

KHcoder 16. 対応分析(第3回)
KHcoderの対応分析、.xlsx .csv 形式のファイルを読み込み「H5」単位で分析する方法。
テキストマイニングツール「KHcoder」の活用メモ
開発者である樋口先生に感謝!
【今回の分析対象テキストはこちらからコピーできます】
抽出語×文書
「分析対象テキスト」のファイル形式がエクセル・CSVの場合
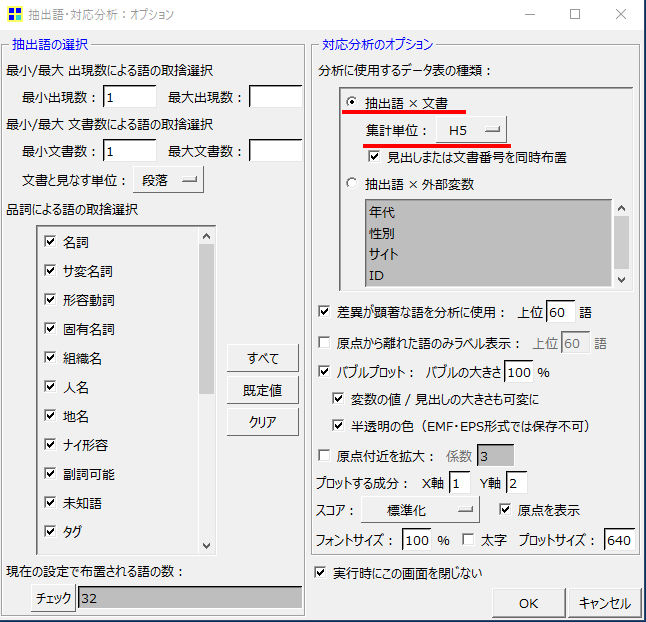
・「対応分析のオプション」→「分析に使用するデータ表の種類」→「抽出語×文書」を選択します。
・今回は「語」の最小出現数を1で設定しています。
・「分析に使用するデータ表の種類」の集計単位がデフォルトで「H5」になっていると思います。「H5」のまま「OK」をクリックします。
集計単位とは「外部変数」として取り扱う単位のことです。
つまり「H5」イコール「外部変数」です。どの「H5」に、どのような「語」が出現しているのかをカウントするのであって、「H5」を構成する「段」数や「文」数をカウントするのではありません。
つまり、「H5」が何段で構成されていようが集計とは無関係です。
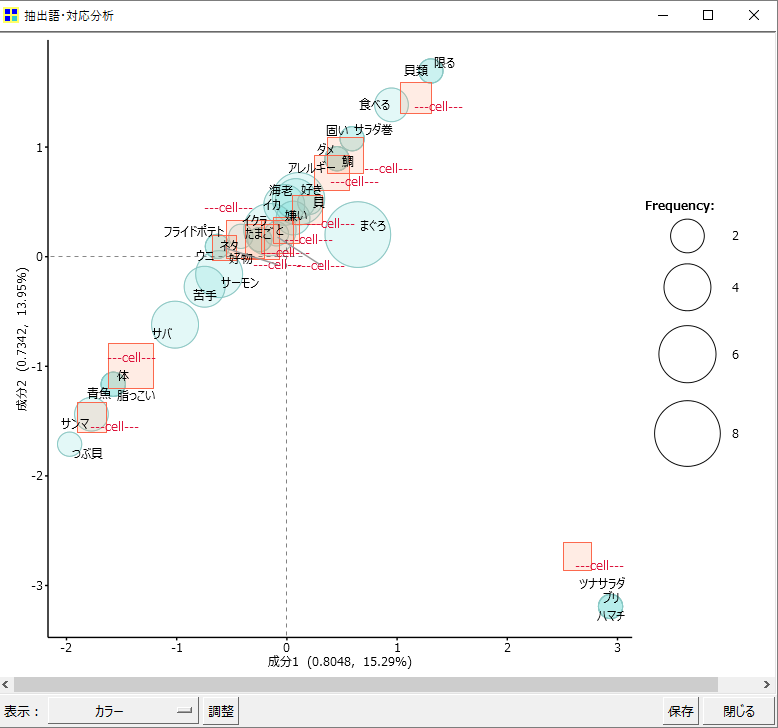
・赤い四角(row)がすべて「—cell—」と表示されます。
「分析対象テキスト」のファイル形式がエクセルまたはCSVの場合には上画像のような表示になります。
