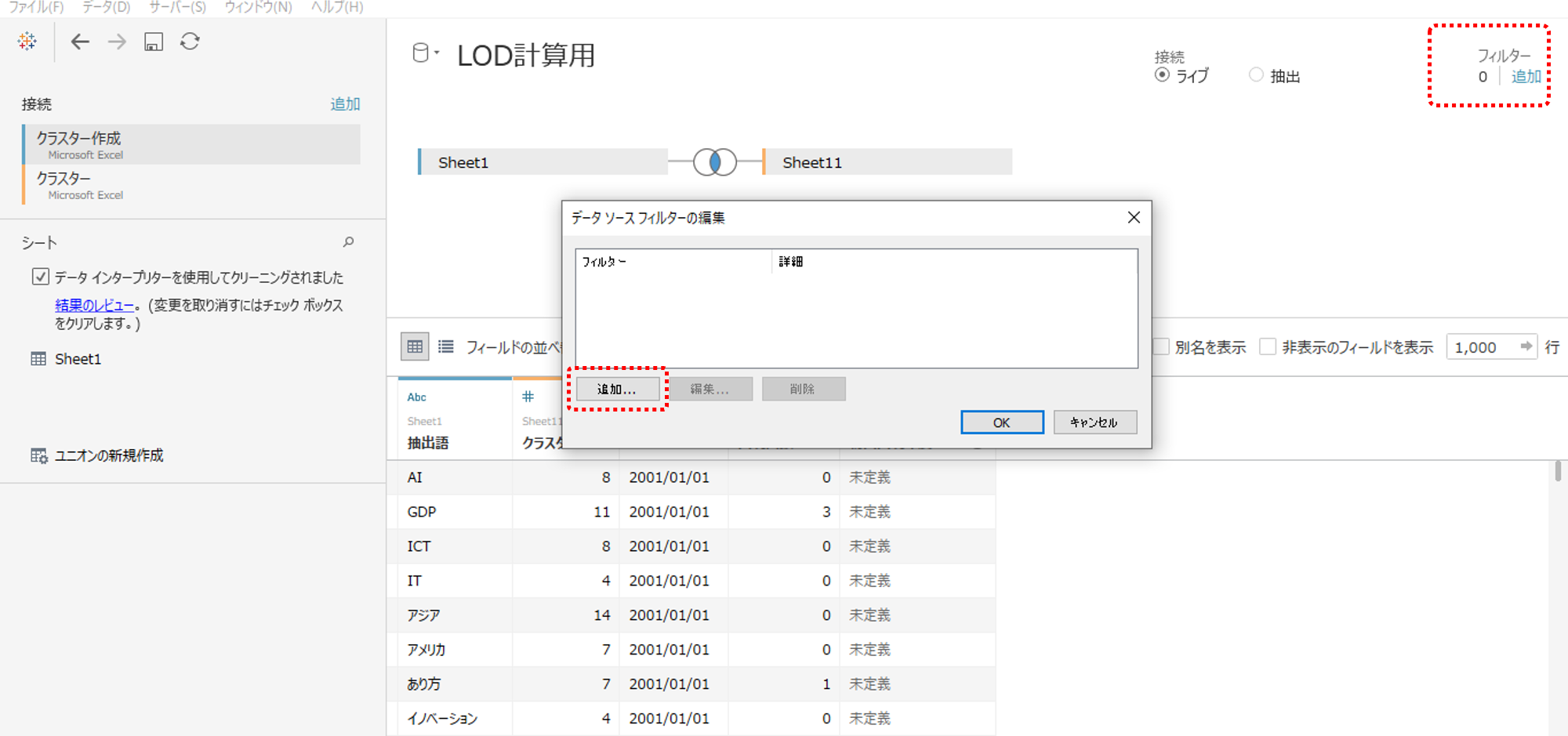
・データ接続ビューへ移動します。
・右上のフィルター追加をクリックします。
。開いた窓の「追加」をクリックします。
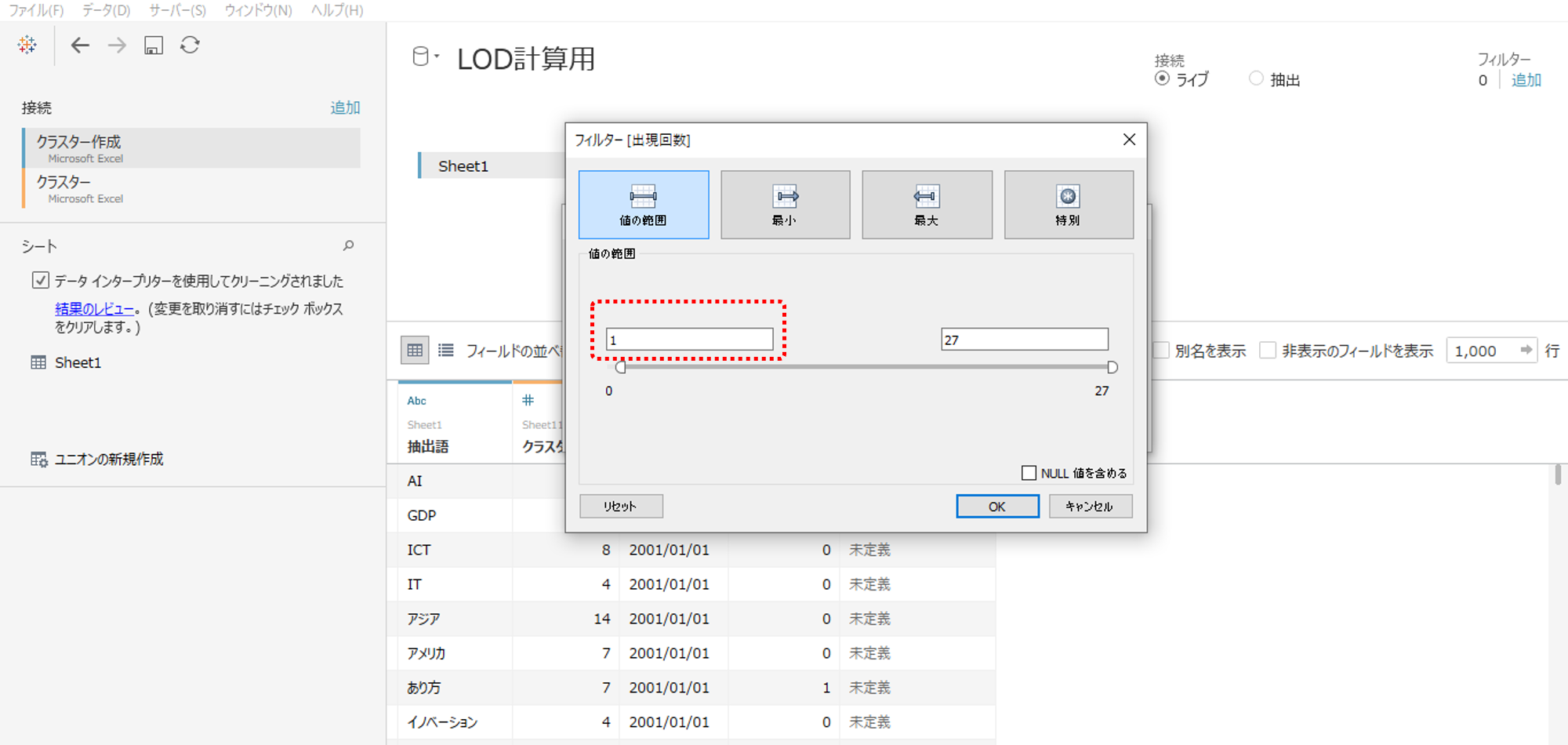
・出現回数フィールドを選択します。
・最小値がゼロになっているところを1へ変更します。
・OKをクリックして窓を閉じれば出現回数ゼロの行データが取り除かれます。
LOD表現とは
表計算とディメンション
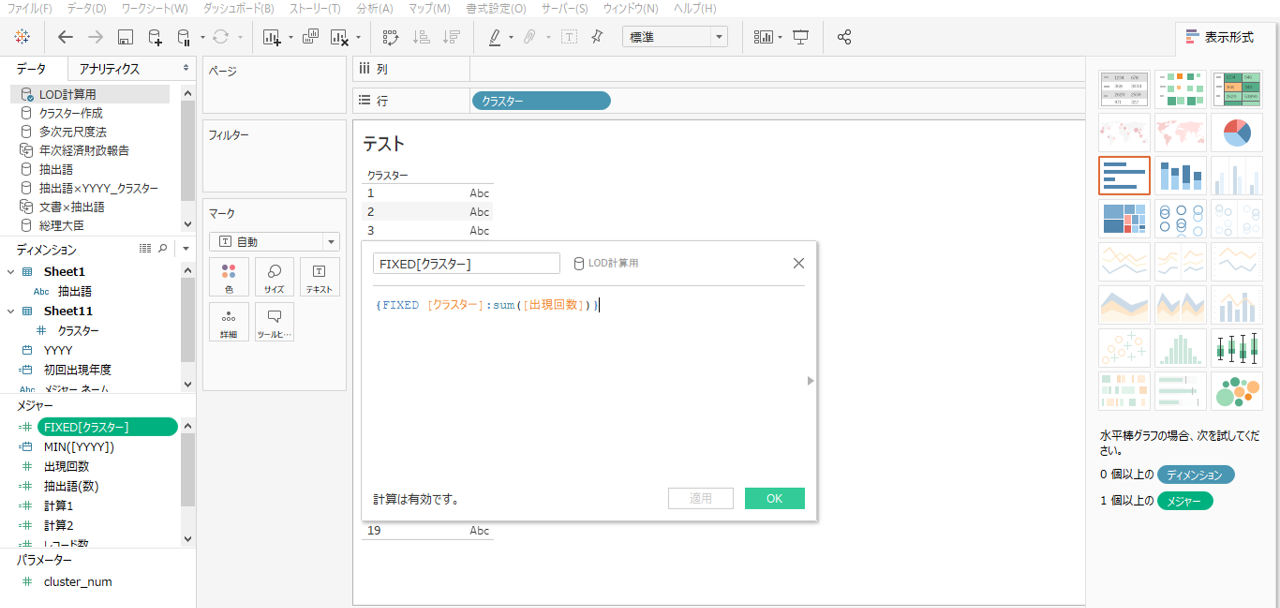
計算式をつくります。
