
KHcoder 11. KWICコンコーダンス
KWICコンコーダンスは、よく使用する機能です。謎のロケーション統計スコアも解説しています。
テキストマイニングツール「KHcoder」の活用メモ
開発者である樋口先生に感謝!
【今回の分析対象テキストはこちらからコピーできます】
KWICコンコーダンス
KWICコンコーダンスの活用場面

・「ファイル」→「抽出語」→「KWICコンコーダンス」から開くことができます。
直接的に「KWICコンコーダンス」へアクセスするよりも
・「抽出語」
・「対応分析」
・「多次元尺度構成法」
・「階層クラスター分析」
・「共起ネットワーク」
・「自己組織化マップ」
さまざまな分析結果からアクセスする場合のほうがおおくなります。
各種分析結果を検証するために「語」の使われ方を確認する必要があるからです。
例えば「好き」が「好き」なのか「好きではない」のかを前後の文脈から確認することができます。とても便利な機能です。
KWICコンコーダンス機能
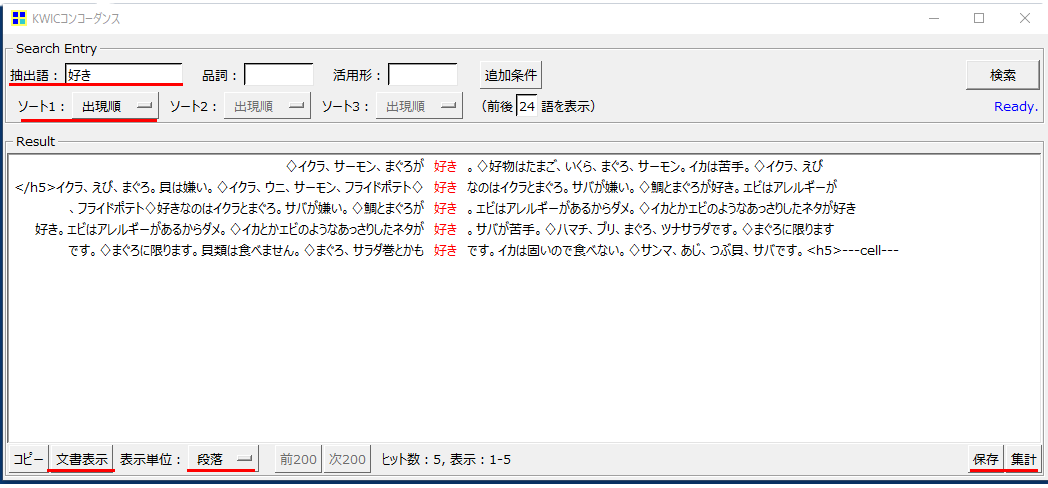
・「抽出語」へ「好き」と入力して「検索」をクリックします。
・「好き」の前後を構成する24「語」がデフォルトで表示されます。
24「語」というのはKHcoderでいう「語」ではなく基本的には24「文字」です。しかし「文字」数を数えてみると24「字」にはなりません。
なぜこのようになるのかというと、
・「語」の途中で表示を切らないルールがあるからのようです。
・24「文字」目が「語」の途中になるときは四捨五入して24「文字」前後の「語」で区切るような設定です。
この24「文字」にはなんらかの意味があるのだろうとは思いますが、この分析で用いている「分析対象テキスト」は短文構成なので、前後10「文字」でも十分の「語」の使われ方を理解することができます。
「分析対象テキスト」の内容により、見やすい数値を設定すればよいと思います。◇(ひし形)の位置はH5の区切り目に表示されます。
文書表示
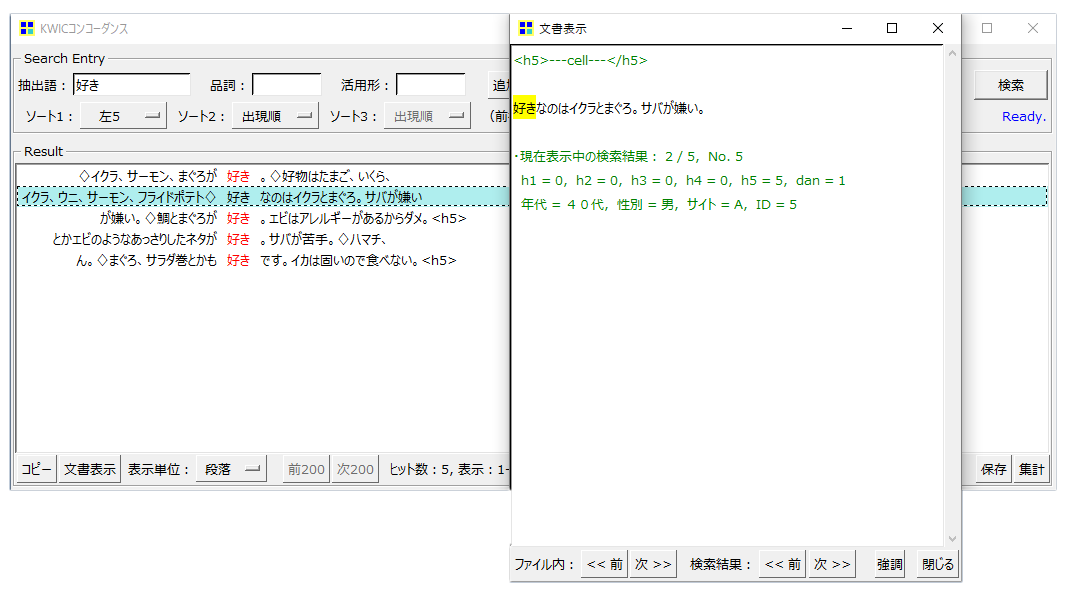
・行を選択し、下の「文書表示」をクリックするとウインドウが開きます。
・右横の「段落」「文」「H5」を設定変更することができます。画像は「段」に設定しているので表示は「段」です。
・選択した「語」が黄色でハイライトされます。
・「現在表示中の検索結果: 2 / 5」は5「語」のうちの2番目
・「No.5」は全12「段」のなかの5番目の段であることを
・「 年代 = 40代, 性別 = 男, サイト = A, ID = 5」はすべて外部変数を示します。
「分析対象テキスト」がエクセルまたはCSVときに上に<—cell—>こんなのが表示されますが気にすることはありません。
