
アソシエーション分析
アソシエーションとは
交友関係を明らかにします
刑事ものというのか、推理・ミステリーものというのか、まず事件が発生すると容疑者の写真をホワイトボードへ貼り名前や血縁関係・交友関係・利害関係が書き込まれます。
事件にかかわる人間どうしの関係を見える化しているわけです。このような人間関係、販売では商品と商品の関係を分析してみえる化する手法がアソシエーション(バスケット)分析です。
一般的に同時購買された(買い物カゴに一緒に入っている)商品どうしの関係性を明らかにすると顧客の購買行動がみえてきます。
店舗は顧客の購買行動を活用して客単価、おもに購入点数アップを狙います。よくあるのは、カレールウ・ジャガイモ・にんじん・たまねぎ・牛肉ですね。「福神漬をお忘れではないですか」といったPRをすることで更なる一品のご購入を目指します。
インターネット広告にも活用されているようです。「あなたにオススメ」「この商品を見た人はこんな商品も見ています」、あるいは「釣り」を検索すると「車」の広告が表示される。これは「釣り」と「車」の関係がよくて「釣り」の次に「車」をクリックするユーザーが多いというデータから導かれた法則があるからです。レストランのメニュー表のレイアウトに活用されていたり、回転すしのネタを流す順番を研究しているところもあるようです。
POSレジデータ

ある食品スーパーのPOSレジトランザクションデータがあります。1か月分で200万行を超えています。
通常、日別・時間帯別・カテゴリー別・商品別・顧客別などのデータは、このようなトランザクションデータをストアサーバで集計しています。
基本的にトランザクションデータは1アイテムごとに1行つくられます。商品のバーコードをレジでピッとスキャンした瞬間に1行のデータができます。このスーパーでは1か月延べ200万アイテムの商品を販売したことになります。
ここで言う200万アイテムというのは延べですから、実際に販売したアイテム数は約7,000になります。この約7,000アイテムの関係性をトランザクションデータをつかって調べるのがスーパーマーケットのアソシエーション分析です。
アソシエーション分析
サンプルデータ
| バスケット番号 | バナナ | みかん | ぶどう |
| A | 1 | 1 | 1 |
| B | 1 | 1 | 0 |
| C | 1 | 0 | 0 |
顧客が購入したデータをクロス集計します。アソシエーション分析をするためにこのデータをトランザクション型へ変換します。データの数値は購入数量です。あとで解説しますが数量は1か0のどちらかでOKです。
データ化のときに注意していただきたいことは、行をバスケット番号にすること、バスケット番号はユニークであることです。
概ねデータには「取引番号」のようなものがありますが「取引番号」が必ずしもユニークになるとは限りません。
POSレジ1台であっても取引日付が違う場合に同じ「取引番号」が発行されることがありますし、POSレジ複数台の場合は同日に同じ「取引番号」が発行されることがあります。
従って、「取引日付&取引時刻&レジ番号&取引番号」=「バスケット番号」このくらい値をくっつけてユニークになるようにバスケット番号をつくります。
また、実践ではアイテム数を絞り込むことをおすすめします。分析ではアイテムが列になるため7,000アイテムを分析すると7,000列のマトリクスになります。そのまま分析すると猛烈な結果が算出されるので、あらかじめ部門を絞る、アイテム数を売上上位に絞って分析するほうが無難です。
トランザクション型へ変換
| 1 | バナナ | みかん | ぶどう |
| 2 | バナナ | みかん | |
| 3 | バナナ |
トランザクション型というのはこのような形式になります。元データを変形する必要はなく、RがやってくれますのでRの手順を説明します。
Rコマンド
Rコマンド説明
#csvファイルを読み込みます
d<- read.table("ディレクトリ/ファイル名.csv",sep=",",fileEncoding="cp932",header=TRUE, na.strings="0", dec=".", strip.white=TRUE)
#NAを0に変換
d[is.na(d)]<-0
#arulesを呼び出し、ない場合はパッケージをインストールしてください
library(arules)
#バスケット番号の列は使用しないので削除
d1<-d[,-1]
#transactionsへ変換
d1<- as(as.matrix(d1),"transactions")
#minlen=2は最小アテム数、maxlen=3最大アイテム数、これは2アイテム以上3アイテム以下のの組み合わせ(あとで説明します)
#support=、confidence=は抽出する最低値(あとで説明します)
d2<- apriori(d1,p=list(support=0.002,confidence=0.005,minlen=2,maxlen=3,ext=TRUE))
#結果を表示します。by = "support"はsupport降順、n=100はsupport降順100行まで表示
d2_1<-inspect(head(sort(d2, by = "support"),n=100))
#結果を出力します。
write(d2,row.names=F,col.names=T,fileEncoding = "cp932",sep=',','ディレクトリ/ファイル名.txt')
(Rコマンドここまで、以下結果表示)Apriori Parameter specification: confidence minval smax arem aval originalSupport maxtime support minlen 0.005 0.1 1 none FALSE TRUE 5 0.002 2 maxlen target ext 3 rules TRUE Algorithmic control: filter tree heap memopt load sort verbose 0.1 TRUE TRUE FALSE TRUE 2 TRUE Absolute minimum support count: 0 set item appearances ...[0 item(s)] done [0.00s]. set transactions ...[3 item(s), 3 transaction(s)] done [0.00s]. sorting and recoding items ... [3 item(s)] done [0.00s]. creating transaction tree ... done [0.00s]. checking subsets of size 1 2 3 done [0.00s]. writing ... [9 rule(s)] done [0.00s]. #9つのルールが算出されました。 creating S4 object ... done [0.00s].
