
年次経済財政報告(経済財政白書)第3回
テキストマイニングした「語」を出現回数と時間軸でクラスタリング。タブローとRの連携方法も解説しています。
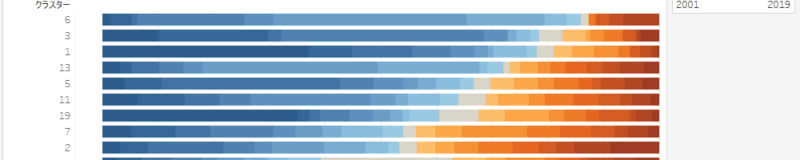
年度と出現回数のクラスタリング
年度と出現回数
前回の投稿では、段落の出現順位(昇順)をidをつかって変数にして、また、抽出語の出現回数をもう一つの変数に設定してPearson(ピアソン)相関係数を算出しました。
そしてPearson相関係数から年度と抽出語のあらわれかたをビジュアル化しました。(年次経済財政報告(経済財政白書)第2回)
今回は、年度と出現回数を変数に設定し、そこからクラスターを形成してVIZを作成してみます。
タブローでクラスター形成
私の記憶ではVer10くらいからでしょうか、タブローにクラスター分析機能が追加されました。この機能をつかえば2軸散布図(変数になるメジャーが2種類)を描きアナリクスペインからクラスターをドロップすることでいとも簡単にクラスター分析をおこなうことができます。ただし変数になるメジャーが2種類のときに限られます。
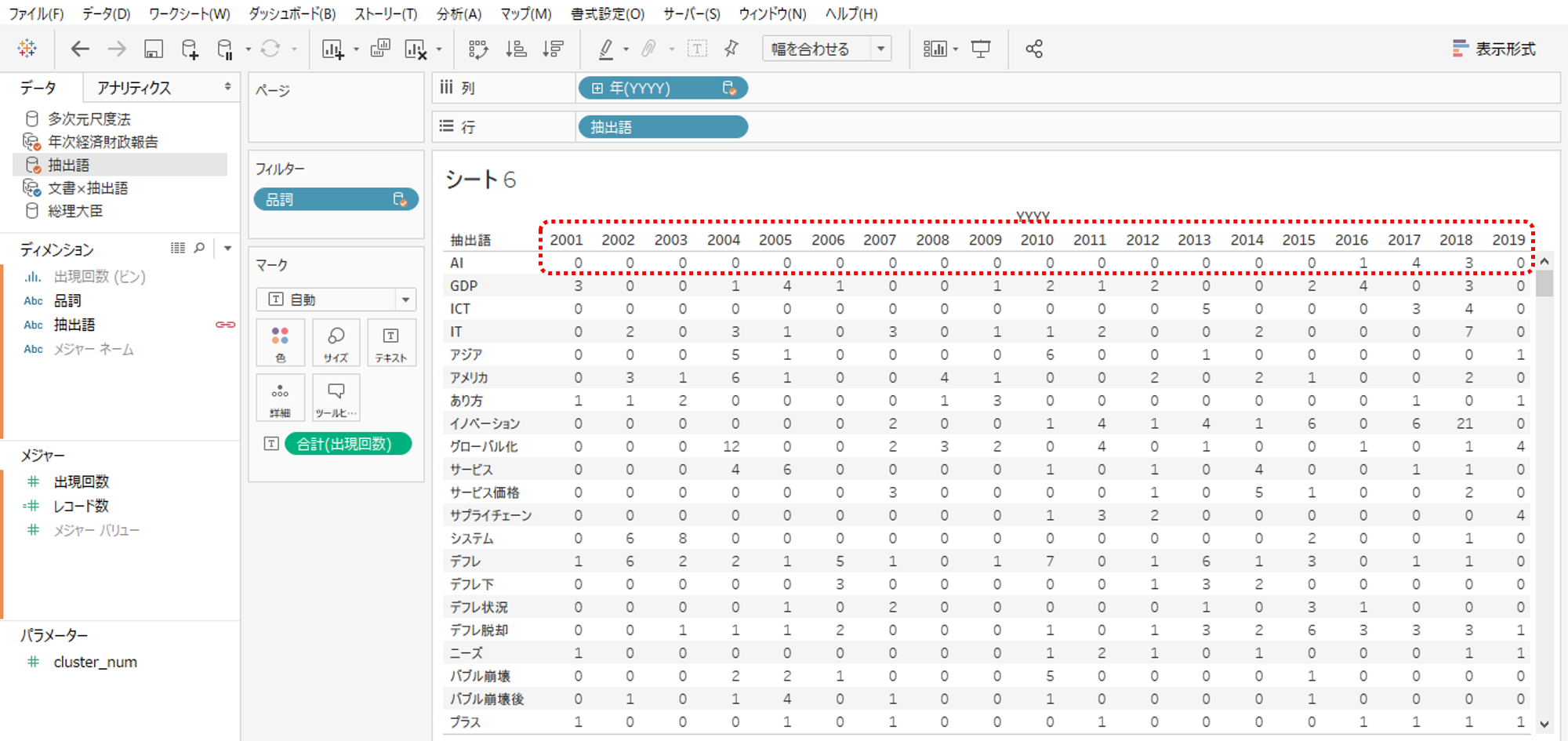
