
令和元年通信利用動向調査 Tableau Prepでやってみる
タブロープレップでデータを整えます。1表を2表へ分割、そしてユニオンで1表まとめるテクニックを紹介しています。
データについて
令和元年通信利用動向調査
<データ出典>
政府統計の総合窓口「e-Stat」(https://www.e-stat.go.jp/)
情報通信・科学技術>通信利用動向調査>令和元年通信利用動向調査>世帯全体編>統計表セット(全22表+アンケート)を加工して作成
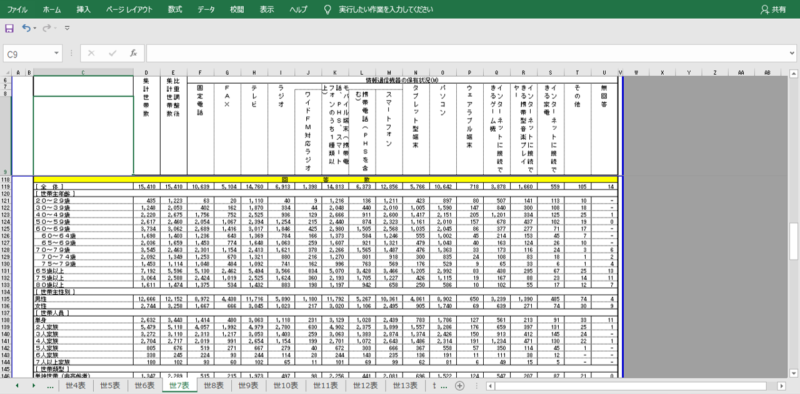
もとデータです。今回はエクセルシートの「世7表」を使用します。表のD列とE列は使用しません。
表は、C列の属性、たとえば”世帯主が20~29歳の世帯のうちの5.1%に固定電話がある”というデータになっています。表のD列とE列を除いて数値はすべて割合(%)です。
