
語の出現場所をビジュアル化する
たいがいのことができるタブロー、はたして、対応分析図をから「語」が出現する位置へドリルダウンできるのでしょうか。
対応分析図からドリルダウン
対応分析結果
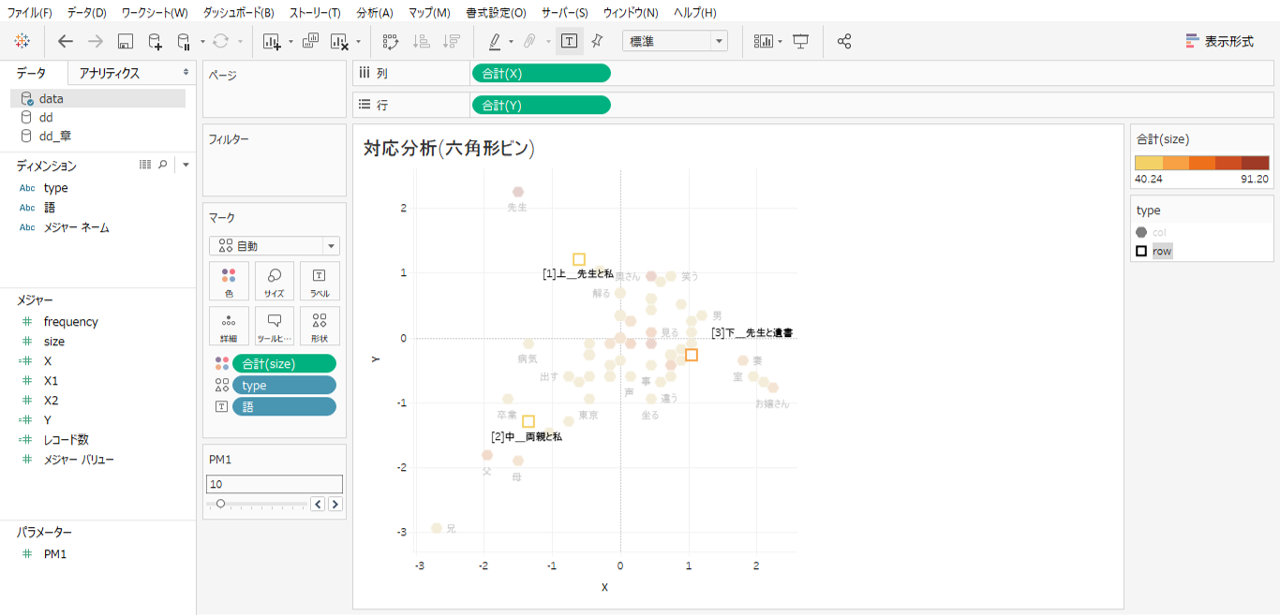
対応分析は「語」(col)と「外部変数」(row)の位置、「語」と「語」の位置、「外部変数」と「外部変数」の位置、それから「語」の出現回数を全体的に俯瞰することを目的にしています。
対応分析は確かに全体的俯瞰にはもってこいなのです。
KHcoderの場合、対応分析の「語」をポチっと押すとKWICコンコーダンスが開いて「語」の使われ方へドリルダウンすることができます。