しかし諦めることはありません。タブローのR連動機能をつかえば3種類以上のメジャーからクラスターを形成することができるのです。仕組みは画像のように抽出語ごとに2001年度から2019年度までの出現回数を横方向に計算してクラスタリングします。
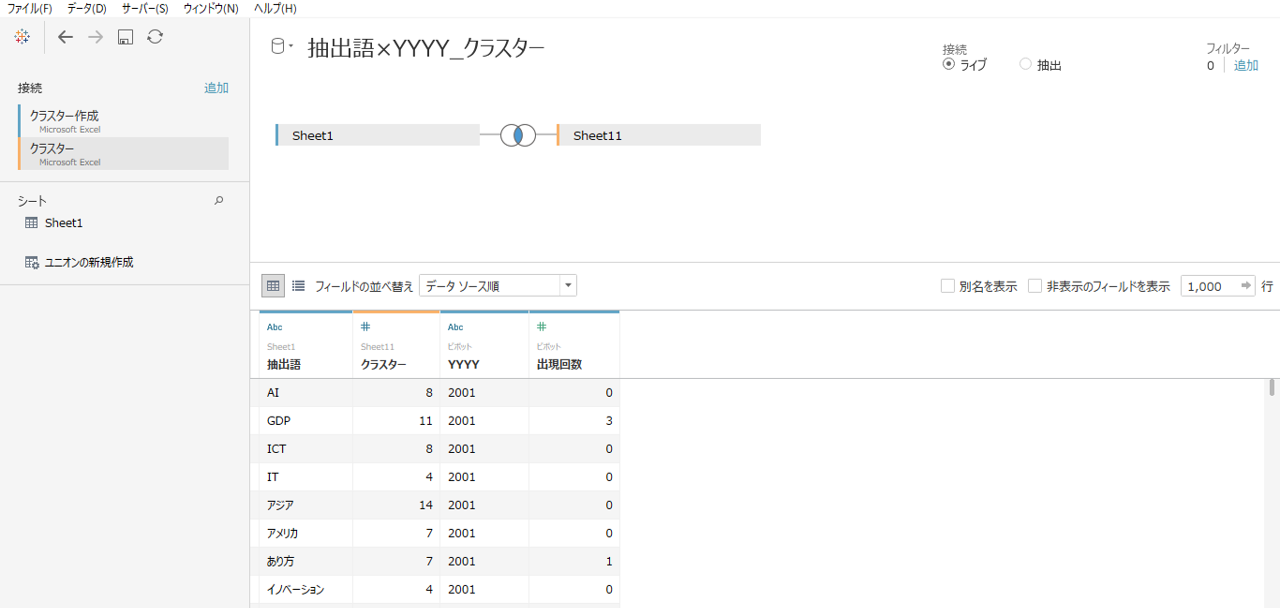
まず、マトリクス表をつくります。
・「文書×抽出語」データソースから抽出語を行シェルフへ投入します。
・「年次経済財政報告書」データソースから年度(YYYY)を列シェルフへドロップします。
今回も名詞系(「名詞」「サ変名詞」「固有名詞」「地名」「未知語」「タグ」)を分析対象するため、
・「抽出語」データソースの品詞でフィルタリングします。
これで各抽出語がどの年度の何回出現したのかをあらわすマトリクスの完成です。
ところが、いまのところ横軸が年度ですからディメンションであり変数になりうるメジャーではありません。年度をクラスター分析用の変数としてつかうためには、各年度それぞれを別々のメジャーへ変換する必要があります。
データソースをつくる
表からエクセルデータソースをつくります。
・「ワークシート」→「エクスポート」→「Excelへのクロス集計」を選択します。
エクセルが自動で立ち上がります。
・ディレクトリへ名前をつけて保存します。