#抽出語の出現回数合計を返す式です
{FIXED [クラスター]:sum([出現回数])}
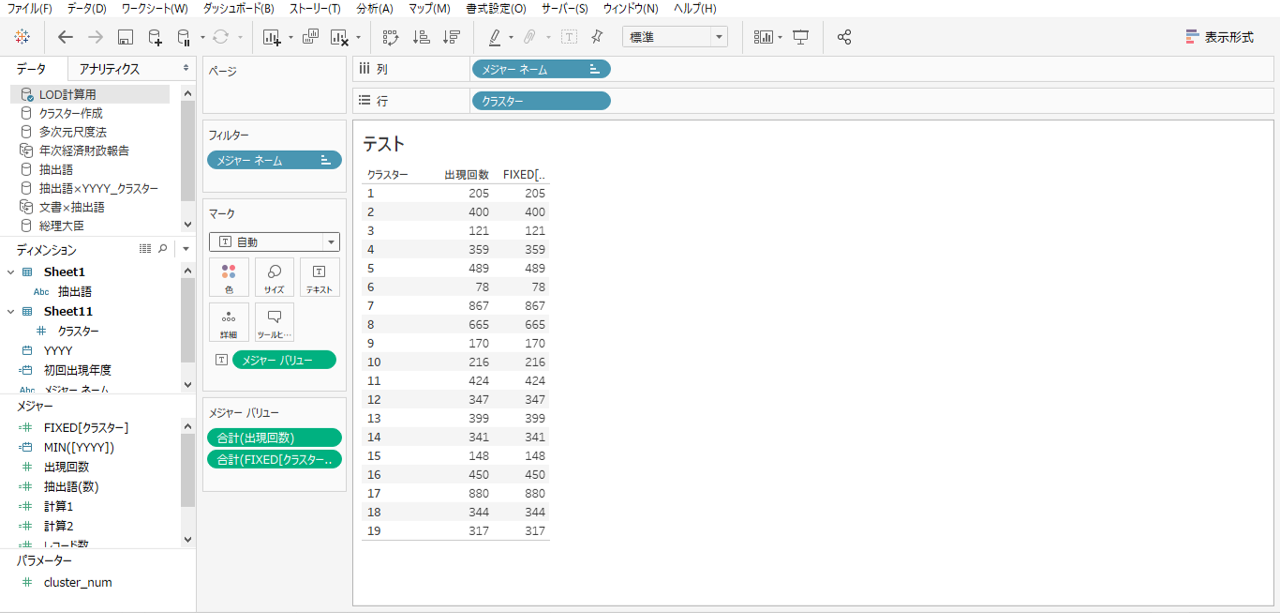
・クラスターを行シェルフへドロップします。
・メジャーの出現回数をLOD計算式の集計結果を表示します。
同一値になります。

・抽出語を行シェルフへ追加します。
ここで不思議なことがおこります。出現回数合計は抽出語の出現回数合計へ数値が変化するのにたいして、LOD計算はクラスター集計のときの数値のままです。
基本的にタブローは表に従って集計します。
ですから表のディメンションがクラスターのときはクラスターごとに集計し、抽出語にかわると抽出語ごとに集計します。