13行~25行が「世帯主年齢」、27行と28行が「世帯主性別」のように複数行でひとつの束になっていることがわかります。つまり表はひとつのように見えますが、実際には複数のデータ表をタテにくっつけている(ユニオンしている)ものだといえます。
数値の単位が2種類ある
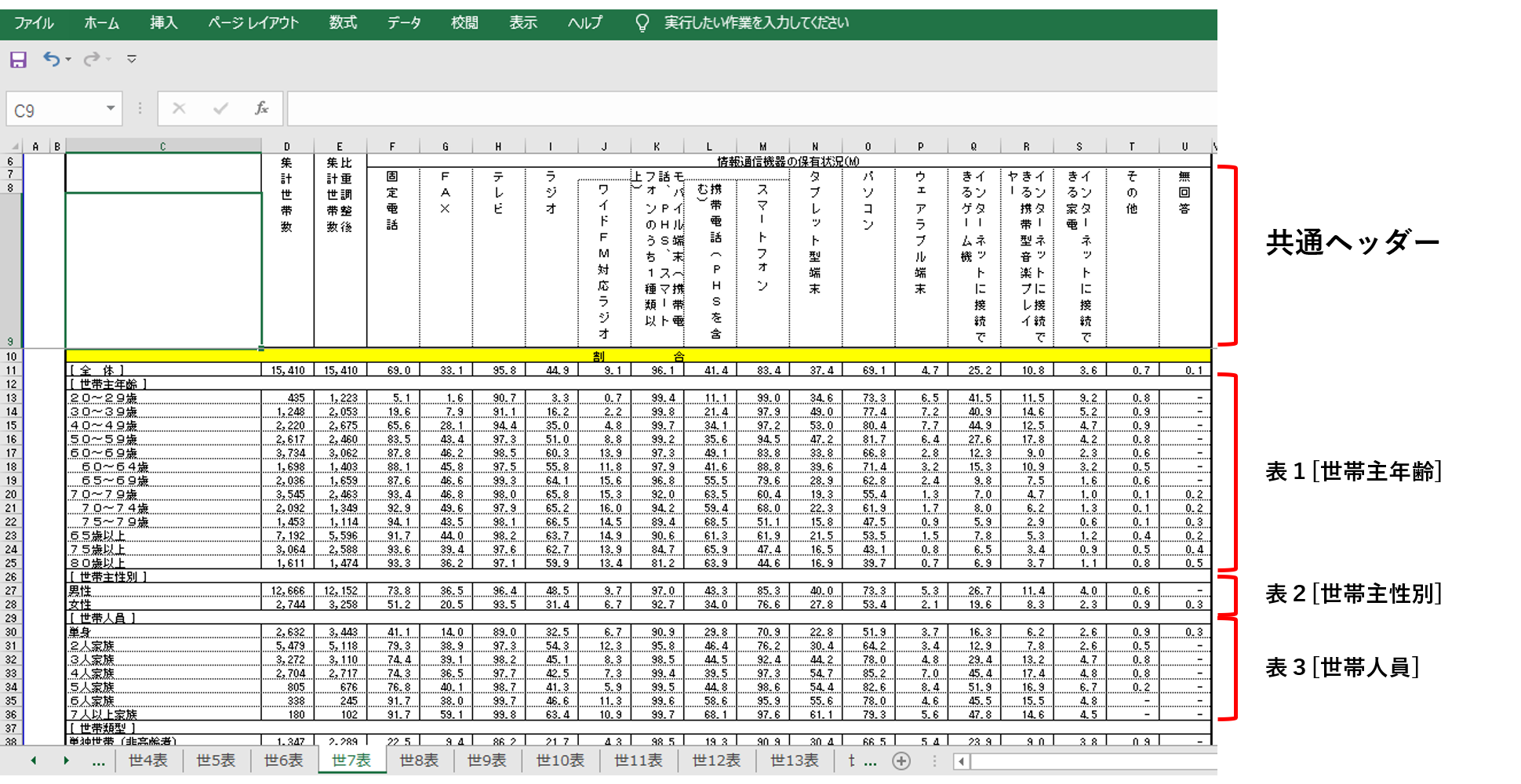
表の下部には別の数値があります。これは実数(世帯数)です。この表には割合(%)と実数(世帯数)の両方の数値があるわけです。
表の数値はアンケート調査結果を集計したものです。もちろんアンケートの対象は無作為抽出だと思います。したがって、この表を分析するときに有効な数値は「割合」です。118行以下はいったん削除してもよさそうです。