・名前は「クラスター作成」にしました。
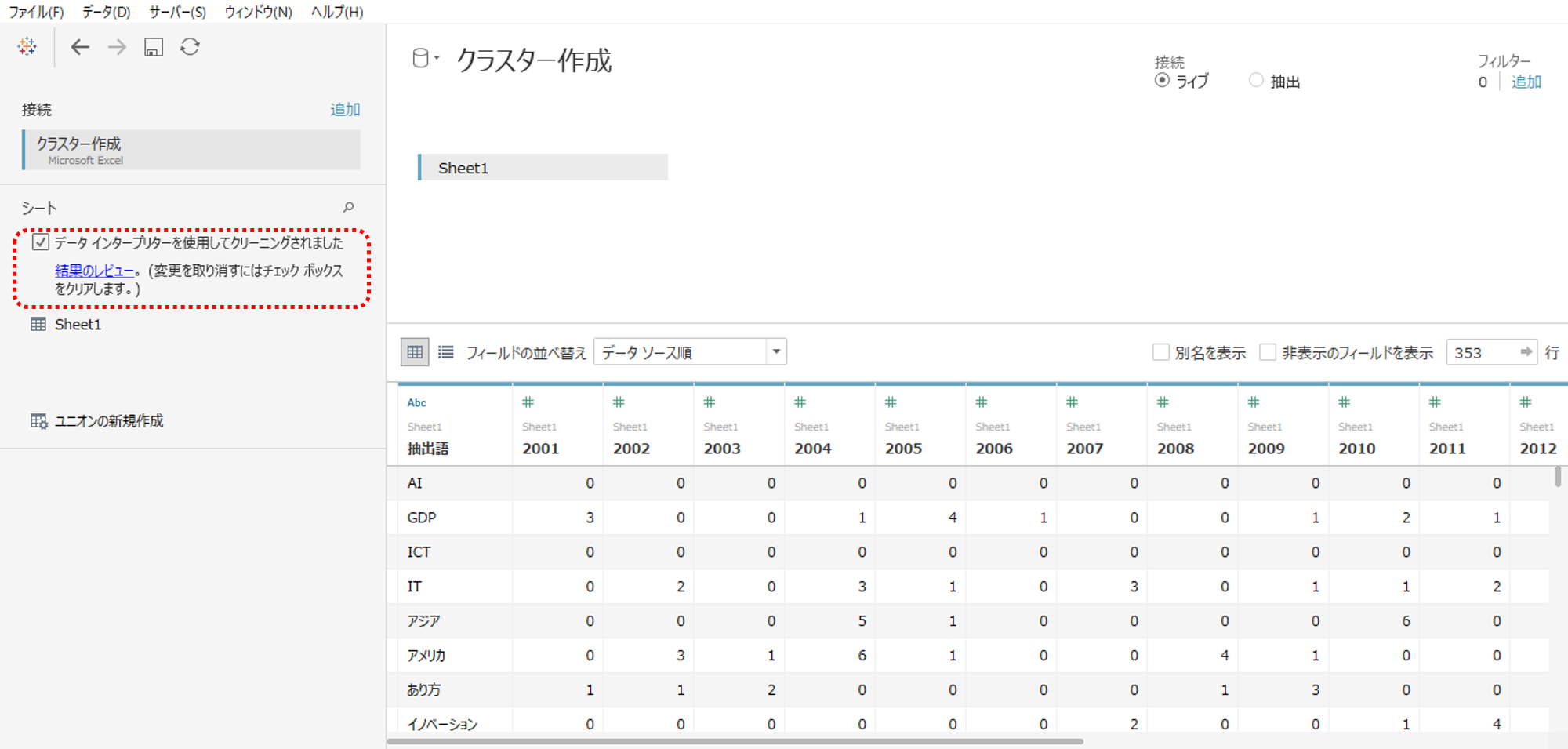
タブローから「クラスター作成」データソースへ接続します。
データソースの1行目のセルが結合されているので、
・データインタープリターをチェックして接続します。
・各年度列のデータ形式は数値のままでOKです。
タブローとRの連動
Rへ計算式を送る
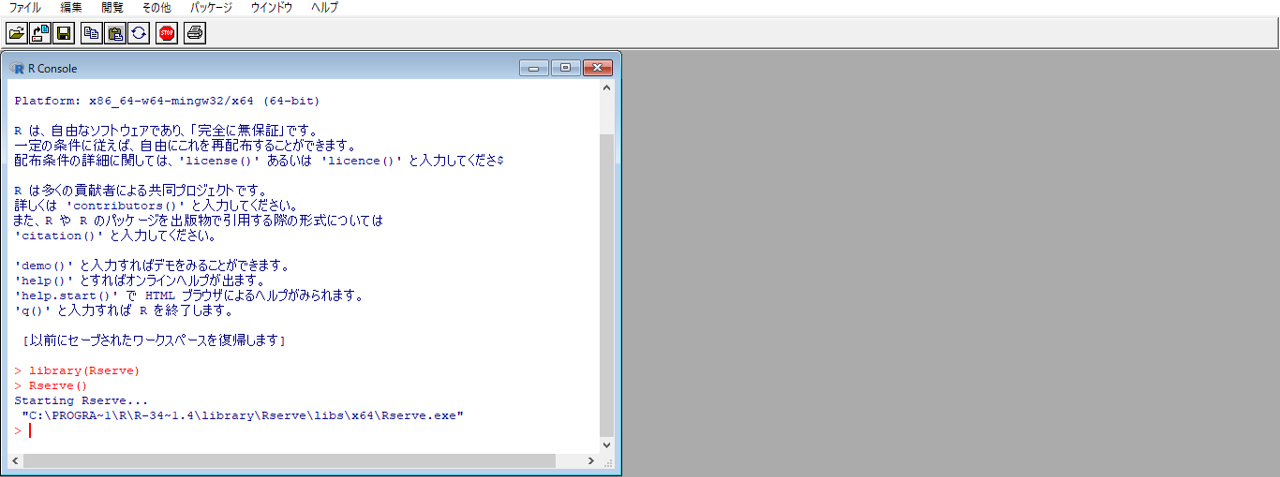
Rを起動します。
#Rのコマンド library(Rserve) Rserve()
パッケージRserveがないときはインストールしてください。パッケージをインストールするときは、Rを管理者モードで起動します。
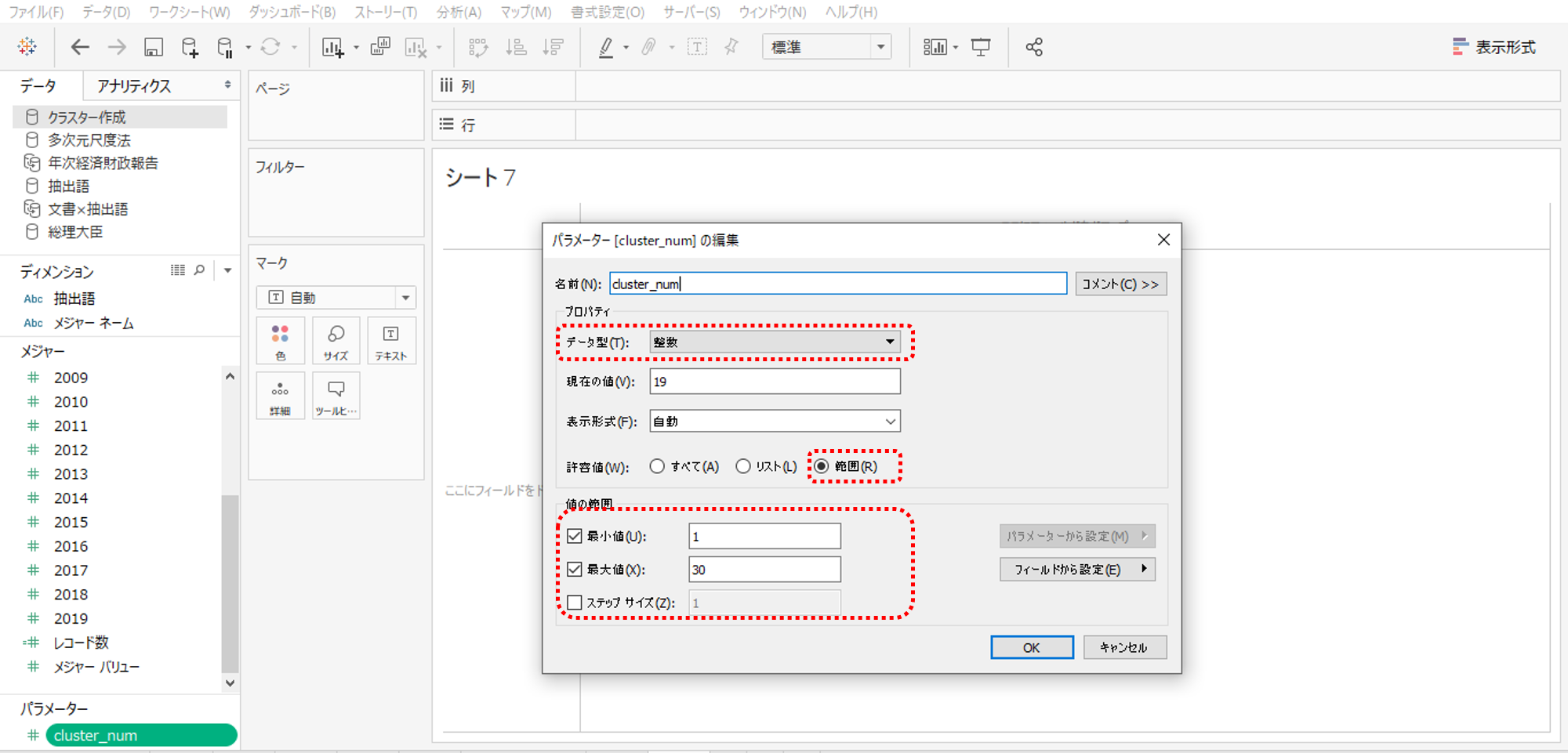
タブローでパラメーターを作成します。
・データ型=整数
・許容値=範囲、最小値=1、最大値=30、ステップサイズ=1です。
このパラメーターでクラスター数を指定して調整します。つまり今回の分析はスラスター数をあらかじめ指定する非階層的クラスター分析です。
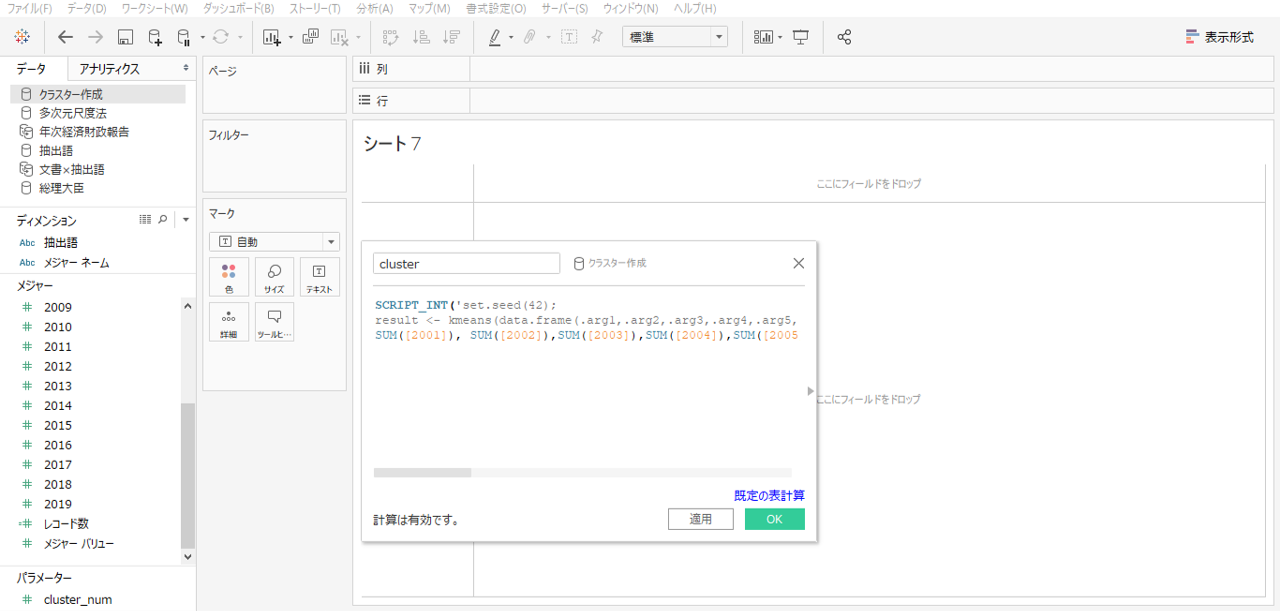
データソースはクラスター作成です。