集計の対象になるディメンションを変更することを粒度の変更といいます。
一方、LOD計算は粒度を変更しても計算式で指定したディメンションで集計します。計算式の「FIXED [クラスター]」が粒度を指定し、「sum([出現回数])」が計算方法を指定しているのです。
無関係のディメンションのとき
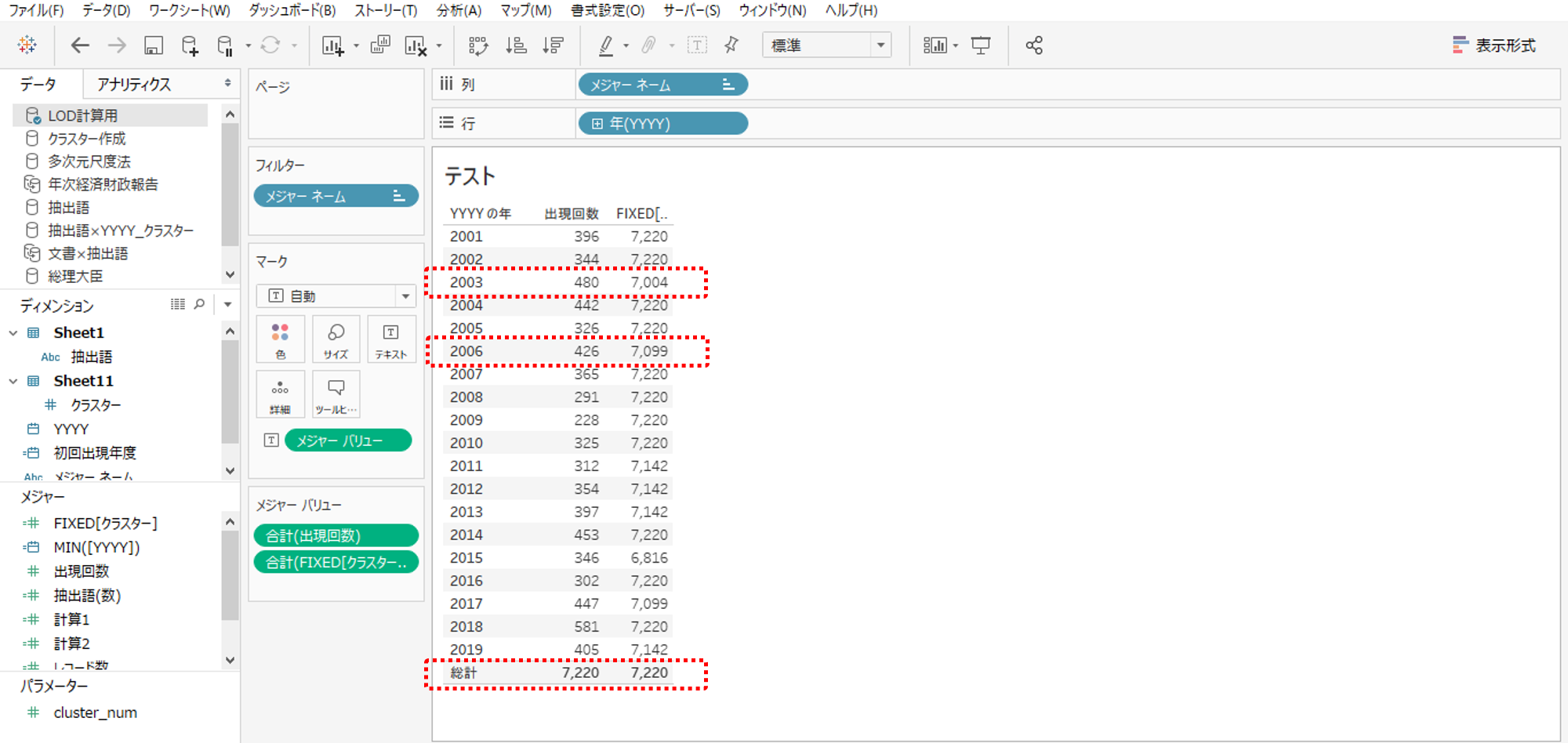
クラスターでも抽出語でもないLOD計算と全く無関係のディメンションで表計算するとどうなるのでしょうか。
・YYYYを行にしました。
一般の集計はYYYYごとに出現回数を集計します。