対応分析結果は「語」等の位置を全体的に表現するものですから、そこからドリルダウンしたいのは「語」の使われ方よりもむしろ「語」が出現するもっと詳細な位置や回数なのです。
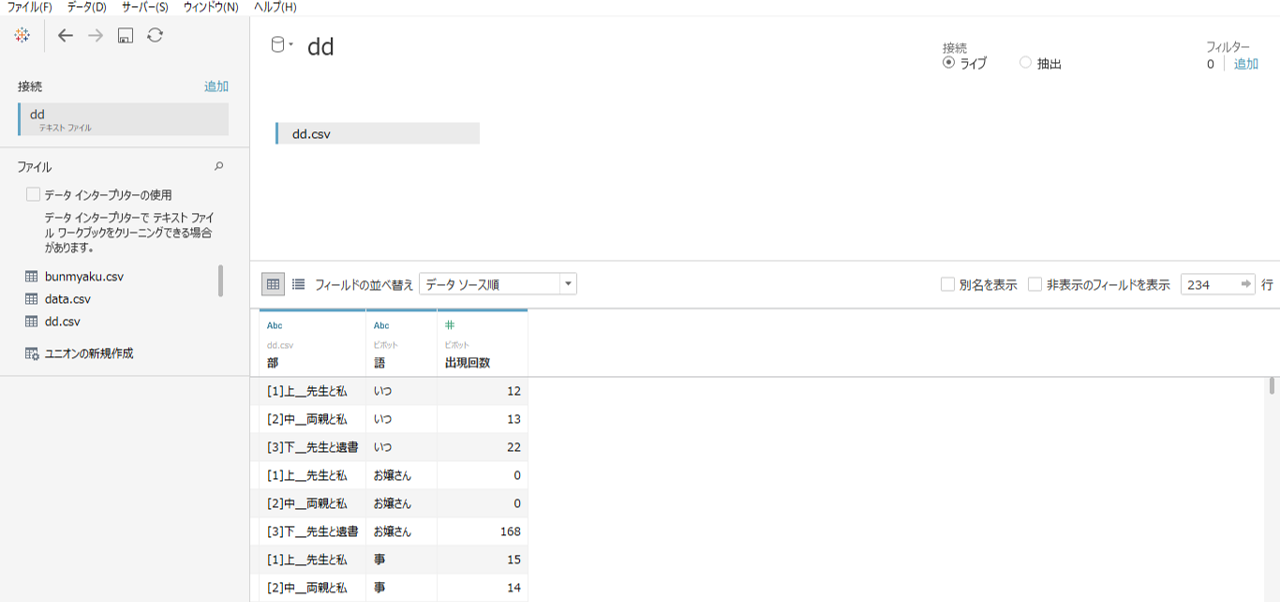
「語」が出現する「部」のデータ
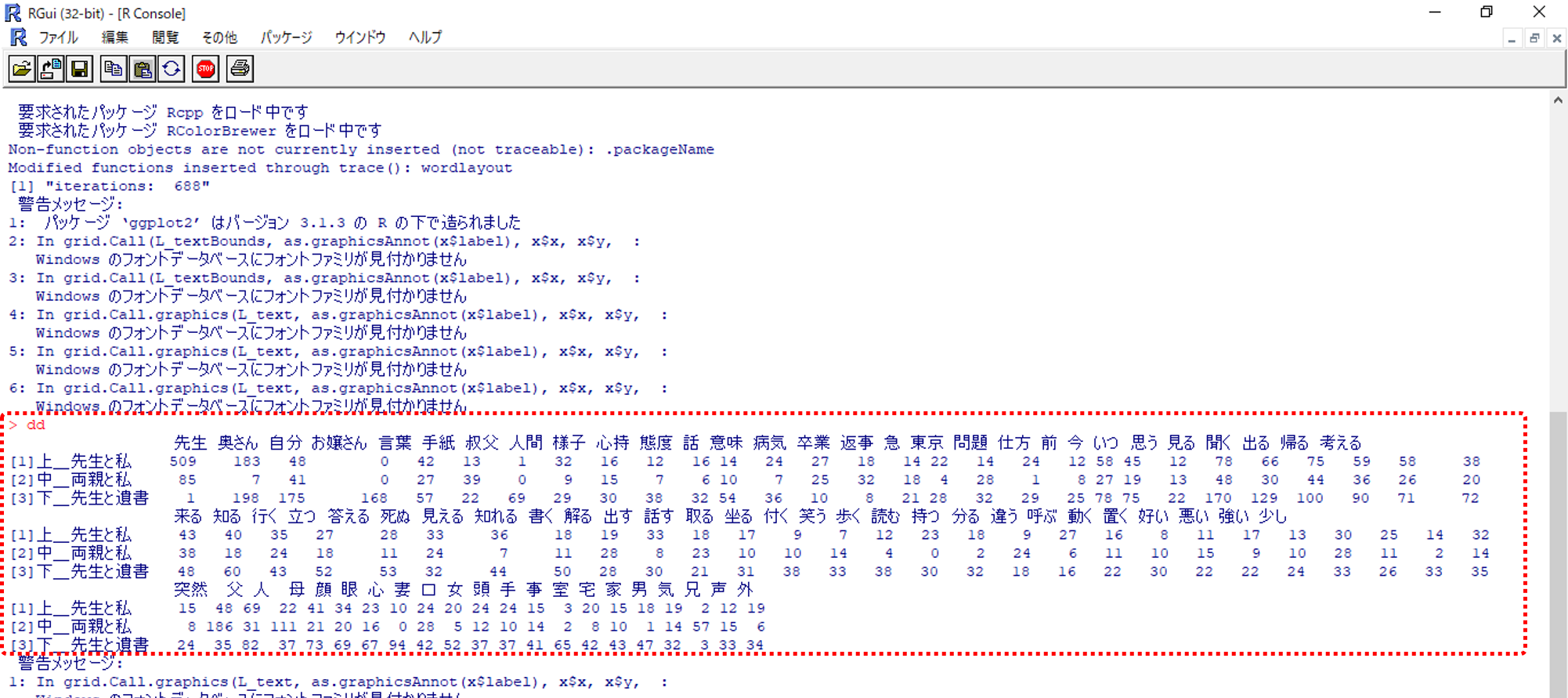
・対応分析結果の右下「保存」をクリックしてRソース形式で出力します。(KHcoder 15. 対応分析(第2回))
・Rを立ち上げてファイルをドロップします。
・Rへ「dd」と入力すると画像のように行が「部」列が「語」のデータを表示できます。
・この「dd」をCSVで出力して保存します。