Rへ送る計算式をつくります。Rで処理する関数は非階層的クラスター分析「kmeans」です。
#計算式
SCRIPT_INT('set.seed(42);
result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4,.arg5,.arg6,.arg7,.arg8,.arg9,.arg10,.arg11,.arg12,.arg13,.arg14,.arg15,.arg16,.arg17,.arg18,.arg19),.arg20[1]);result$cluster;',
SUM([2001]), SUM([2002]),SUM([2003]),SUM([2004]),SUM([2005]),SUM([2006]),SUM([2007]),SUM([2008]),SUM([2009]),SUM([2010]),SUM([2011]),SUM([2012]),SUM([2013]),SUM([2014]),SUM([2015]),SUM([2016]),SUM([2017]),SUM([2018]),SUM([2019]),[cluster_num])
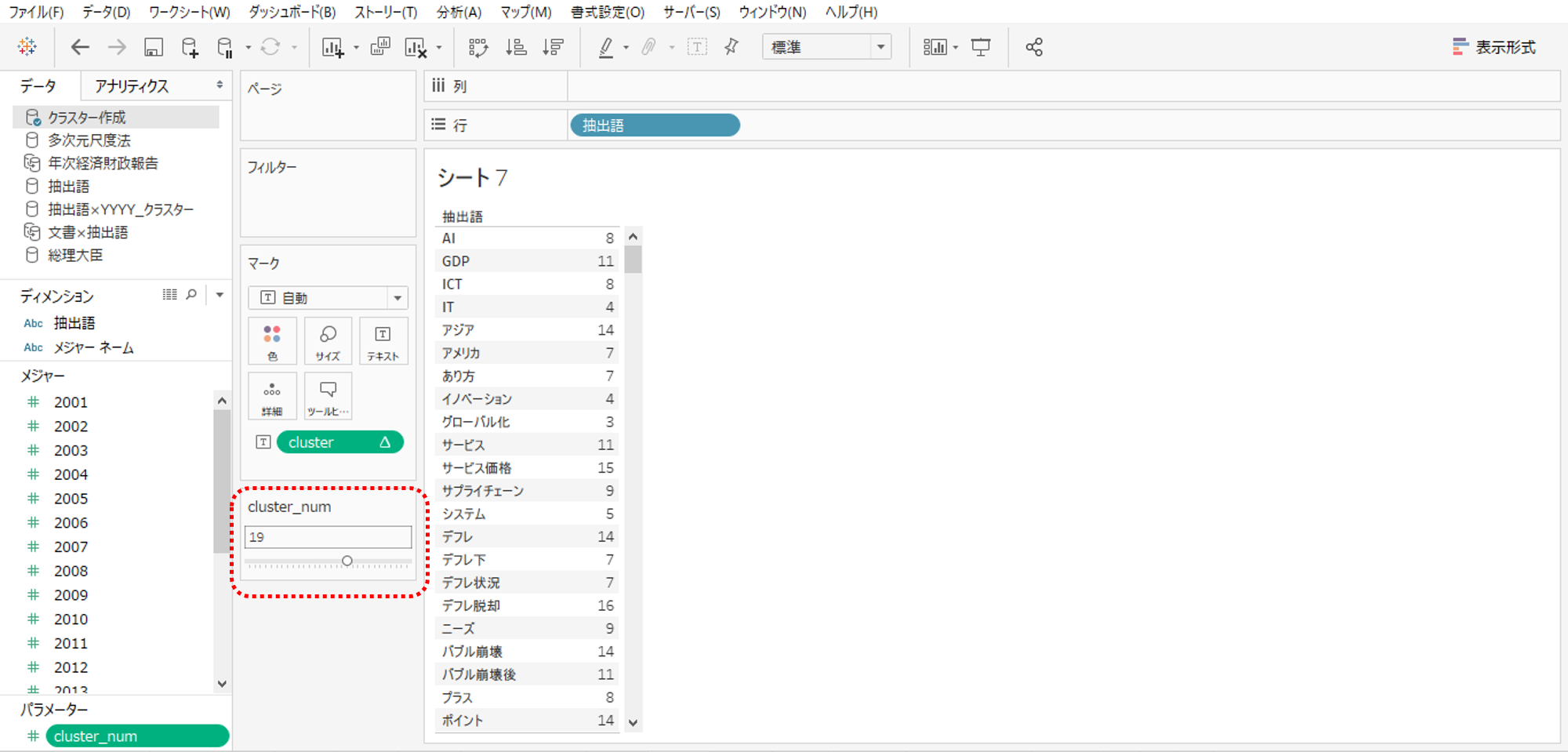