LOD計算は妙な集計結果になります。表の総計は7,220です。LOD計算の集計はYYYYごとに7,220だったり、そうではなかったりしています。
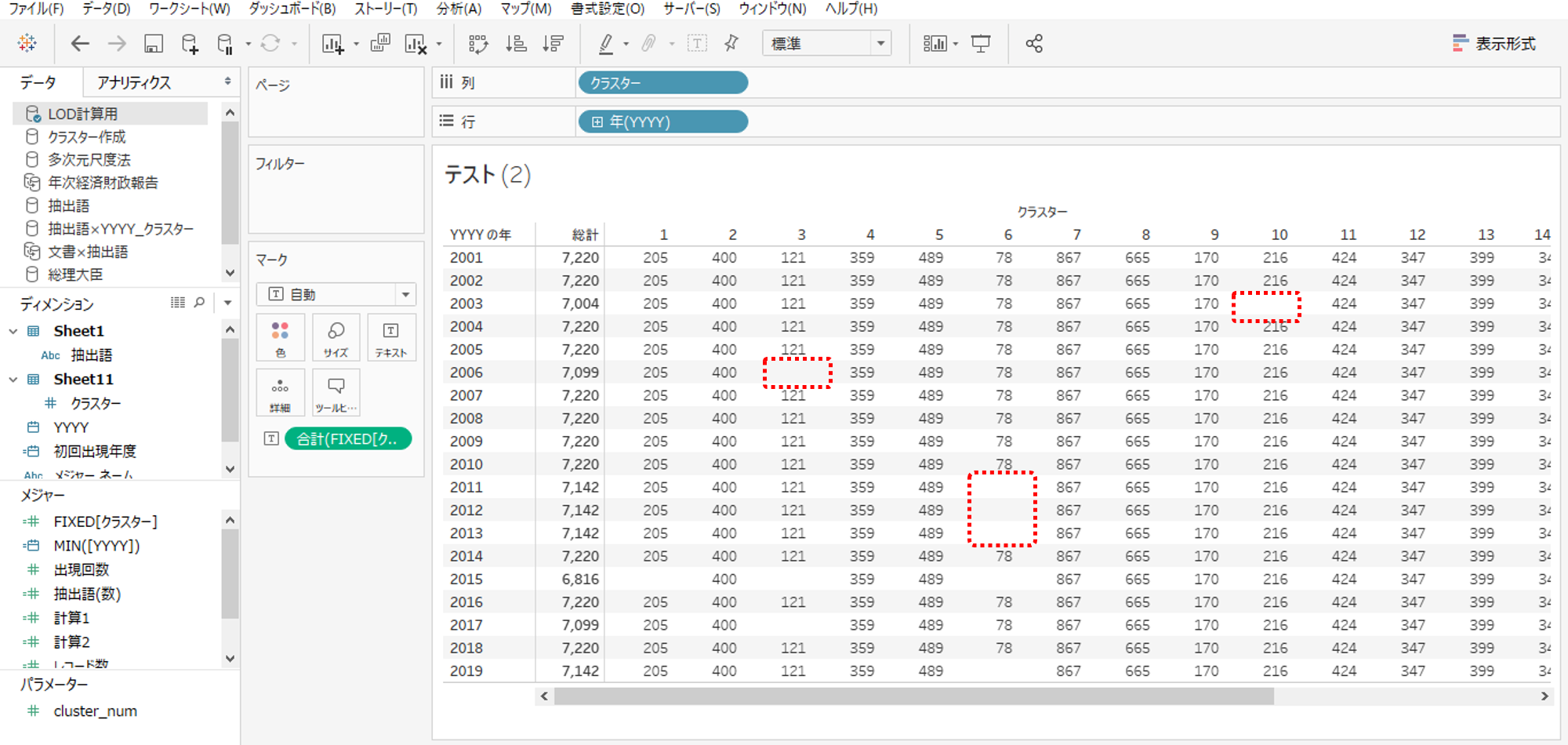
クラスターごとの出現回数がみえるように
・クラスターを列シェルフへドロップします。
2003年度はクラスター10に含まれる抽出語がゼロだから集計結果は7,220にならないわけです。
つまり、無関係のディメンションで表計算してもLOD計算は常にクラスターで集計しているのです。律儀なヤツ。
初出現した年度