#Rからデータを出力するコマンド write.csv(dd, "ディレクトリ名/dd.csv")

タブローから接続
ピボットします
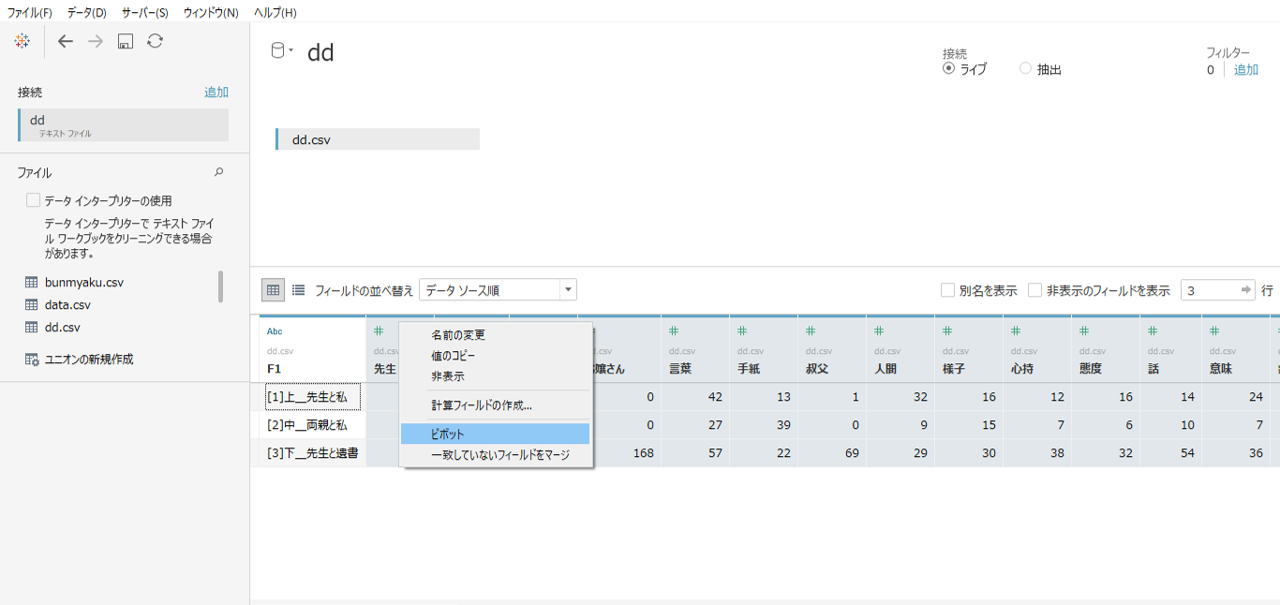
・データへ接続して、「部」の列を残して「語」の列をすべてピボットします。
・フィールド名をととのえます。
ツリーマップ
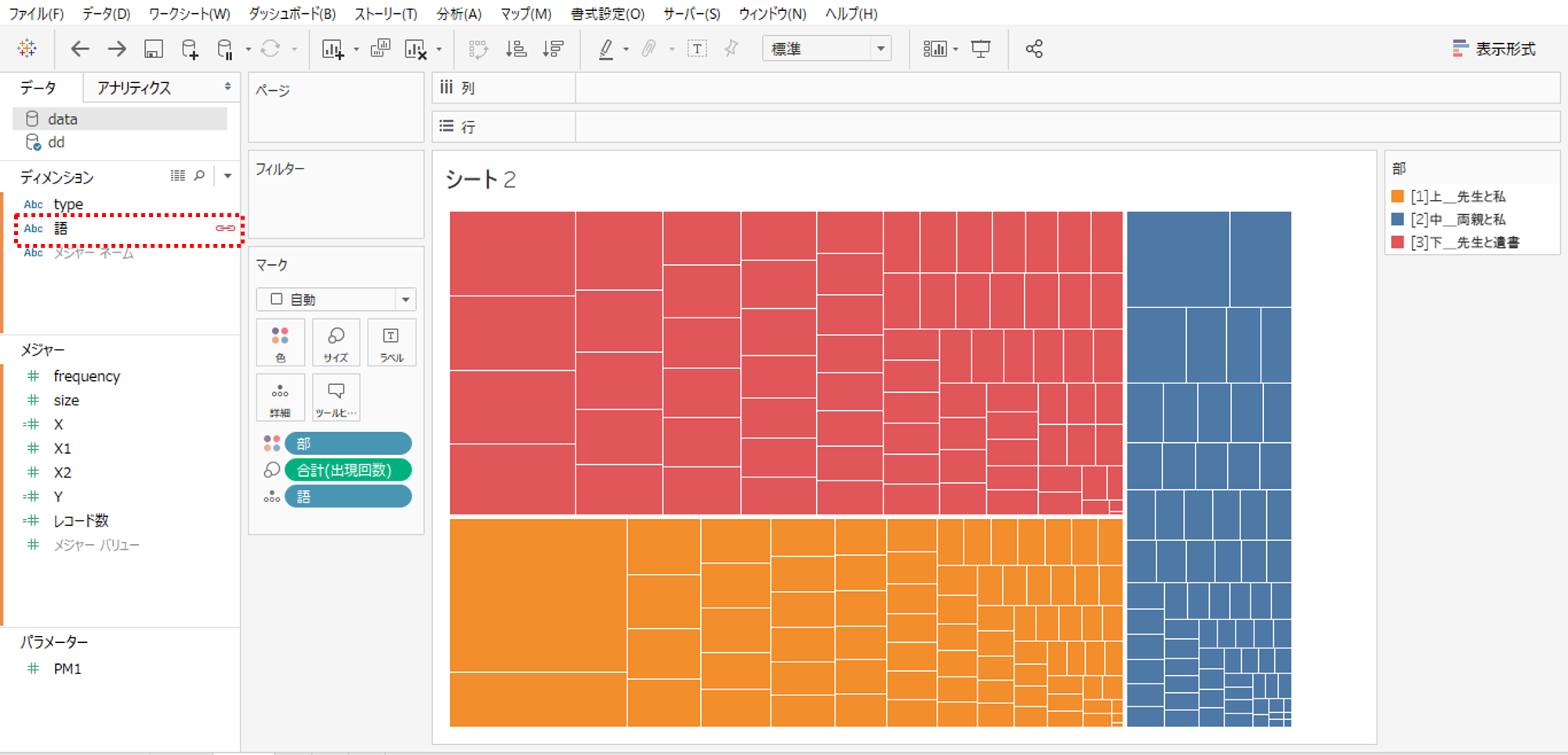
・「部」を色
・出現回数をサイズ
・「語」を詳細へドロップするとツリーマップを描くことができます。
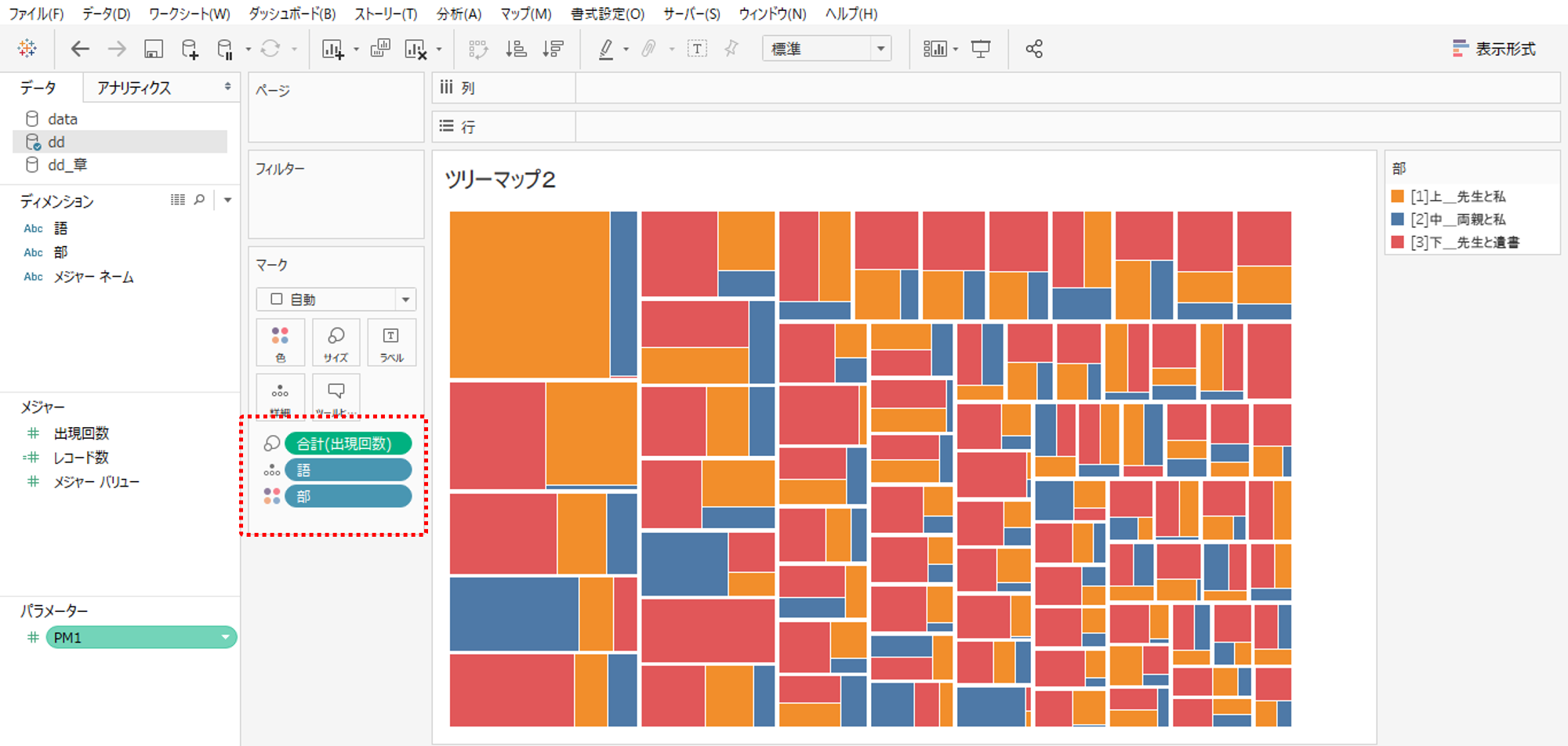
このときに六角形ビンのデータと「語」でデータブレンドしリレーションするように設定します。リンクマークがオレンジ色になればOKです。