データソースは「クラスター作成」です。
・列シェルフへ抽出語をドロップしてクラスター計算式をマークへ入れます。
・Rで計算されたクラスターが返ってきます。
・パラメーターコントロールを表示してクラスター数を調整します。
・今回は年度が2001年から2019年まで19あるので19にしてみました。
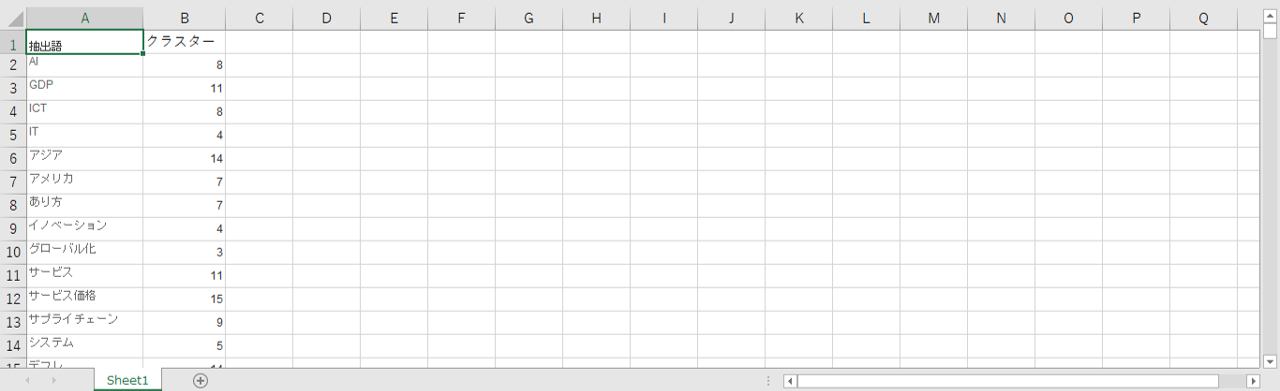
タブローへRで計算されたクラスターが返ってくるもののこれは先述したよ通り横方向計算した結果です。
従ってこの表が崩れると計算結果がRから返ってこなくなります。
例えばこの状態で行列を入れ替えるとクラスター計算はできません。各種VIZを作成する際に抽出語とクラスターとの関係を常に維持したいのでこの表をエクセルでエクスポートします。手っ取り早い手法です。
再度データをつくる
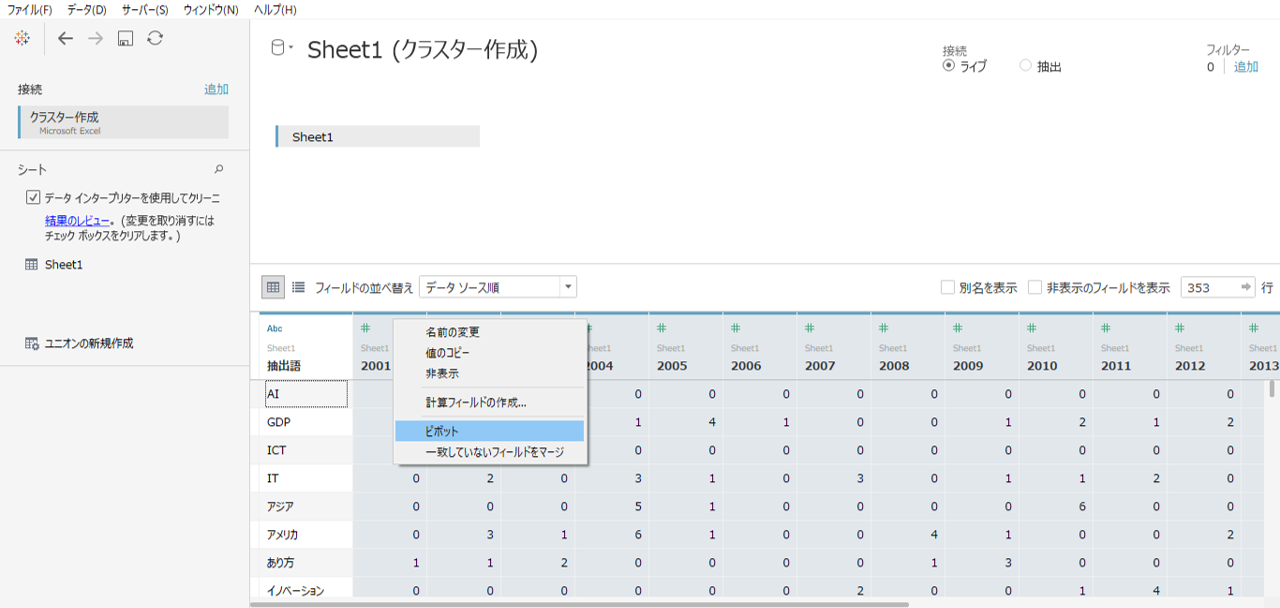
クラスターをつくるたに接続した「クラスター作成」データソースへ別データで再接続します。
・年代に相当する2001~2019をピボットします。
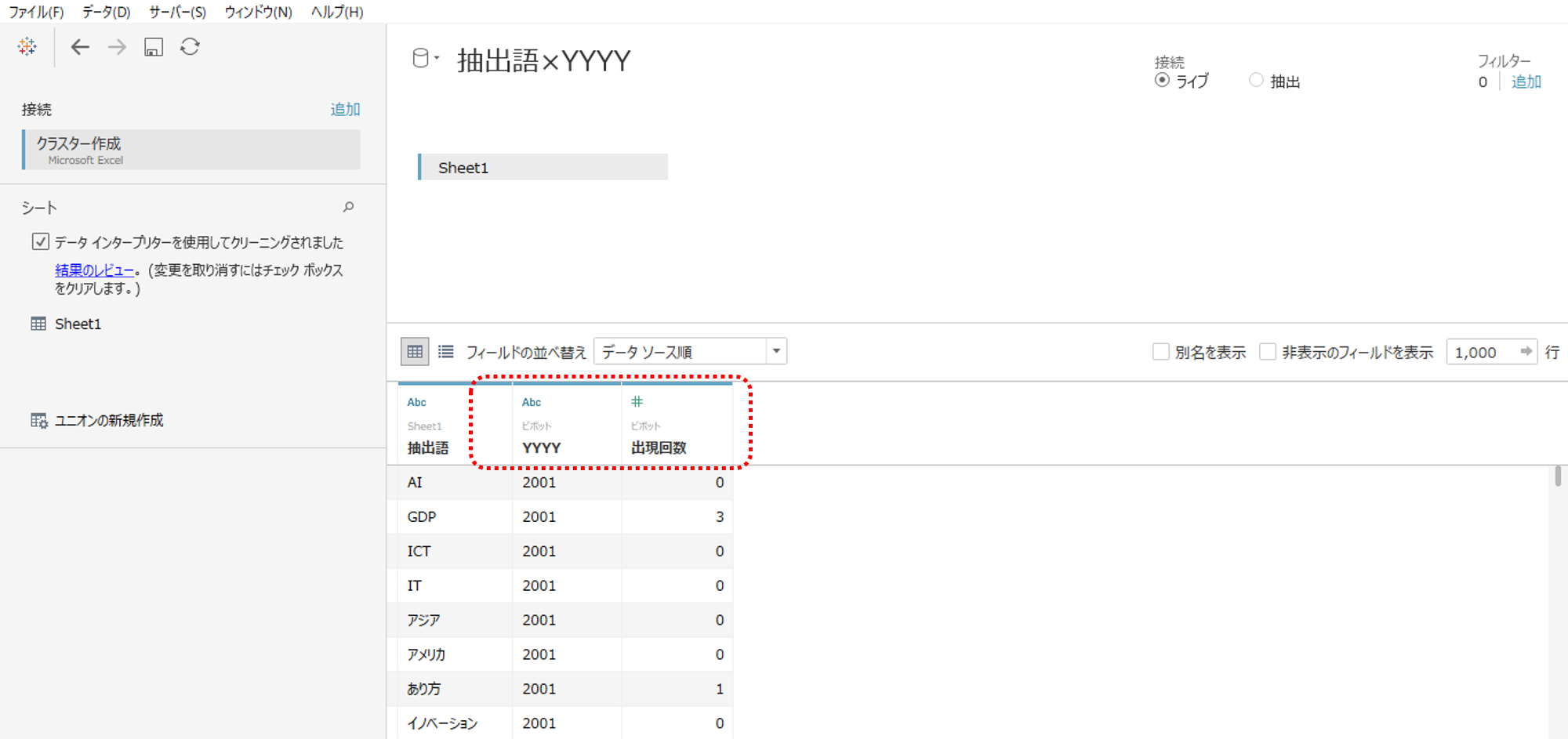
・フィールド名(列名)を書き換えます。
・YYYYはデータ形式を日付へ変更します。