表を分析できる形式へ整形する
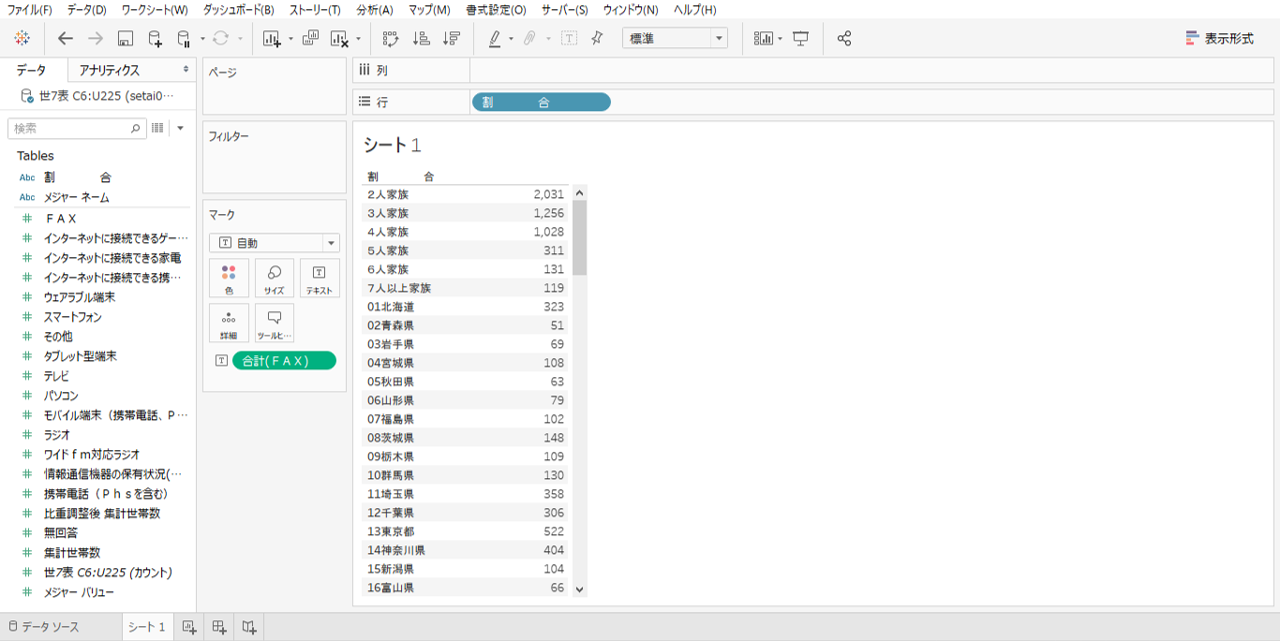
タブローのデータインタープリター機能をつかって表へ接続します。
<ディメンション>
エクセルのC列のすべての行名がディメンションの内訳になります。同じ行名が複数あるときは集約されてユニーク(Distinct)で表示されます。
<メジャー>
D列~U列のすべての列名がメジャーネームになり(同じ列名があっても集約されません)、列の数値がメジャーになります。
メジャーはディメンションごとに集計(合計)されるので、「割合」も「世帯数」も数値はすべて合計されます。
この状態で分析を開始するのは難しそうです。
3ステップで整形できる
① 必要な行だけをとりだす
