
KHcoder 17. 多次元尺度構成法
多次元尺度構成法とは?どのような計算ロジックになっているのか。分析手順と分析結果の見方についても解説しています。
テキストマイニングツール「KHcoder」の活用メモ
開発者である樋口先生に感謝!
【今回の分析対象テキストはこちらからコピーできます】
分析ロジック
データ
多次元尺度構成法で分析するときに、KHcoderからRへ送られるデータです。
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] サーモン 1 1 0 1 0 0 0 0 0 0 0 1 サバ 0 0 0 0 1 0 1 0 0 0 1 1 イカ 0 1 0 0 0 0 1 0 0 1 0 0 サンマ 0 0 0 0 0 0 0 0 0 0 1 1 アレルギー 0 0 0 0 0 1 0 0 0 0 0 0 #実際は下へずっと続きます
・集計単位を「段」に設定
・抽出された全ての「語」を分析対象に設定しています。
分析用データは
・行が「語」
・列が「段」になります。
実際のデータは「語」(行)がずっと下まであります。「段」数が12ですから列数は12になります。集計単位を「文」にすると列数が「文」の数になります。
距離計算
Rでは、バイナリ法で「語」と「語」の距離を計算します。
サーモン サバ イカ サンマ アレルギー ウニ サバ 0.8571429 イカ 0.8333333 0.8333333 サンマ 0.8000000 0.5000000 1.0000000 アレルギー 1.0000000 1.0000000 1.0000000 1.0000000 ウニ 0.7500000 1.0000000 1.0000000 1.0000000 1.0000000 #実際は下・右へずっと続きます
計算結果のマトリクスの下三角成分を使います。
この「語」と「語」の距離に基づいて「語」をプロットする座標を計算します。
座標計算