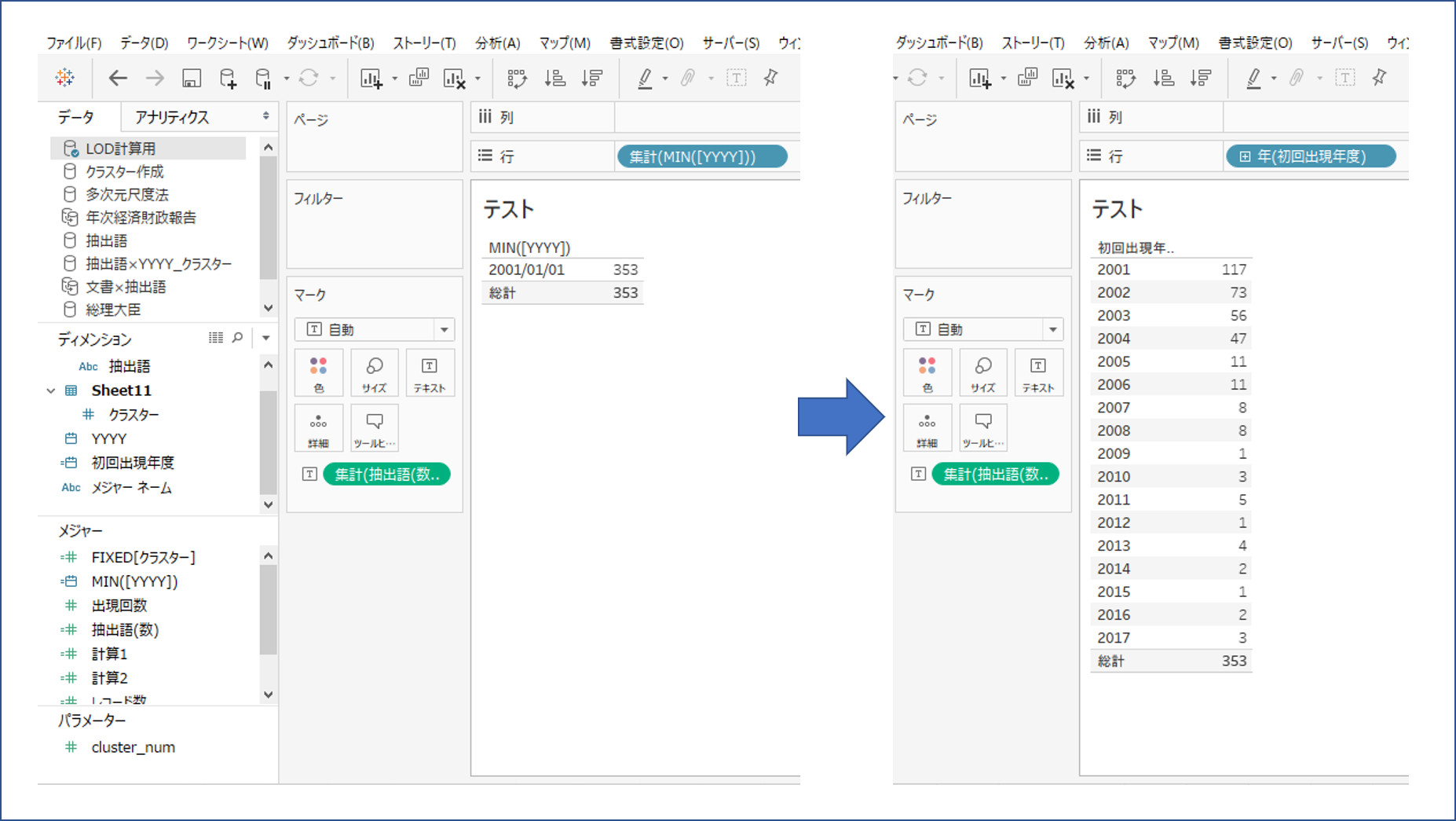
そのようなわけで、単純に計算式「MIN([YYYY])で集計すると画像の左側、LOD計算にすると画像の右側になって出現した初年度を返すことができるのです。
VIZをつくる
初出現から

・YYYYが列シェルフ
・クラスターと抽出語が行シェルフです。
・形状を四角にします。
・色へLOD計算した初回出現年度(不連続)をドロップします。

・レコード数を行シェルフへ追加して
・行合計を左へ表示します。
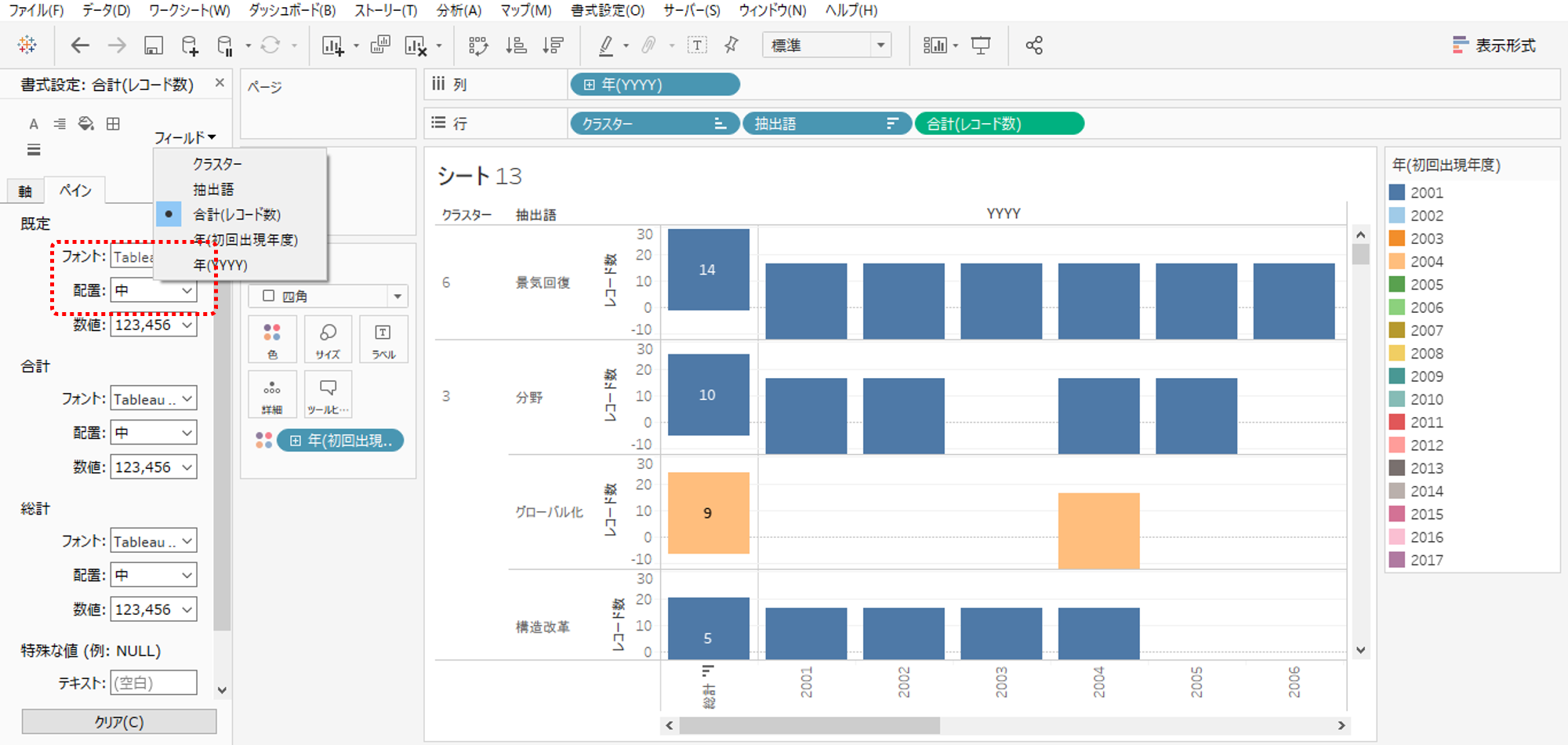
・総計のマークラベルを常に表示するにして