必要な数値は「割合」だけです。行間の小見出し的な行も不要です。
② 粗い粒度のディメンションをつくる
13行~25行が「世帯主年齢」のように複数行でひとつのかたまりになっています。
「20~29歳」、「30~39歳」・・・のように複数ある属性をまとめるための新規ディメンションを作成します。現在の属性よりも粗い粒度のディメンションの下に現在のディメンションをぶら下げます。
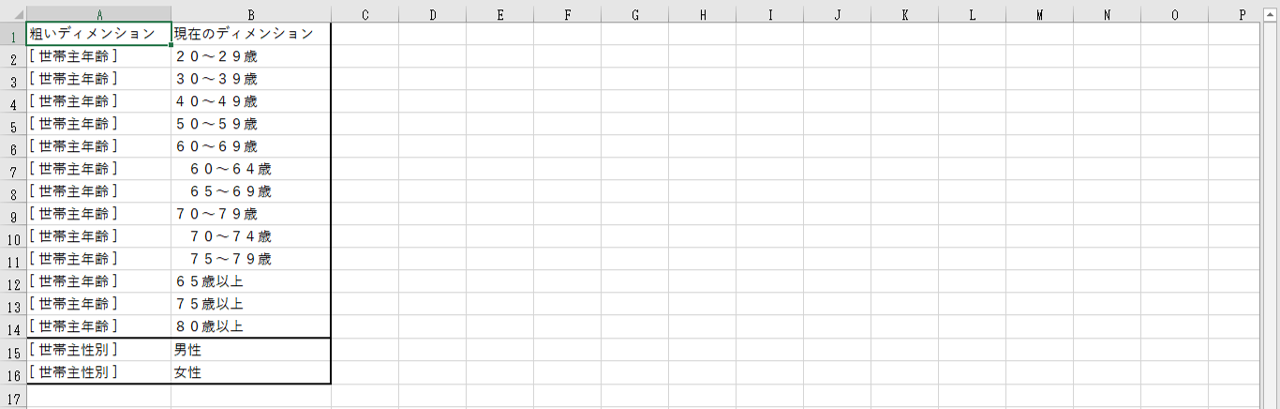
このようになればOKです。
③ 列指向形式へ変換する
現在はクロス集計形式のデータですから数値列がすべてメジャーネームになります。分析で必要とするメジャーは「割合」だけですから、列指向形式へ変換します。
タブロープレップの手順
ちょっとだけエクセルに手を加える