[,1] [,2] サーモン -0.19062007 0.04787992 サバ -0.34093911 0.19118075 イカ -0.05119963 -0.40643327 サンマ -0.67589332 0.10838642 アレルギー 0.59665721 0.12008529 ウニ -0.32385067 0.58824070 ネタ -0.17027715 -0.30833503 #実際は下へずっと続きます
・1列([,1])がX座標
・2列([,2])がY座標になります。
「多次元尺度法のオプション」で座標を計算する方法が4種類用意されています。それぞれ座標を計算する関数が違います。
| KHcoderオプション | R関数 |
| Kruskal | isoMDS |
| Classical | cmdscale |
| Sammon | sammon |
| SMACOF | mds |
クラスター
サーモン サバ イカ サンマ アレルギー ウニ サバ 0.2076799 イカ 0.4752247 0.6641472 サンマ 0.4890308 0.3450351 0.8094946 アレルギー 0.7905815 0.9402880 0.8348295 1.2726043 ウニ 0.5565431 0.3974275 1.0313656 0.5951421 1.0327169 #実際は下へずっと続きます
・算出した「語」のX座標、Y座標から
・ユークリッド法(euclid)で「語」と「語」の距離を計算します。
・この距離をもとにウォード法(ward.D2)でクラスターを形成します。
分析手順と結果
分析手順
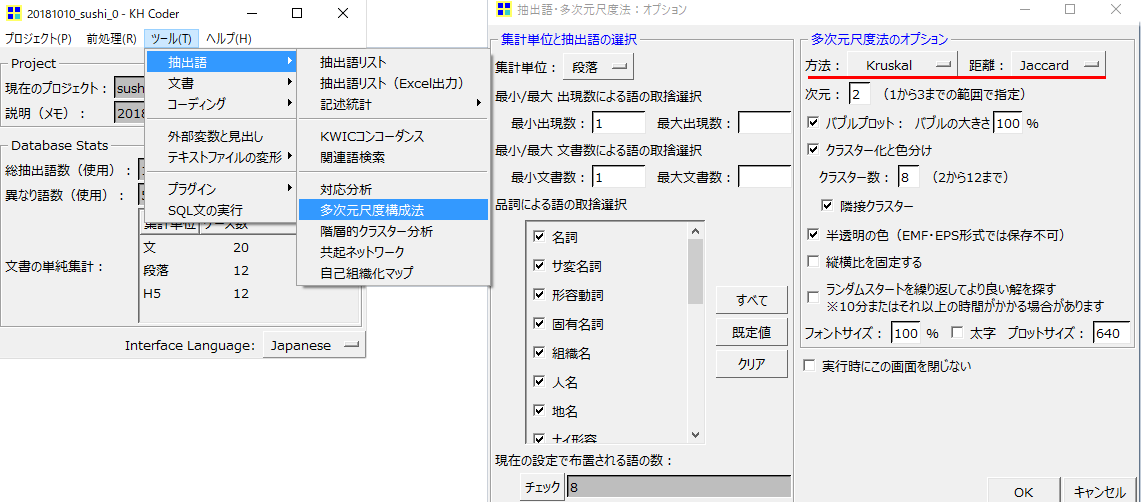
・「ツール」→「抽出語」→「多次元尺度構成法」の順でクリックします。
【集計単位】:「H5」「段」「文」のどれかを選択します。
【最小/最大出現数による語の取捨選択】:今回は最小出現数「1」に設定しました。
【最小/最大文書数による語の取捨選択】:集計単位で「段」を選択していれば、文書イコール「段」です。
【品詞による語の取捨選択】:デフォルトでOKです。必要に応じて設定して下さい。
【方法】:座標を計算する関数を選択します。デフォルトの「Kruskal」でOKです。