カードの「部」と「語」の順番を入れ替えるとビジュアルを変更することができます。
ダッシュボード
ダッシュボード作成
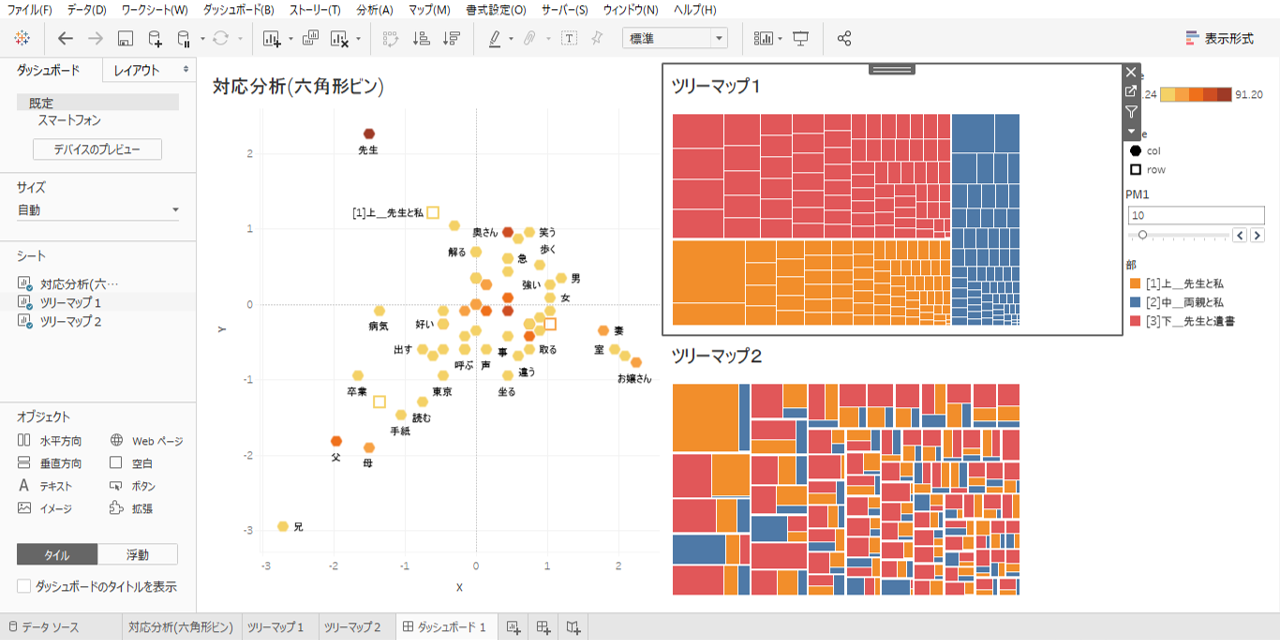
・ダッシュボードへ六角形ビン対応分析とツリーマップ2種類を貼り付けます。
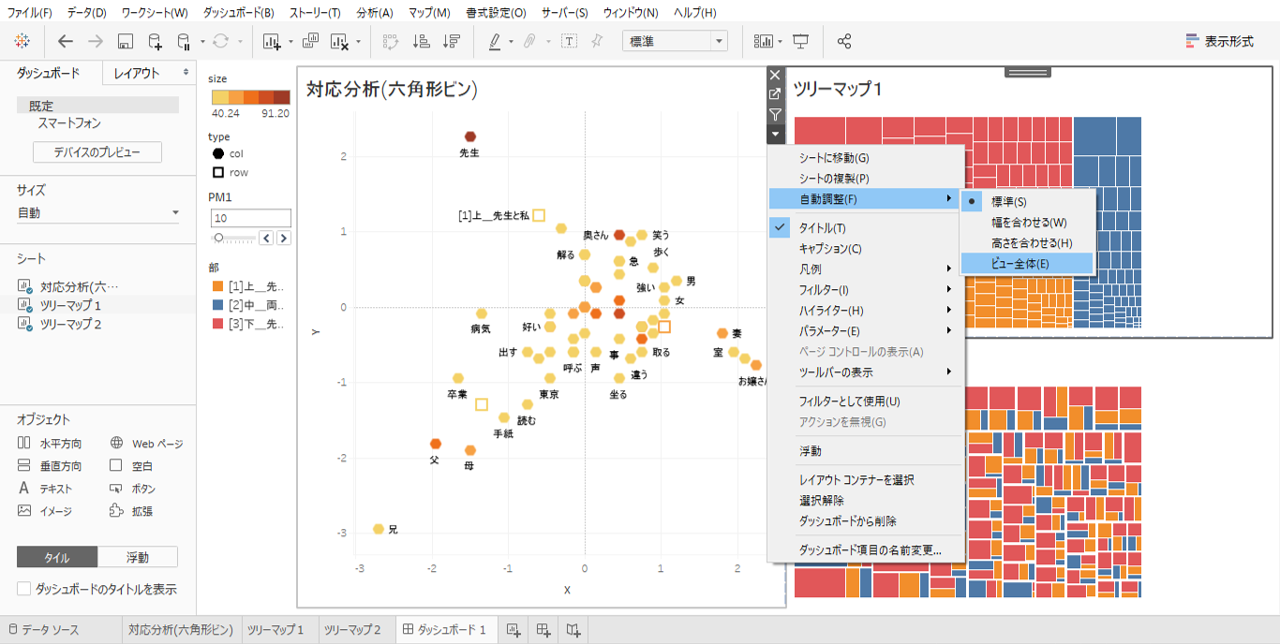
・ツリーマップの▼をクリック
・「自動調整」→「ビュー全体」を選択します。
これで、枠の中いっぱいにツリーマップを表示することができます。
アクションを追加
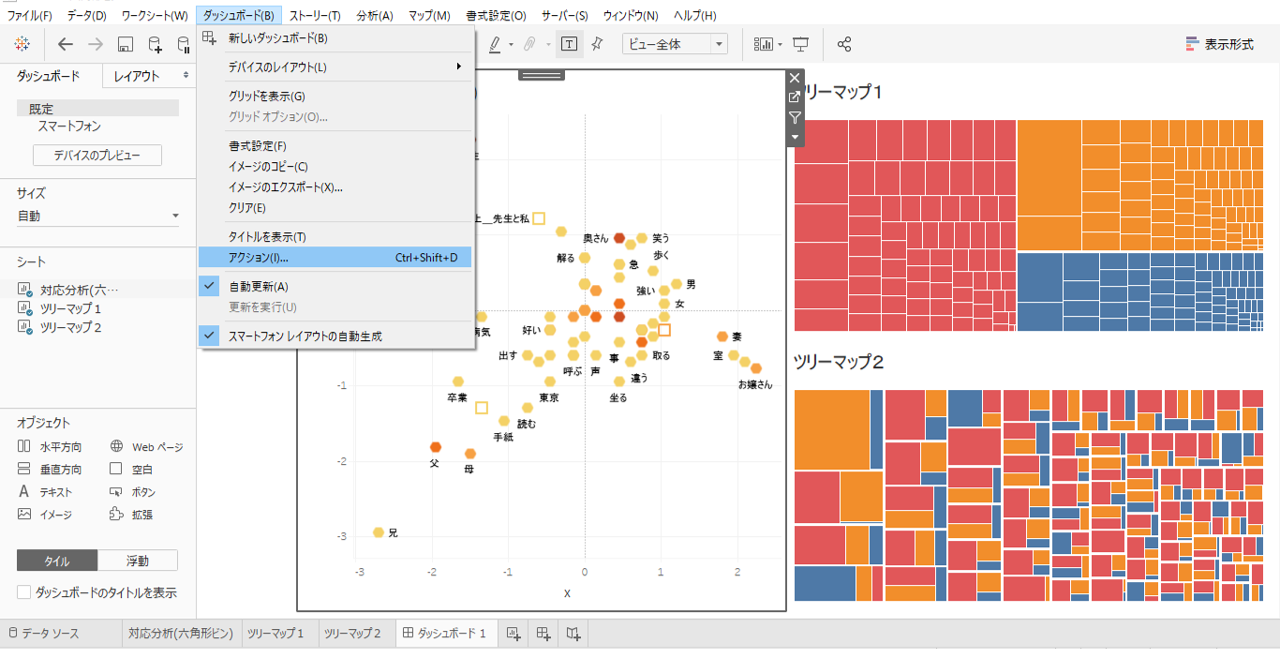
・「ダッシュボード」→「アクション」を選択します。