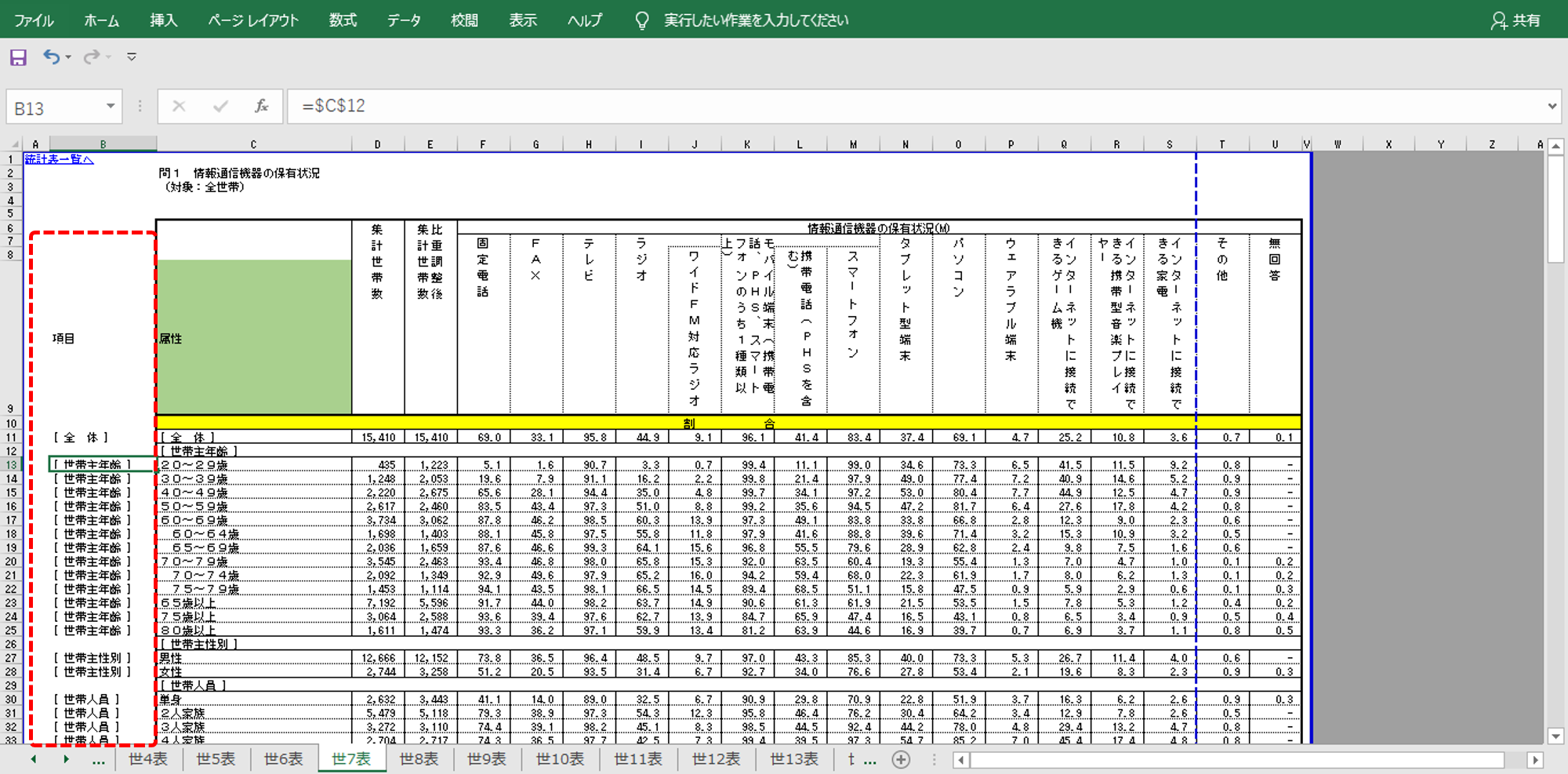
B列へ列名を書き込みます。「項目」にしました。B列の各セルへ粗い粒度になる名称を書き込みます。図のように計算式で書き込みました。数値がない行は空白、表の下部の数値が「世帯数」の行も空白のままです。
E列の列名が空白なので「属性」としました。
これだけです。行列の削除とかは一切おこないません。
表へ接続してフィルターする
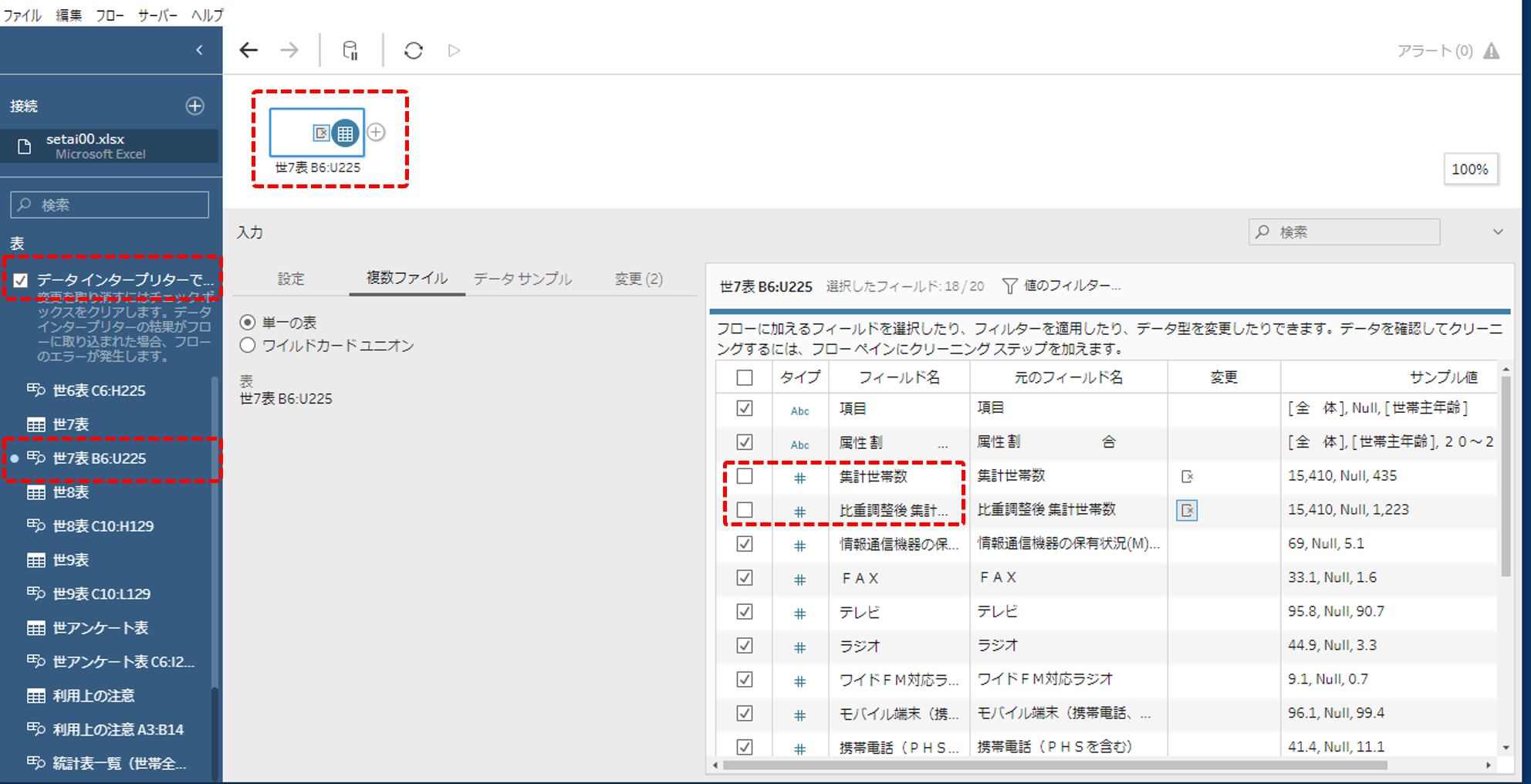
データへ接続します。データインタープリターをチェックします。(これは便利な機能!)「世7表」をドロップします。虫眼鏡のマークがついている方です。
「集計世帯数」と「比重調整後集計世帯数」の列は使用しないので、ここでチェックを外します。