・エクセルへエクスポートしたクラスターのデータと結合します。
・結合句は「抽出語」
・結合のタイプは「内部」です。
VIZをつくる
年度と出現回数
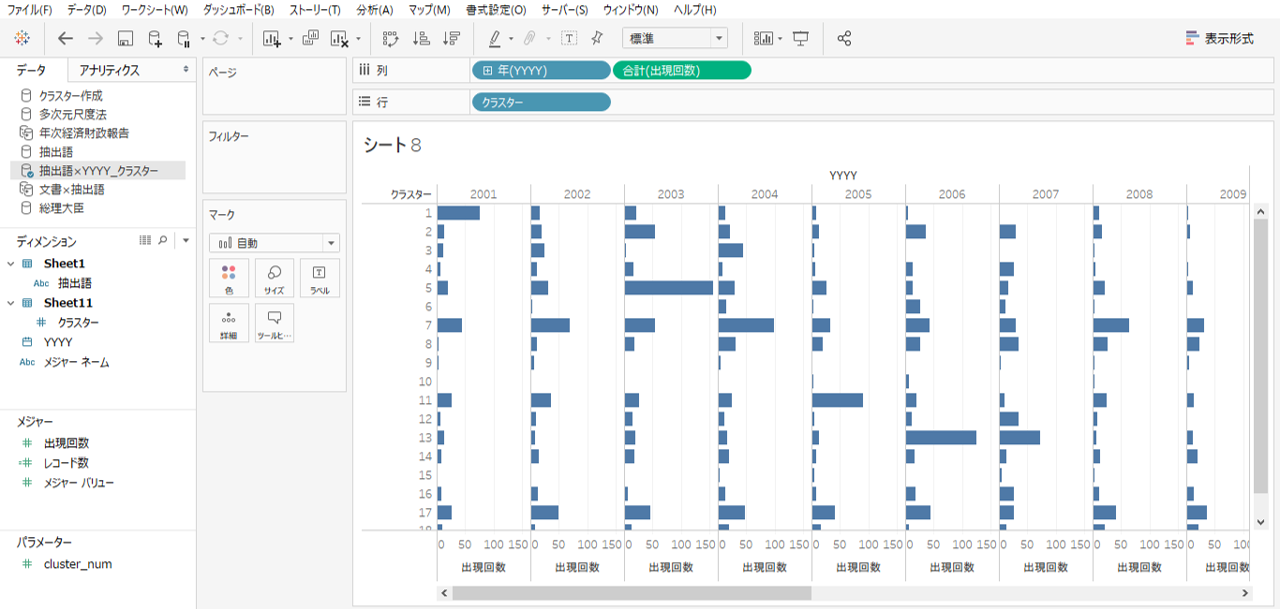
・YYYYと出現回数を列シェルフへ
・クラスターを行シェルフへ入れます。
各クラスターに含まれる抽出語の年度別出現回数を確認することができます。
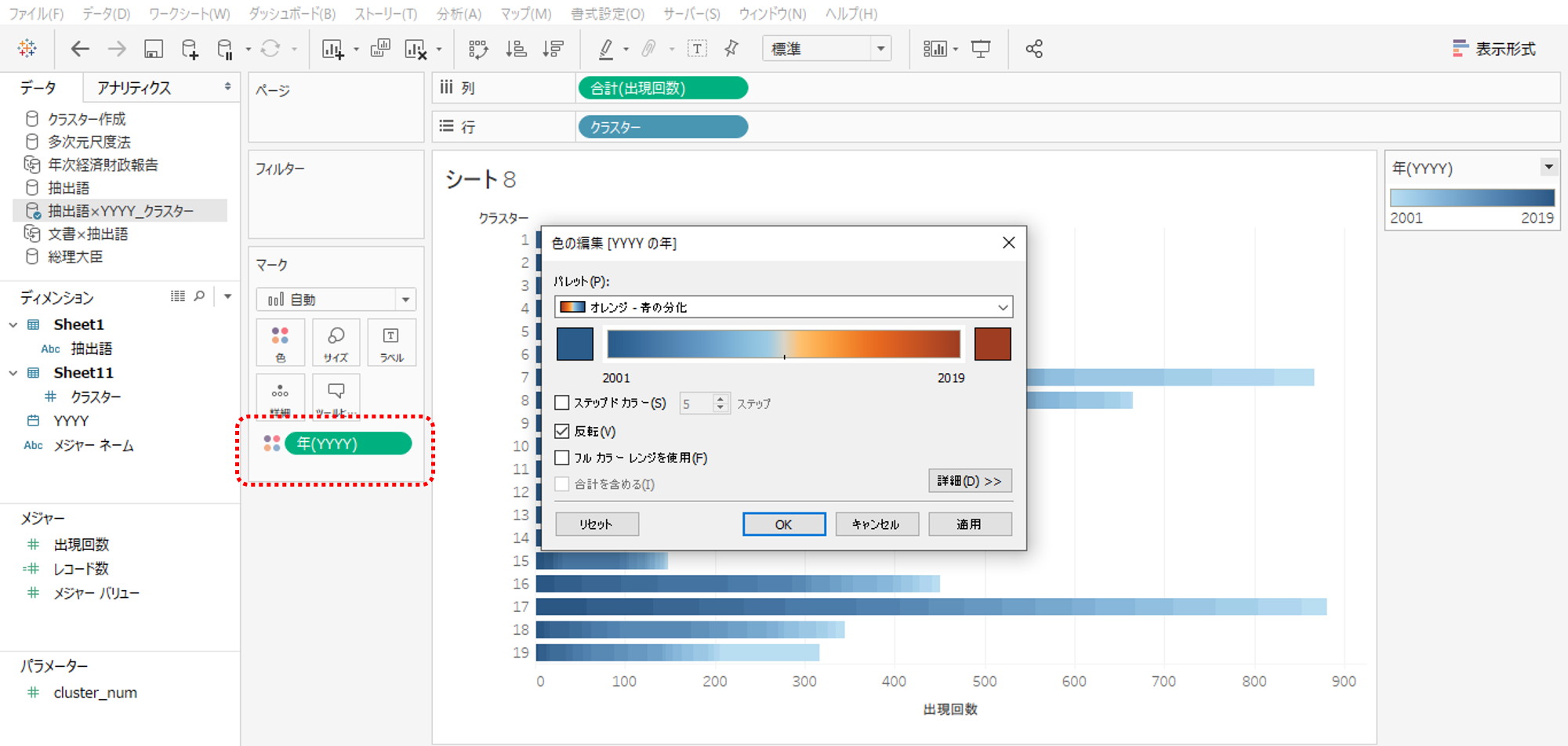
・YYYYを列シェルフから色へ移動します。
・YYYYを移動すると「不連続」の日付になっているの「連続」へ変更します。
色は前回に倣い2001年度寄りをブルー、2019年度寄りをオレンジに設定しました。
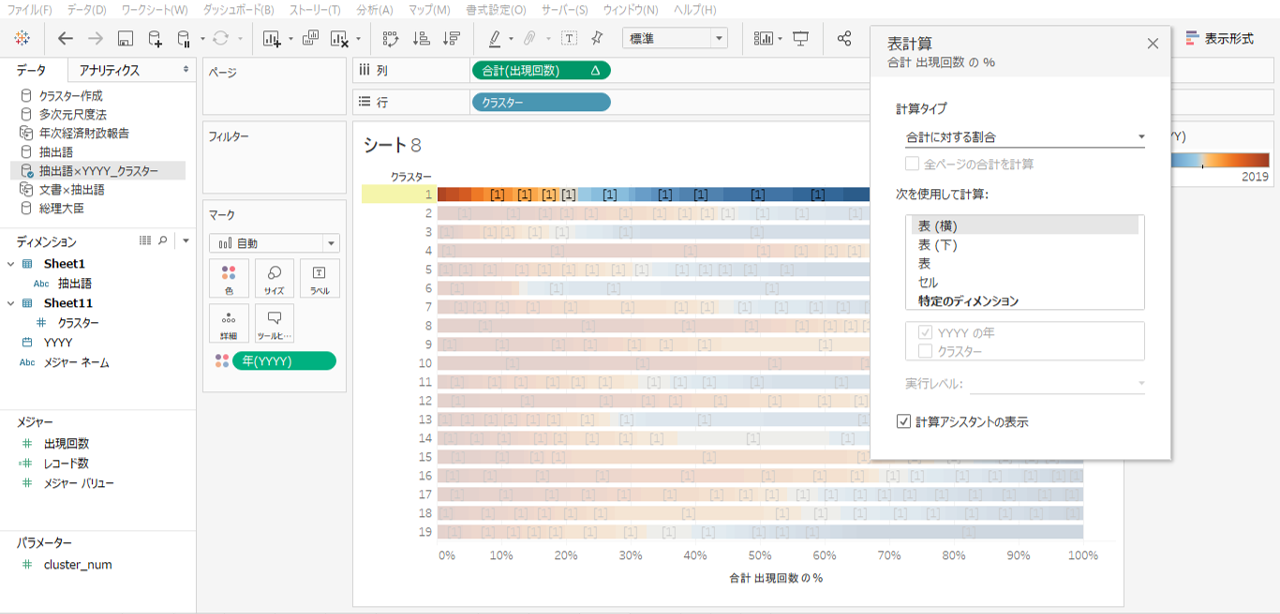
・出現回数へ表計算を追加します。
・合計に対する割合、表(横)です。
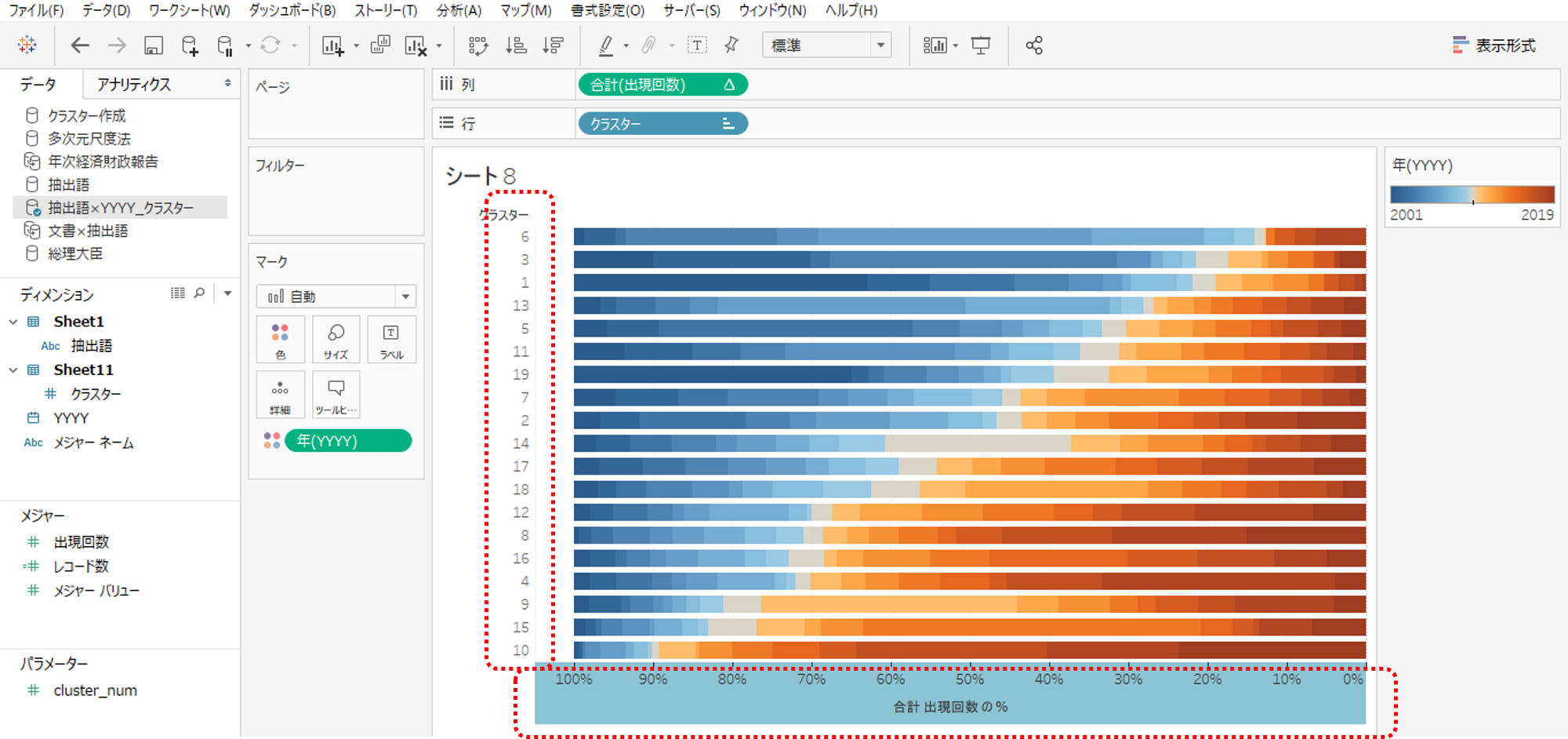
連続した年(日付)を反転とか並び替えとかすることができないので横軸を反転します。年(日付)ではなくて数値にしておけばよかった。