【距離】:距離を計算する方法を選択します。デフォルトの「Jaccard」でOKです。
【次元】:「2」が見やすいです。「3」で設定すると立体的な描画になります。
その他の設定はデフォルトのままでOKです。
分析結果
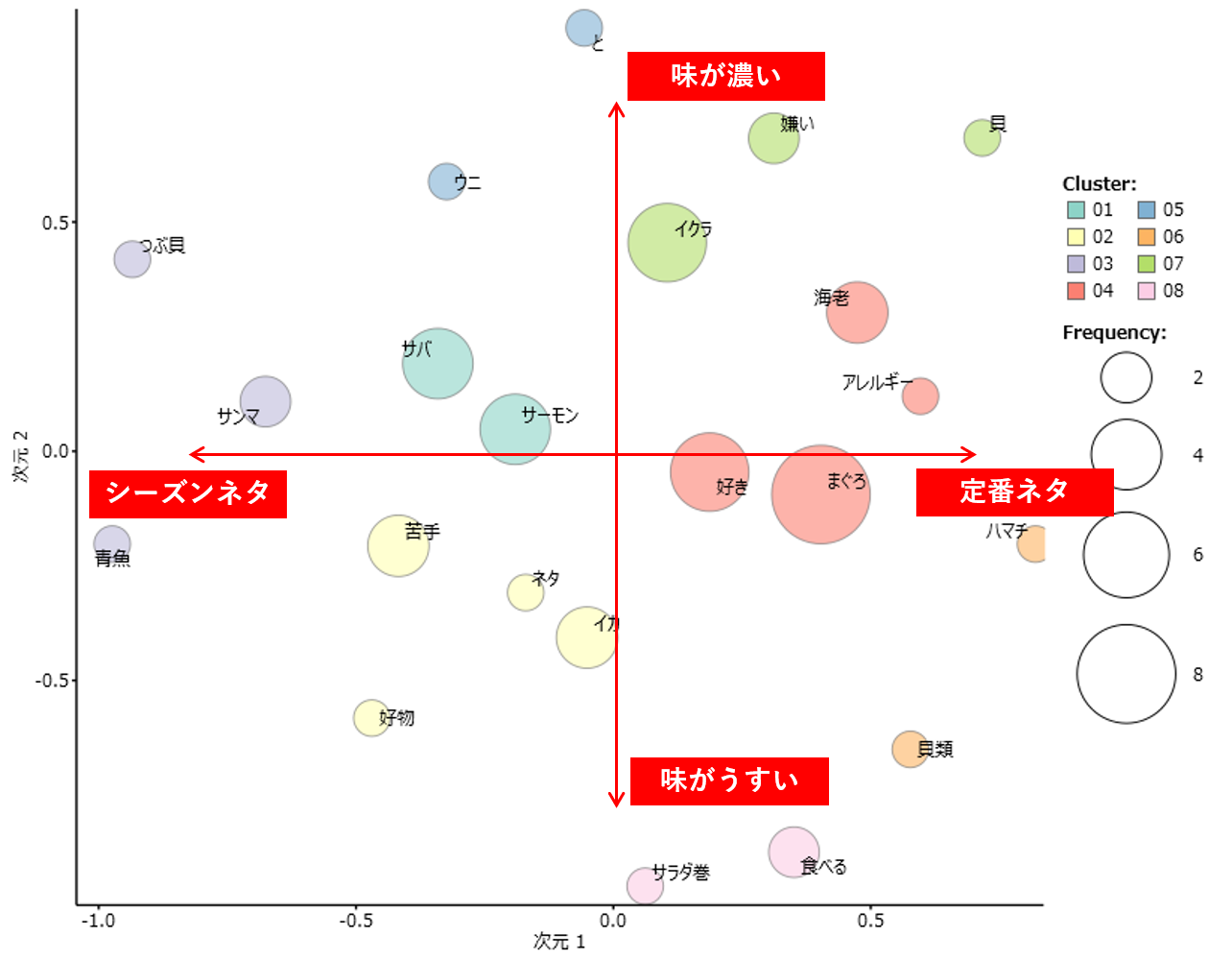
・クラスターで色分けされたバブルプロットが表示されます。
・バブルの大きさは「語」が出現する回数に比例して大きくなります。
・(赤い矢印と文字は筆者が記入したものです)
結果から何が解るのか?これが多次元尺度構成法の最大の課題です。
座標は「語」と「語」の距離を、バブルの大きさは「語」の出現回数をを示すだけです。
・最大の課題とは、軸に意味がないこと
・対応分析のようなマーカーになる(外部変数)要素がないことです。
分析者が軸の意味を自分で考えなくてはなりません。
*今回の「分析対象テキスト」でははっきりとした軸は見えません。筆者自身が縦軸、横軸の意味を例として追加しています。あくまでも例としてご覧ください。
・X軸は右側に「まぐろ」「海老」があるので右が年間定番ネタ
・「サンマ」「サバ」がある左側をシーズンネタにしました。
・Y軸は「イクラ」「ウニ」がある上側を味が濃い
・「イカ」「サラダ巻」がある下を味が薄い、
このように意味付けしました。仮にバブルの大きさイコール人気だとすると、「イクラ」は年間定番のなかの味が濃いネタでは人気がある、このような見方が可能になるのだろうと思います。
以下の抽出語/コードは分析から省かれました
メッセージ
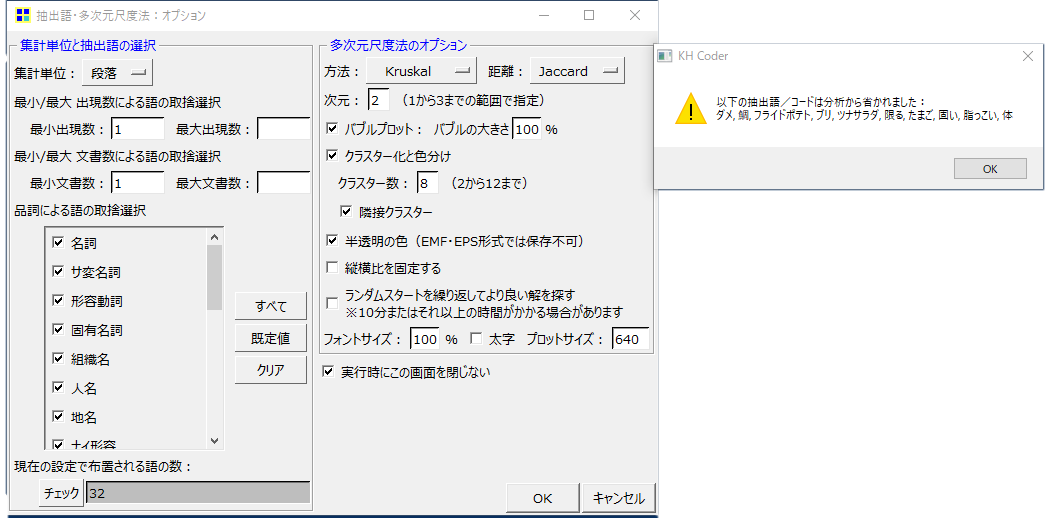
多次元尺度構成法で画像のようなメッセージがあらわれることがあります。特に今回のように「段」数が少なく、「語」数も少ないようなときに表示されます。これは「語」と「語」の距離計算の結果がゼロになるときに起こる現象です。
Rコマンド
check4mds <- function(d){
jm <- as.matrix(Dist(d, method="binary"))