「—cell—」というのが何だか・・・
---cell--- イクラ、サーモン、まぐろが好き。 ---cell--- 好物はたまご、いくら、まぐろ、サーモン。イカは苦手。 ---cell--- イクラ、えび、まぐろ。貝は嫌い。 ---cell--- イクラ、ウニ、サーモン、フライドポテト ---cell--- 好きなのはイクラとまぐろ。サバが嫌い。 ---cell--- 鯛とまぐろが好き。エビはアレルギーがあるからダメ。 ---cell--- イカとかエビのようなあっさりしたネタが好き。サバが苦手。 ---cell--- ハマチ、ブリ、まぐろ、ツナサラダです。 ---cell--- まぐろに限ります。貝類は食べません。 ---cell--- まぐろ、サラダ巻とかも好きです。イカは固いので食べない。 ---cell--- サンマ、あじ、つぶ貝、サバです。 ---cell--- サバ、あじ、サンマのような青魚が体にいい。脂っこいサーモンとかは苦手です。
原因はエクセルまたはCSVの「分析対象テキスト」を読み込むと、KHcoderはこのようなテキストに変換して分析を実行するからです。
エクセルまたはCSVの1セルごとに「H5」を自動的に付与する仕組みになっているのです。「—cell—」は「H5」の区切り記号だとみなして構いません。
「分析対象テキスト」がtxt.形式のときはこのような自動処理は行われません。従って、txt.形式のときは手で「H5]を付与する必要があります。
