
KHcoder 13. 関連語検索(第2回)
KHcoderの分析軸、関連語検索の「段」と「文」の分析結果の違いについて解説しています。
テキストマイニングツール「KHcoder」の活用メモ
開発者である樋口先生に感謝!
【今回の分析対象テキストはこちらからコピーできます】
「段」と「文」の違い
共起の関係
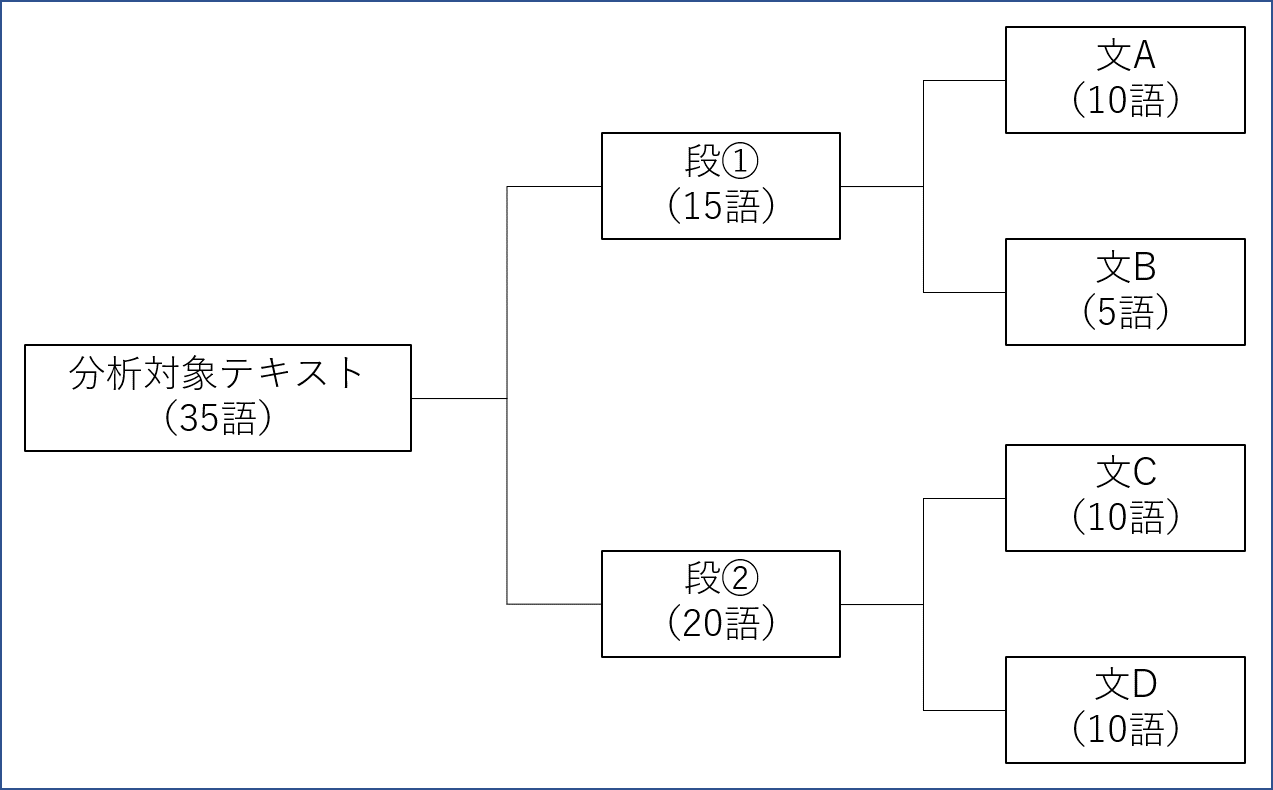
簡単な図を用いて「段」と「文」の共起の関係を説明します。
図は今回使用している分析対象テキストとは無関係に、説明のために作成した仮想図です。
関連語検索機能は集計単位を「段」に設定すると結果数値は「段」数とそれに基づいて出現率・共起率・Jaccard係数を算出します。
「文」に設定すると結果数値は「文」数と「文」数の出現率・共起率・Jaccard係数を算出します。
従って、完全に「段」イコール「文」でないかぎり「段」「文」それぞれの分析結果は異なったものになります。
「段」で共起するが、「文」で共起しない
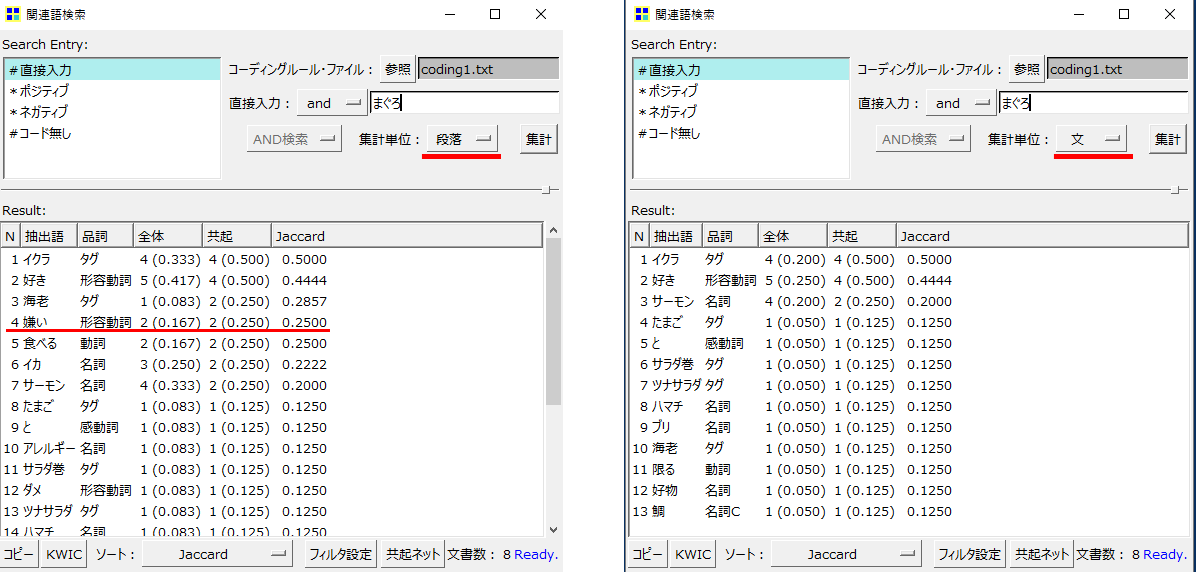
左は「段」、右は「文」で関連語検索結果を表示しています。(条件付き確率が低下する語も表示しています)
・左側「段」で集計すると「まぐろ」と「嫌い」が共起します。