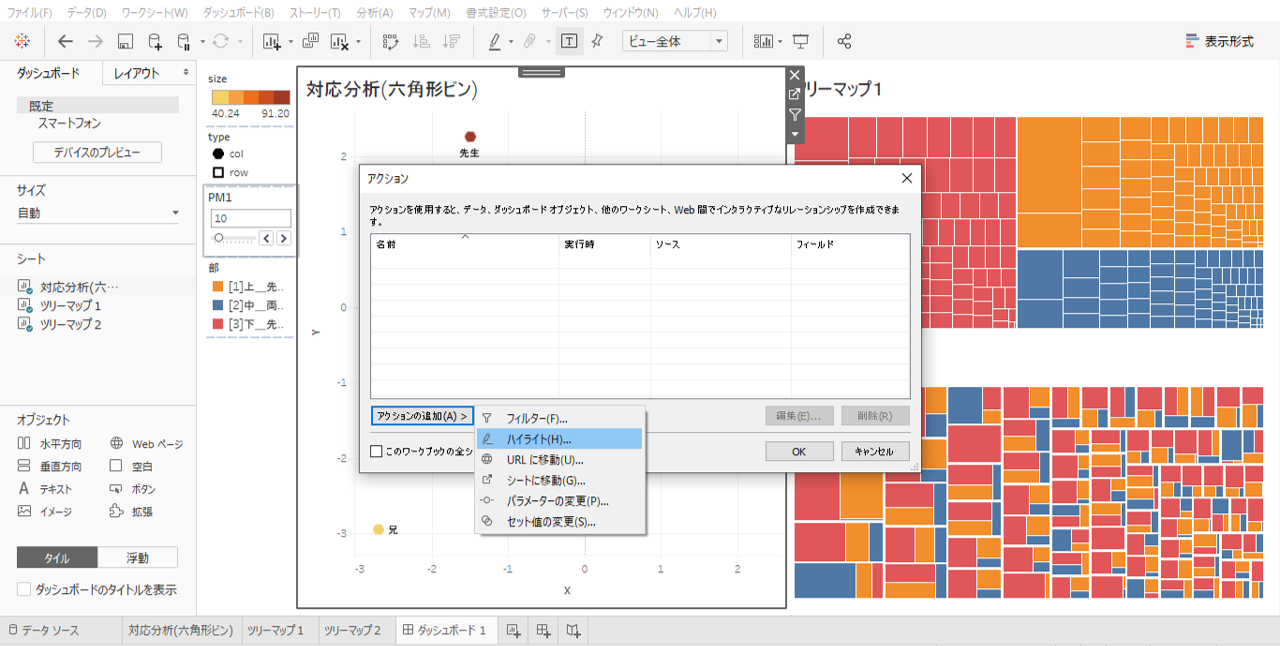
・「アクションの追加」→「ハイライト」を選択します。
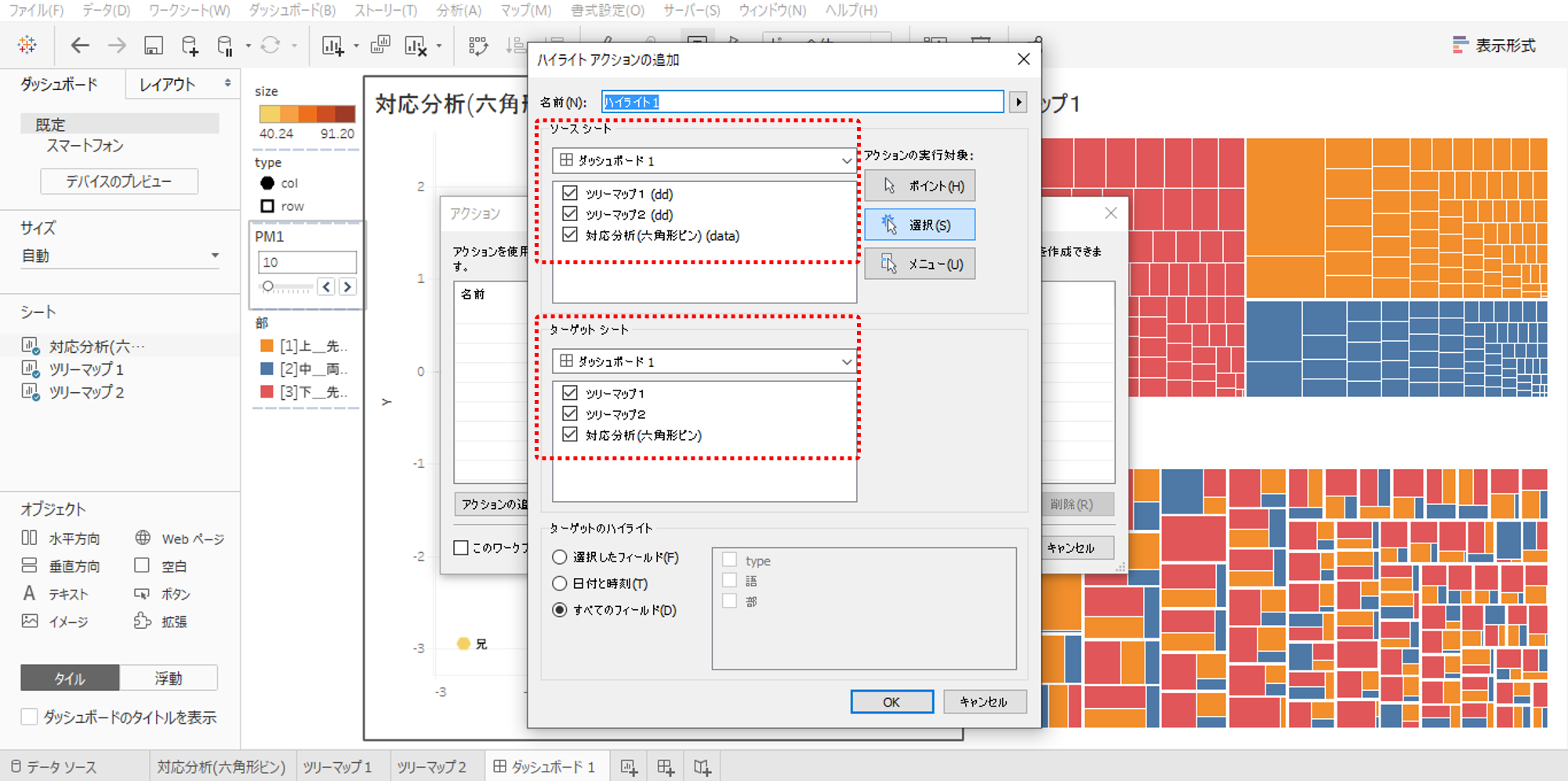
「ソースシート」というのは、アクションのもとになるシートです。画像の状態なら、3種類のシートのうちどこかのデータポイントを選択すると(クリックすると)、「ターゲットシート」(画像の設定ではすべてのシート)が連動してハイライトされるという設定です。
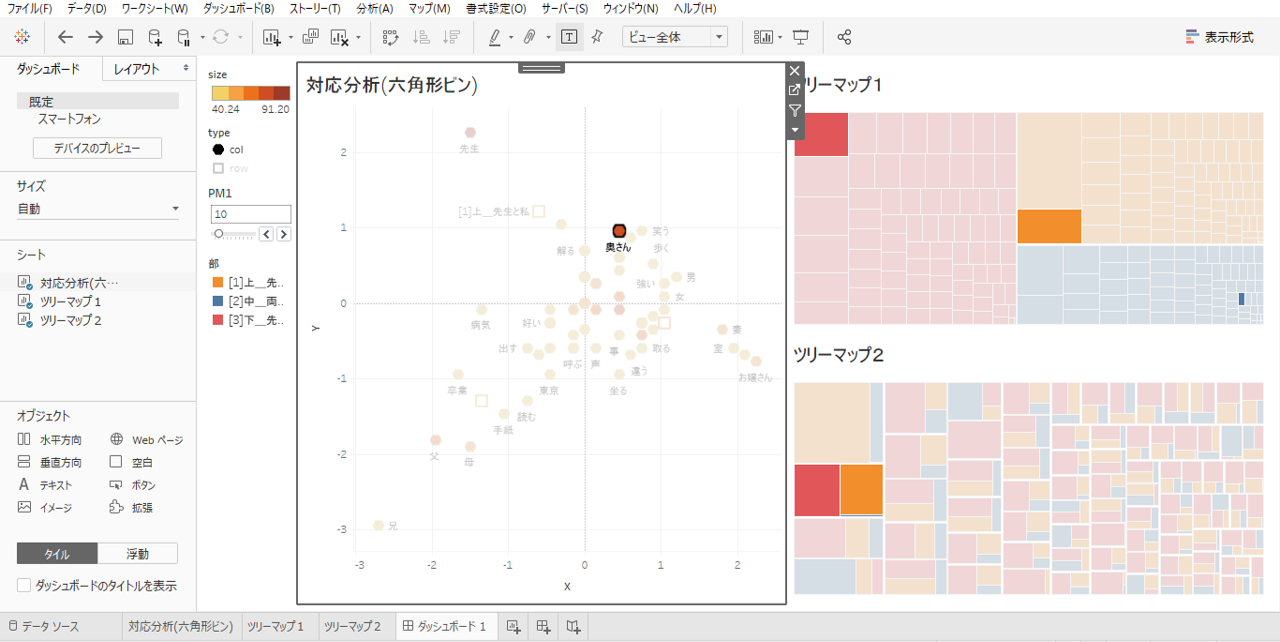
六角形ビンの「奥さん」をクリックします。
ツリーマップ1から「奥さん」という「語」は、
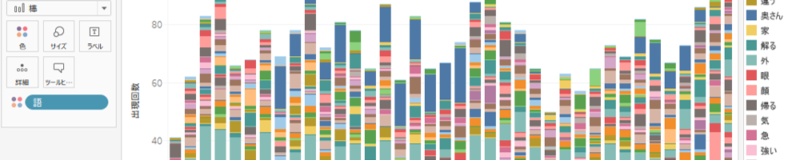