クリーニングステップを追加します。もとデータの列名のセルが結合されていたり、2行に分かれているようなとき、データインタープリターを使用するとフィールド名が思ったとおりになっていないことがあります。フィールド名をチェックして修正します。

「項目」列のNULLを除外します。これで分析に必要な行だけを取り出すことができました。

「項目」フィールドの値をクリーニングします。手順は2回です。
① クリーニング→句読点の削除
② クリーニング→すべてのスペースを削除

うつくしく整いました。
ピボットします
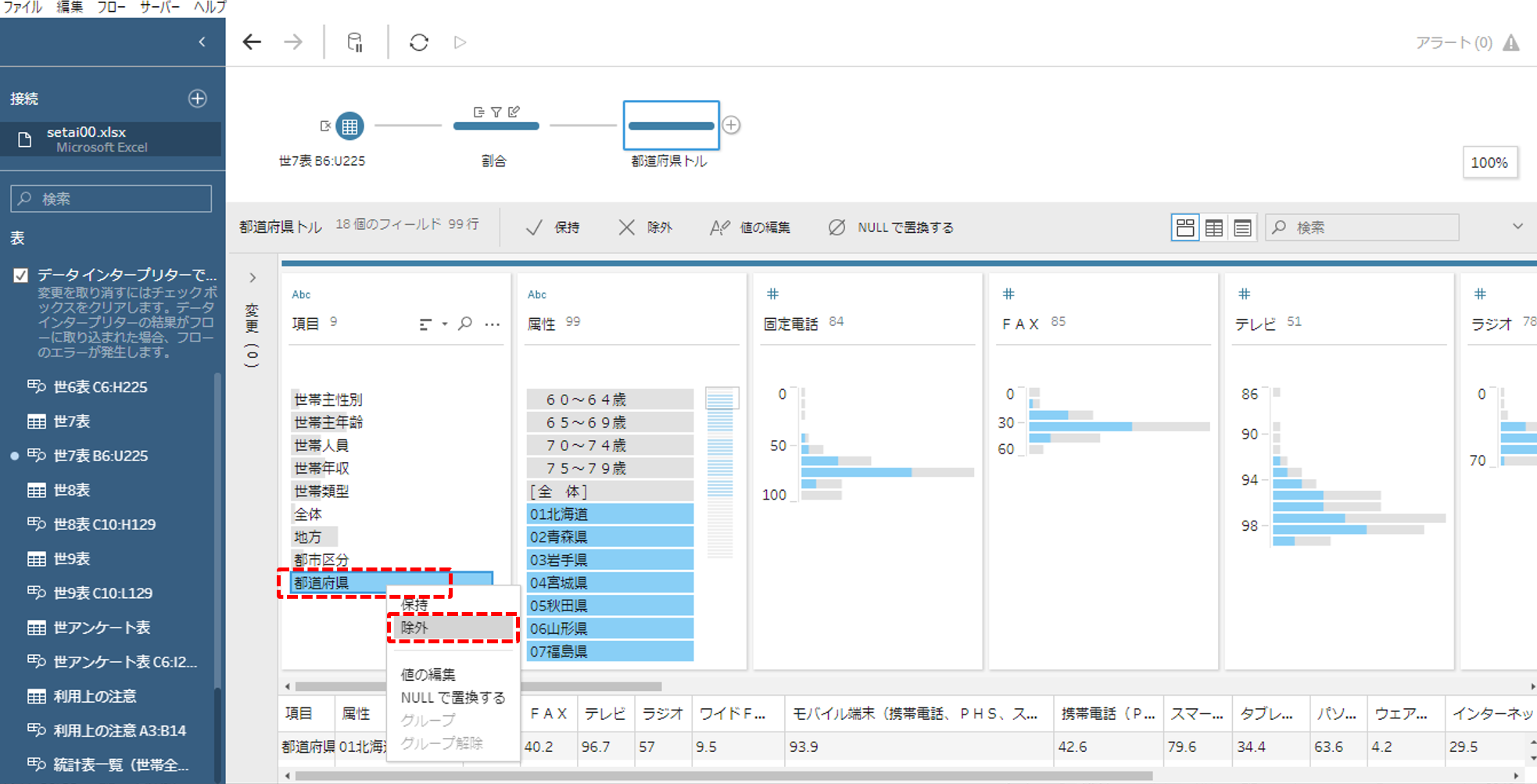
クリーニングステップを追加します。
いったん「項目」フィールドの「都道府県」を除外します。これは、のちに都道府県名の前にくっついている数字を外すからです。