分析結果
lhs rhs support confidence lhs.support lift
1 {みかん} => {バナナ} 0.6666667 1.0000000 0.6666667 1.0
2 {バナナ} => {みかん} 0.6666667 0.6666667 1.0000000 1.0
3 {ぶどう} => {みかん} 0.3333333 1.0000000 0.3333333 1.5
4 {みかん} => {ぶどう} 0.3333333 0.5000000 0.6666667 1.5
5 {ぶどう} => {バナナ} 0.3333333 1.0000000 0.3333333 1.0
6 {バナナ} => {ぶどう} 0.3333333 0.3333333 1.0000000 1.0
7 {みかん,ぶどう} => {バナナ} 0.3333333 1.0000000 0.3333333 1.0
8 {バナナ,ぶどう} => {みかん} 0.3333333 1.0000000 0.3333333 1.5
9 {バナナ,みかん} => {ぶどう} 0.3333333 0.5000000 0.6666667 1.5
Rコマンドのminlen=2は最小アテム数の設定です。
1に設定すると「{みかん} =>」このように矢印の左側1アイテムだけの結果が表示されます。つまり単独で購入されている場合の分析結果だけが表示されるわけです。これではアソシエーションになりません。minlenの設定は2以上が必須です。
今回はmaxlen=3の設定です。仮に2に設定すると結果は6通りが表示されます。7行目以下「{みかん,ぶどう} => {バナナ} 」これは3アイテムですからmaxlen=2では表示されません。実践的には3~5の設定で十分です。
結果解説
数値の意味
| lhs | rhs | support | confidence | lhs.support | lift | ||
| 1 | {みかん} | => | {バナナ} | 0.666667 | 1.000000 | 0.666667 | 1.000000 |
| 2 | {バナナ} | => | {みかん} | 0.666667 | 0.666667 | 1.000000 | 1.000000 |
| 3 | {ぶどう} | => | {みかん} | 0.333333 | 1.000000 | 0.333333 | 1.500000 |
| 4 | {みかん} | => | {ぶどう} | 0.333333 | 0.500000 | 0.666667 | 1.500000 |
| 5 | {ぶどう} | => | {バナナ} | 0.333333 | 1.000000 | 0.333333 | 1.000000 |
| 6 | {バナナ} | => | {ぶどう} | 0.333333 | 0.333333 | 1.000000 | 1.000000 |
| 7 | {みかん,ぶどう} | => | {バナナ} | 0.333333 | 1.000000 | 0.333333 | 1.000000 |
| 8 | {バナナ,ぶどう} | => | {みかん} | 0.333333 | 1.000000 | 0.333333 | 1.500000 |
| 9 | {バナナ,みかん} | => | {ぶどう} | 0.333333 | 0.500000 | 0.666667 | 1.500000 |

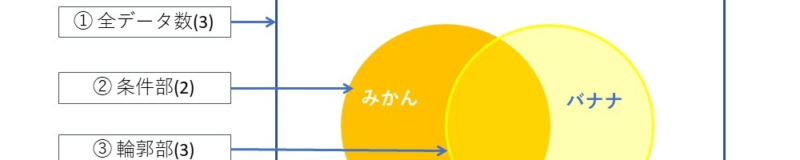
図のカッコ内の数値はデータ行数(買物カゴの数)です。
以下1行目の「{みかん} => {バナナ}」を例にして数値を解説します。
・support(支持度)
条件部②と輪郭部③を同時に含むデータ数(④の部分)÷全データ数①
<例>
{みかん} => {バナナ} 0.6666667
④÷①=2÷3=0.6666667
<結論>
全顧客のうち66.7%が「みかん」と「バナナ」を同時に購入します。
・confidence(確信度)
条件部②と輪郭部③を同時に含むデータ数(④の部分)÷条件部②を含むデータ数
<例>
{みかん} => {バナナ} 1.0000000
④÷②=2÷2=1.0000000
<結論>
「みかん」を購入した顧客のうち100%が「バナナ」も購入します。