・第3部で最も出現回数が多い「語」です。
・第1部では2番目に出現回数が多く
・第2部の出現回数が少ないことがわかります。
ツリーマップ2から
・第3部と第1部に出現する回数はほぼ同じといったことがわかります。
ツリーマップと連動することで「語」が各「部」のなかで出現する回数・順位を確認することができるようになりました。
「章」までドリルダウン
「章」のデータを抽出
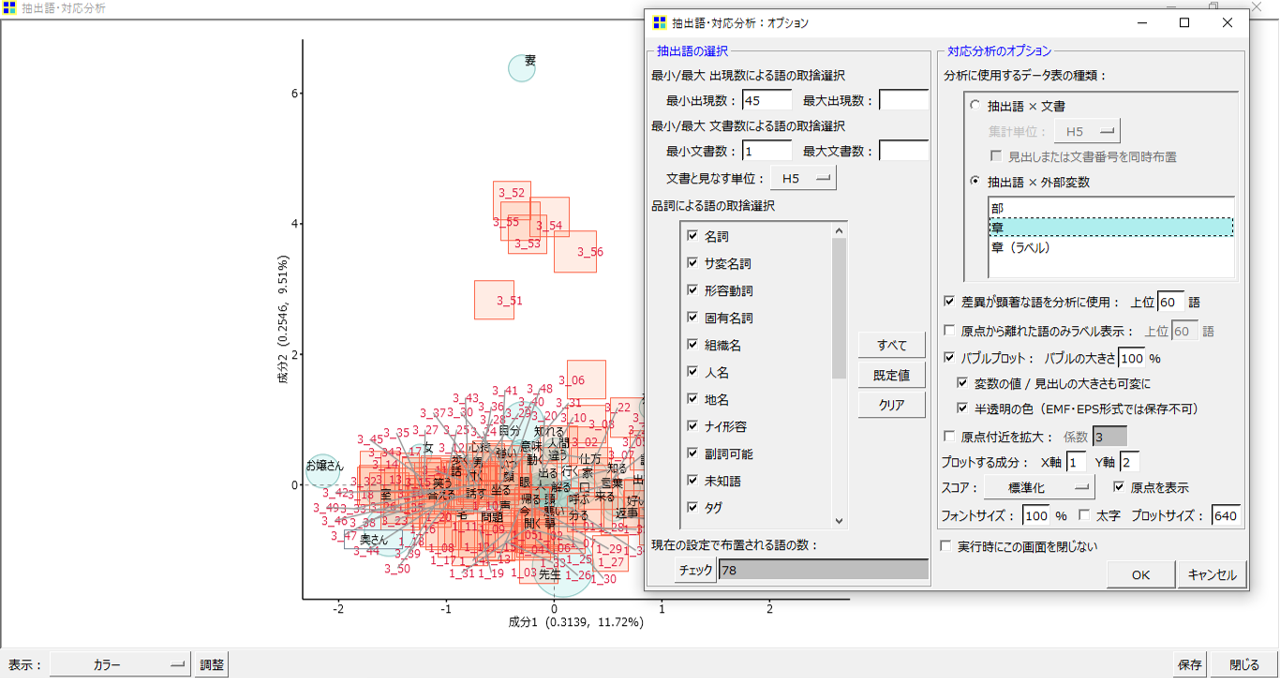
・KHcoderの対応分析の設定を、「抽出語」×「外部変数」、「章」に設定します。
・「部」と同様の手順で、「保存」からRソースを出力
・Rへ投入して「dd」のデータをCSVで取り出します。