ちなみに、ステップを追加するごとに簡単なステップ名を付けることをオススメします。全体のフローが長くなると、それぞれのステップで何を変更したのかがわからなくなってしまうからです。
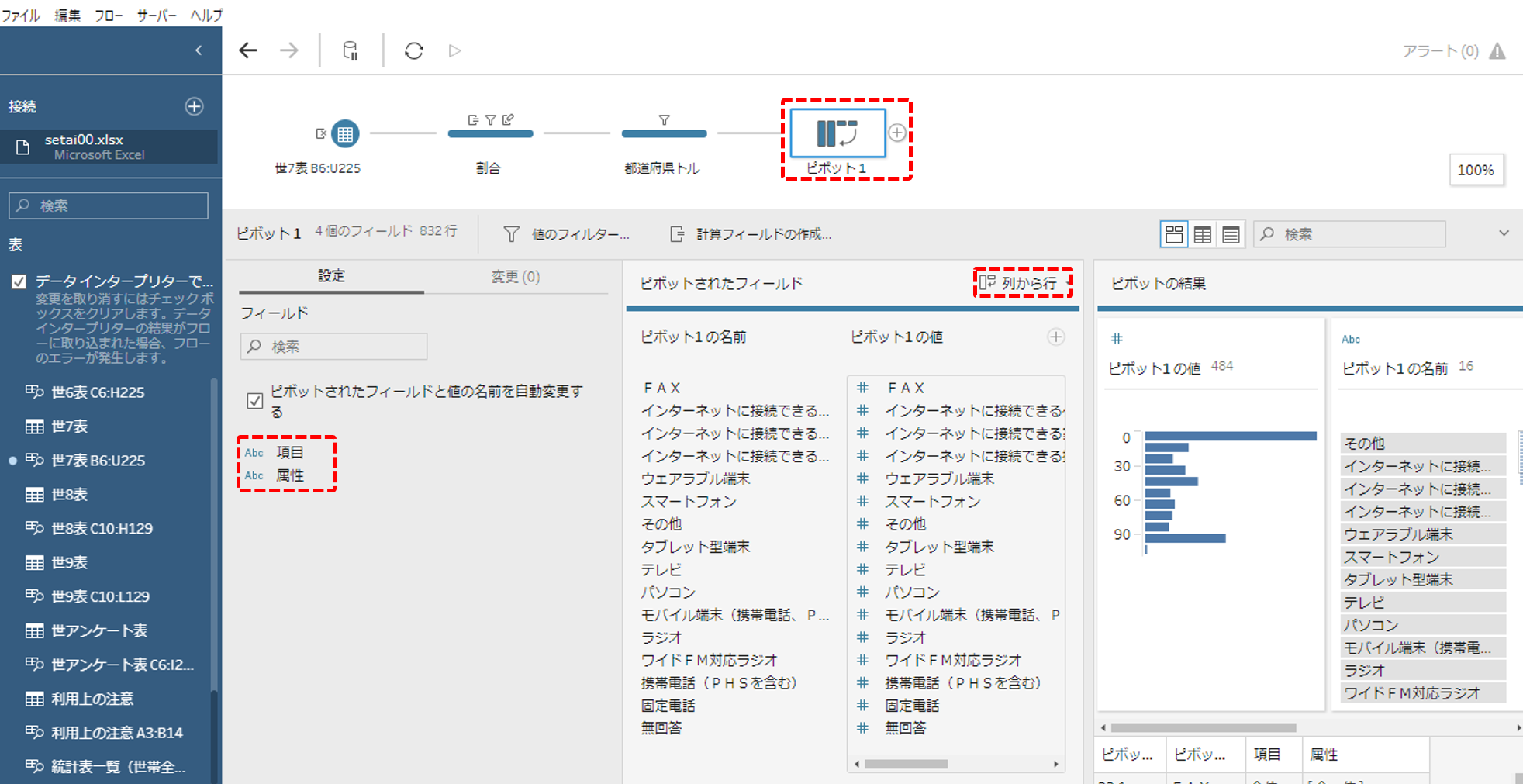
ピボットを追加します。「項目」と「属性」を残して、その他のすべてのフィールドを列から行へピボットします。
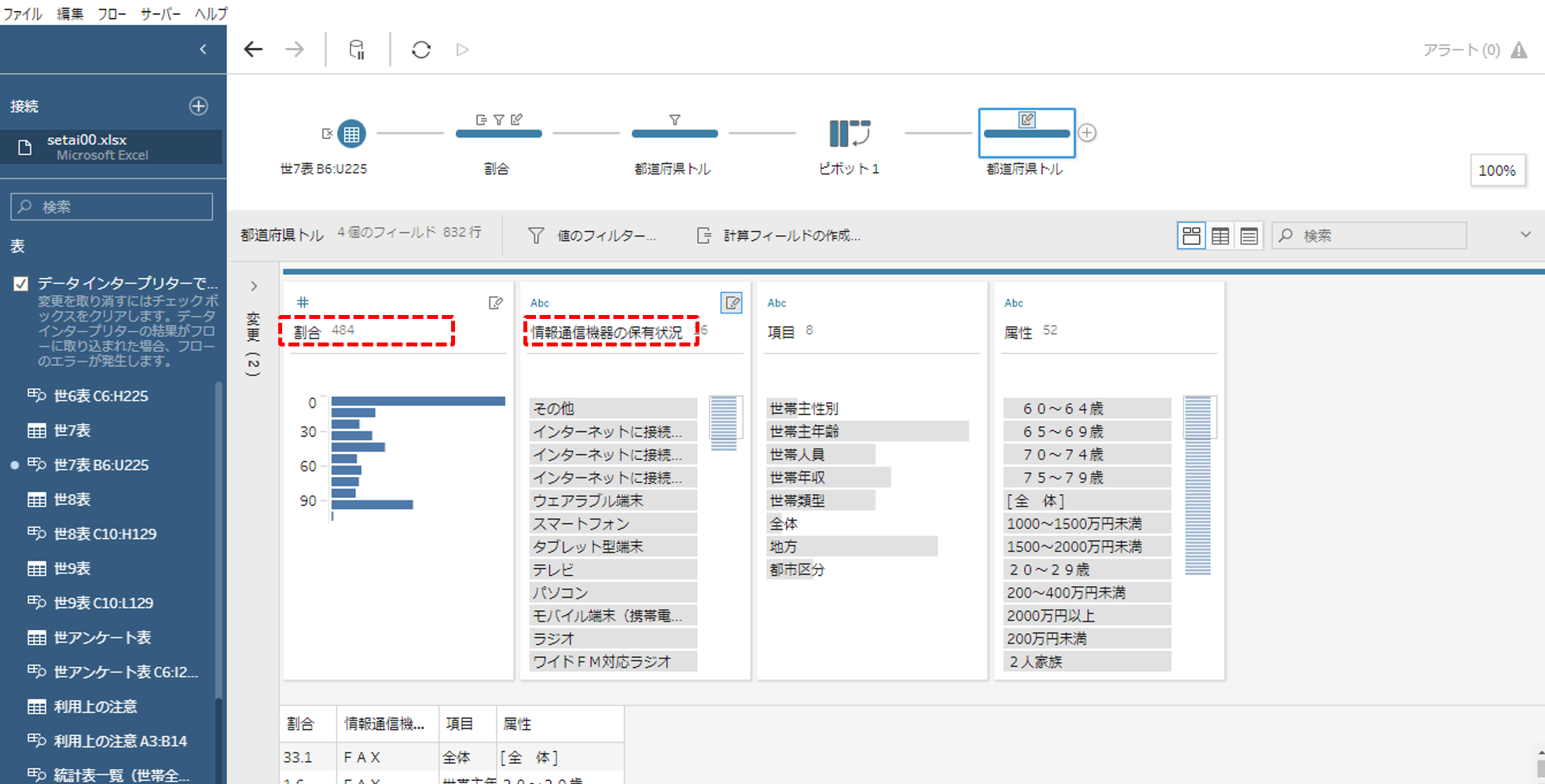
フィールド名をととのえます。
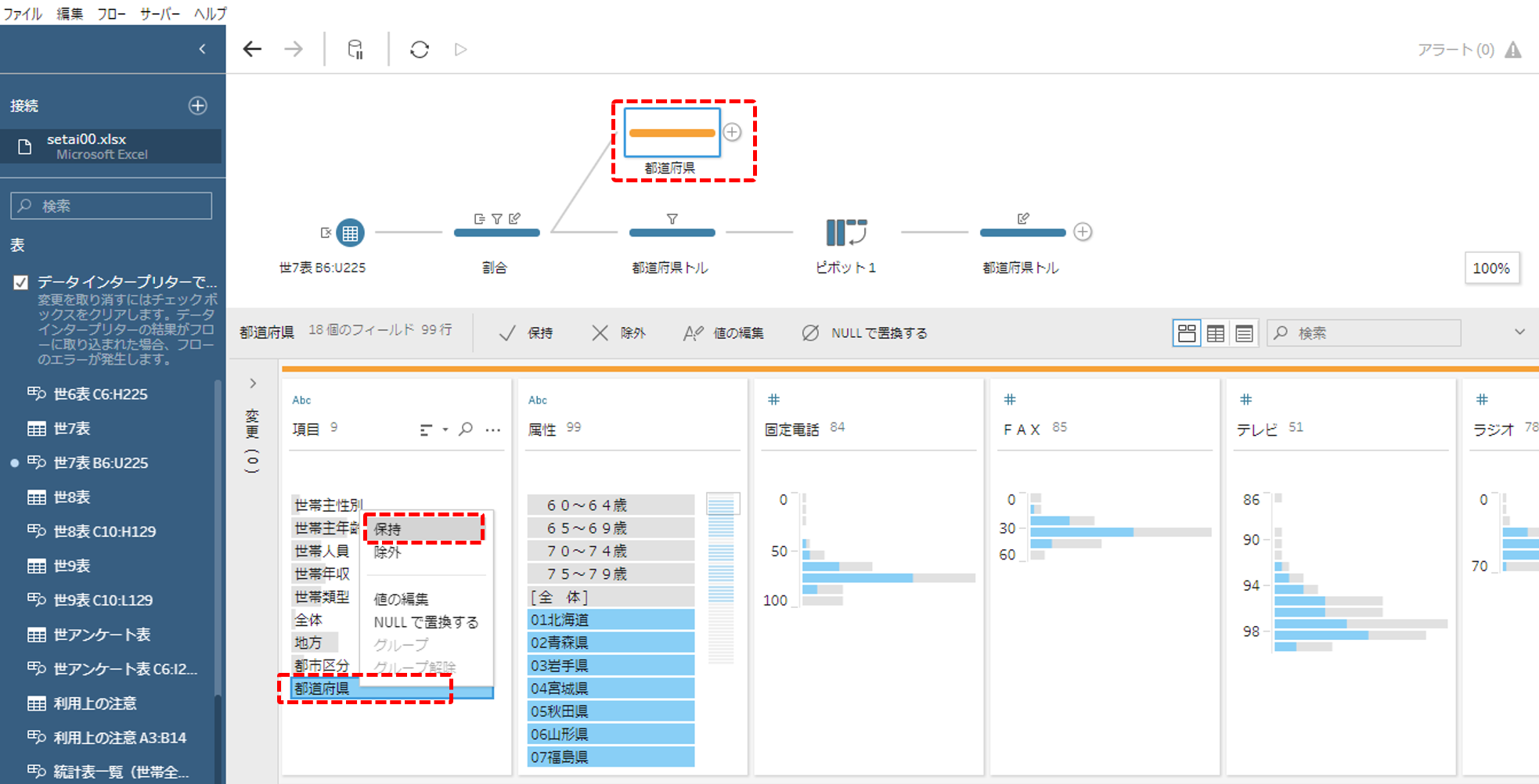
クリーニングステップを追加します。ここでは「項目」の「都道府県」だけを保持します。
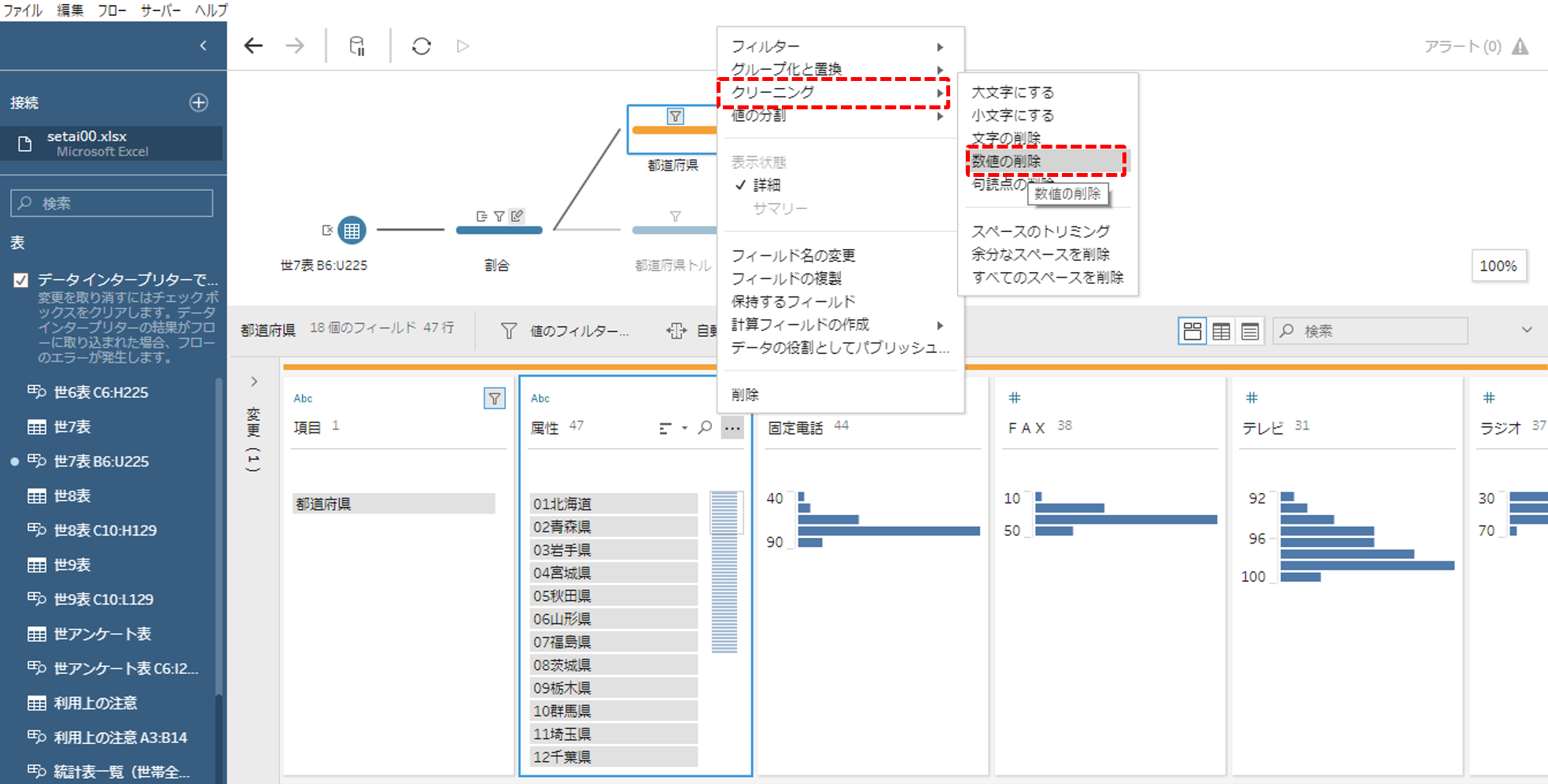