そのまま読むと、回答者のなかには「まぐろ」が「嫌い」な人がいるのだろうと一旦は結論することが可能です。
| テキスト |
| イクラ、えび、まぐろ。貝は嫌い。 |
| 好きなのはイクラとまぐろ。サバが嫌い。 |
ところが実際のテキストをみると、「嫌い」なのは「まぐろ」ではなく、「貝」「サバ」です。
・集計単位を「文」にすると「まぐろ」と「嫌い」は共起しません。
・「段」で集計する場合
「段」イコール回答者の関係を保持したままだから、「段」イコール「回答者」で集合の1要素です。
共起というのは集合の各要素の類似性をみつけることができるものですから、よく似た回答をした回答者をみつけることが可能になります。
一方で、回答の内容をより実態に近いかたちで理解しようとするなら、「文」の集計を確認する必要があるということです。「文」で集計することで「嫌い」なのは「まぐろ」ではなく、「貝」「サバ」だということを発見できるのです。
コーディングしたときの関連語検索
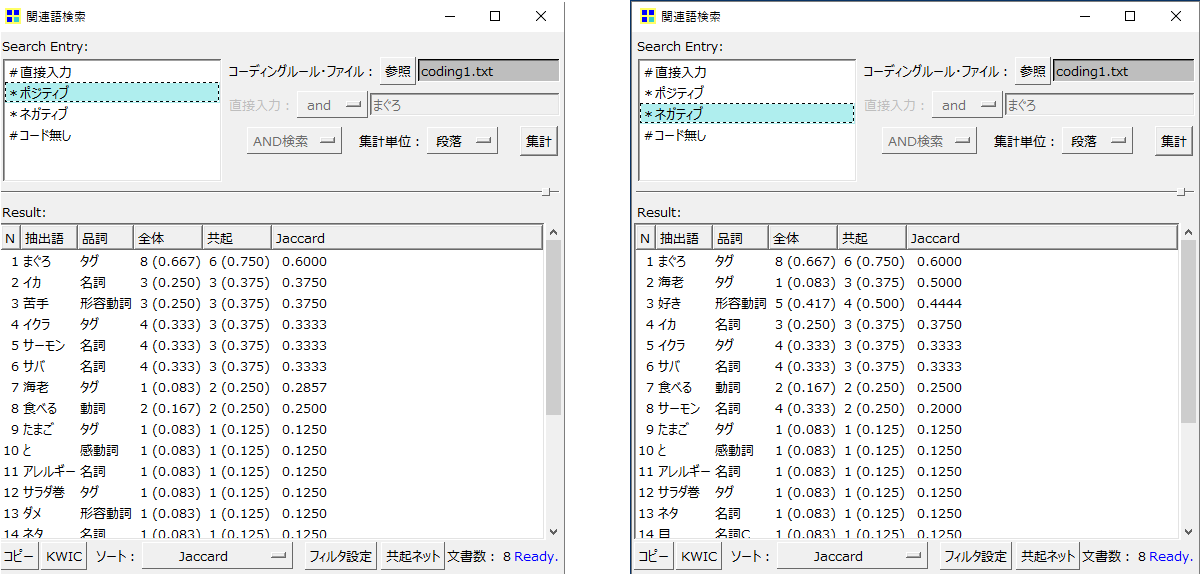
「段」で集計
*ポジティブ 好き or 限る or いい or あっさり or 好物 *ネガティブ 苦手 or 嫌い or ダメ or 固い or 脂っこい or ない or ん
このようなコーディングファイルを読み込みました。(KHcoder8. コーディングを参照)