クラスターも並べ替える手段がないため、手動でなんとなく並べ替えました。2001年度寄りに多く出現する抽出語を含むクラスターから2019年度寄りに多く出現する抽出語を含むクラスターが形成されていることがわかります。
ツリーマップ
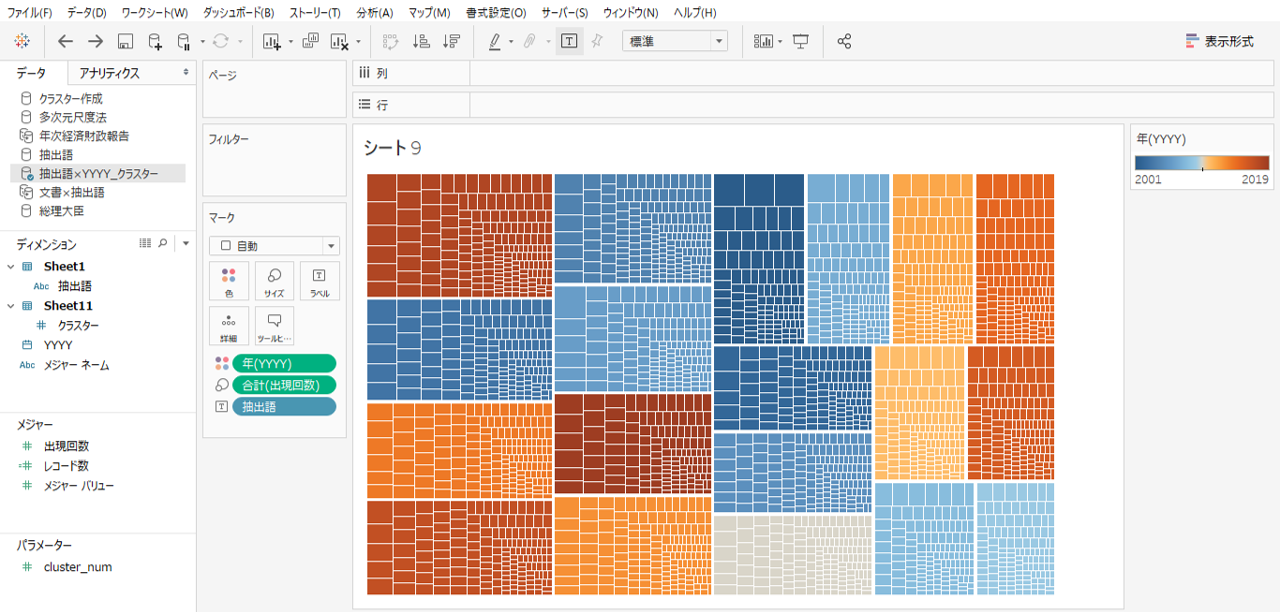
ツリーマップをつくります。ツリーマップはデンドログラム(樹形図)とは別物です。
・YYYYを色
・出現回数をサイズ
・抽出語をラベルへドロップします。
出現回数棒グラフ
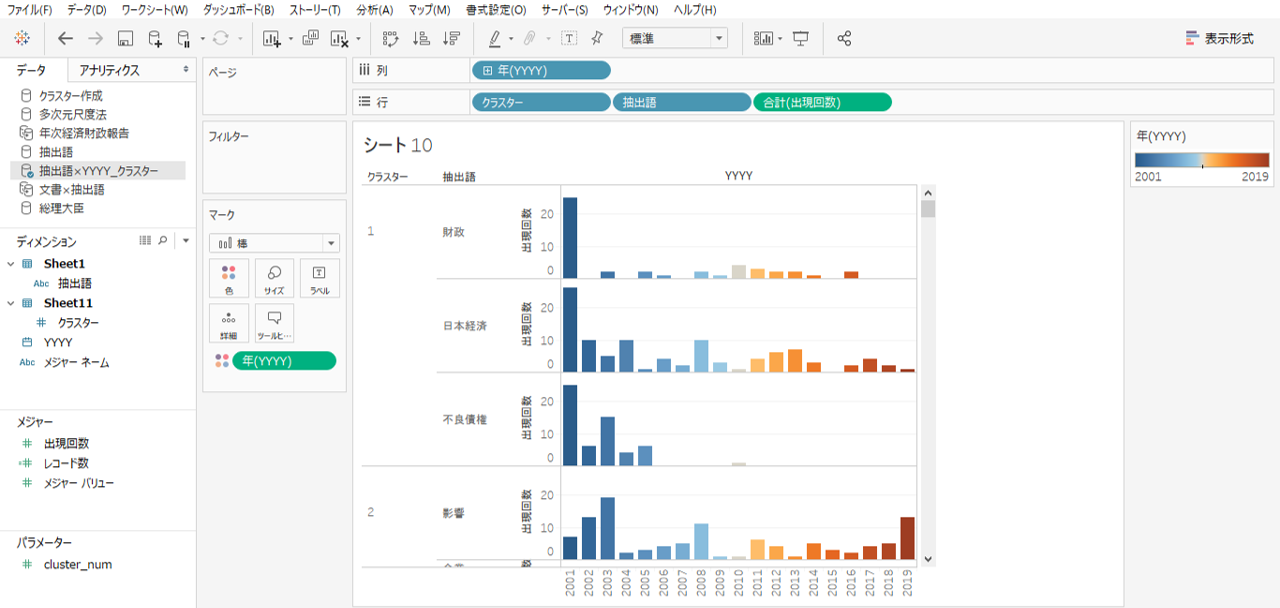
・列シェルフへYYYY
・行シェルフへクラスター、抽出語、出現回数を入れます。
・色はYYYY(連続)です。
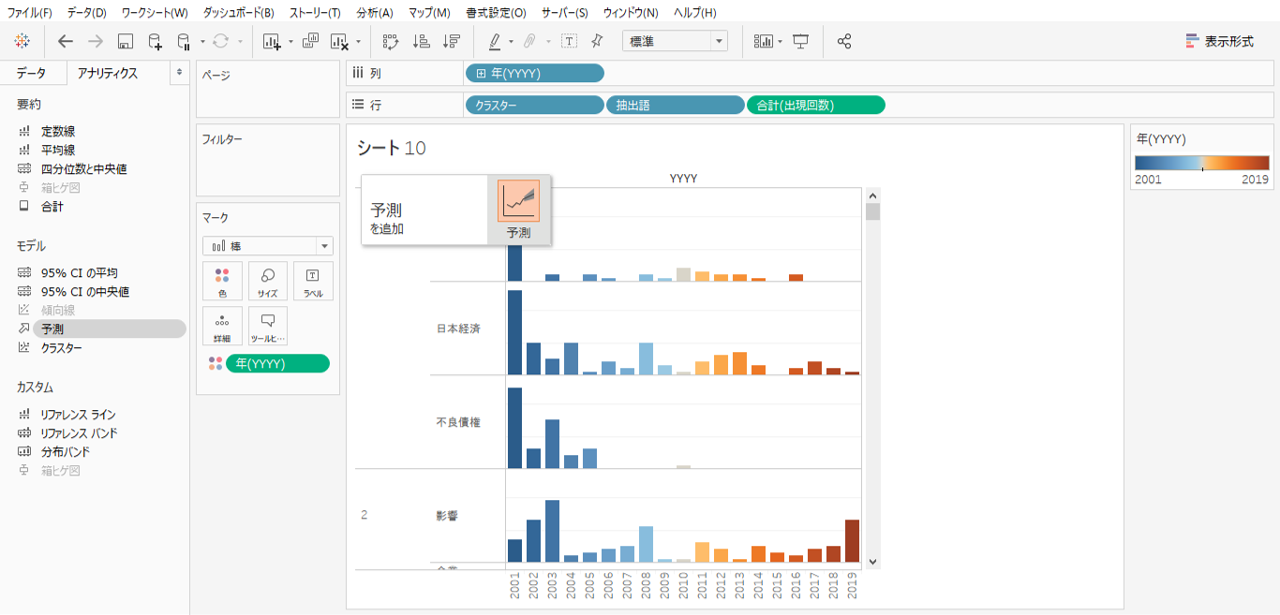
出現回数の予測を追加してみましょう。
・アナリクスペインから「予測」を引っぱってくると窓があらわれるのでドロップします。
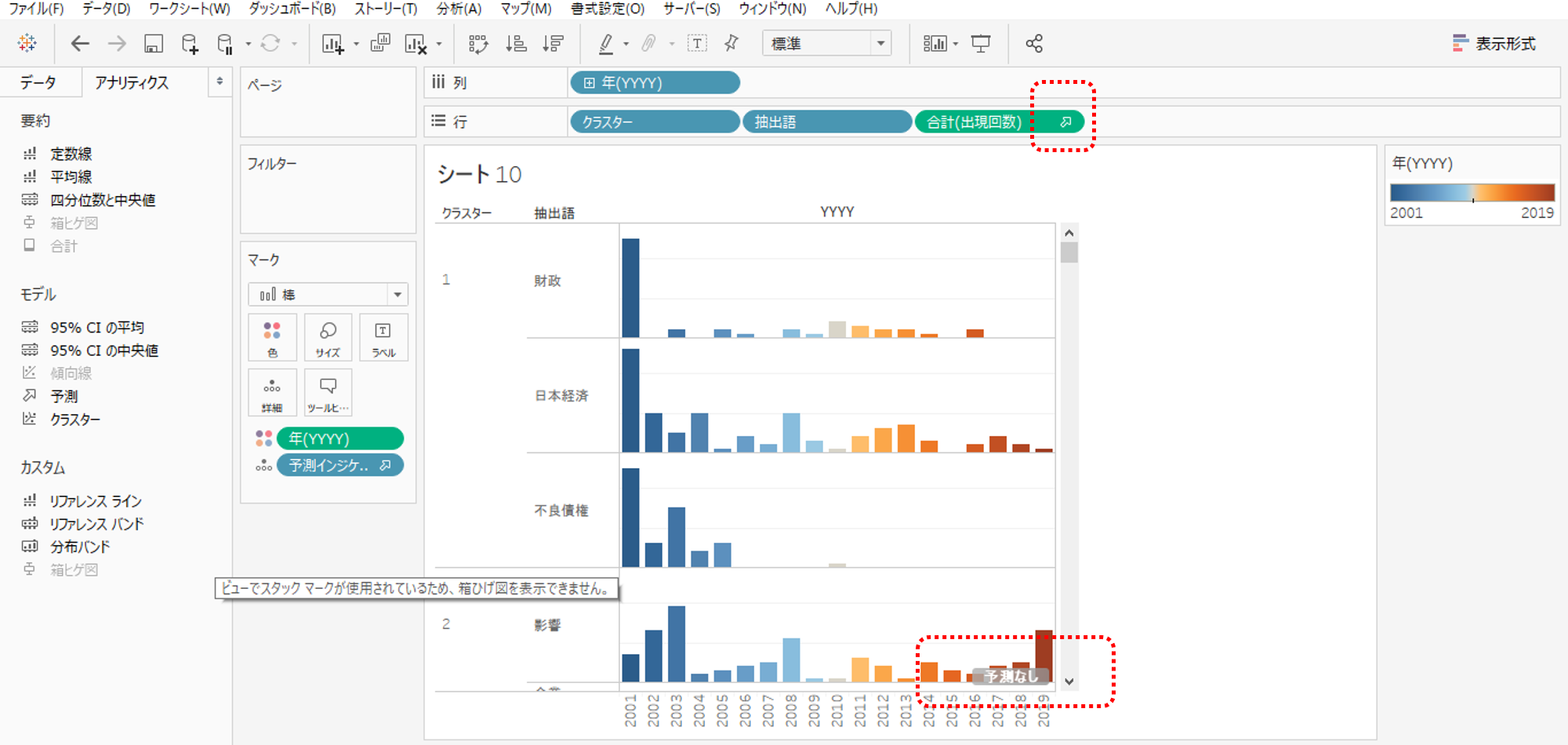
「予測なし」と表示されます。これは予測対象となる行数(抽出語数)が多すぎることが原因で表示されます。ダッシュボードでフィルターすると行数が減少して解決できるのでこまま進みます。
ダッシュボード
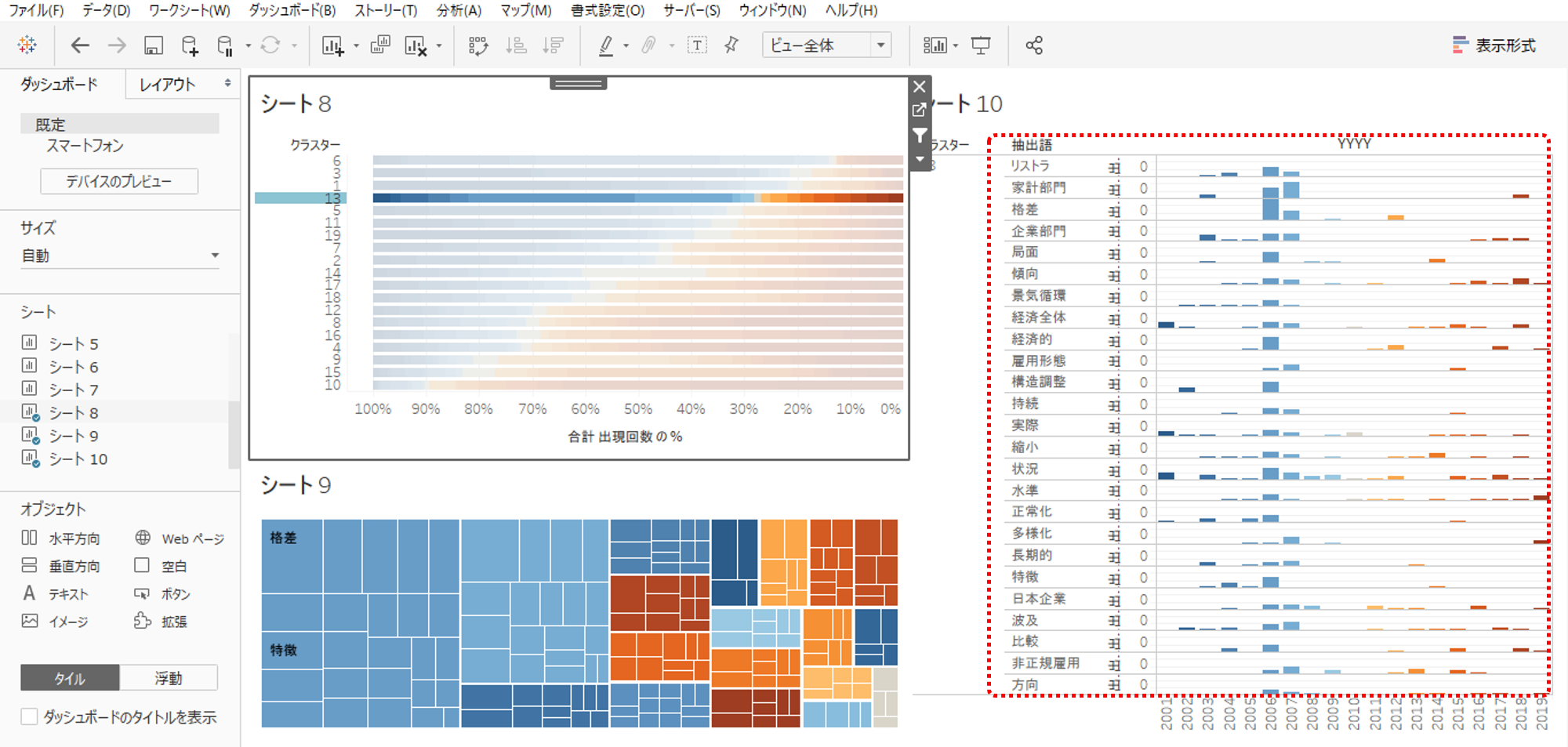