行が「章」、列が「語」のデータになります。
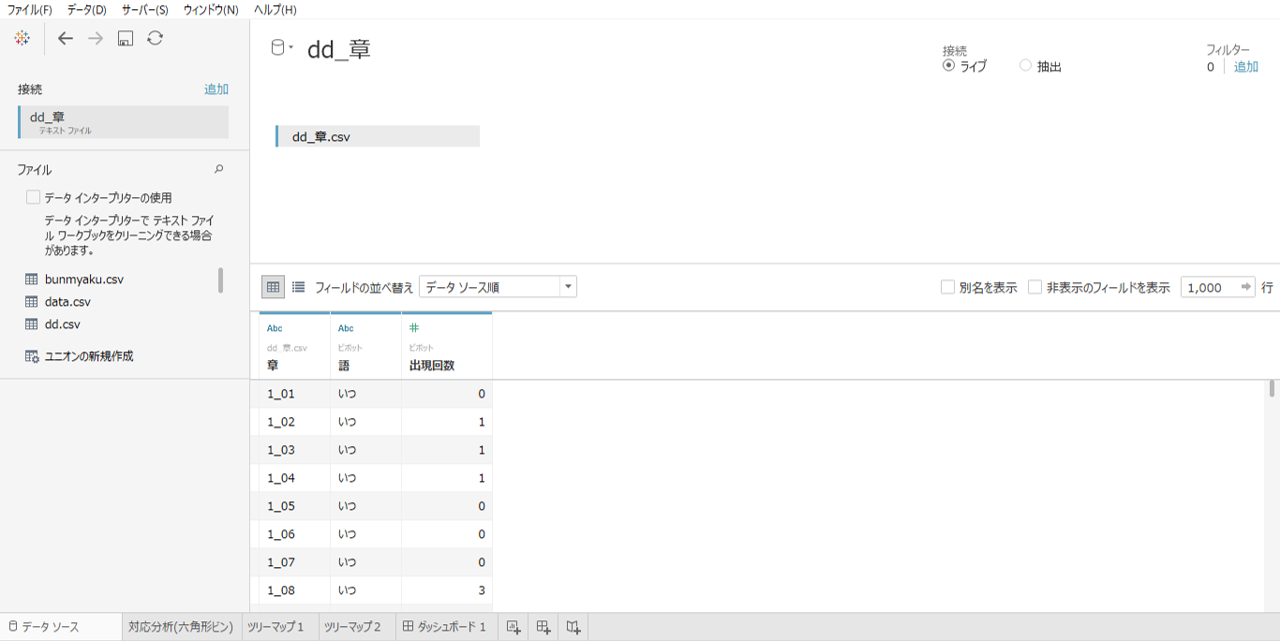
・タブローからCSVへ接続します。
・「部」のときと同じようにすべての「語」の列をピボットします。
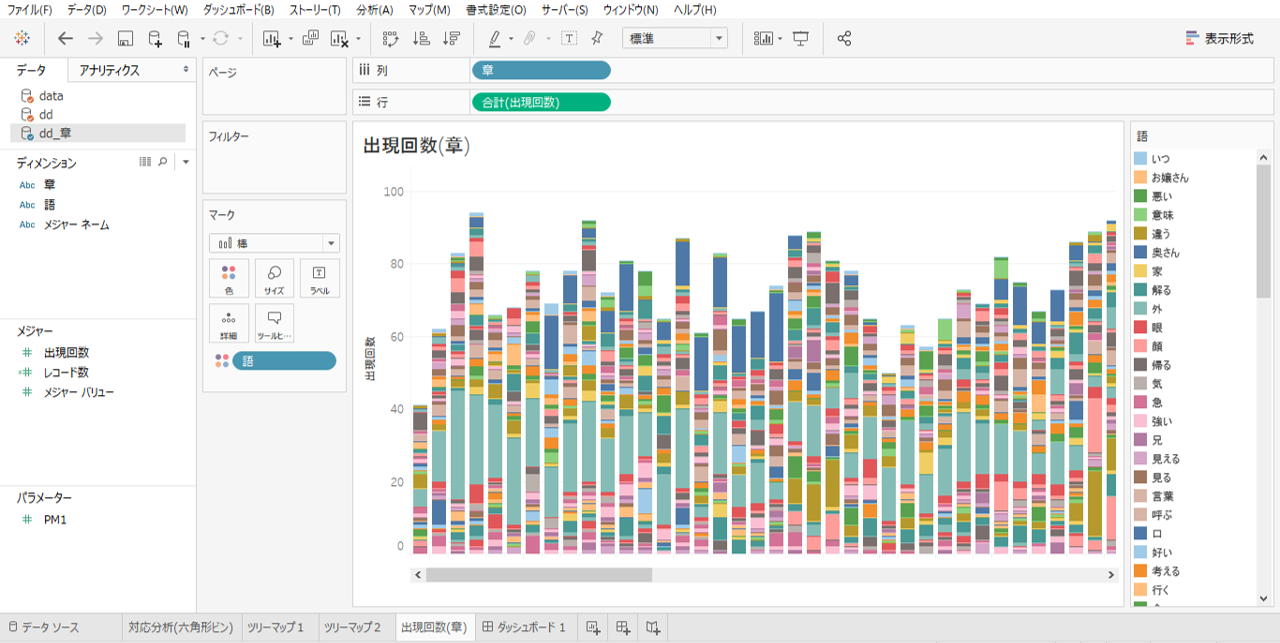
・新規ワークシートで
・「章」を列シェルフへ
・「出現回数」を行シェルフへドロップします。
・「語」で色を設定します。
・ここでもすべてのデータがリレーションするように3種類のデータソースを「語」でブレンドします。
ダッシュボード
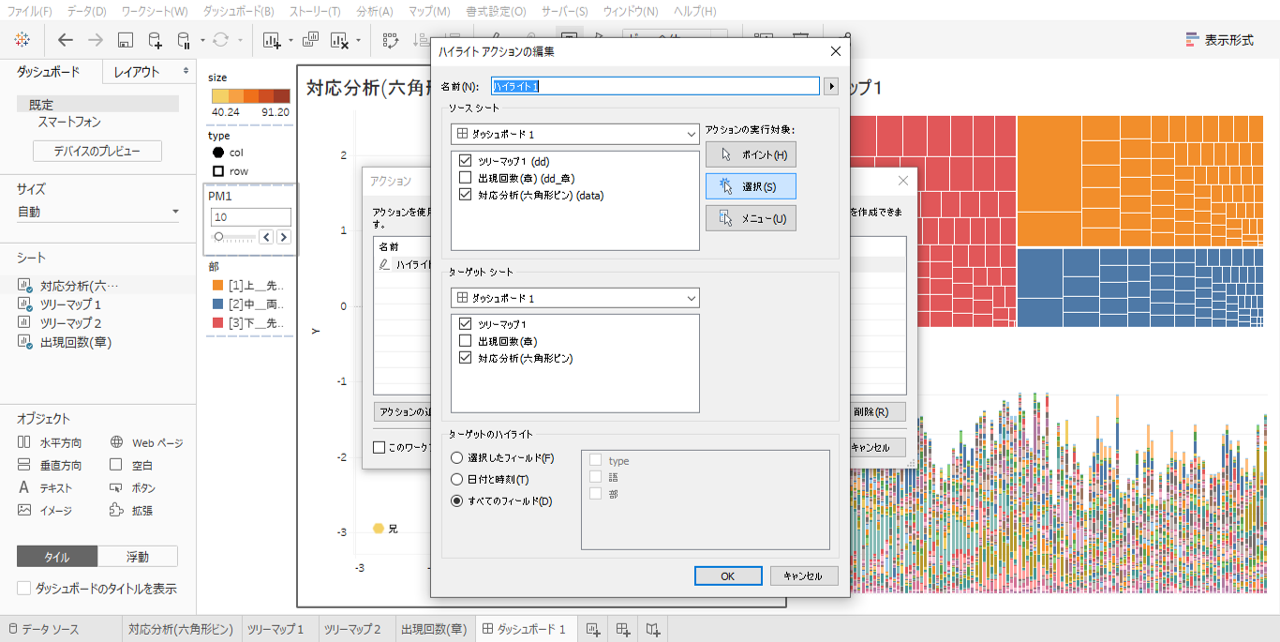
・ダッシュボードからツリーマップ2を削除して