自動で「H5」を付与してくれるのであれば、どうせならcell1、cell2、cell3のように通し番号を自動的に付与してくれれば有難いのですが、仕様として、すべて「—cell—」になるということです。
これでは、どの「H5」がどの「—cell—」に該当するのかがわかりません。
そこで、エクセルまたはCSVの「分析対象テキスト」に「外部変数」を付与することが容易であるというメリットを生かして「H5」を単位にして対応分析を実施する方法をご紹介します。
H5にIDを付与しておく
| テキスト | 年代 | 性別 | サイト | ID |
| イクラ、サーモン、まぐろが好き。 | 10代 | 男 | A | 1 |
| 好物はたまご、いくら、まぐろ、サーモン。イカは苦手。 | 10代 | 女 | A | 2 |
| イクラ、えび、まぐろ。貝は嫌い。 | 10代 | 男 | A | 3 |
「分析対象テキスト」がエクセルまたはCSVのときは、外部変数として「H5」に相当するセルにたいしてIDを付与しておきます。
そして、このIDを「外部変数」にして対応分析を行えば「—cell—」を消した分析が可能になります。
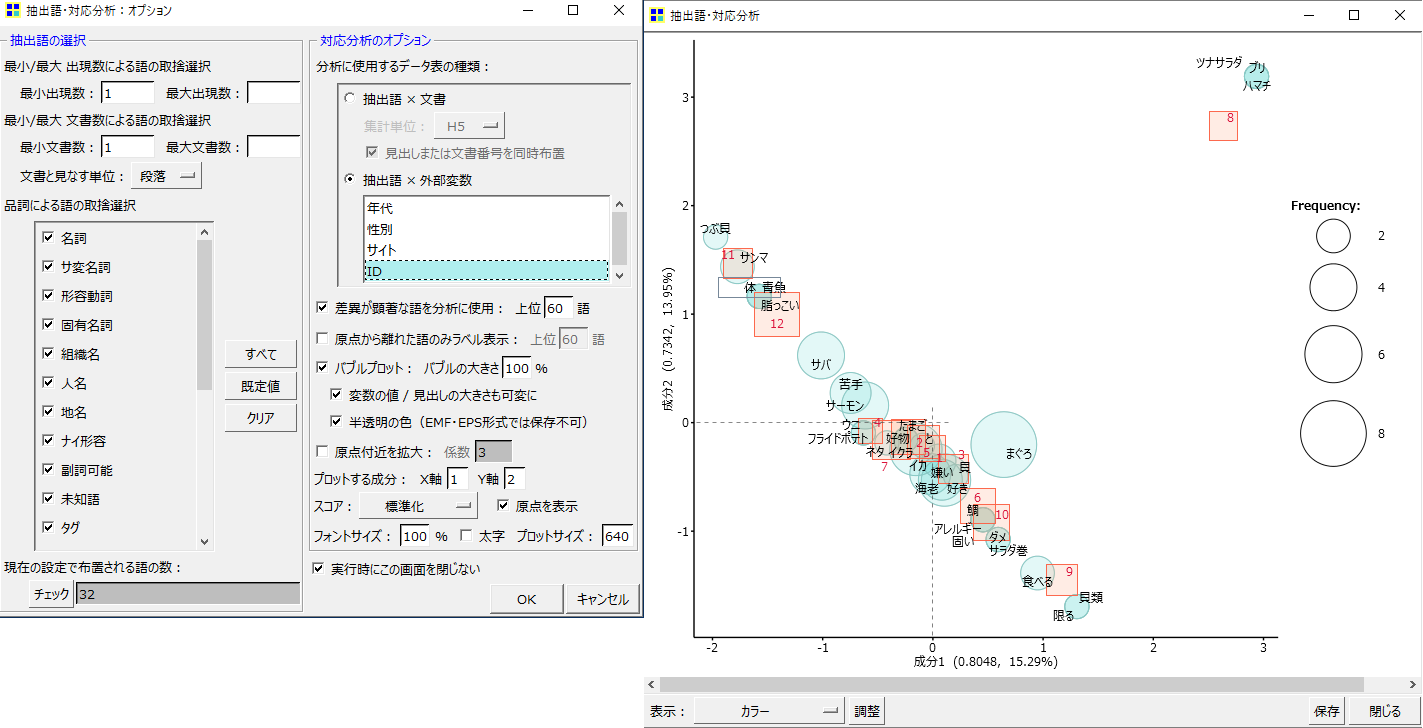
・「抽出語×文書」から「抽出語×外部変数」へ戻ります。
・「ID」を指定します。