・書式設定のフィールドからレコード数を選択します。
・ペインのタブ、既定のフォントを8、配置を中に設定します。
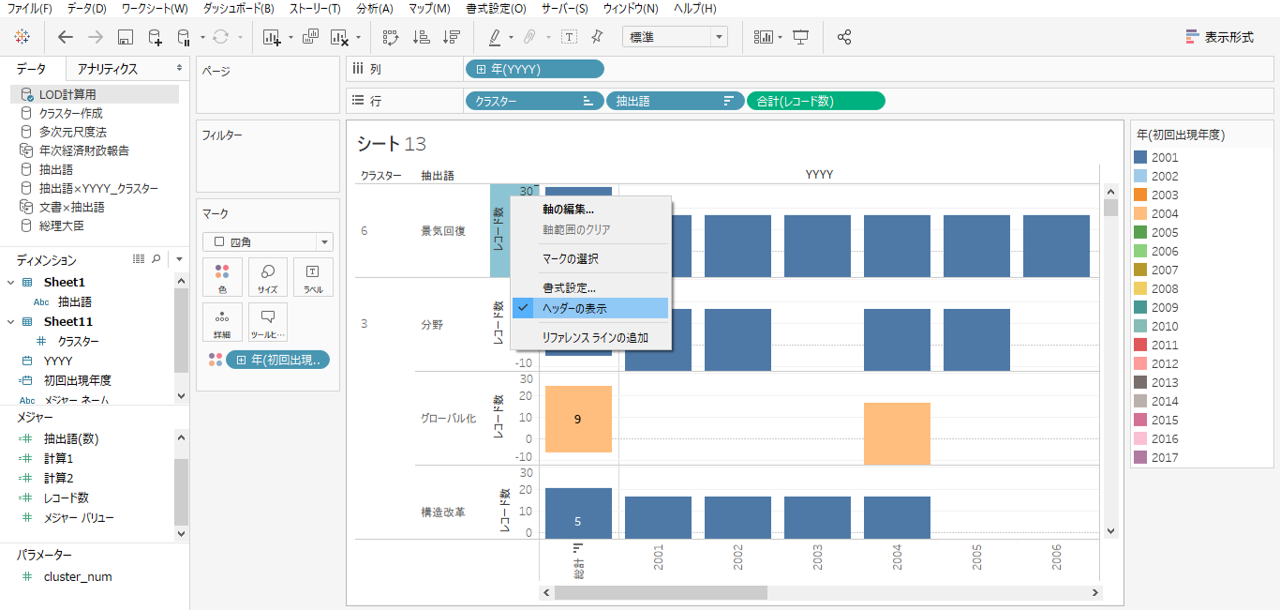
・不要なヘッダーの表示を消します。
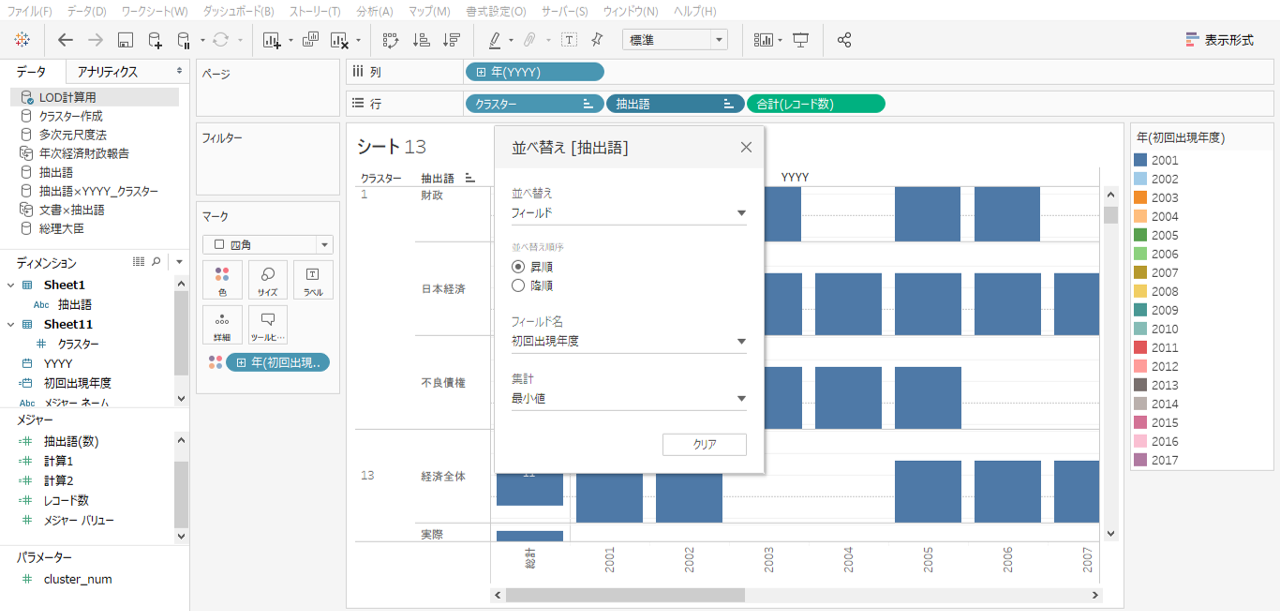
・行シェルフの抽出語を右クリック
・並び替えを選択して
・フィールド、降順、初回出現年度、最小値で並び替えます。
積み上げ棒グラフ

年度ごとに抽出語数をカウントします。出現回数ではありません。
COUNTD([抽出語])
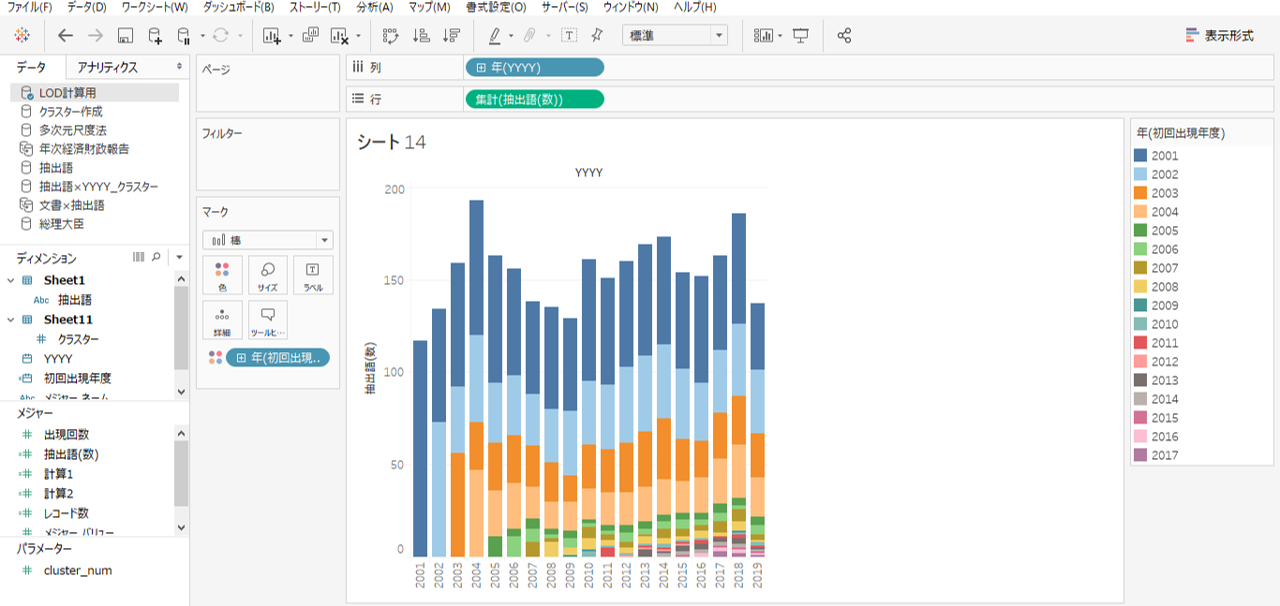