「都道府県」フィールドを「クリーニング」→「数値の削除」します。
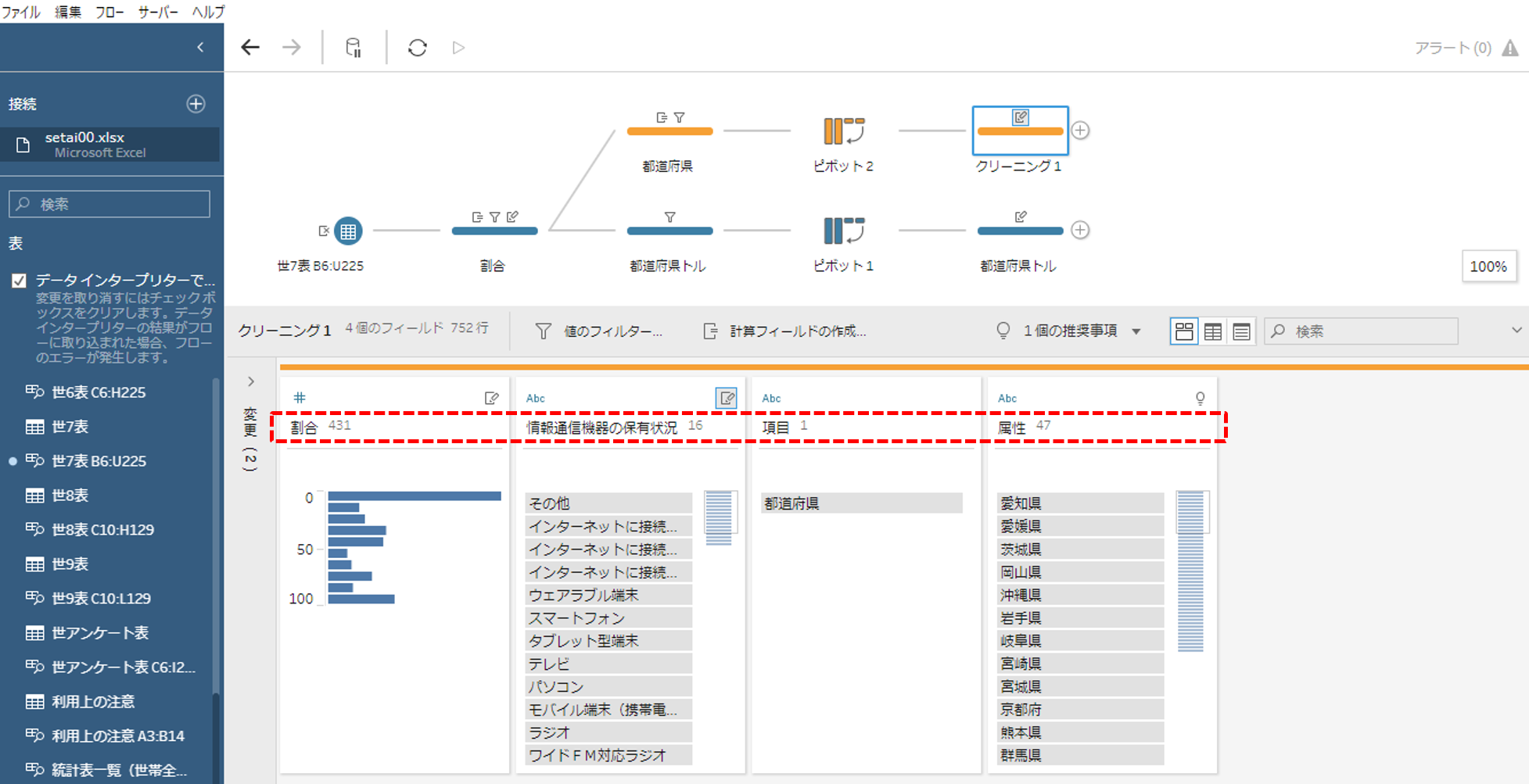
「項目」と「属性」を残して、その他のすべてのフィールドを列から行へピボットします。
フィールド名をととのえます。すべてのフィールド名を「都道府県トル」と一致させます。
ユニオンします
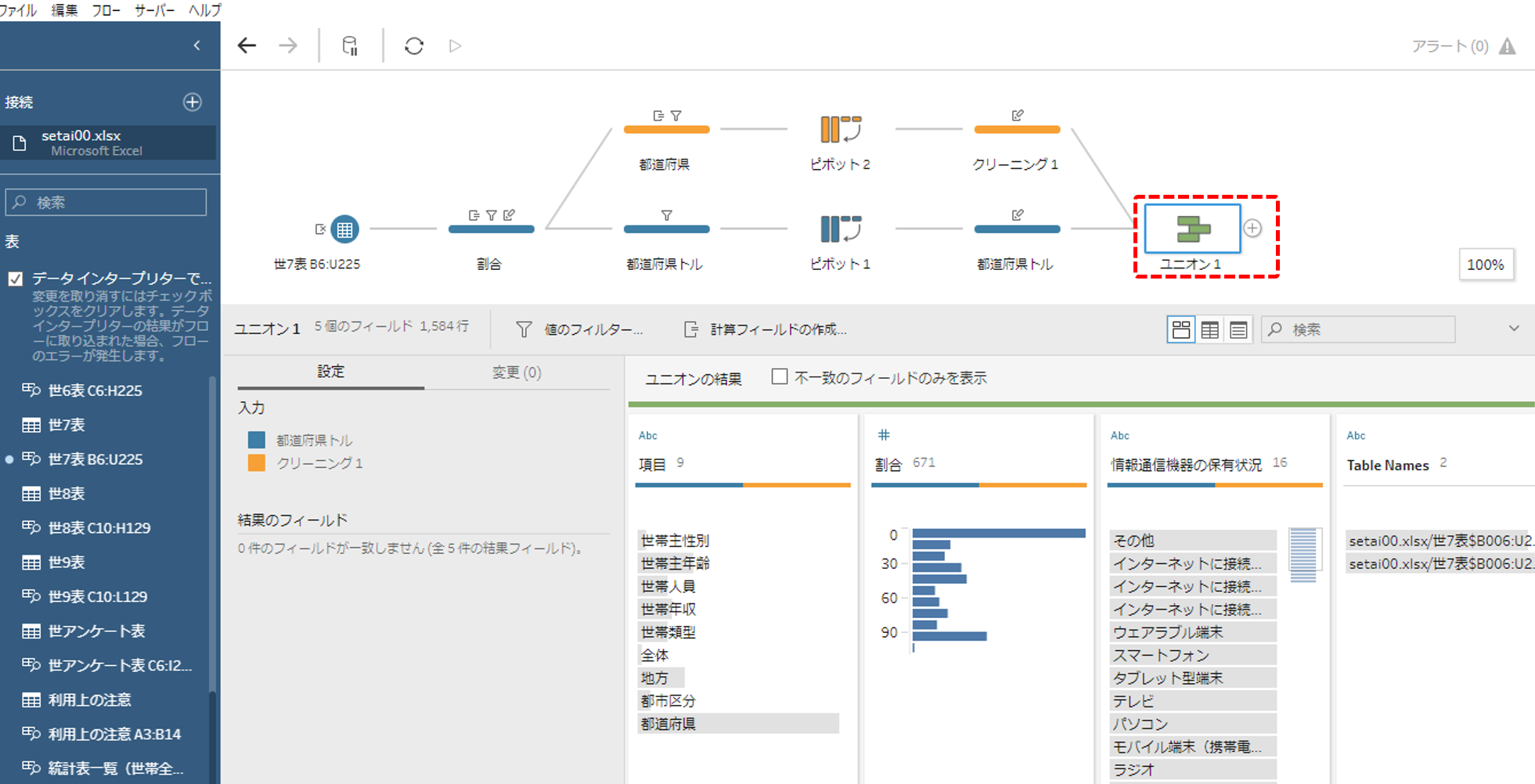
ここまでの手順で作成してきた2つのデータをユニオンします。

ユニオンによって作成されるフィールドを削除して完成です。
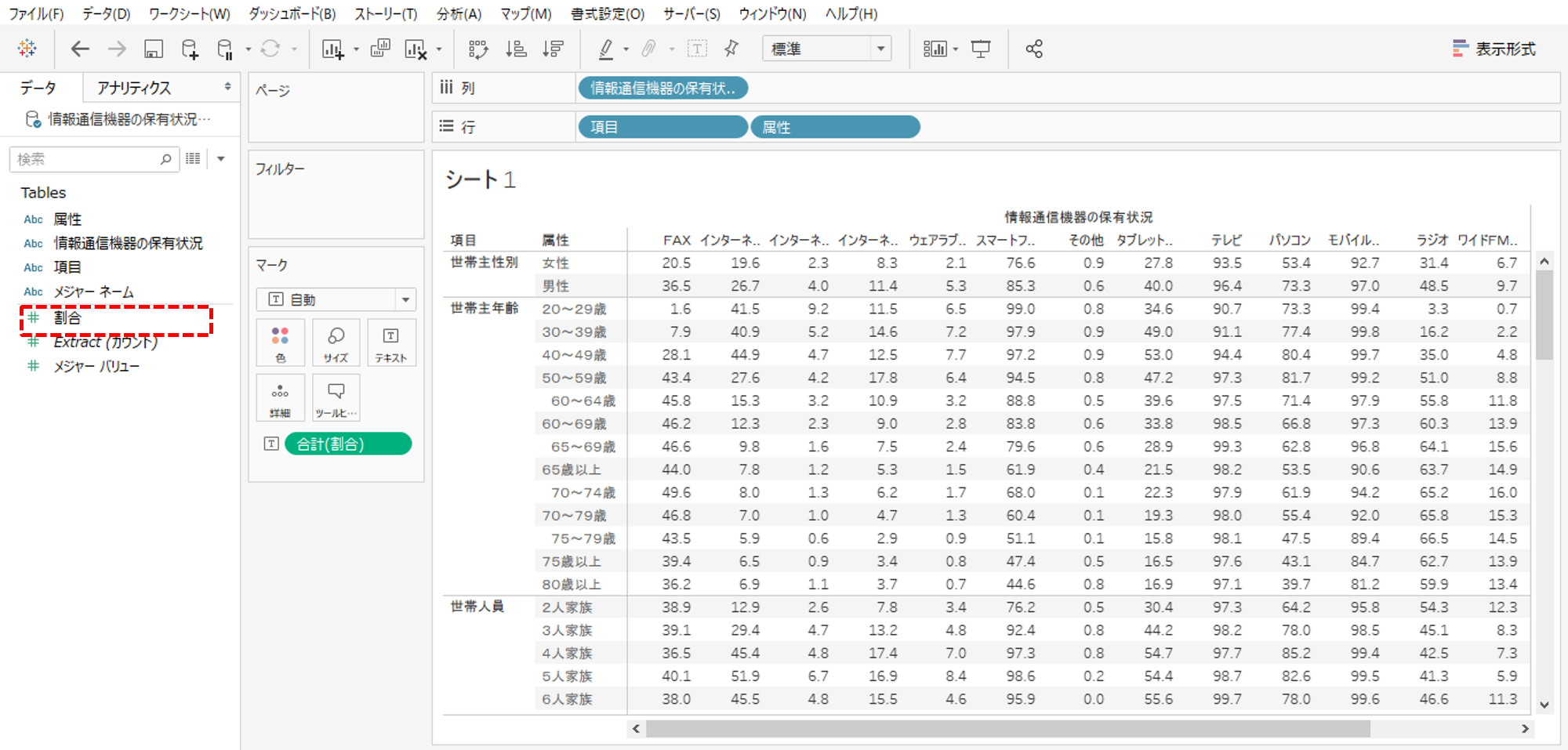
タブローで接続します。粗い粒度の「項目」と細かい粒度の「属性」、列指向形式へ変換したのでメジャーは「割合」だけになります。