そうすると「H5」イコール「ID」ですから「抽出語×文書 H5」と同様の結果になります。(なぜか90度回転して描画されますが、同じものです)
今回の「分析対象テキスト」のように「H5」イコール「段」になっていれば「H5」で分析する必要がありませんから、このように「分析対象テキスト」は「ID」を付与する必要はありません。
ところが、「H5」イコール「段」にならない場合、エクセルまたはCSVのセル内にエンターがあるような場合は行ごとに「ID」を「外部変数」として付与しておくことをオススメします。
ビジュアル変更
プロットする成分
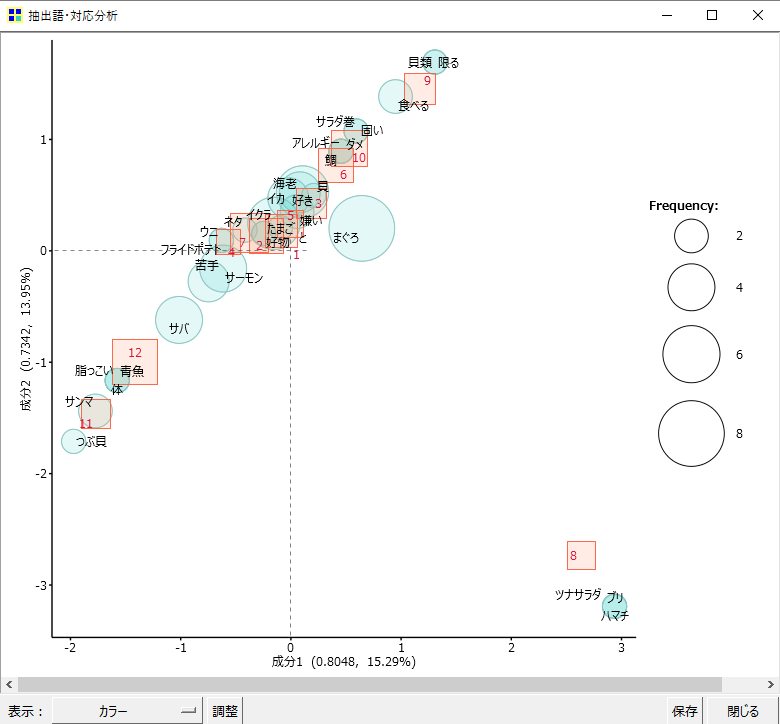
・「抽出語×文書」に戻ります。
・集計単位を「段落」に設定して「OK」をクリックします。
ここでは自動的に「段」の番号(ID)が付与されます。「H5」は番号が付与されないのに「段」は番号が付与されます。
実行結果をみると
・8番の「段」が他の「段」と比較して大きく離れた位置へプロットされます。
やはりcorresp関数は全体を三角形で描きたがる性質があるようです。
8番、9番、11番の赤い四角を頂点にして全体が描画されます。青い丸も同様に三角形を描きたがります。
8番の「段」や「ツナサラダ」「ブリ」「ハマチ」の「語」が他の「段」や「語」と比較して、ここまで違うのか!というとそうでもない感じがします。ちなみに8番の文書は「ハマチ、ブリ、まぐろ、ツナサラダです。」です。