文書表示機能を使用するとき分析結果の検証など、例えば「好き」と「まぐろ」が共起しているのが本当に4回なのか確かめることができます。
私的にはプレゼンで文書表示機能をよく使います。特にアンケート・クチコミのなかでも少数意見をパッパと見せるときに外部変数がくっついてるのでとても見やすいです。
・ウインドウの下の「ファイル内:<<前 後>>」はファイル内の前・後の「段」(表示単位を「段」に設定している場合)へ移動します。
・検索「語」の「好き」を含むか含まないかは無関係に単純に前・後の「段」へ移動します。
・「検索結果:<<前 後>>」は検索「語」の「好き」を含む前・後の「段」へ移動します。
・「強調」をクリックすると、新しいウインドウがさらに開きます。
・「言葉」の窓へ「語」を入力して「追加」をクリックします。
・強調したい「語」をブルーでハイライトします。
・「種類」は「抽出語」か「文字列」を選択できます。
・窓へ入植する値が「語」であれば「抽出語」「文字列」どちらを選択しても同じ結果になります。
例えば「マグロが好き」のように「語」を超える場合、または「マグ」のように「語」未満の場合は「文字列」を選択してください。
ソート
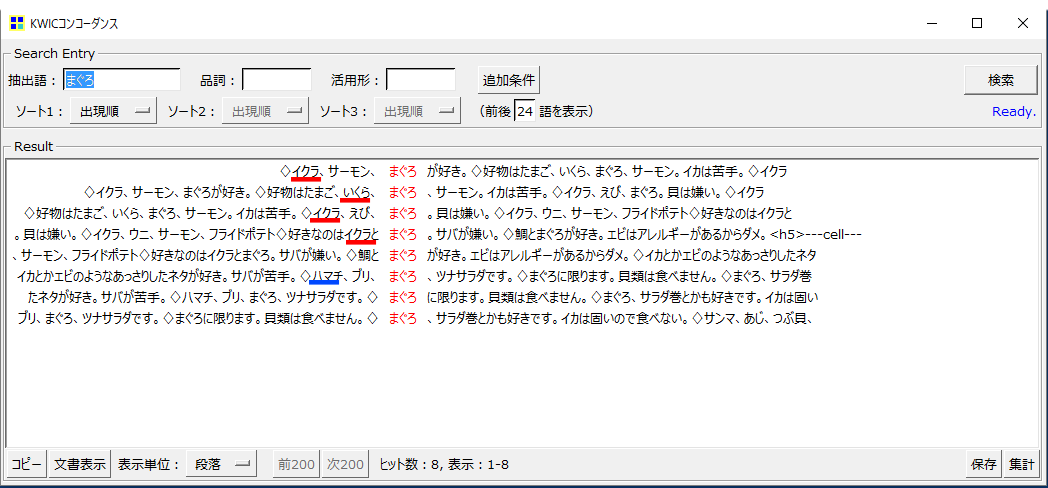
・「ソート1」のデフォルトは「出現順」です。
単純に「好き」が出現する文書順に表示されます。「右5」等があります。文の先頭から「まぐろ」までの「文字」数が5になっている「文」があればその「文」がいちばん上に表示されます。「ソート2」「ソート3」まであります。
ロケーション統計
「集計」をクリック

・「ロケーション統計」が開きます。
「まぐろ」という「語」の左5から右5までの間にだけ出現する「語」が表示されます。
左5から右5までの間ですから、その途中が「文」「段」「H5]で切れていても抽出されます。
・「いくら」が「まぐろ」の左側(前方)4語目に2回
・「いくら」が「まぐろ」左側(前方)2語目の2回出現している
このように結果を読みます。デフォルトで「スコア」順になっています。つまり「スコア」が高いほど近くに出現する「語」と理解できます。
スコア係数は
・左右5が0.2
・左右4が0.25
・左右3が0.33
・左右2が0.5
・左右1が1.0
スコア係数×出現回数でスコア合計を算出しています。
スコアのほかにJccard係数の表示できます。
ただし前後5「字」をはさむ範囲のJccard係数です。通常のJccard係数は「H5」「段」「文」が基本ですから相当に狭い範囲内のJccard係数になります。
また、通常は「H5」「段」「文」を超えるJccard係数は算出できませんが、前後5「字」以内で「H5」「段」「文]で切れていても計算されます。
検証してみると、左右の次の数値は「語」数ではなく「文字」数です。句読点も1「文字」でカウントしています。
【今回の分析対象テキストはこちらからコピーできます】