・出現回数の棒グラフを貼り付けます。
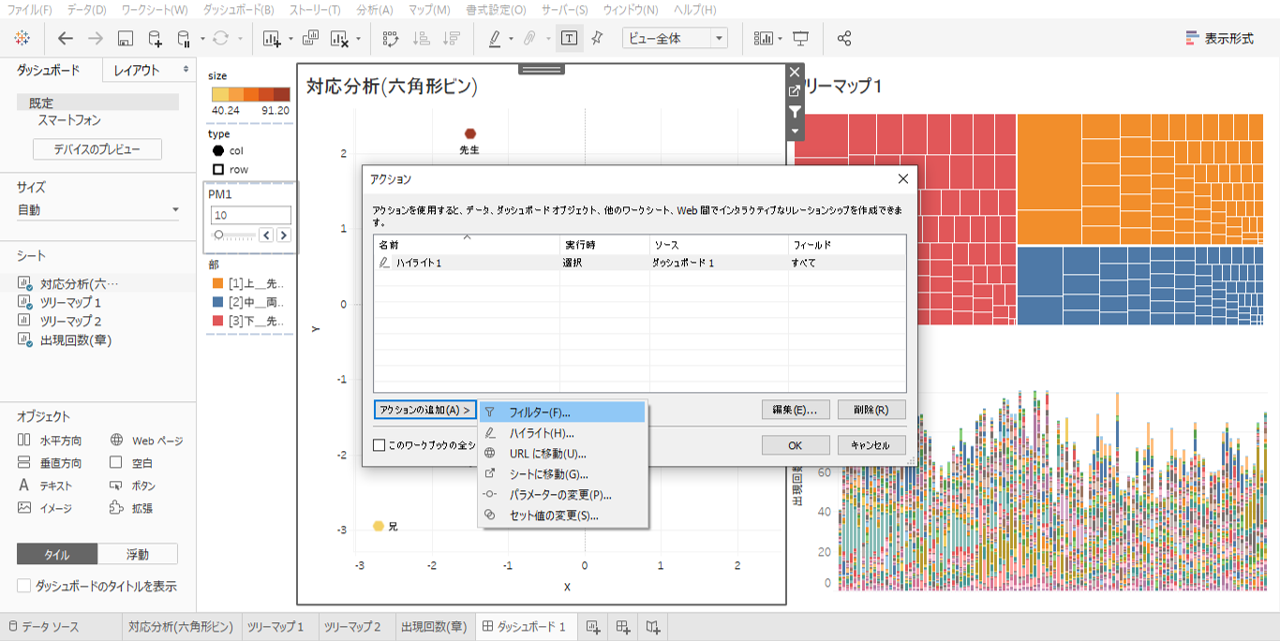
・ダッシュボードアクションの窓を開いて
・出現回数シートはハイライトアクションから除外します。
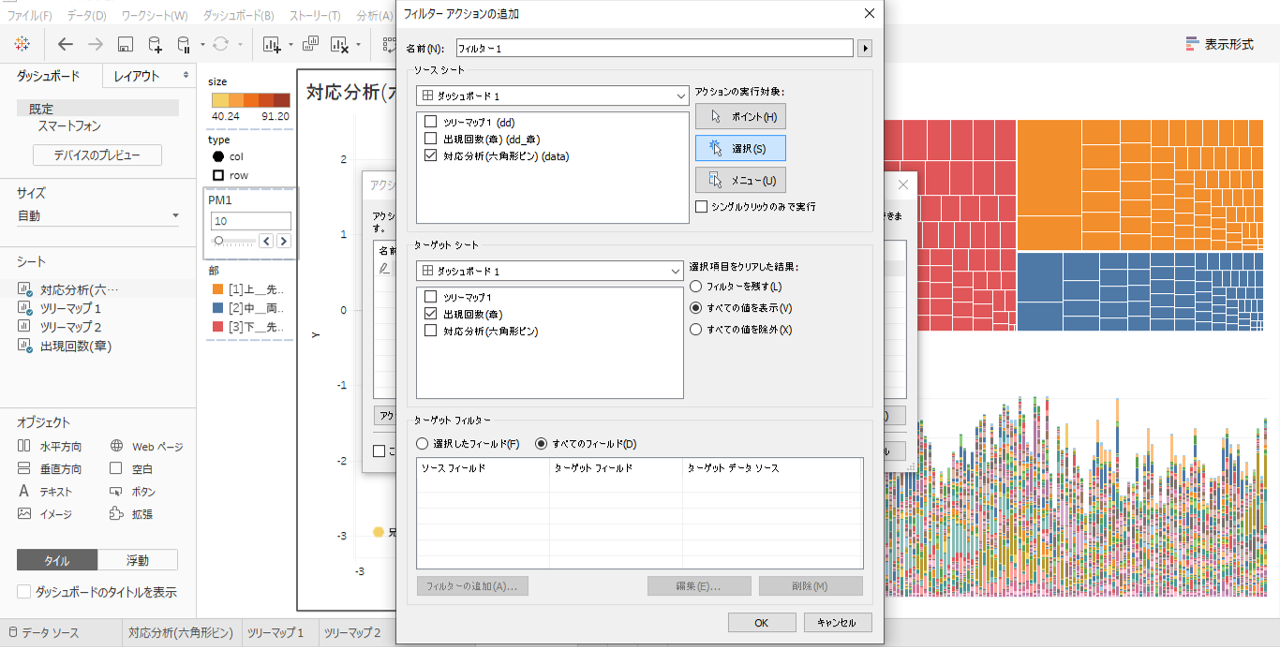
・「アクションの追加」→「フィルター」を選択します。
・ソースシートが六角形ビンシート
・ターゲットシートが出現回数シートです。
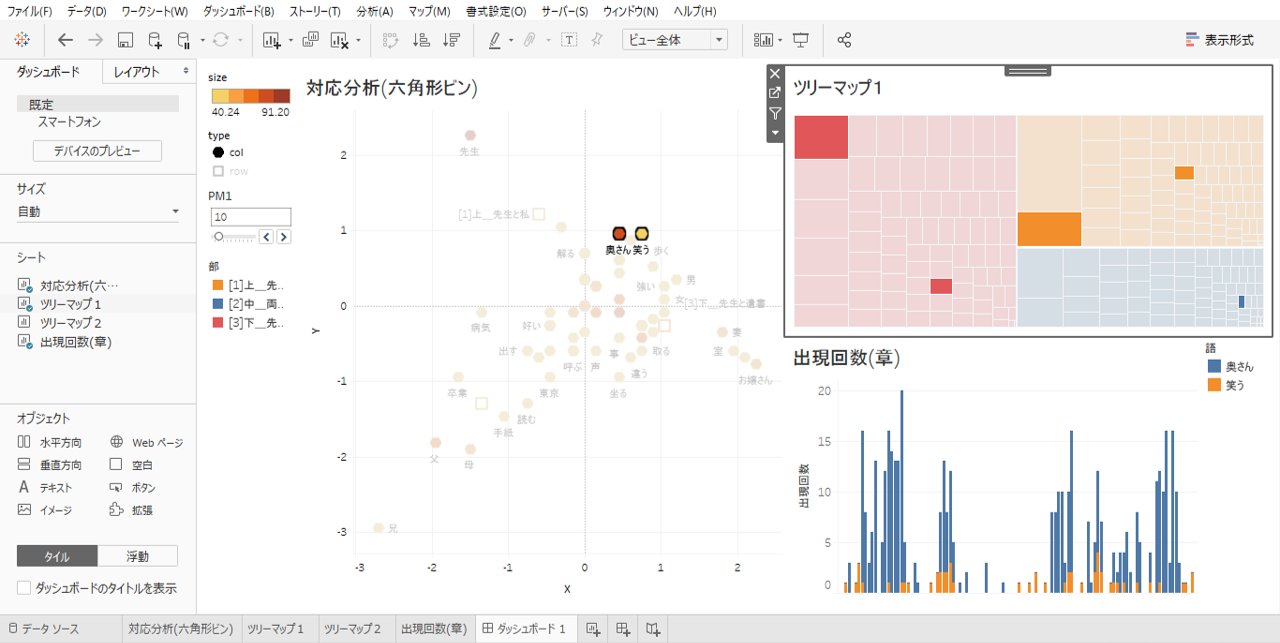
六角形形ビンのデータポイントをクリックするとツリーマップ1の「語」がハイライトされ、出現回数の棒グラフはフィルターされます。画像のように複数選択も可能です。