・lhs.support
support÷confidence
lhs rhs support confidence lhs.support lift
{みかん} => {バナナ} 0.6666667 1.0000000 0.6666667 1.0
④÷①÷(④÷②)=0.6666667÷1.0000000=0.6666667
<結論>
全バスケットのうち{みかん}が入っているバスケットの割合は0.6666667です。
・lift(リフト値)
{みかん} => {バナナ}のとき
ミカンのconfidence÷バナナのIhs.support
<例>
{みかん} => {バナナ} 1.0
1.0000000÷(③÷①)=1.0000000÷(3÷3)=1.0
<結論>
「みかん」を購入した顧客のうち「バナナ」も購入た顧客の割合は、顧客全体の中で「バナナ」を購入した顧客の割合と同じ(値が1.0)です。
細かい数値を重要視しない
アソシエーション分析においてsupport、confidence、lhs.support、liftなど数値そのものの重要性は低いと感じています。なにしろ3行のデータから9のルールが算出されます。
重要なのは順番です。最も売れている組み合わせ、最も支持されている組み合わせがどうなのかを知ることです。「バナナ」が10個売れると「みかん」が6個売れることよりも、「バナナ」と「みかん」の組み合わせ相性がよいということがわかれば十分です。
ネットショップで「バナナ」をカゴに入れた瞬間に「みかん」をレコメンドすると「みかん」も購入していただける可能性が高いだろうということです。レコメンドした顧客のうちどれくらいの顧客が反応したのかは実績分析で明らかにできることです。
数量が変化するとどうなるのか
バナナが1個増えると
バスケット番号Aのバナナを1個増やします。
| バスケット番号 | バナナ | みかん | ぶどう |
| A | 2 | 1 | 1 |
| B | 1 | 1 | 0 |
| C | 1 | 0 | 0 |
| 1 | バナナ | バナナ | みかん | ぶどう |
| 2 | バナナ | みかん | ||
| 3 | バナナ |
トランザクション型はこのようになります。
結果
lhs rhs support confidence lhs.support lift
1 {みかん} => {バナナ} 0.6666667 1.0000000 0.6666667 1.0
2 {バナナ} => {みかん} 0.6666667 0.6666667 1.0000000 1.0
3 {ぶどう} => {みかん} 0.3333333 1.0000000 0.3333333 1.5
4 {みかん} => {ぶどう} 0.3333333 0.5000000 0.6666667 1.5
5 {ぶどう} => {バナナ} 0.3333333 1.0000000 0.3333333 1.0
6 {バナナ} => {ぶどう} 0.3333333 0.3333333 1.0000000 1.0
7 {みかん,
ぶどう} => {バナナ} 0.3333333 1.0000000 0.3333333 1.0
8 {バナナ,
ぶどう} => {みかん} 0.3333333 1.0000000 0.3333333 1.5
9 {バナナ,
みかん} => {ぶどう} 0.3333333 0.5000000 0.6666667 1.5
お気づきだと思いますが、分析結果は全く同じになります。
それは、すべての数値が、データ行数(買物カゴの数)だからです。つまりアソシエーション分析では1顧客の「バナナ」購入数が100個になっても「みかん」や「ぶどう」の販売数は変化しないというう仮説が成り立ってしまうということです。このような意味においても結果数値自体は目安と考えた方がよさそうです。
分析の結果から
lhs rhs support confidence lhs.support lift
2 {バナナ} => {みかん} 0.6666667 0.6666667 1.0000000 1.0
「バナナ」と「みかん」の相性がよいということに変化がありません。そうなると、「バナナ」購入顧客にたいして更に「バナナ」レコメンドするような結果はアソシエーション分析からは出てこないということです。