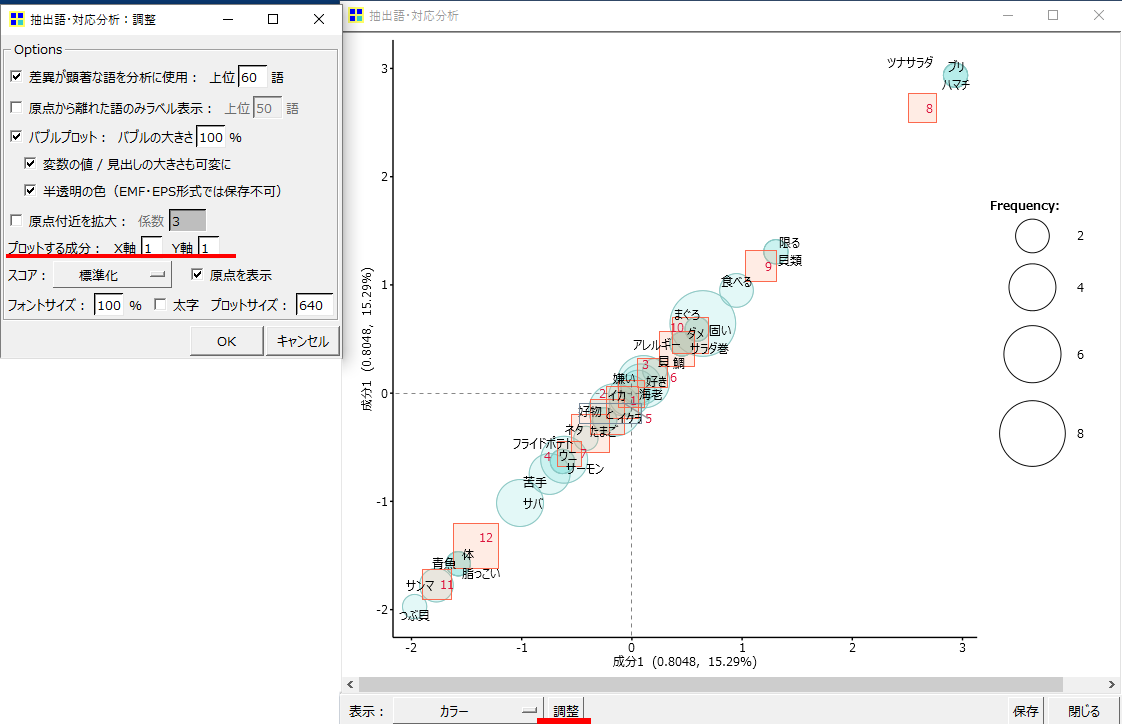
8番の「段」だけが他のプロットから大きく離れて特殊な見え方になるので、少し違う見え方になる方法をやってみます。
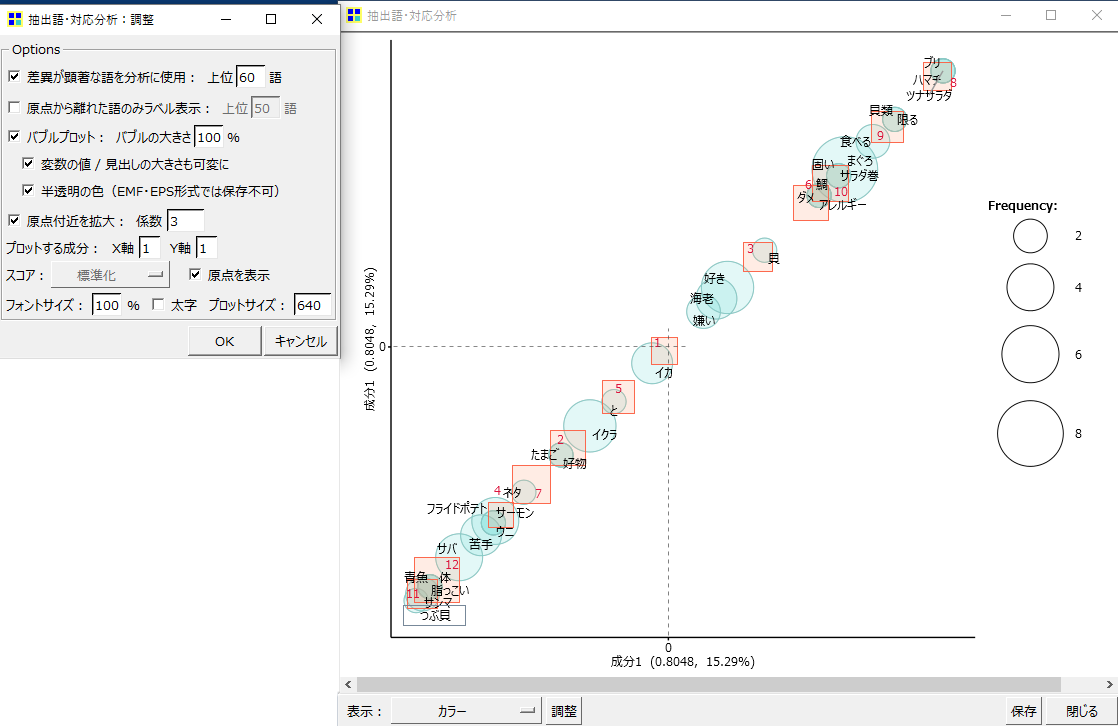
・左下の「調整」→「プロットする成分」のY軸を「1」にします。
結果は横軸も縦軸もX1の座標になるので右上がり45度の直線上に各要素がプロットされます。
直線用に並ぶので
・8番と11番の距離が最も離れている
・4番と12番よりも12番と11番の距離が近い
このような見方が可能になります。なんとなく2軸での表現よりも近い距離にある「段」のならび順がみえるような感じがします。
| plot | type | frequency | size | X1 | X2 |
プロットする成分というのは対応分析結果をCSVで出力したときの「X1」「X2」のことです。
今回はX軸「1」Y軸「1」で表現しました。X軸「2」Y軸「2」に設定すると横軸「X2」縦軸「X2」で描画します。
原点付近を拡大
・左下の「調整」→「原点付近を拡大」にチェックして「OK」をクリックします。
中央付近のごちゃごちゃ感をスッキリさせることができます。
・「原点付近を拡大」機能は距離計算の結果であるプロットする座標を見やすい位置へ変更する機能です。
数学的に計算される正確な座標ではないことを理解しておく必要があります。