・シート8、9、10をダッシュボードへ貼ります。
・シート8からフィルターアクションを追加します。
シート8のクラスターを選択するとシート9、10が連動します。
・シート10の行数が多すぎるので調整します。
コンテキストフィルター
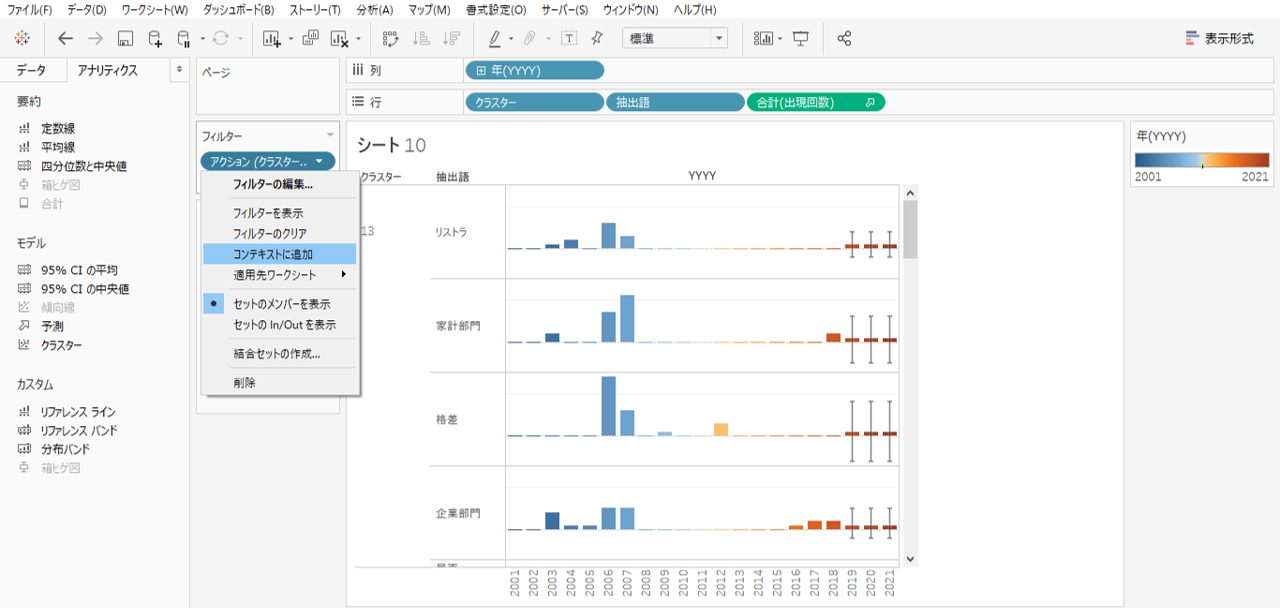
シート10へ戻り、
・アクションフィルターを右クリックして
・コンテキストフィルターを選択します。
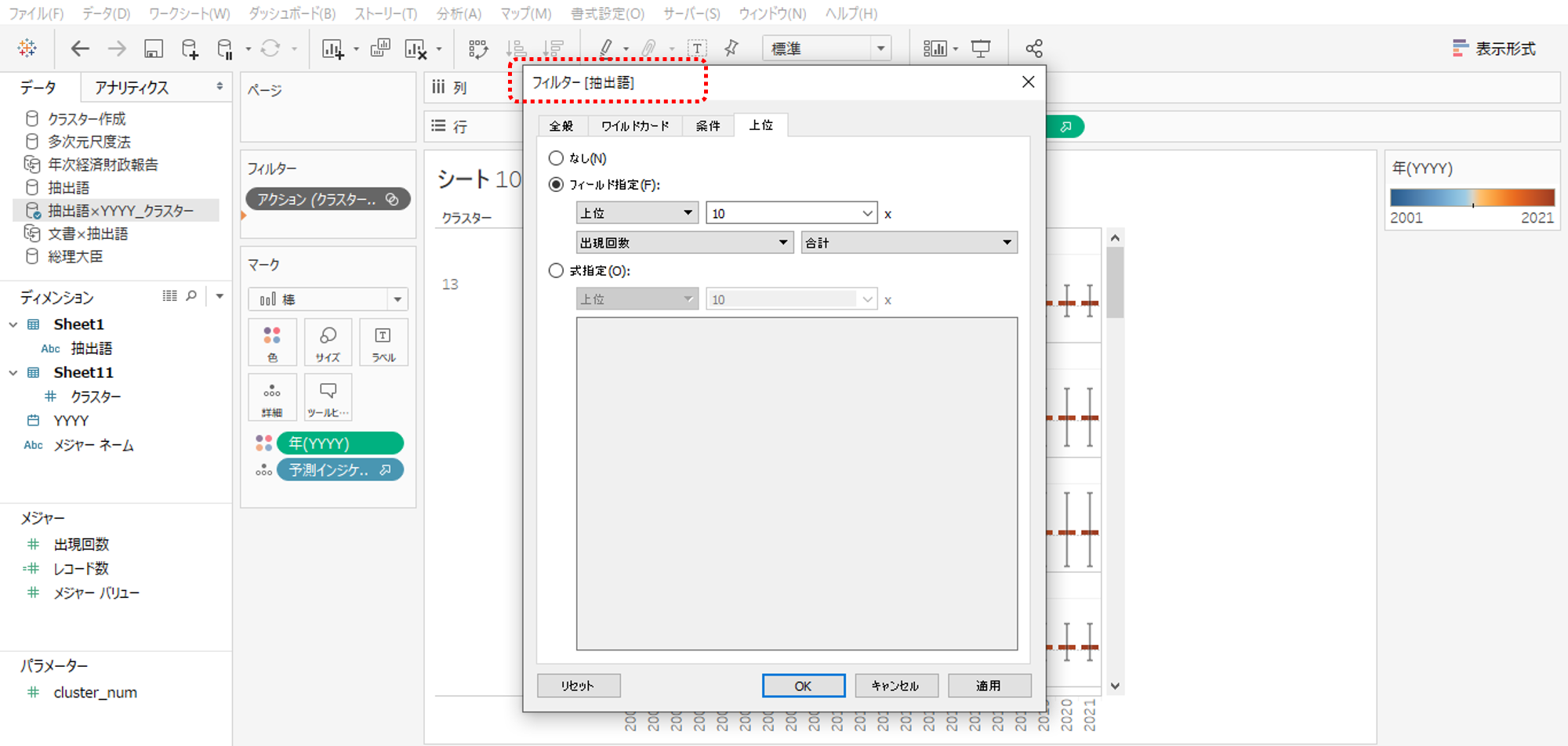
・ディメンションの「抽出語」をフィルターへ入れて編集します。
・出現回数上位10位に設定します。
アクションフィルター(クラスターのフィルター)をコンテキストにすることで、どのクラスターを選択しても常に出現回数上位10位の抽出語が表示できるようになります。
コンテキストにしないと、常に全抽出語のなかから上位10位を表示します。従って、あるクラスターを選択したときに上位10位までにランクインしている抽出語が選択したクラスターに含まれていないならば何も表示されないことになります。
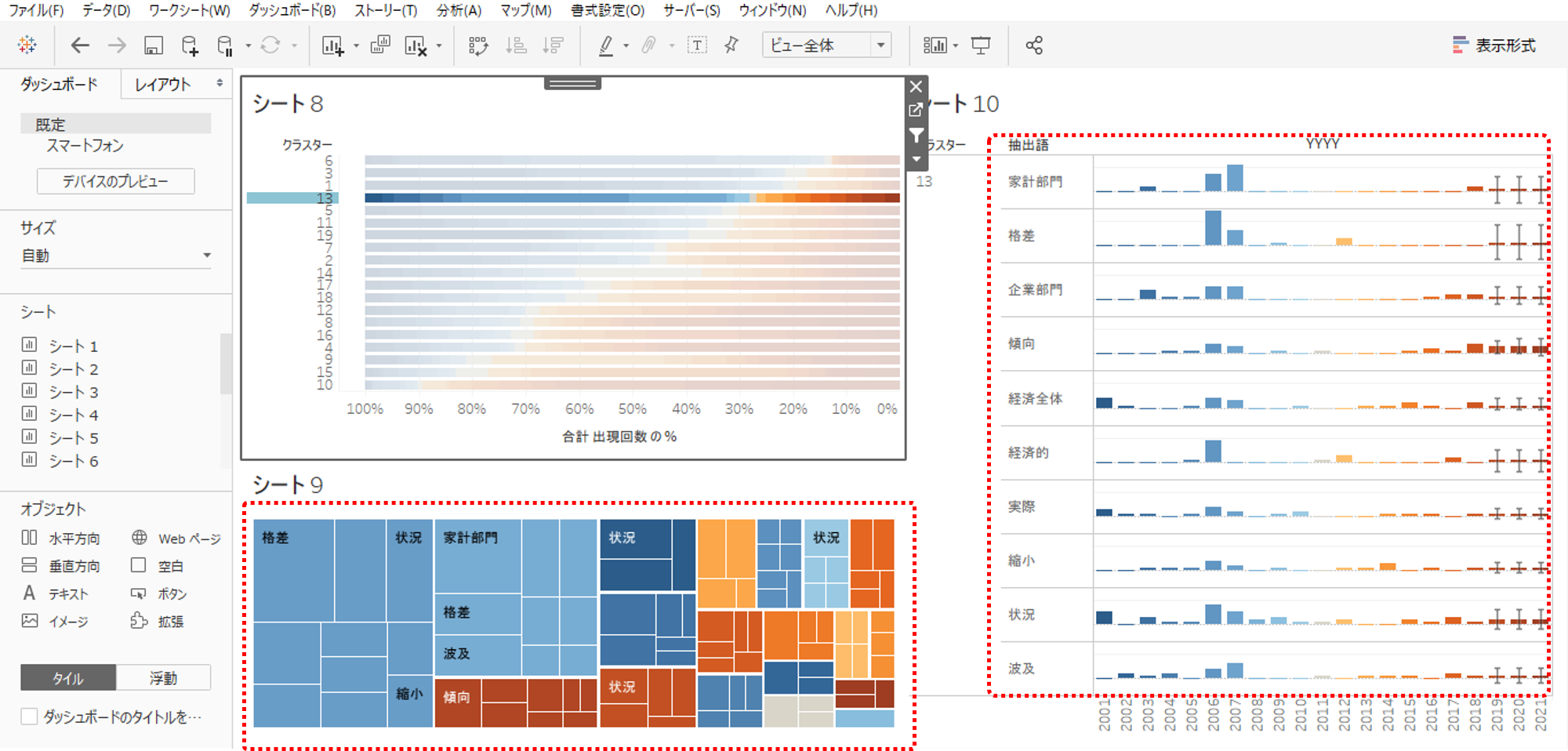
シート9も同様にコンテキストを適用しました。