・列シェルフへYYYY
・行シェルフへ抽出語数をドロップします。
・色は初回出現年度です。
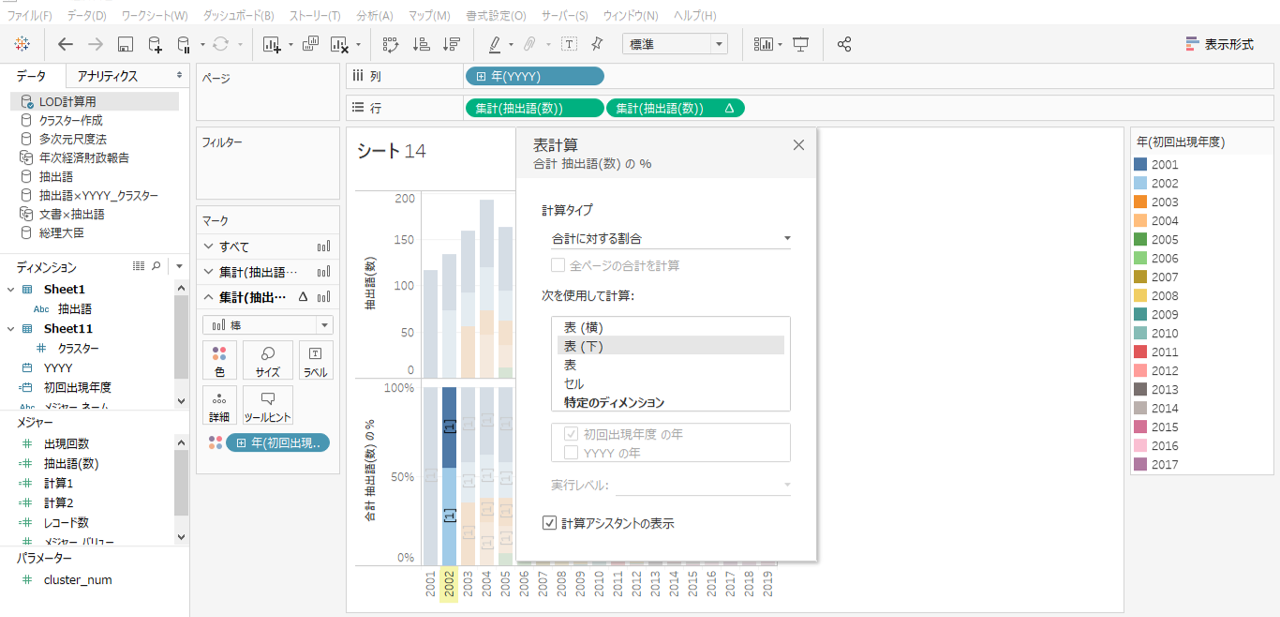
・もう一度、抽出語数を行シェルフへ入れて表計算を追加します。
・表計算は、合計に対する割合、表(下)へ計算します。
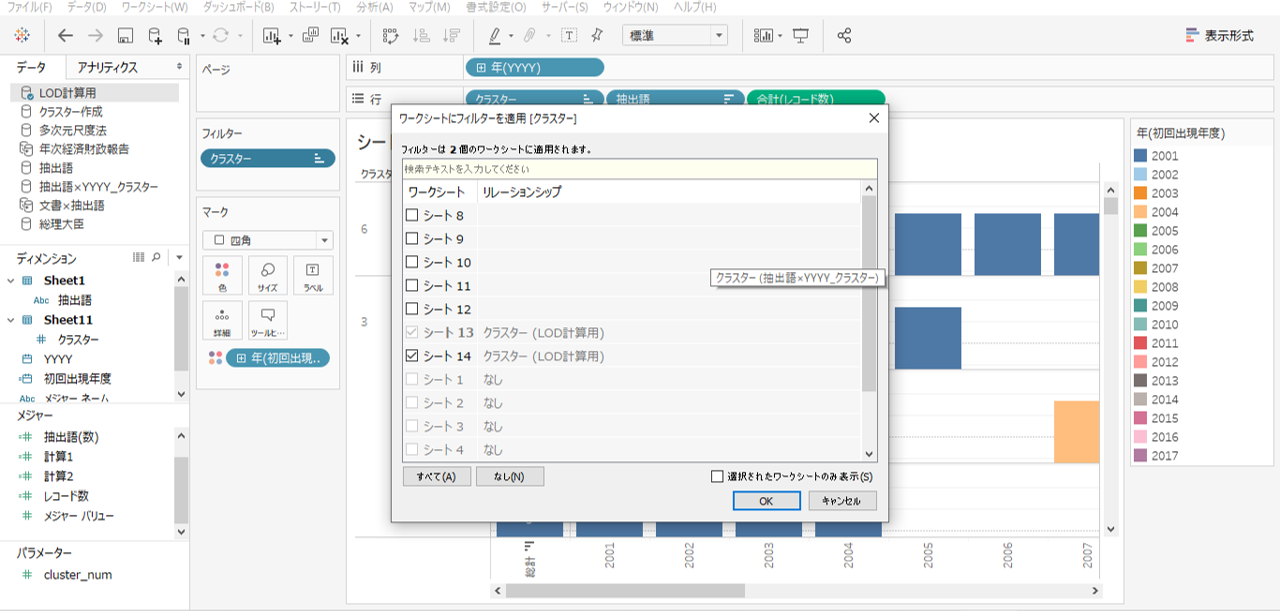
シート14へ戻り、
・クラスターをフィルターペインへ入れます。
・右クリックして、適用先ワークシート→選択したワークシートをクリックします。
・開いた窓のシート14をチェックします。
ダッシュボード