jm[upper.tri(jm,diag=TRUE)] <- NA
if ( length( which(jm==0, arr.ind=TRUE) ) ){
return( which(jm==0, arr.ind=TRUE)[,1][1] )
} else {
return( NA )
}
}
while ( is.na(check4mds(d)) == 0 ){
n <- check4mds(d)
print( paste( "Dropped object:", row.names(d)[n]) )
d <- d[-n,]
}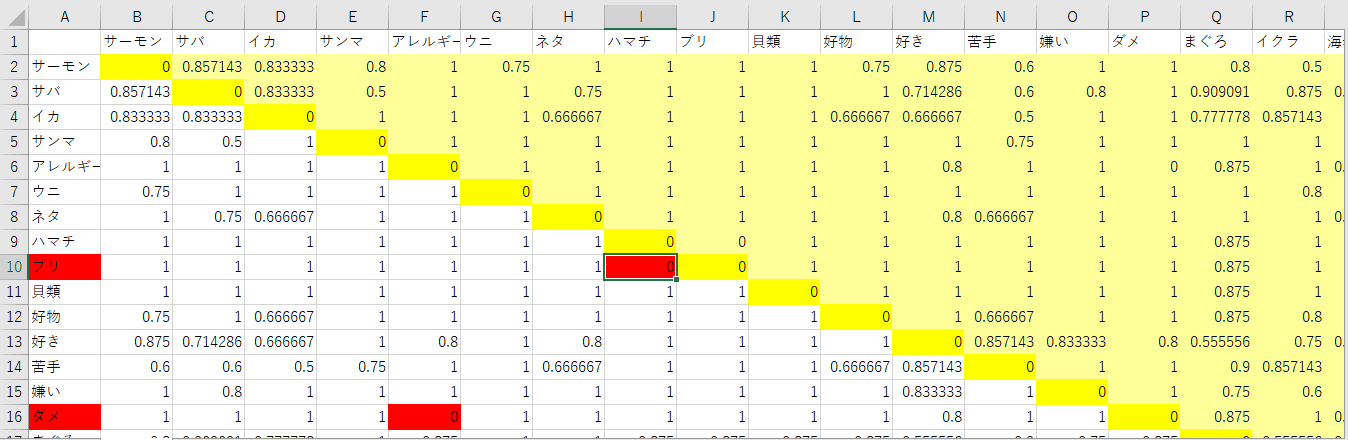
「語」と「語」の距離を計算してマトリクスを作成します。
・上三角成分(黄色い部分)、対角成分(濃い黄色い部分)を含めてを全て NAに変換します。
・下三角成分(白い部分)のなかで距離がゼロになる要素(赤い部分)を含む行を除外して多次元尺度構成法用のデータにします。
・これに基づいて除外する前に除外する行名をメッセージとして表示します。
結果は、
・「ブリ」と「ダメ」がゼロになるので、「ブリ」と「ダメ」がメッセージで表示されます。
距離がゼロになるとき
| テキスト | 年代 | 性別 | サイト | ID |
| ハマチ、ブリ、まぐろ、ツナサラダです。 | 40代 | 女 | B | 8 |
「ブリ」と「ハマチ」を例にします。
・「ブリ」「ハマチ」がそれぞれ出現するのはID8の「段」です。
・「分析対象テキスト」のその他の段には全く出現しません。
今回の分析は「段」で実施しています。
・従って「語」と「語」の距離は「段」を単位に計算します。
もしも、「ブリ」「ハマチ」が複数の「段」に出現しているとしたら距離を計算することが可能です。ところが今回の「分析対象テキスト」では特定の1「段」に同時に1回だけ出現しているので「ブリ」と「ハマチ」の距離はゼロです。
では「ブリ」が省かれて「ハマチ」がなぜ残るのか?
これは、下三角成分を分析データとして使うロジックだからです。もしも上三角成分を使うのであれば「ハマチ」が削除されることになります。