ポジティブで説明します。
もともとの「語」である「好き」「限る」「あっさり」「好物」の4「語」が「ポジティブ」という1「語」に置き換わったと考えてください。
コーディングの共起は
・「コーディング」した「好き」「限る」「あっさり」「好物」の4「語」のどれかと
・共起する「語」が出現する「段」数が結果として表示されます。
もともと4「語」あるから、多くの「語」と「段」数が示されます。
通常は、「文」よりも「段」、「語」よりも「コード」のほうが多くの「語」から構成されています。
・集計単位が「文」よりも「段」のほうが共起する「語」は多い。
・集計単位が「語」よりも「コード」のほうが共起する「語」は多い。
「段」で集計しても、結局「まぐろ」に対して回答者はポジティブなのかネガティブなのか?あるいは回答者12人のうちポジティブな回答者が何人いるのか?いすれにしても明確にできません。
「文」で集計
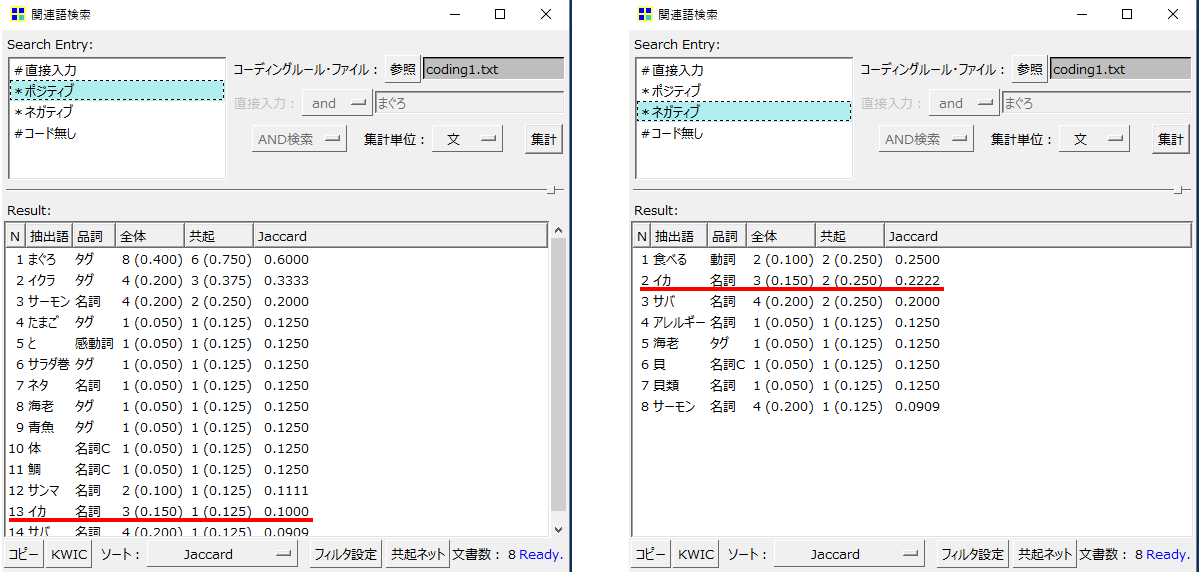
コーディングの場合は「文」で集計した方がみやすいように思います。「イカ」は3分の2がネガティブで、苦手とか食べないと答えていることが見えてきます。やはり「文」のほうが「分析対象テキスト」に沿った結果が出やすい感じです。
>KHcoder 12. 関連語検索(第1回)