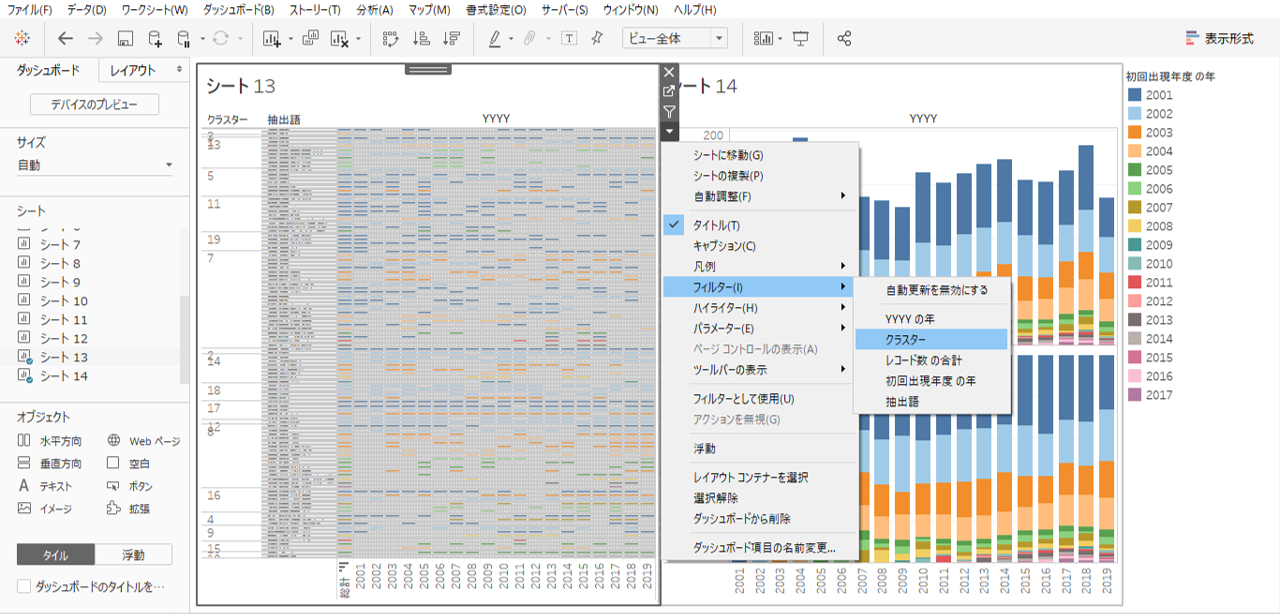
・ダッシュボードへシート13、14をはりつけます。
・シート13の▼をクリックして
・フィルター→クラスターを選択します。
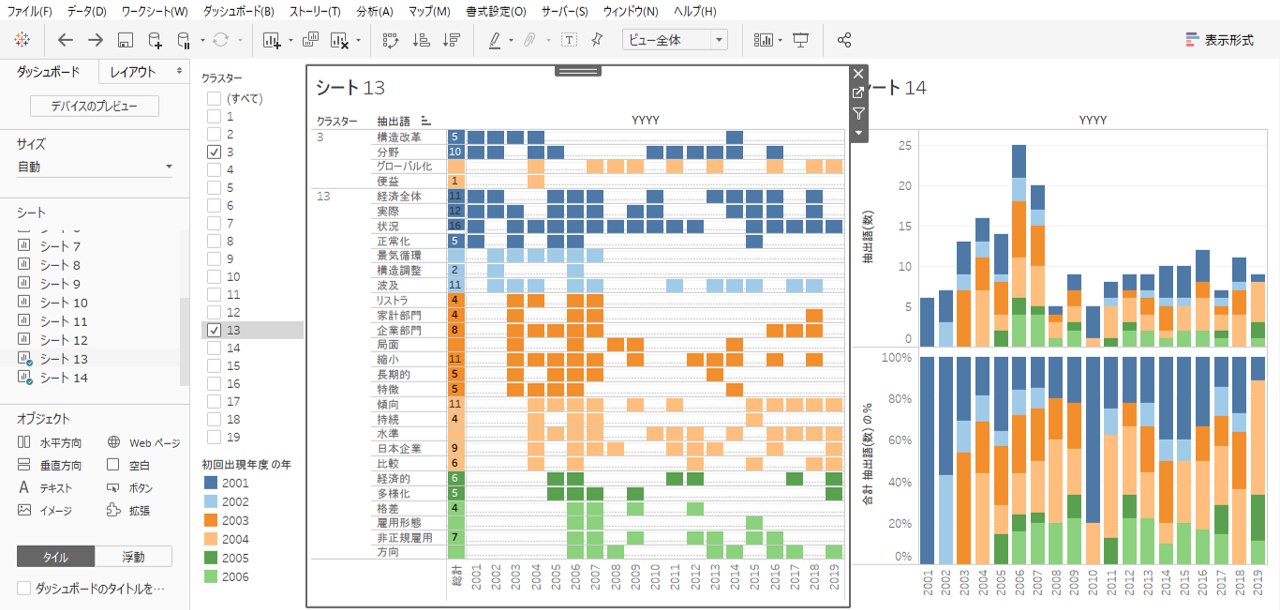
・クラスターフィルターと色の凡例を左側へ配置します。
・フィルターでクラスターを選択します。
シート13から抽出語が初出場した年度とその後の出場履歴がわかります。シート14は古豪と新興の勢力図といったところでしょうか。
このデータは出現回数8回以上、品詞を名詞系に絞っていることをお忘れなく。